


Что такое OpenTelemetry и как она может улучшить качество ваших сервисов
Рассмотрим на примерах, что такое OpenTelemetry, из каких ключевых концептов она состоит, и какие проблемы помогает решить.
13К открытий28К показов
Раньше, когда мы говорили "backend", мы скорее всего имели в виду одно большое приложение с одной большой базой данных, для мониторинга которого было достаточно простого логирования. Теперь, благодаря технологиям вроде Kubernetes, микросервисы стали стандартом, приложений становится больше, приложения становятся распределенными и традиционного логирования уже недостаточно для отладки и диагностики проблем.
Отличным решением для организации мониторинга является OpenTelemetry - современный инструментарий, который можно применять для отладки и анализа производительности распределенных систем.
Эта статья предназначена для профессионалов в сфере IT, стремящихся расширить свои знания в области оптимизации работы бэкенда. Ниже мы в деталях рассмотрим, что такое OpenTelemetry, из каких ключевых концептов она состоит, и какие проблемы помогает решить. Если вам интересно, как OpenTelemetry может изменить подход к мониторингу и отладке ваших бэкенд-систем, повысив их надежность и эффективность – читайте дальше!
Коротко об истории OpenTelemetry
Первыми с проблемой распределенного логирования и трейсинга столкнулись крупные технологические компании еще в конце 2000-х годов. В 2010 году Google опубликовал статью "Dapper, a Large-Scale Distributed Systems Tracing Infrastructure", послужившую основой для разработки компанией Twitter инструмента трейсинга - Zipkin, который был выпущен в 2012 году.
Затем, в 2014 году, появился Kubernetes, который значительно упростил разработку микросервисов и других облачных распределенных систем. Это привело к тому, что все большее количество компаний начало сталкиваться с проблемой распределенного логирования и трейсинга в микросервисах. Для стандартизации распределенного трейсинга был создан стандарт OpenTracing, принятый CNCF, а также проект OpenCensus от Google, решающий ту же задачу.
В 2019 году проекты OpenTracing и OpenCensus объявили об объединении под названием OpenTelemetry. Полученная платформа объединяет лучшие практики, накопленные за много лет, и позволяет с минимальными усилиями интегрировать трассировку, логирование и метрику в любые системы, независимо от их сложности.
Сегодня OpenTelemetry – это не просто проект, это по сути отраслевой стандарт сбора и передачи телеметрических данных. Его разработку и поддержку осуществляет сообщество специалистов и компаний – лидеров рынка, таких как Google, и Microsoft. Проект непрерывно развивается, получая все новые возможности с целью еще большего упрощения процесса интеграции и использования.

А что внутри?
OpenTelemetry - это целый набор практик и инструментов, определяющих, какие сигналы может генерировать приложение для взаимодействия с внешним миром, а также как эти сигналы можно собирать и визуализировать для наблюдения за состоянием приложений и системы в целом. Три основных типа сигналов: трассировка, логирование и сбор метрик. Давайте рассмотрим составляющие части подробнее.
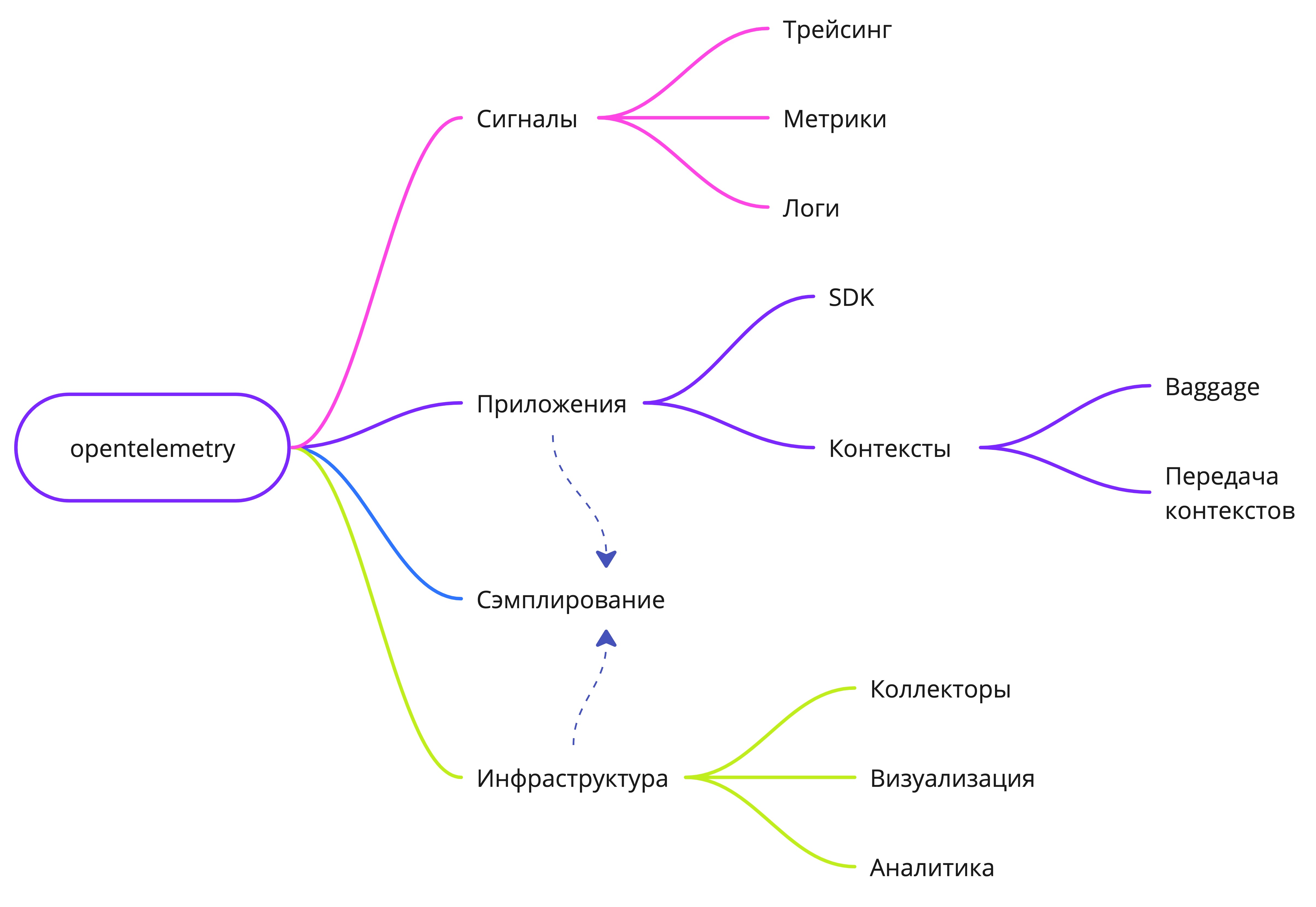
Контексты
OpenTelemetry вводит понятие контекста операции. Контекст в первую очередь включает в себя атрибуты trace_id (идентификатор текущей операции) и span_id (идентификатор подзапроса, при ретраях каждый подзапрос, например, должен иметь уникальный span_id). Кроме того, контекст может содержать статическую информацию, такую как название ноды, на которой развернуто приложение, или название окружения (prod/qa). Такие поля в терминологии OpenTelemetry называются resource и прикрепляются к каждому логу, метрике или трассировке для более удобного поиска. Дополнительно в контексте могут содержаться динамические данные, например, идентификатор текущего эндпоинта ("http_path": "), которые могут быть выборочно прикреплены к группе логов, метрик или трассировок.GET /user/:id/info"
Контексты OpenTelemetry могут передаваться между различными приложениями с использованием протоколов context propagation. Эти протоколы представляют собой наборы заголовков, которые добавляются в каждый HTTP- или gRPC-запрос, или же в заголовки сообщений для очередей. Это позволяет нижестоящему приложению восстановить контекст операций из этих заголовков.
Можно выделить следующие виды передачи контекста:
- B3-Propagation: Это набор заголовков вида
x-b3-*, изначально разработанный для системы трассировки Zipkin. Он был адаптирован в OpenTracing и использовался многими инструментами и библиотеками. B3-Propagation обеспечивает передачу trace_id/span_id, а также флага, указывающего на необходимость семплирования; - На смену ему пришел стандарт W3C Trace Context: Разработанный рабочей группой W3C. Он объединяет в себе практики различных подходов к контекстному распространению в единый стандарт и этот подход является стандартным в OpenTelemetry.
Tracing
Трейсинг - это процесс записи и последующей визуализации таймлайна пути запроса через несколько приложений.
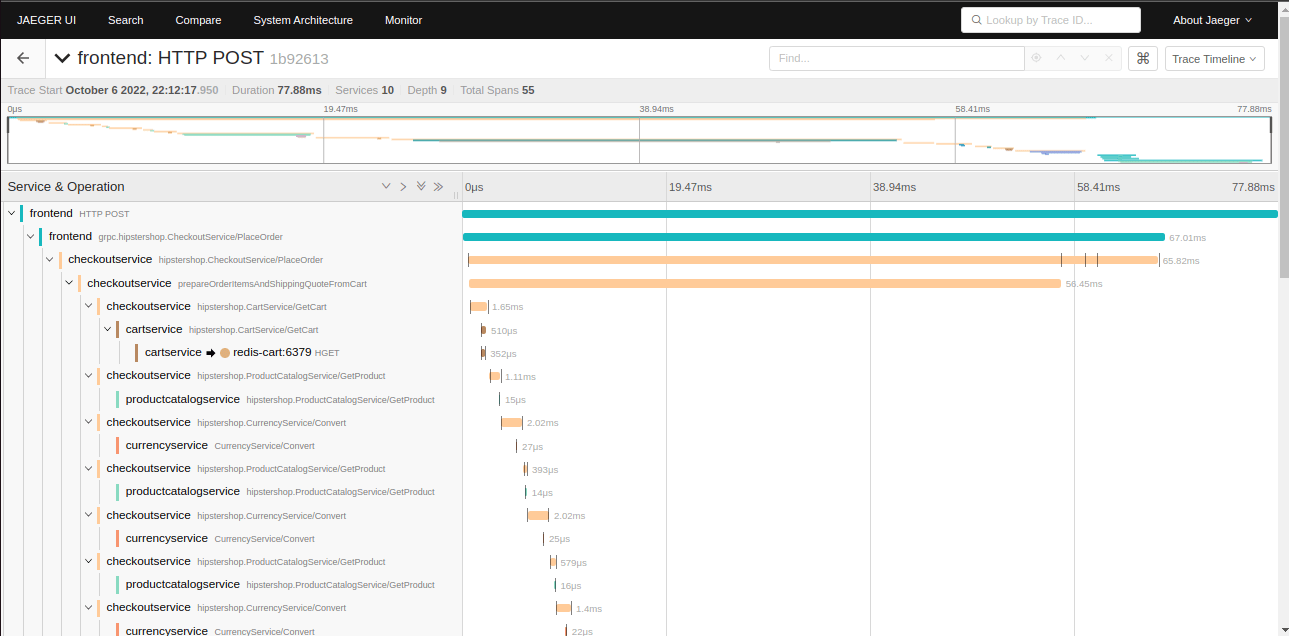
На визуализации каждая полоска называется "span" и имеет идентификатор "span_id". Корневой span называется "trace" и имеет идентификатор "trace_id", который служит идентификатором всего запроса.
Такая визуализация позволяет:
- Анализировать время исполнения запроса на каждой из систем и баз данных и выявлять узкие места, требующие оптимизации
- Выявлять циклические зависимости между сервисами
- Находить дублирующие запросы
Используя данные трейсинга, можно также строить дополнительные аналитики, такие как построение карты микросервисов или распределение времени между разными системами при обработке операций.
Важно отметить, что даже если не используется выгрузка трейсов для визуализации таймлайнов, OpenTelemetry все равно генерирует trace_id и span_id для использования в других сигналах.
Logs
Логирование, несмотря на свою кажущуюся тривиальность, остается одним из наиболее мощных инструментов для диагностики проблем. OpenTelemetry расширяет возможности традиционного логирования, добавляя контекстную информацию. В частности, при наличии открытого трейса к логам автоматически добавляются атрибуты trace_id и span_id, позволяющие связать логи с таймлайном операций. Кроме того, в качестве атрибутов лога можно использовать как статическую информацию из контекста OpenTelemetry – например, идентификатор ноды, так и динамическую информацию – например, идентификатор текущего HTTP-эндпоинта ("http_path": "GET /user/:id").
Используя идентификатор trace_id, можно найти логи всех микросервисов, связанных с текущим запросом, в то время как span_id позволяет разделять подзапросы. Например, в случае ретраев логи от разных попыток будут иметь разные span_id. Использование этих идентификаторов позволяет быстро анализировать поведение всей системы в реальном времени и быстрее диагностировать проблемы, что способствует повышению стабильности и надежности.
Metrics
Сбор метрик предоставляет количественные данные о работе системы, такие как задержки, количество ошибок, использование ресурсов и т.д. Мониторинг метрик в реальном времени позволяет оперативно реагировать на изменения в производительности системы и предотвращать сбои и перегрузки, гарантируя высокий уровень доступности и надежности приложения для пользователей. А интеграция с хорошо известными инструментами, такими как Prometheus и Grafana, позволяет визуализировать эти данные, что существенно упрощает мониторинг.
Коллекторы метрик OpenTelemetry совместимы со стандартами выгрузки метрик Prometheus и OpenMetrics, что обеспечивает возможность легкого перехода на решения OpenTelemetry без необходимости внесения значительных изменений. SDK OpenTelemetry позволяет вместе с метриками выгружать примеры trace_id, чтобы была возможность связывать метрики с примерами логов и трейсами.
Связь между сигналами
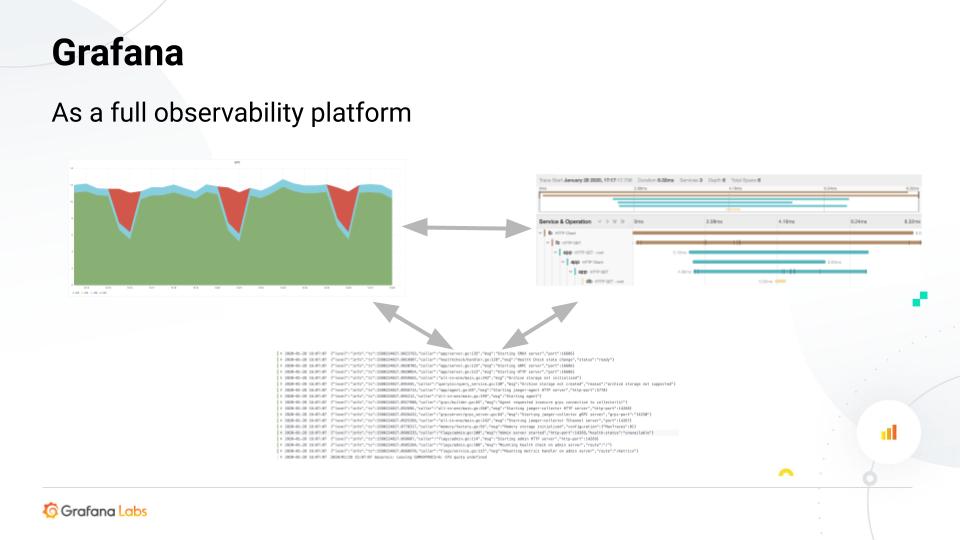
Вместе логи, метрики и трейсинг создают комплексную картину состояния системы: логи предоставляют информацию о событиях в системе, позволяя быстро находить и исправлять ошибки; метрики отражают качественные и количественные показатели работы системы, например, время отклика или процент ошибок; трейсинг дополняет эту картину, отображая путь выполнения запросов через различные компоненты системы, что помогает понять взаимосвязи между ними. Однозначная связь логов, трейсов и метрик – одна из отличительных особенностей OpenTelemetry.
Grafana, к примеру, позволяет пользователю, открывшему лог, увидеть соответствующий трейс и метрики запроса, что существенно повышает удобство и эффективность использования платформы.
Помимо этих трех компонентов, OpenTelemetry включает в себя концепции Sampling, Baggage и управления контекстом операций.
Sampling
В высоконагруженных системах трафик выгружаемых логов и трейсов может достигать огромных значений, требуя невероятных расходов на инфраструктуру и хранение данных. Для решения этой проблемы стандарты OpenTelemetry включают в себя возможность семплирования сигналов – возможность выгружать не все трейсы и логи, а только их часть. Например, можно подробно выгружать только сигналы от некоторого процента запросов или выбрать для выгрузки только сигналы от долгих запросов или только сигналы от запросов, завершившихся с ошибкой. Это позволяет получить достаточную выборку для построения статистики и сэкономить значительные ресурсы.
Однако, если каждая система самостоятельно принимает решения о том, какие запросы мониторить подробно, а какие – нет, мы столкнемся с тем, что будем всегда видеть фрагментированную картину по каждому запросу – некоторые системы будут выгружать подробные данные, в то время как другие могут решить, выгружать данные частично или вовсе не выгружать их.
Для решения этой проблемы механизмы распространения контекста OpenTelemetry передают флаг семплирования вместе с trace_id/span_id. Это необходимо для того, чтобы, если сервис, первый принявший запрос от пользователя, решит, что запрос должен быть выгружен подробно, все остальные системы также должны следовать этому решению и также выгружать данные подробно. В противном случае все системы должны выгружать сигналы частично или не выгружать вовсе, чтобы сэкономить ресурсы. Такой подход называется "Head Sampling" - решение принимается в начале обработки запроса случайно или на основе каких-то входных атрибутов.
Кроме этого, OpenTelemetry поддерживает режим "Tail Sampling", при котором все приложения всегда выгружают все сигналы подробно, но существует некоторый промежуточный буфер. После получения всех данных этот буфер принимает решение о том, стоит ли сохранить данные полностью или оставить лишь частичную выборку. Такой подход позволяет сохранить более репрезентативную выборку по каждой категории запросов (успешные/долгие/ошибочные), но требует настройки дополнительной инфраструктуры.
Baggage
Механизм Baggage позволяет вместе с trace_id/span_id передавать произвольный набор пар ключ-значение, который автоматически будет передаваться между всеми микросервисами по ходу обработки запроса. Этот механизм полезен для передачи дополнительной информации, которая необходима на протяжении всего пути запроса – например, для передачи информации о пользователе или настройках среды выполнения.
Пример заголовка для передачи baggage по стандарту w3c
tracestate: rojo=00f067aa0ba902b7,congo=t61rcWkgMzE,userId=1c30032h5
Вот несколько примеров использования Baggage:
- Передача бизнес контекста операции, такого как userId, productId, deviceId, через все микросервисы. Такую информацию приложения могут автоматически логировать, чтобы получить возможность искать логи любого приложения по контексту юзера, совершившего оригинальный запрос;
- Специфичные настройки параметры для SDK или инфраструктуры;
- Флаги, по который балансировщики могут принимать решение о роутинге запроса – такой подход можно использовать, чтобы автоматически роутить некоторые запросы на mock бекенды во время тестирования. Т.к. baggage передается автоматически – не надо придумывать дополнительных протоколов, достаточно настроить правило на балансировщике.
Важный момент: хотя влияние Baggage на производительность само по себе минимально, чрезмерное его использование может существенно увеличить нагрузку на сеть и сервисы. Тщательно выбирайте, какие данные вам действительно необходимо передавать через Baggage, если хотите избежать проблем с производительностью.
Имплементация
С точки зрения инфраструктуры
Имплементация OpenTelemetry на уровне инфраструктуры требует интеграции бекендов OpenTelemetry в архитектуру приложений и настройки инфраструктуры для агрегации данных и состоит из четырех этапов:
- Интеграция с приложениями. На первом этапе SDK или агенты OpenTelemetry интегрируются непосредственно в приложения для сбора метрик, логов и трассировок. Это обеспечивает непрерывный поток данных о работе каждого компонента системы.
- Конфигурация экспортеров. Собранные данные направляются из приложений через экспортеры во внешние системы для дальнейшей обработки. Это могут быть системы логирования, мониторинга, трассировки или аналитики, в зависимости от ваших потребностей.
- Агрегация и хранение. На этом этапе может происходить нормализация данных, обогащение их дополнительной информацией и слияние данных из разных источников для создания единого представления о состоянии системы.
- Визуализация данных. Наконец, обработанные данные представляются в виде дашбордов в таких системах, как Grafana (для метрик и трассировок) или Kibana (для логов). Это позволяет командам быстро оценивать состояние системы, выявлять проблемы и тенденции, а также создавать алерты на основе созданных сигналов.
С точки зрения приложения
Для интеграции с приложением необходимо подключить SDK OpenTelemetry для соответствующего языка или использовать библиотеки и фреймворки, имеющие прямую поддержку OpenTelemetry. OpenTelemetry часто предоставляет свои реализации широко используемых интерфейсов известных библиотек, что позволяет осуществить drop-in замену. Например, в мире Java для сбора метрик часто используется библиотека Micrometer. SDK OpenTelemetry предоставляет свои реализации интерфейсов Micrometer, что позволяет заменить выгрузку метрик без изменения основного кода приложения. Кроме того, OpenTelemetry предоставляет реализации старых интерфейсов OpenTracing и OpenCensus, что позволяет максимально безболезненно мигрировать на OpenTelemetry.
В заключение
В условиях постоянного развития и усложнения IT-систем OpenTelemetry – ключ к двери в будущее надежных и эффективных бэкендов. Этот инструмент не просто упрощает отладку и мониторинг; он открывает возможности для глубокого понимания работы приложений и оптимизации их производительности на новом уровне. Присоединяйтесь к сообществу OpenTelemetry, чтобы вместе приближать будущее, где каждый из нас может сделать разработку бэкендов проще и эффективнее!

13К открытий28К показов

Даже простейший ИТ-проект способен превратиться в настоящий квест, где исправленный баг моментально оборачивается двумя новыми проблемами. Что с этим делать? Рассказываем в статье.

Узнайте, сколько CO₂ генерирует ваш код в 2025 году и как снизить углеродный след в IT. Практические советы по оптимизации архитектуры, выбору «зеленых» технологий и реальные кейсы компаний. Экологичное программирование — новый тренд для разработчиков и бизнеса.

Самый актуальный список курсов: как они устроены, кому подходят и что получите на выходе

Что такое ArgoCD. Показываем основы работы с ArgoCD. Рассматриваем пошаговую инструкцию и основные нюансы инструмента ✔ Tproger