5 заданий по SQL с реальных собеседований
SQL — один из самых востребованных навыков в IT. Разбираем несколько задач с собеседований, разбитых по уровням junior, middle и senior.
SQL — один из самых востребованных навыков в современной IT индустрии (на 3 месте по популярности согласно StackOverflow Developer Survey 2020, даже Python идет на 4 месте).
Само собой, конкуренция в этой сфере огромна и собеседования порой превращаются в сущую пытку — кандидатам дают огромные задачи, задают десятки каверзных вопросов, устраивают дизайн-интервью и все это на позицию Junior аналитика…
Сегодня Елизавета, аналитик и эксперт IT Resume, делится 5 задачами и вопросами, которые входят в программу подготовки к собеседованию SQL Interview. Это задачи с реальных собеседований в крупные IT-компании, и они разбиты по уровням — Junior, Middle и Senior. Попробуйте и вы свои силы — сможете их решить без подсказки 😉

Елизавета Рузова
аналитик и эксперт в IT Resume
Вводные данные
Есть таблица анализов Analysis:
- an_id — ID анализа;
- an_name — название анализа;
- an_cost — себестоимость анализа;
- an_price — розничная цена анализа;
- an_group — группа анализов.
Есть таблица групп анализов Groups:
- gr_id — ID группы;
- gr_name — название группы;
- gr_temp — температурный режим хранения.
Есть таблица заказов Orders:
- ord_id — ID заказа;
- ord_datetime — дата и время заказа;
- ord_an — ID анализа.
Далее мы будем работать с этими таблицами.
Задача 1. Уровень: Junior
Формулировка: вывести название и цену для всех анализов, которые продавались 5 февраля 2020 и всю следующую неделю.
Это задача для начинающих специалистов. В ней проверяется базовое знание SELECT-запросов и умение работать с датой-временем.
Примечание На собеседованиях редко придираются к специфике диалекта — если Вы привыкли работать в PostgreSQL, то используйте привычные функции. Главное — правильно решить задачу.
Ответ

Задача 2. Уровень: Middle
Формулировка: нарастающим итогом рассчитать, как увеличивалось количество проданных тестов каждый месяц каждого года с разбивкой по группе.
Эта задача уже более высокого уровня: ее можно давать как Middle, так и Junior специалистам. Здесь проверяется базовое понимание оконных функций, джоинов и группировок.
Примечание После того, как вы написали первую версию своего запроса, попробуйте его оптимизировать. Например, в данном примере мы используем CTE — обобщенные табличные выражения.
Ответ

Задача 3: Уровень Senior
В этой задаче мы будем работать с другой таблицей (да, она будет всего одна). Сам запрос в этой задаче не сложный, но для его написания необходимо как бы уметь «мыслить на SQL».
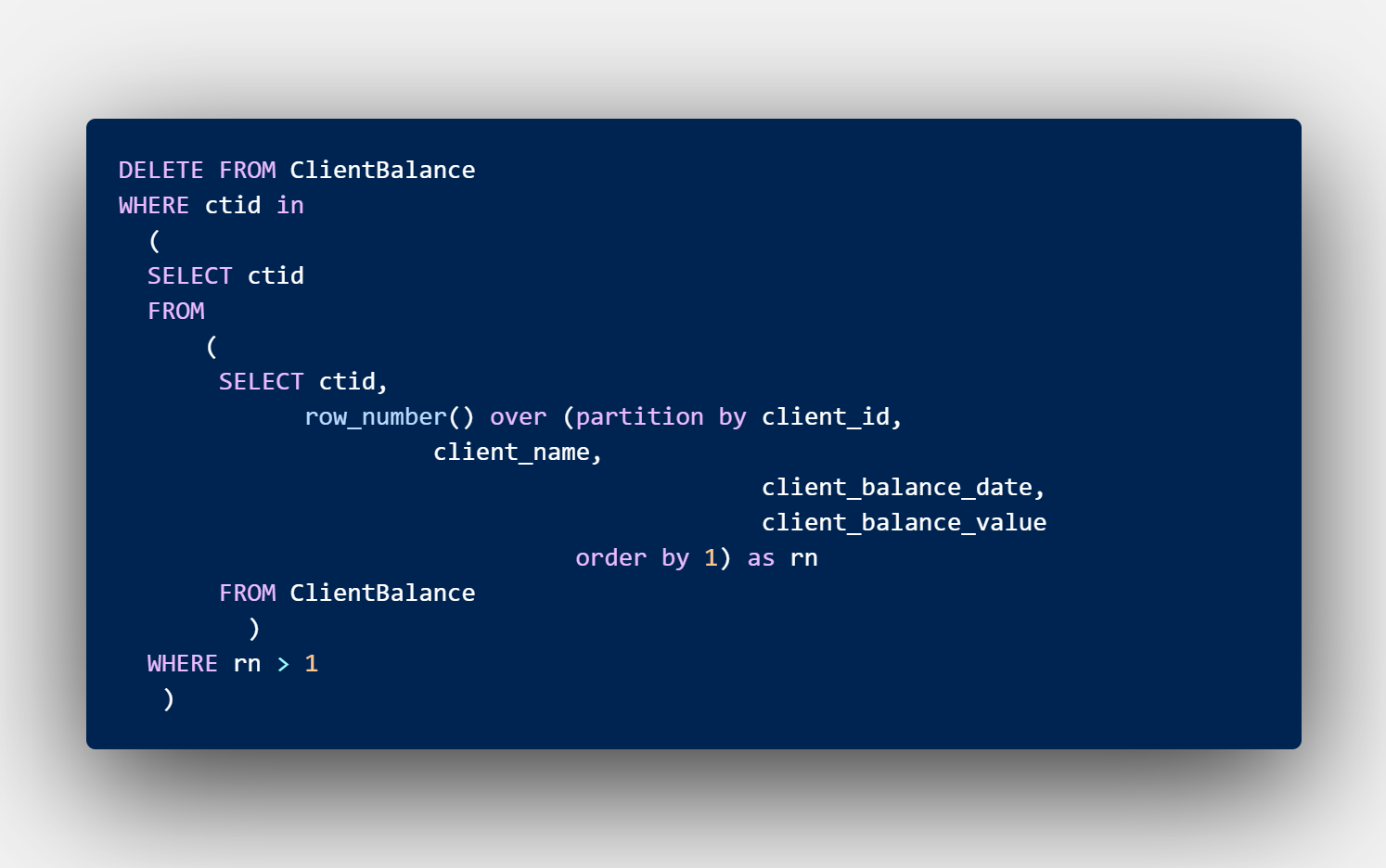
Рассмотрим таблицу балансов клиентов:
ClientBalance(client_id, client_name, client_balance_date, client_balance_value)
- client_id — идентификатор клиента;
- client_name — ФИО клиента;
- client_balance_date — дата баланса клиента;
- client_balance_value — значение баланса клиента.
Формулировка: в данной таблице в какой-то момент времени появились полные дубли. Предложите способ для избавления от них без создания новой таблицы.
Ответ
Вопрос 1. Уровень: Junior
Есть категория «хитрых» вопросов, которые особенно любят задавать Junior-специалистам. Хотя чего уж там, любым специалистам.
Один из таких видов — вопросы по темам, на которые в повседневной жизни не обращаешь внимания и о которых не задумываешься. Просто делаешь на автомате, а на собеседовании это стреляет. Ну или на проекте, когда код начинает работать неправильно. Но это другая история…
Вопрос: Как оператор GROUP BY обрабатывает поля с NULL?
Если Вы не знаете ответ на этот вопрос, то после прочтения ответа обязательно проверьте свои проекты — может у вас где-то закралась ошибка? 😉
Ответ
Учитывая, что NULL в SQL — просто отсутствие значения, то все значения NULL при группировке попадают в одну группу. Например, пусть есть таблица:
Тогда запрос select sum(score) from table group by name даст:
Вопрос 2. Уровень Middle
Этот вопрос не такой хитрый, как предыдущий, а вполне себе конкретный. Однако, он требует знания оконных функций и их тонкостей, а это исконное Middle требование.
Вопрос: В чем отличие функции RANK() от DENSE_RANK()?
Примечание Кстати говоря, по мотивам этого вопроса очень любят давать задачи на собеседованиях в разных вариациях: пронумеровать строки с одинаковыми значениями без разрывов, с разрывами и так далее. Так что потренируйтесь на досуге 🙂
Ответ
По аналогии с функцией ROW_NUMBER, оконные функции RANK и DENSE_RANK служат для нумерации строк. Однако, делают они это немного иначе: строки с одинаковым значениям получают одинаковый ранг. Для ряда задач это логично: если у двух сотрудников одинаковая зарплата, мы не можем сказать, что кто-то из них первый, а кто-то второй. Они одинаковы. Но при таком подходе возникает проблема: а какой ранг должен получить следующий сотрудник? Например, если первые два были одинаковые и у них ранги 1, то сотрудник со второй зарплатой в компании должен иметь ранг 2 или 3?
Эпилог
Мы разобрали с вами всего 5 возможных заданий, которые судьба и рекрутеры могут подкинуть вам на собеседовании. Однако, вариантов, на самом деле, масса. И чтобы реально подготовиться к собеседованию, нужно нарешать как можно больше задач, понять и прочувствовать теоретические аспекты и буквально научиться «мыслить на SQL». Именно на это и нацелена программа SQL Interview — так что будем рады помочь вам получить работу мечты!
И, помимо этого, не забывайте: SQL — чисто прикладной инструмент. Чтобы его освоить, нужно практиковаться, практиковаться и практиковаться. Выучить его можно буквально за несколько недель интенсивных занятий, а вот освоить на уровне Senior… порой на это уходят годы.





Посты кончились :(Вернитесь позже, мы обязательно выпустим новые
