Асинхронность в программировании
В высоконагруженных системах эффективная работа с помощью простых потоков затруднена. Разбираемся, как решить проблему с помощью асинхронности.

Традиционно в программировании используют синхронное программирование — последовательное выполнение инструкций с синхронными системными вызовами, которые полностью блокируют поток выполнения, пока системная операция, например чтение с диска, не завершится. В качестве примера ниже написан echo-сервер:
При вызове методов read() и write() текущий поток исполнения будет прерван в ожидании ввода-вывода по сети. Причём большую часть времени программа будет просто ждать. В высоконагруженных системах чаще всего так и происходит — почти всё время программа чего-то ждёт: диска, СУБД, сети, UI, в общем, какого-то внешнего, независимого от самой программы события. В малонагруженных системах это можно решить созданием нового потока для каждого блокирующего действия. Пока один поток спит, другой работает.
Но что делать, когда пользователей очень много? Если создавать на каждого хотя бы один поток, то производительность такого сервера резко упадёт из-за того, что контекст исполнения потока постоянно сменяется. Также на каждый поток создаётся свой контекст исполнения, включая память для стека, которая имеет минимальный размер в 4 КБ. Эту проблему может решить асинхронное программирование.
Асинхронность
Асинхронность в программировании — выполнение процесса в неблокирующем режиме системного вызова, что позволяет потоку программы продолжить обработку. Реализовать асинхронное программирование можно несколькими способами, о которых вы узнаете ниже.
Callbacks
Для написания асинхронной программы можно использовать callback-функции (от англ. callback — обратный вызов) — функции, которые будут вызваны асинхронно каким-либо обработчиком событий после завершения задачи. Переписанный пример сервера на callback-функциях:
В wait_connection() мы всё ещё ждём чего-то, но теперь вместе с этим внутри функции wait_connection() может быть реализовано подобие планировщика ОС, но с callback-функциями (пока мы ждём нового соединения, почему бы не обработать старые? Например, через очередь). Callback-функция вызывается, если в сокете появились новые данные — лямбда в async_read(), либо данные были записаны — лямбда в async_write().
В результате мы получили асинхронную работу нескольких соединений в одном единственном потоке, который намного реже будет ждать. Эту асинхронность можно также распараллелить, чтобы получить полный профит от утилизации процессорного времени.
У такого подхода есть несколько проблем. Первую в шутку называют callback hell. Достаточно погуглить картинки на эту тему, чтобы понять, насколько это нечитаемо и некрасиво. В нашем примере всего две вложенные callback-функции, но их может быть намного больше.
Вторая проблема заключается в том, что код перестал выглядеть как синхронный: появились «прыжки» из wait_connection() в лямбды, например лямбда, переданная в async_write(), что нарушает последовательность кода, из-за чего становится невозможно предсказать, в каком порядке будут вызваны лямбды. Это усложняет чтение и понимание кода.
Async/Await
Попробуем сделать асинхронный код так, чтобы он выглядел как синхронный. Для большего понимания немного поменяем задачу: теперь нам необходимо прочитать данные из СУБД и файла по ключу, переданному по сети, и отправить результат обратно по сети.
Пройдём по программе построчно:
- Ключевое слово
asyncв заголовке функции говорит компилятору, что функция асинхронная и её нужно компилировать по-другому. Каким именно образом он будет это делать, написано ниже. - Первые три строки функции: создание и ожидание соединения.
- Следующая строка делает асинхронное чтение, не прерывая основной поток исполнения.
- Следующие две строки делают асинхронный запрос в базу данных и чтение файла. Оператор
awaitприостанавливает текущую функцию, пока не завершится выполнение асинхронной задачи чтения из БД и файла. - В последних строках производится асинхронная запись в сокет, но лишь после того, как мы дождёмся асинхронного чтения из БД и файла.
Это быстрее, чем последовательное ожидание сначала БД, затем файла. Во многих реализациях производительность async/await лучше, чем у классических callback-функций, при этом такой код читается как синхронный.
Корутины
Описанный выше механизм называется сопрограммой. Часто можно услышать вариант «корутина» (от англ. coroutine — сопрограмма).
Далее будут описаны различные виды и способы организации сопрограмм.
Несколько точек входа
По сути корутинами называются функции, имеющие несколько точек входа и выхода. У обычных функций есть только одна точка входа и несколько точек выхода. Если вернуться к примеру выше, то первой точкой входа будет сам вызов функции оператором asynс, затем функция прервёт своё выполнение вместо ожидания БД или файла. Все последующие await будут не запускать функцию заново, а продолжать её исполнение в точке предыдущего прерывания. Да, во многих языках в корутине может быть несколько await’ов.
Для большего понимания рассмотрим код на языке Python:
Программа выведет всю последовательность чисел факториала с номерами от 0 до 41.
Функция async_factorial() вернёт объект-генератор, который можно передать в функцию next(), а она продолжит выполнение корутины до следующего оператора yield с сохранением состояния всех локальных переменных функции. Функция next() возвращает то, что передаёт оператор yield внутри корутины. Таким образом, функция async_factorial() в теории имеет несколько точек входа и выхода.
Stackful и Stackless
В зависимости от использования стека корутины делятся на stackful, где каждая из корутин имеет свой стек, и stackless, где все локальные переменные функции сохраняются в специальном объекте.
Так как в корутинах мы можем в любом месте поставить оператор yield, нам необходимо где-то сохранять весь контекст функции, который включает в себя фрейм на стеке (локальные переменные) и прочую метаинформацию. Это можно сделать, например, полной подменой стека, как это делается в stackful корутинах.
На рисунке ниже вызов async создаёт новый стек-фрейм и переключает исполнение потока на него. Это практически новый поток, только исполняться он будет асинхронно с основным.
yield в свою очередь возвращает обратно предыдущий стек-фрейм на исполнение, сохраняя ссылку на конец текущего в предыдущий стек.
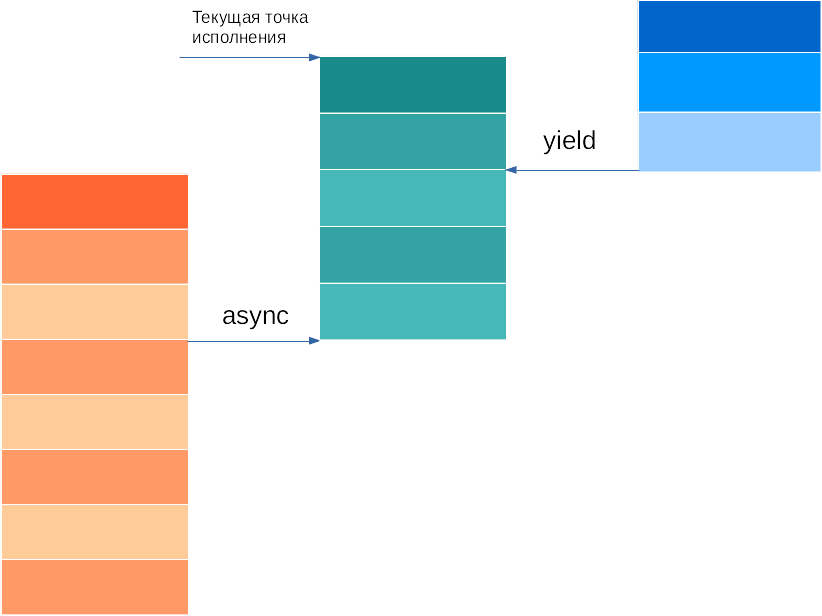
Наличие собственного стека позволяет делать yield из вложенных вызовов функций, но такие вызовы сопровождаются полным созданием/сменой контекста исполнения программы, что медленней, чем stackless корутины.
Более производительными, но вместе с тем и более ограниченными, являются stackless корутины. Они не используют стек, и компилятор преобразует функцию, содержащую корутины, в конечный автомат без корутин. Например, код:
Будет преобразован в следующий псевдокод:
По сути здесь создаётся класс, который сохраняет всё состояние функции, а также последнюю точку вызова yield. У такого подхода есть проблема: yield может быть вызван только в теле функции-корутины, но не из вложенных функций.
Симметричные и асимметричные
Корутины также делятся на симметричные и асимметричные.
Симметричные имеют глобальный планировщик корутин, который и выбирает среди всех ожидающих асинхронных операций ту, которую стоит выполнить следующей. Примером является планировщик, о котором говорилось в начале функции wait_connection().
В асимметричных корутинах нет глобального планировщика, и программист вместе с поддержкой компилятора сам выбирает, какую корутину и когда исполнять. Большинство реализаций корутин асимметричные.
Вывод
Асинхронное программирование является очень мощным инструментом для оптимизации высоконагруженных программ с частым ожиданием системы. Но, как и любую сложную технологию, её нельзя использовать только потому, что она есть. Необходимо всегда задавать себе вопрос: а нужна ли мне эта технология? Какую практическую пользу она мне даст? Иначе разработчики рискуют потратить очень много сил, времени и денег, не получив никакого профита.
Смотрите также: Асинхронное программирование в Python

