


5 этапов оптического распознавания символов на практике
Рассказываем, как мы выросли по качеству распознавания текста в два релиза, руководствуясь главными принципами OCR.
8К открытий14К показов

Егор Федотьев
Руководитель разработки фронт-офисных решений
Один из видов кредитов нашего банка — потребительские IL-кредиты, которые выдаются в торговых сетях партнёров (например, МВидео). Большое значение в этом сегменте имеет скорость принятия решений о выдаче кредита. Это важно и для клиентов, и для партнёров — последние выберут банк, который обеспечит самый быстрый тайминг обработки.
Самый эффективный способ уменьшить тайминг обработки — увеличить процент автоматических авторизаций (когда документы в заявке обрабатываются без участия человека). Для этого мы в 2021 году купили новый нейросетевой шаблон распознавания паспорта.
Он должен был кратно повысить процент автоматических авторизаций, но результаты оказались средними. Тогда у нас появилась идея сделать своё оптическое распознавание символов на основе машинного обучения и с использованием open-source библиотек.
Технологии
Мы не стали писать с нуля низкоуровневую математику (это долго, больно и дорого), а исследовали рынок. Посмотрели, какие технологии наиболее зрелые, выбрали те, что подходят под наши требования (надёжность, лёгкость, небольшой порог вхождения, возможность использовать в коммерческих целях).
И подобрали несколько решений под наши задачи:
- сегментацию делает YOLOv3, реализующий на CPU алгоритм TensorFlow;
- очисткой занимается OpenCV от Intel, внутри которого та самая низкоуровневая математика;
- за распознавание символов отвечает Tesseract, разработка HP, перешедшая в Open Source благодаря Google;
- за работу с частотным словарем (о нём поговорим ниже) — SymSpell;
- все решения имеют реализацию .NET, и на нём же выполнена интеграция.
Как всё устроено в OCR
Мы выделили пять основных этапов распознавания документов:
- Выравнивание скана по вертикали.
- Очистка скана от шумов, пятен, удаление линий, повышение четкости.
- Сегментация — определение областей, в которых расположены конкретные поля паспорта: фамилия, имя, дата выдачи и так далее.
- Распознавание символов — классический optical character recognition, знакомый нам ещё по Fine Reader.
- Постпроцессинг — сверка распознанных Ф.И.О. с частотным словарём и проверка числовых полей regexp`ами.
Дальше рассмотрим все этапы подробнее.
Выравнивание скана
Итак, мы получили изображение второй и третьей страниц паспорта. В первую очередь надо уменьшить его до стандартного размера скана (примерно 1060х1500 рх) — чтобы последующая обработка не была слишком долгой.
Затем мы нормализуем картинку. Паспорта часто снимают под углом — а для распознавания они должны располагаться вертикально. Что происходит на этом этапе?

YOLOv3 проводит вектор по центру изображения и определяет границы страниц паспорта (чёрная линия и голубой и зелёный прямоугольники соответственно). Затем помечаем центры каждой области и соединяем их (красная линия). Так мы находим угол между полученными векторами и с помощью OpenCV поворачиваем изображение на эту величину.
Очистка
Теперь скан выровнен по вертикали, но в нём ещё остаются шумы: полосы от принтера или засветы от сканера. Если изображение делали с помощью смартфона, могут быть и солнечные блики или трапеции— за счёт того, что паспорт оказался полусогнут при съёмке.
Для очистки мы используем стандартные алгоритмы OpenCV: удаление шумов(non-local means denoising), уменьшение размеров контуров(erosion), увеличение контрастности и четкости и так далее
Отдельная проблема — на некоторых сканах при обработке появляются вертикальные чёрные линии толщиной в 1–2 пикселя, которые могут влиять на распознавание.



От них избавляемся в несколько этапов. Сперва трессхолдим изображение по методу Otsu, который устанавливает пороги для белого и чёрного цветов. Конвертируем по этим порогам в бинарное чёрное и белое изображение. Затем инвертируем цвета, получая изображение уже с белой полосой.
Затем все белые элементы соединяем с ближайшими и получаем вот такой результат:

Это нужно для того, чтобы сделать нашу белую линию гарантированно непрерывной. Процесс никак не вредит основному изображению.
Дальше мы ищем все белые линии, которые удовлетворяют следующим требованиям:
- пересекают область с данными паспорта;
- занимают минимум 73% длины изображения;
- не толще двух пикселей (если мы удалим более толстые линии, то не сможем восстановить текст, через который они проходят).
На последнем шаге мы заменяем в найденных линиях все значения цвета пикселя на соседние. Получается вот такой результат:

Сегментация
Сегментация — определение сегментов скана, в которых содержатся нужные нам данные и нет лишнего.
Мы вручную разметили пять сотен паспортов: выделили поля с данными и указали, в каких полях какие данные лежат. Размеченный таким образом датасет мы подавали в нейросетку, обучали её, и смотрели как она справляется распознаванием тестовой пачки сканов паспортов.
Пришлось немало помучиться с экспериментами по разметке обучающего датасета, чтобы понять, что стоит выделять в одно поле, а что — нет, чтобы получить минимум ошибок на тестовом датасете. В итоге мы пришли к такому варианту.
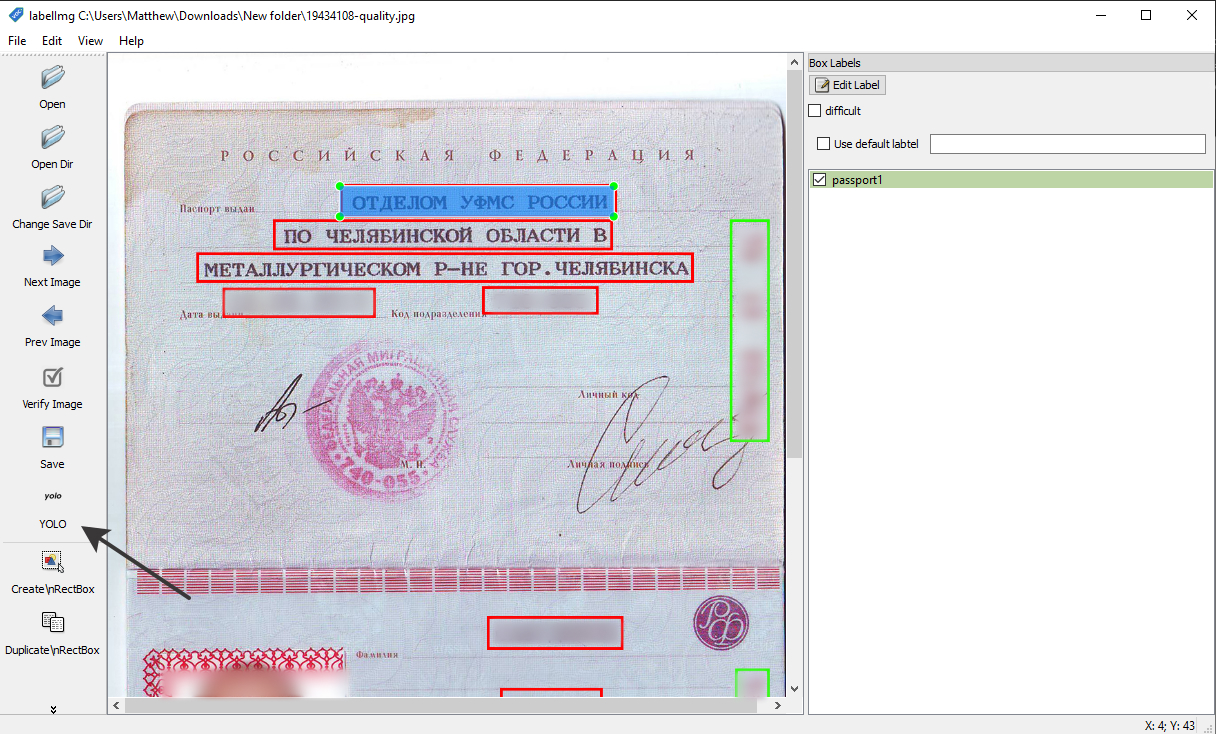
Распознавание символов
Мы уже очистили изображение, нашли все нужные поля: Ф. И. О., серия, номер, кем выдан и так далее. Теперь мы уменьшаем толщину шрифта и, если это необходимо, увеличиваем чёткость и контраст текста.
Зачем это нужно? Во-первых, шрифты в паспортах разные (одним шрифтом написаны только серия и номер и чаще всего МЧЗ — машиночитаемая зона внизу страницы). Слишком жирный шрифт нейросеть может не распознать — и, например, выдать условную восьмёрку вместо тройки. Во-вторых, яркость и чёткость у большинства полей разные, и светло-серый текст на светло-сером фоне так же путает алгоритм.

Наконец, загружаем всё в Tesseract, который работает с каждой строкой отдельно (это повышает качество распознавания) и делает нам классический OCR — превращает изображение в текст.
Постпроцессинг
После распознавания текста подключаются регулярные выражения, которые убирают лишние знаки, заменяют «о» на «0» и «з» на «3» в числовых полях.
И на финальном этапе мы используем частотный словарь всех возможных Ф. И. О. Как он работает? На основе клиентской базы банка мы создали три несвязанных между собой файла: с именами, фамилиями, отчествами и их частотой среди клиентов. Из них сделали справочники, по которым проверяем, есть ли в Ф. И. О. ошибки и при необходимости меняем данные на более вероятные (например, отчество Андреевин на Андреевич).
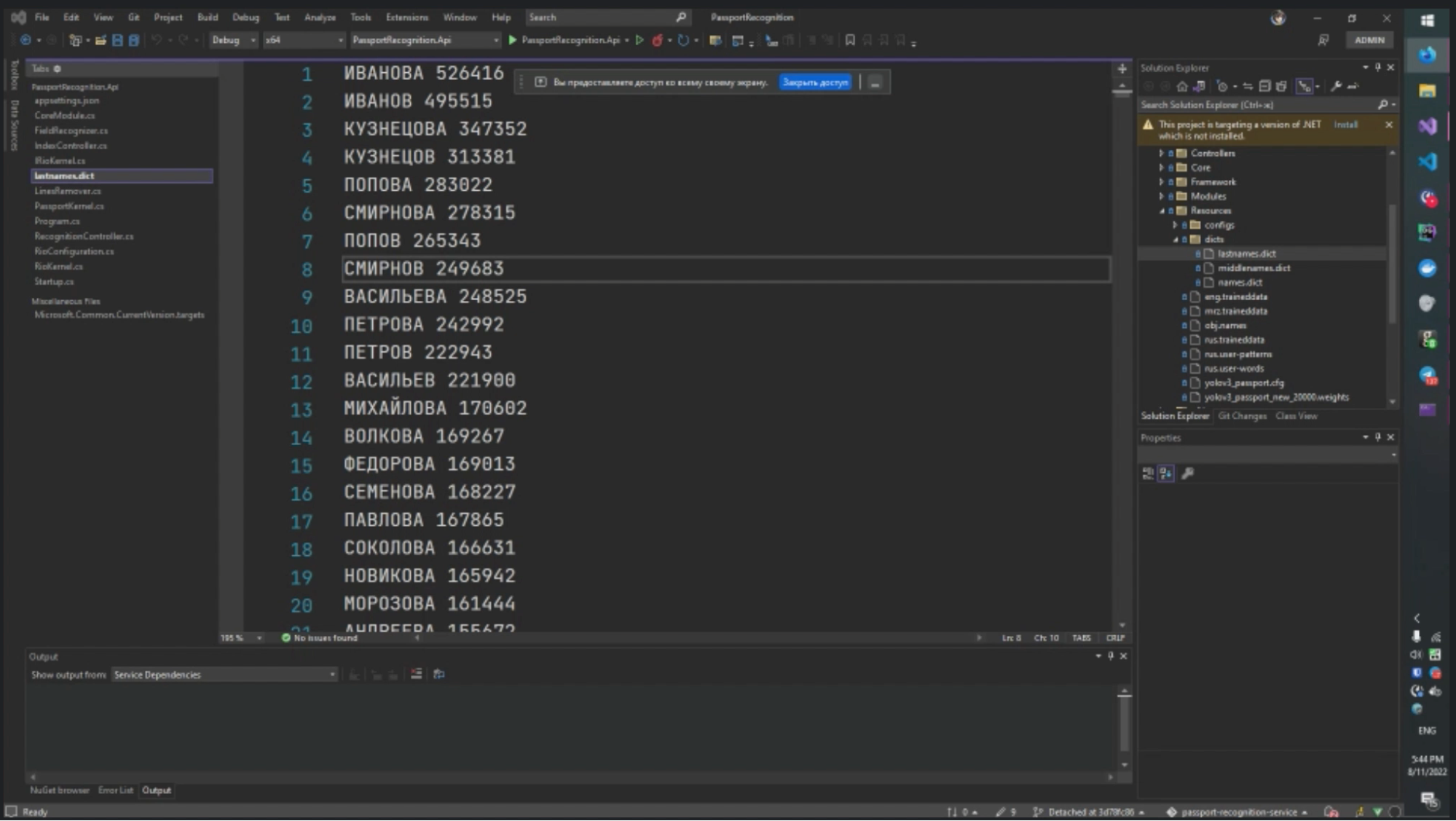
За работу со словарём отвечает библиотека SymSpell. Словарь улучшил качество распознавания примерно на 10%
Наконец, мы сверяем все распознанные данные с машиночитаемой зоной, внутри которой закодированы все данные паспорта. Если распознанные данные совпали, то это успех и значит, что автоматическая авторизация случилась.
Результаты
Число автоматических авторизаций заявок на кредит выросло с 31% до 82%. А время распознавания снизилось с 11 до 5 секунд без использования вычислений на видеокарте.
Кроме того, мы устранили зависимость от вендора в части распознавания — и теперь можем сами писать сервисы распознавания других документов, менять компоненты системы и делать точечные оптимизации.
Особую радость вызывает то, что от первых экспериментов на dev-среде до первого релиза прошло всего несколько месяцев, и большую часть работы сделал всего один разработчик — Матвей Смирнов.
В планах — распознавание документов формата А4 с мелким шрифтом и расширение линейки шаблонов внутрибанковского распознавания. А также словарь деловой лексики, которая часто используется в договорах.
И конечно, будем продолжать оптимизировать алгоритмы, чтобы приблизиться к 100%.

8К открытий14К показов
Было жёстко, но если мы справились, то и у вас получится. В статье рассказываем, что используем для поддержания рабочей атмосферы в команде.
Рассказали, как устроена система омниканальной рассылки без сложной персонализации и как реализовать что-то похожее с отправкой в Telegram
Чтобы ТЗ было понятно и разработчику, и заказчику, оно должно соответствовать ряду правил. Каких? Разбираемся в статье.
Команда банка «Ренессанс Кредит» продемонстрировала автоматизацию банковских процессов на реальном кейсе с примерами кода.