Болевые точки Django в современной разработке
Сегодня хочу поговорить про Django. Django — замечательный фреймворк. А еще крайне популярный, его часто осваивают новички и используют в своих проектах. На самом деле у Django есть и несколько минусов, а точнее нюансов, на которые важно обращать внимание и о которых важно знать, приступая к разработке.
Привет! Меня зовут Николай Долганов, я старший разработчик Python в Группе НЛМК.

Сегодня хочу поговорить про Django. Django — замечательный фреймворк. А еще крайне популярный, его часто осваивают новички и используют в своих проектах. На самом деле у Django есть и несколько минусов, а точнее нюансов, на которые важно обращать внимание и о которых важно знать, приступая к разработке.
Django как инструмент для быстрого старта
Только по данным ресурса Хабр Карьера на июнь 2023 года, Django входил в топ-8 по вакансиям. Популярность фреймворка легко объяснима.
1. Низкий порог вхождения. Можно сказать, порожек, маленькая неровность на пути начинающего программиста.
2. Огромный объем материалов от сообщества и разработчиков. Например, отличная официальная документация на английском. Или на русском.
3. Фреймворк — это коробка с батарейками, которая решает большинство функциональных задач.
4. Множество готовых решений, которые можно интегрировать с вашим проектом.
Именно это позволяет быстро создать рабочее решение на Django. Особенно если предыдущее решение стало недоступным из-за санкций.
Однако почти каждый аргумент в пользу Django, исключая разве что документацию и материалы сообщества, имеет контраргумент.
1. В большинстве случаев квалификации программиста на Django недостаточно для того, чтобы в срок и качественно решить задачи бизнеса.
2. Батарейки Django зачастую работают не так, как нужно, проигрывая наивным самописным решениям.
3. Готовые расширения Django либо слишком велики для решения локальных задач, либо создают проблемы в зависимостях. Кроме того, они могут создавать риск для безопасности инфраструктуры.
Проблемы Django Admin
Один из проектов в нашей компании создан с помощью Django.
В процессе работы мы столкнулись с некоторыми болевыми точками фреймворка, о которых стоит рассказать.
Django представляет собой готовое решение, но не все его компоненты подходят для Production. Например, Django Admin позволяет сэкономить время на написании собственной контрольной панели. В теории. На практике вы столкнетесь с тем, что схема данных в БД отличается от представления формы для редактирования данных.
Например, в БД есть поля типа Interval и Boolean. Запись может иметь срок действия (после наступления которого запускается какая-то проверка), может быть бессрочной (поле Boolean) либо не имеет ни срока, ни признака бессрочного действия (проверка запускается вручную). Первая проблема, с которой вы столкнетесь при реализации, — это отсутствие в Django ORM поля модели, которое полностью эксплуатировало бы тип данных Interval. Вторая проблема состоит в необходимости написания формы для «админки», чтобы пользователь заполнял одно поле, а не два одновременно. Разумеется, подобные проблемы в энтерпрайзе давно решаются отказом от Django Admin в пользу DRF + SPA.
Еще одна существенная проблема Django Admin — это отсутствие оптимизации запросов по умолчанию. Впрочем, учитывая особенности архитектуры компонента (с шаблонизатором), оптимизировать запросы простыми способами не получится. Так что решение так или иначе будет тормозить, если у вас много связей и данных.
Так мы постепенно приблизились к главной «батарейке» Django и к ее главной болевой точке — ORM.
Анализ запросов к БД, созданных Django ORM
Прежде чем понять, как нам могут угрожать запросы к БД, предлагаю научиться анализировать их, используя ORM Django.
Рассмотрим пример, который никогда не существовал в реальности. Файл models.py, которого никогда не было:
Давайте составим запрос на получение всех заводов группы Glam Metal:
Запуск этого кода внутри консоли современной IDE позволяет произвести анализ переменных (дебаг):
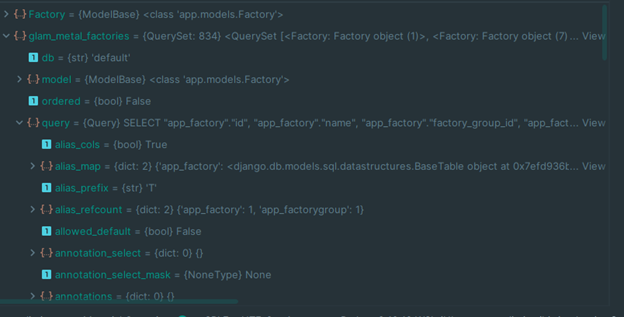
Посмотрите: переменная glam_metal_factories — это экземпляр класса QuerySet. Это тот самый механизм «ленивых» запросов Django ORM. Сначала мы получаем экземпляр класса QuerySet, потом, если, например, обратиться к первому элементу выборки или запустить цикл for, запрос уйдет в БД.
Но сейчас нас интересует свойство query. Это экземпляр класса Query, но его репрезентативный дандер-метод возвращает запрос, который будет выполнен в БД, если мы сделаем обращение к ней.
Если у вас нет под рукой дебагера, можно сделать так:
И мы получим вот такой результат:
Помните: важным умением для разработчика Django является анализ SQL-запросов. Давайте разберемся почему.
Первые проблемы
Итак, у нас есть три модели. У нас есть запрос, который получает только заводы, входящие в группу Glam Metal. Этого мало, чтобы построить приложение. Ведь приложением пользуются люди, и для них наши Frontend-разработчики подготовили приятный пользовательский интерфейс на JavaScript.
Интерфейс связывается с Backend посредством REST API. В качестве «батарейки» для REST мы используем Django Rest Framework (в простонародье DRF).
Давайте представим, что у нас есть некий эндпоинт, который возвращает только заводы группы Glam Metal. Только список. Нам потребуется следующий модуль serializers.py:
А также представление во views.py:
Теперь нам потребуется занести в систему некоторое количество заводов. Не будем мелочиться и заведем сразу 5000. Для этого воспользуемся библиотекой Factory Boy:
Выполним:
И дождемся окончания операции.
Здесь мы предполагаем, что в системе есть пользователь с id=1. На самом деле под пользователя тоже лучше завести фабрику.
Итак, открыв в браузере наш API, мы увидим следующее:
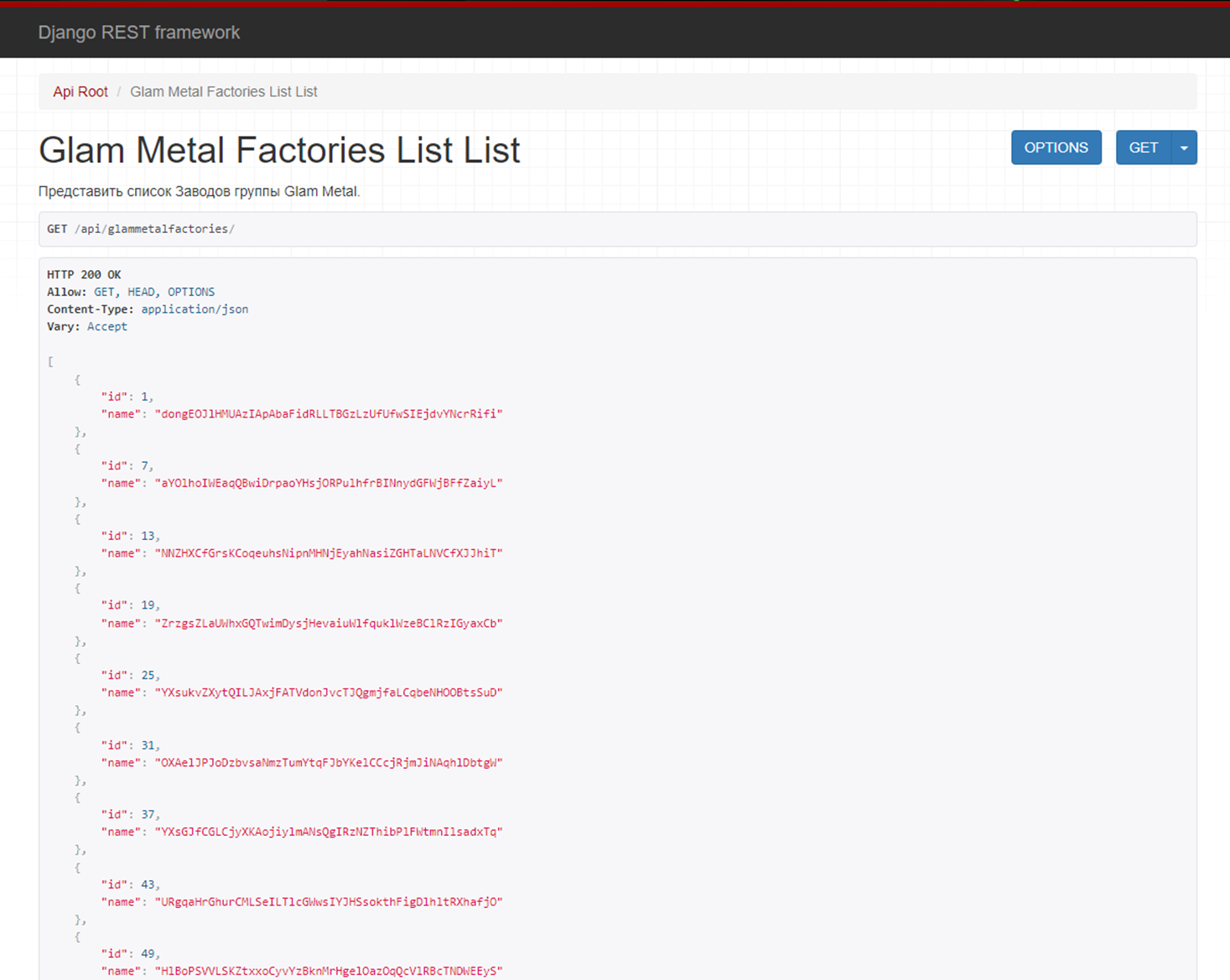
Однако пролистайте статью выше и вспомните, как выглядел наш запрос. Он выбирал все поля из таблицы с заводами. И хотя наш пример является виртуальным, в жизни бывает так, что полей у модели может быть очень много.
Так мы сталкиваемся с первой проблемой оптимизации запросов в Django ORM: она по умолчанию выбирает все поля!
Усложняем задачу
Нам пришла доработка: мы должны выводить список всех контактных лиц (их телефоны), а также ФИО пользователя, которые хранятся в модели User. Также мы должны вывести имя группы заводов, чтобы в следующей доработке сделать поле group_name динамическим — будем его прокидывать в Query Params.
Модернизируем serializers.py:
Обратите внимание на метод get_full_name. Он ссылается на property fio, которое программист создал для модели User, чтобы не повторять фрагмент кода для получения ФИО в разных местах. Выглядит это свойство так:
Мы получили результат:
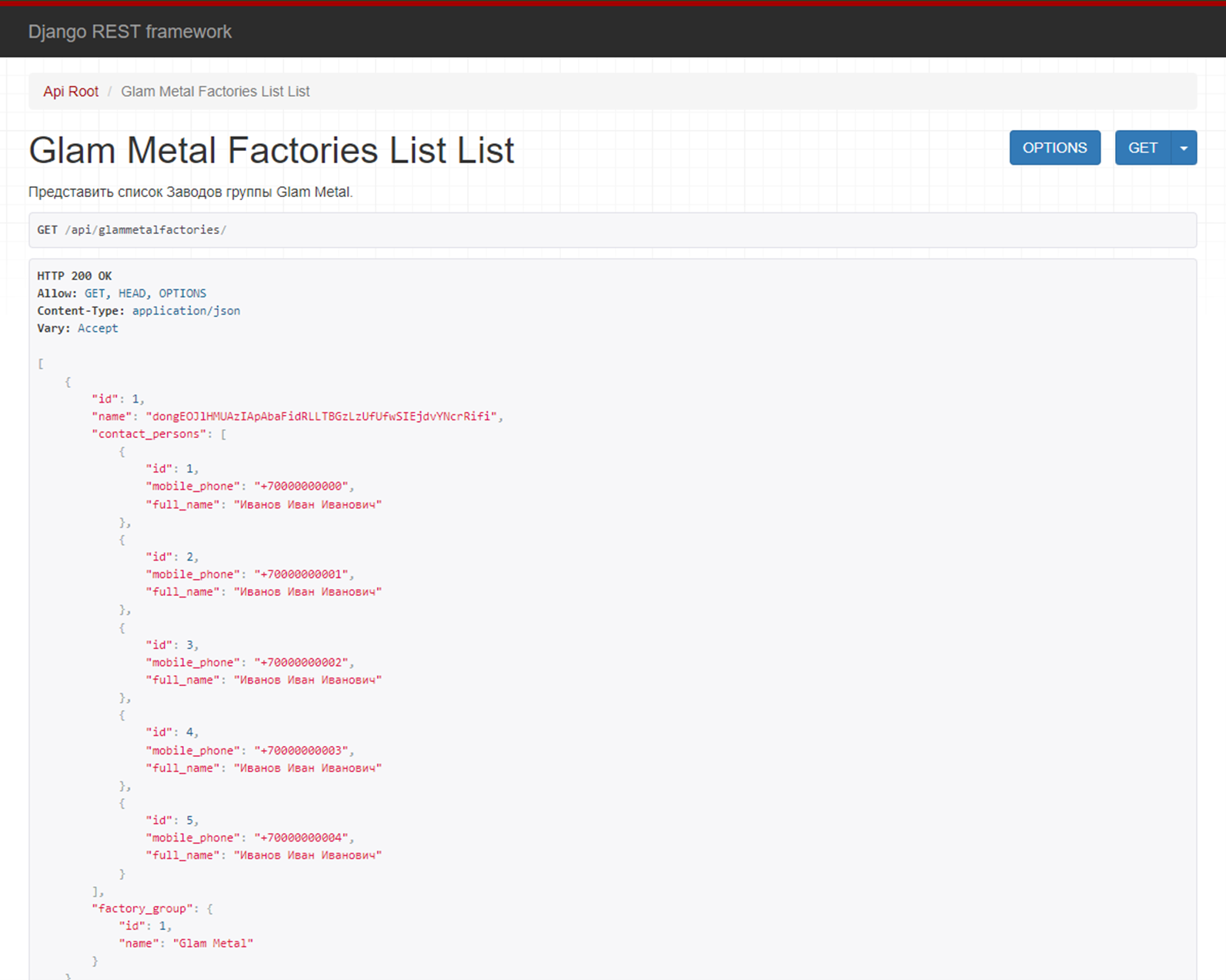
Задачу можно закрывать? На самом деле нет. Все только начинается.
Используем Django Debug Toolbar
Если вы спросите у опытного джангиста, как он проверяет запросы к БД, он, скорее всего, скажет о Django Debug Toolbar. И не ошибется, поскольку это достаточно мощный инструмент для определения того, что делала Django прежде, чем отдать пользователю ответ.
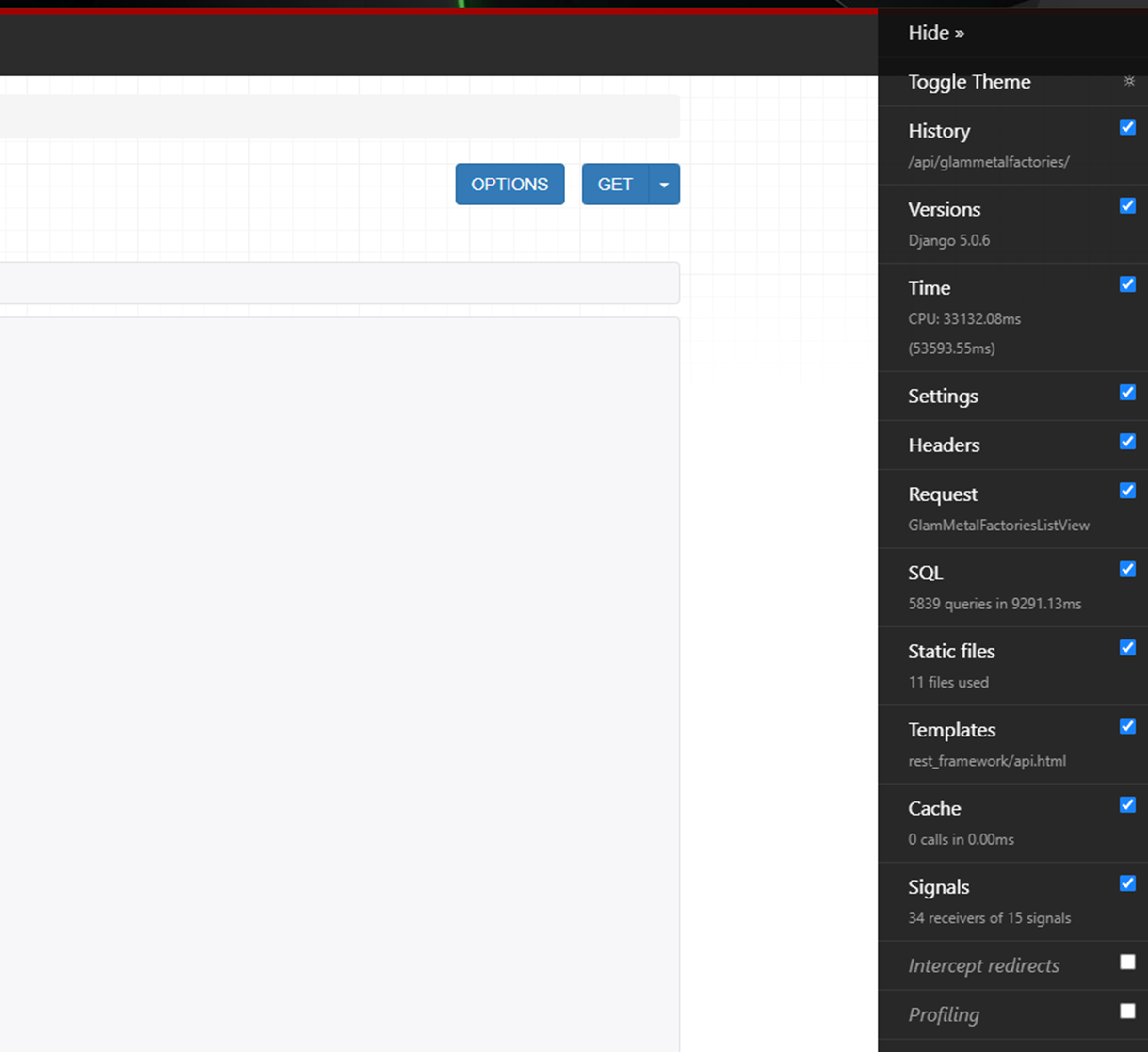
Посмотрите: у нас вышло 5839 запросов. Притом что заводов группы Glam Metal всего 834:

Открыв детализацию SQL-запросов, мы увидим вот такую картину:
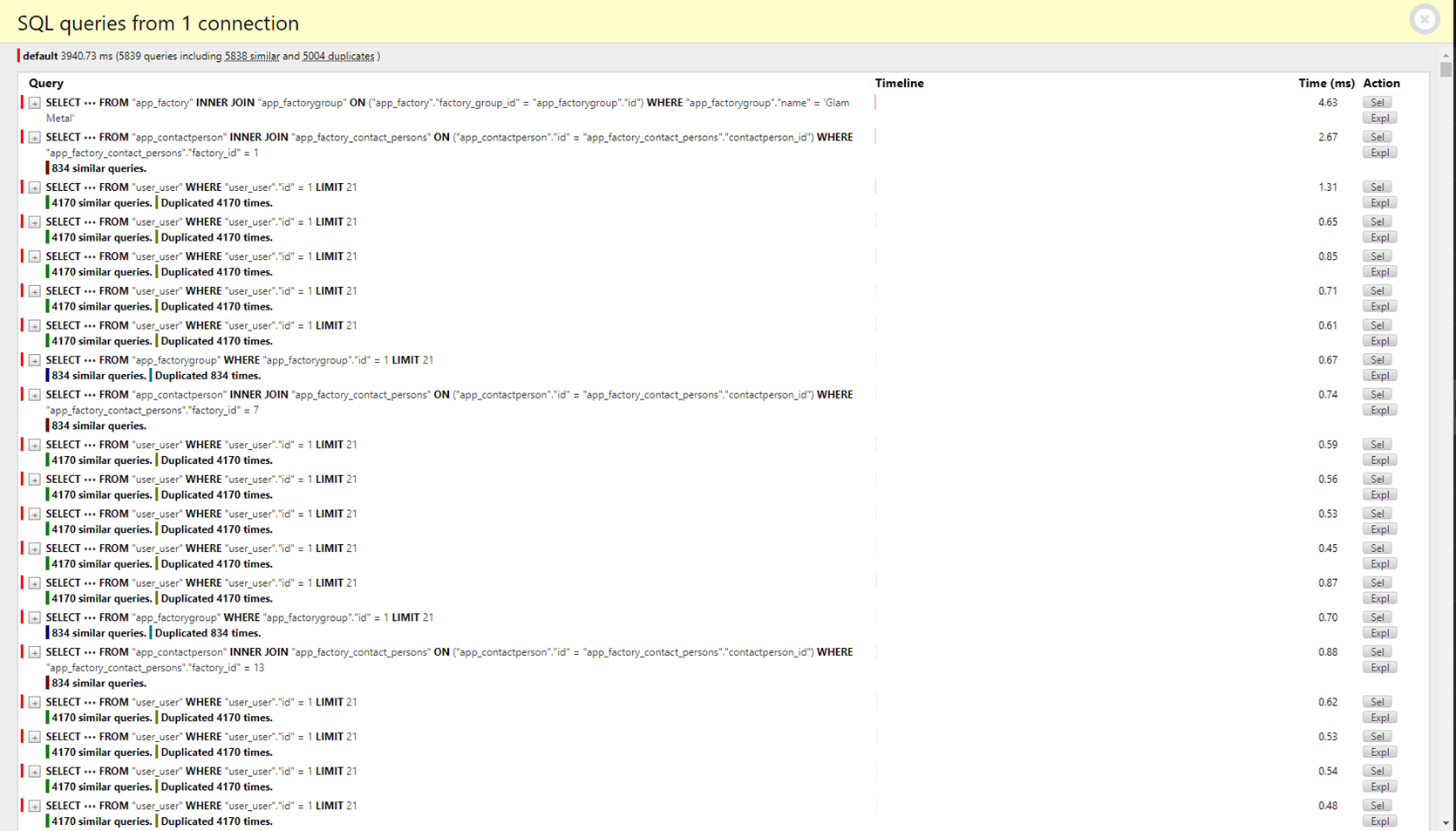
Одной из ключевых особенностей Django Debug Toolbar является группировка одинаковых запросов (similar queries):

Открыв детальную информацию по группе, мы можем просмотреть Traceback вызовов, которые привели к появлению этой группы:
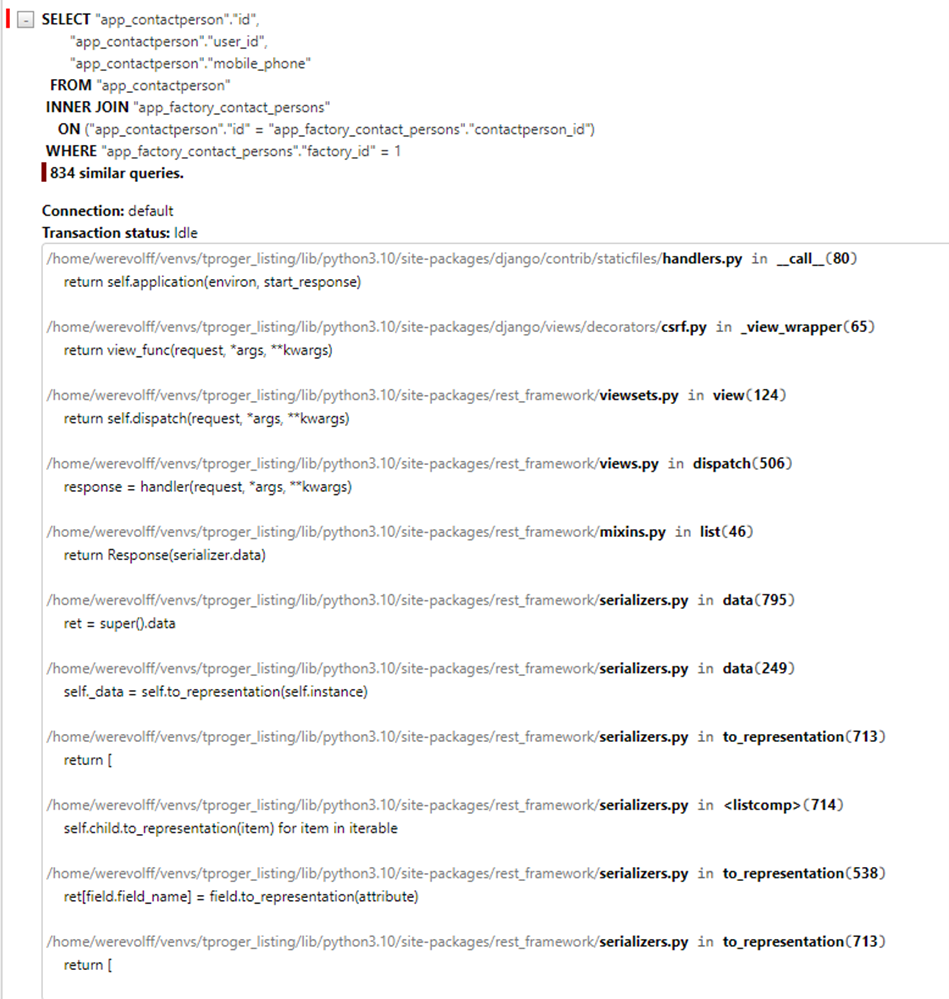
В нашем случае, если источником проблемы является to_representation модуля serializers, то мы говорим об известной проблеме n+1. Дело в том, что в момент, когда мы пытаемся получить данные из связанной модели, ORM отправляет еще один запрос.
Как вы видите, при выводе списка ситуация становится критической. Но мы можем исправить это, добавив для всех связей ForeignKey/OneToOneField правило select_related():
Посмотрите, как изменился оригинальный запрос:
Как вы можете видеть, мы выбрали поля id и name для таблицы, которую присоединили к нашей выборке посредством join. Теперь для получения данных группы заводов не будет создаваться лишних запросов.
Еще мы можем сократить число выбираемых полей, используя .only() и .defer():
Давайте обновим страницу с Debug Toolbar и посмотрим, как изменилась статистика:
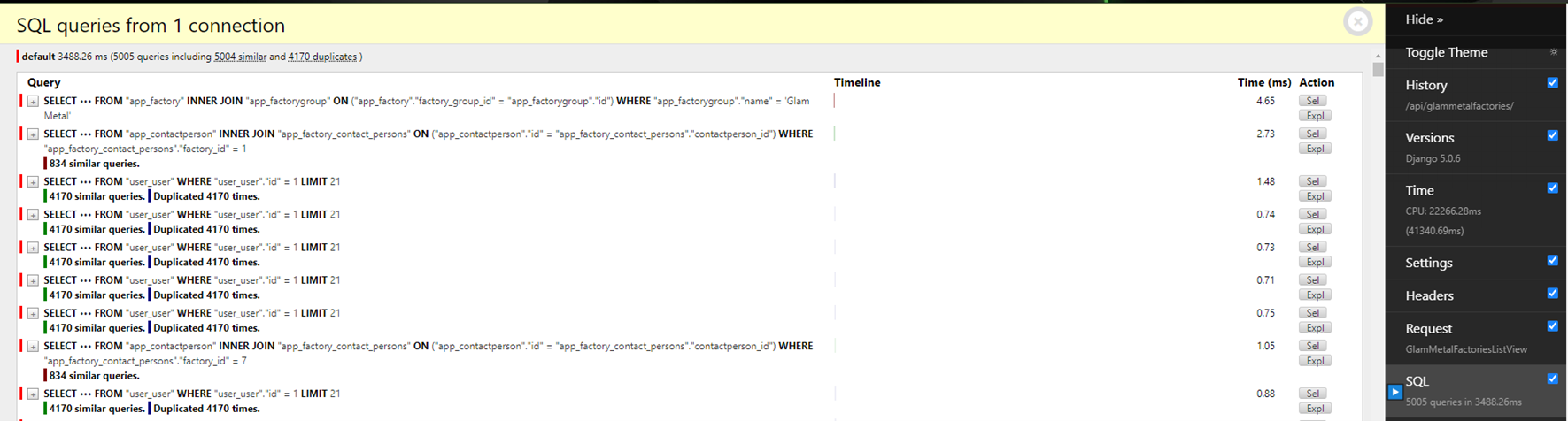
Нам удалось убрать 834 запроса. Теперь очень хочется убрать, например, обращения к User, которых чересчур много. Но, к сожалению, мы не можем этого сделать сейчас, поскольку User — это связь контактного лица, а контактные лица связаны с заводами через связь ManyToMany.
На этот случай Django ORM имеет реализацию паттерна Prefetch:
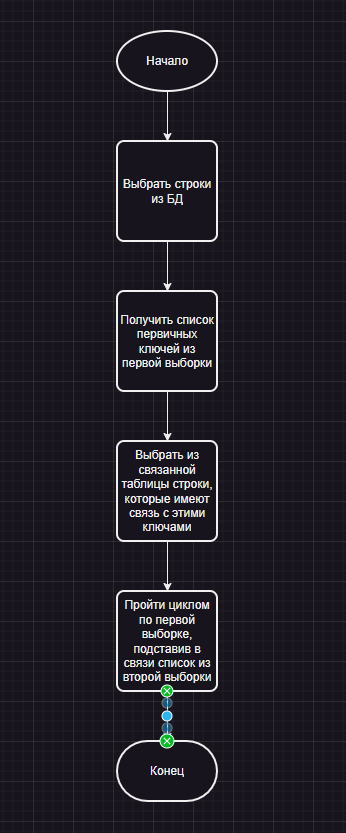
Давайте попробуем:
Если вы посмотрите на SQL-запрос, который порождает эта инструкция, то увидите, что он не отличается от предшественника. Зато, обновив страницу, увидите это:
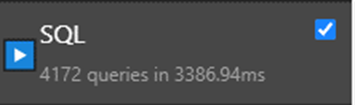
Уже неплохо, но куда делись 833 запроса (что на единицу меньше 834 — общего числа наших записей?

Вот они. Django выполняет алгоритм Prefetch в точности: сначала запрашивает заводы, потом отдельным запросом «вытаскивает» всех контактных лиц. А уже объединение этих данных происходит на стороне python.
Осталась последняя проблема: необходимо избавиться от запросов к User.
Для этого мы должны научиться контролировать второй запрос, выполняемый неявно, для получения контактных лиц. К счастью, Django имеет для этого встроенный механизм — объект Prefetch():
Посмотрим на результаты:
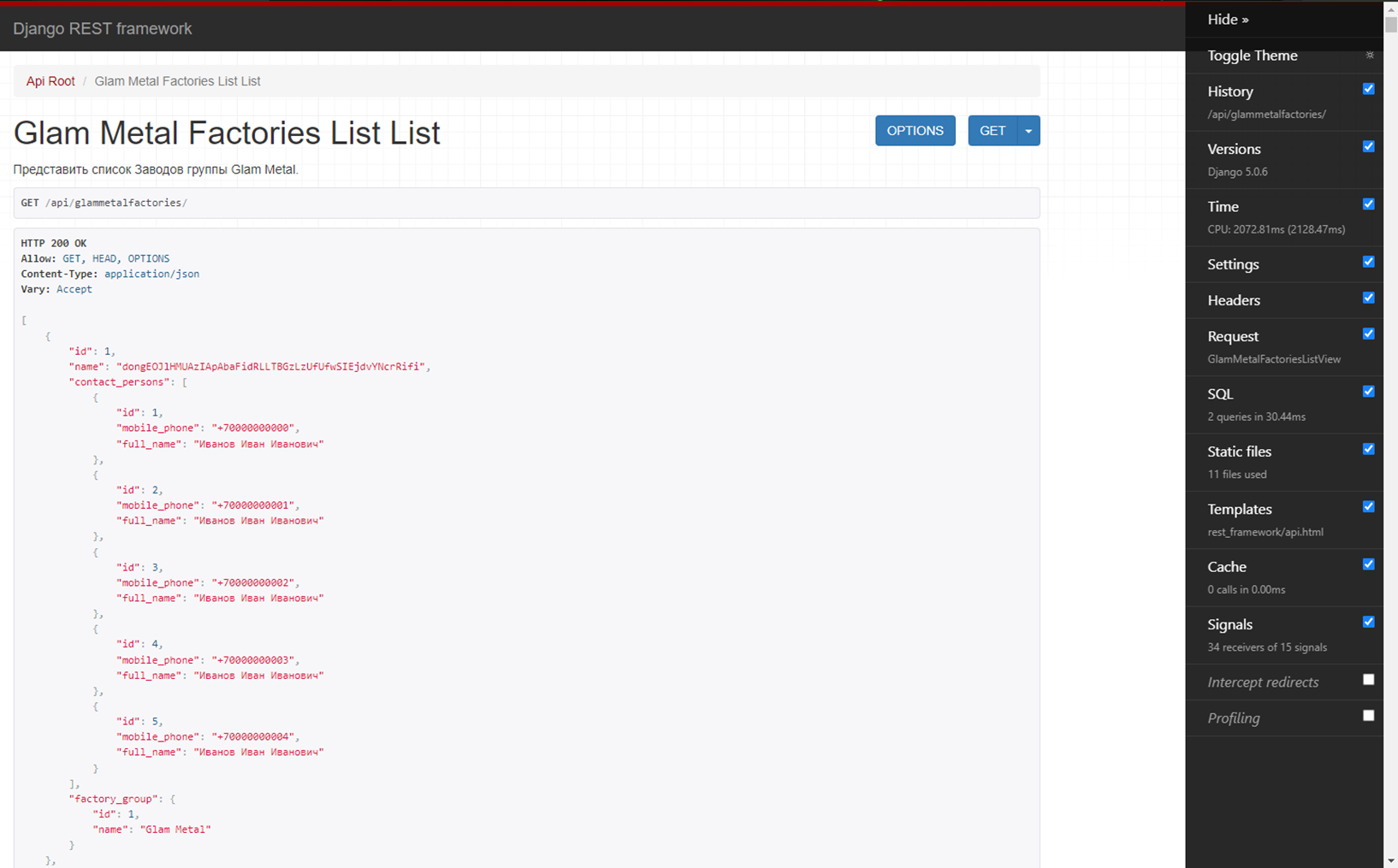
Два запроса, которые были выполнены за 30,44 мс. Посмотрим на запросы:
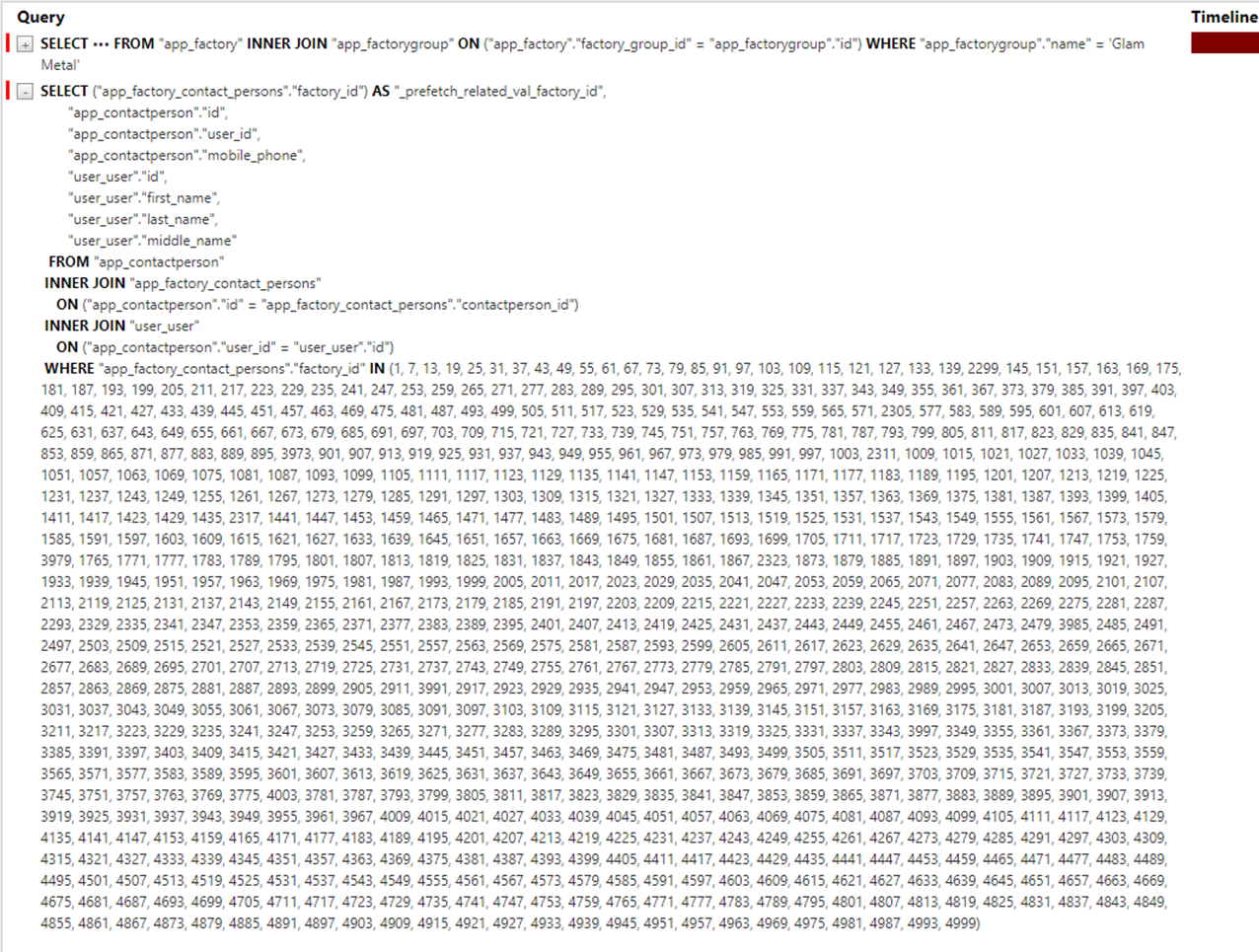
Итак, у нас было 5839 запросов к БД, которые исполнялись на локальной машине 9291,13 мс. Используя Django Debug Toolbar, мы выявили проблемную область и сократили число запросов до двух, а время выполнения — до 30,44 мс.
Тонкости Django
К сожалению, описанная выше проблема встречается в разработке на Django очень часто, поскольку джангисты недолюбливают чистый SQL и игнорируют оптимизацию запросов. Django ORM очень далека от SQL и использует абстракции, непохожие на операторы этого языка. Так, мы видим, что для ограничения полей, выбираемых в SELECT, нам приходится использовать необязательные методы .only()/.defer(). А join’ами мы вообще не можем управлять напрямую (как, кстати, и операцией group_by()).
Эти тонкости требуют от разработчика особенного внимания и достаточной квалификации, чтобы определить болевые точки проекта.
Также могу посоветовать разработчикам на Django, если они используют Pytest, обратить внимание на пакет pytest-django-queries, который предоставляет фикстуру, показывающую количество и состав запросов в БД. Фикстура подключается всегда с обнуленным счетчиком, что позволяет использовать ее как на этапе создания тестовых данных, так и на этапе запуска кода.
Послесловие: о чем мы не успели поговорить?
К сожалению, проблемы ORM — это не единственный недостаток Django. Выше мы видели, как программист использовал property внутри модели, чтобы внедрить в нее бизнес-логику и показать ФИО пользователя. Подобные решения зачастую приводят к ситуации, когда количество запросов к БД растет не из-за отсутствия select_related/prefetch_related, а из-за того, что обращения к БД разбросаны по всему коду. В этом случае исправление архитектурных проблем может затянуться.
При всей своей простоте Django очень чувствительна к организации кода и к архитектурным ошибкам.
Еще один интересный момент — это слабая поддержка асинхронного программирования. Нет, сама Django поддерживает асинхронные операции. Проблема состоит в «батарейках» Django, которые не всегда догоняют коробку по поддержке тех или иных фич. Например, тот же DRF поддерживает async только при добавлении новых зависимостей: adrf или Django-rest-framework-async. Однако ситуация остается проблемной потому, что Serializers не поддерживают async при обращении к .data. И это вынуждает нас использовать иной подход к архитектуре решения. Например, вводить слой Use-Cases, чтобы передавать в Serializers уже подготовленные данные и выносить формирование QuerySet из слоя представлений, где ему не место.
Еще одна сложность Django — это тяжеловесная система Middleware. Многие готовые Middleware совершенно не оптимизированы, и их использование нередко влечет за собой проблемы с производительностью.
Также для Serializers Django лучше заменить движок json на ujson или orjson. Использование простого Serializer вместо ModelSerializer может поднять производительность (но, скорее всего, потребует ввода паттерна Repository для предварительного перевода данных в более простой формат).
В общем, Django — хороший фреймворк. Для средних проектов. Для маленьких он слишком большой. Для больших он слишком медленный и содержит слишком универсальные решения, которые наверняка придется переписывать.
Django хорош для начала больших разработок, когда необходимо быстро реализовать функционал, снизив расходы на сопутствующие работы (например, на реализацию админ-панели, или на авторизацию, или на пагинацию). Однако, начиная писать на нем большой проект, убедитесь сначала, что у вас достаточно квалификации и смелости, чтобы реализовать хотя бы часть функционала самостоятельно, не используя готовых решений.

