


Как специалисту по Data Science написать классификатор, если часть данных неверно размечена

Данные важны для аналитики. Однако если они размечены неверно, от них может быть больше вреда, чем пользы. Разбираемся, как работать с такими данными.
8К открытий8К показов

Таня Пучило
ментор курса Wargaming Forge: Game Data Analytics
В разработке ПО в целом и видеоигр в частности важно всегда иметь возможность проанализировать работу системы и поведение пользователей. Для того чтобы аналитики имели возможность собрать информацию и дать полезные рекомендации, а разработчики — воспользоваться этими рекомендациями для улучшения продукта, нужно заранее позаботиться не только о корректном логировании, но и о правильной разметке данных. Так как это не всегда возможно, часть данных не используется при анализе, или, что ещё хуже, на их основе делаются некорректные выводы.
Подход к работе с неверно размеченными данными, описанный в статье, пригодится любому аналитику или датасаентисту, который имеет дело с неверно размеченными данными, но очень хочет использовать их для построения решений, и не ищет лёгких путей.
Что такое неверная разметка и почему это происходит?
Неверно размеченные данные — это данные, метки которых не соответствуют действительности. К примеру, у вас есть набор картинок котиков и собачек, но часть котиков почему-то оказывается собачками согласно разметке. Такая проблема может возникнуть по нескольким причинам: субъективность человека, размечающего данные; ошибки при получении данных, и, в случае косвенной разметки, выбор неверного алгоритма. Очевидно, такие проблемы могут возникнуть в абсолютно любых областях: в медицине, развлечениях, обучении — где угодно.
Я работаю в Wargaming, наша область — это игры. А как известно, в играх проходит множество событий (таких, как акции на какой-либо контент, запуск нового режима), имеющих совершенно разные цели: начиная от привлечения новых игроков, заканчивая монетизацией или повышением их вовлеченности. Проведя очередное игровое событие, вы, как аналитик, получаете следующую задачу: реализовать алгоритм, с помощью которого можно будет прогнозировать участие игроков в подобном событии в будущем. Вы хотите получить инструмент вида:

Входные данные, которые вам доступны, включают:
- характеристики игроков (сколько они играют боев, в каких режимах, какую технику предпочитают и т. д.),
- факт участия игрока в событии (к примеру, совершили ли игроки покупку предлагаемого контента).
Кажется, что ничто не мешает вам обучить алгоритм на основе характеристик игроков для прогнозирования вероятности его участия в событии. Однако во время проведения события что-то идёт не так, и вы понимаете, что часть игроков, которые хотели в нём поучаствовать, не могут этого сделать. Если это покупка — они пытаются её совершить, но не могут, — количество предлагаемого контента ограничено; если это новый режим — они пытаются сыграть в него, но у них не получается зайти в бой по каким-то техническим проблемам. Эти игроки так и останутся в статусе «не поучаствовал, но хотел бы».

Вот незадача! Ведь вам, как аналитику, очень нужны точные данные об участниках события, чтобы использовать эту информацию для обучения алгоритма. А данные, которые у вас есть, выглядят следующим образом:

При этом третьего столбца на самом деле не существует. И нет никакого технического способа проверить, правильна метка или нет. Всё, что вы знаете, — это то, что часть игроков попала в ошибочный класс.
Что делать?
Вариант первый: ничего!
Ну не можем мы обучить модель и сделать прогноз, — бывает. Мы всегда можем посчитать описательные статистики по игрокам-участникам события (к примеру, среднее количество боёв в день) и выделить простые правила для отбора потенциальных участников в новом событии. В случае среднего количества боёв в день, может получиться так, что у группы участников значение метрики в среднем на 30% выше, чем у не участников. Вот мы и будем предполагать, что все игроки, с похожим значением метрики, как у участников события, станут потенциальными участниками следующего события.
Плюсы:
- Просто и быстро.
Минусы:
- Отсутствие масштабируемости или ограниченное количество метрик, которые вы можете охватить. Если речь идёт про 1–2 метрики, использовать правила для них не составит труда. Но в действительности метрик, которые вы захотите сравнить, окажется в разы больше. А если вам вдруг захочется посмотреть на взаимное влияние нескольких признаков, сделать это будет очень сложно и преимущество, связанное со скоростью, уже не будет актуальным.
- Точность/качество. Вы просто не сможете их адекватно оценить.
- Влияние ошибочных данных. Неверно размеченных игроков вы всё же никуда не денете, поэтому их характеристики будут искажать значения рассматриваемых метрик. К примеру, в «не участников» события попадут потенциальные участники, с количеством боёв в день гораздо более высоким, чем у не участников. В итоге среднее значение или другая статистика, будут иметь ошибочно завышенное значение.
Вариант второй: обучить алгоритм на той разметке, которая есть
В качестве вектора признаков для характеристики игроков берём всевозможные метрики, которые приходят нам на ум (включая среднее количество боёв в день), а в качестве целевой переменной — участие игрока в событии, предполагая, что ошибок в данных у нас нет. На этих данных обучаем алгоритм, используя магию машинного обучения, и с помощью полученного алгоритма прогнозируем участие игроков в следующем событии.
Плюсы:
- Масштабируемость. За счёт того, что это алгоритм машинного обучения, вы учитываете гораздо больше признаков и их взаимное влияние на целевую переменную.
- Точность/качество. Теперь-то вы можете оценить качество полученной модели (недаром было придумано такое огромное количество метрик качества методов машинного обучения), однако, скорее всего, то, что вы получите, вас не устроит.
Минусы:
- Влияние ошибочных данных. А качество алгоритма не устроит вас потому, что ошибочные данные всё так же присутствуют в обучающей выборке и оказывают существенное влияние на обучение.
Вариант третий – переразметить игроков и обучить модель на переразмеченных данных
Прежде чем обучать модель на характеристиках игроков и целевой переменной, попытаемся получить новые, более точные, значения целевой переменной. И только после этого, используя обновлённые значения, обучим финальный алгоритм.
Плюсы:
- Масштабируемость. Это всё та же модель машинного обучения, с помощью которой вы учтёте множество признаков и их взаимосвязи.
- Точность/качество. Смотри предыдущий пункт.
- Отсутствие влияния ошибочных данных. Если у вас получилось качественно (а как это понять — будет описано ниже) переразметить выборку, то влияние ошибочных данных на результат обучения будет сведено к минимуму.
Учитывая, что последний вариант имеет наибольшее количество преимуществ и мы не ищем лёгких путей, остановимся именно на нём.
Как найти в выборке неверно размеченные объекты?
Качество финальной модели зависит от двух вещей: от качества исходных данных (в частности — их разметки) и возможностей/настройки выбранной модели. В нашем случае основной упор делается на качество данных, поэтому заниматься оптимизацией характеристик моделей мы не будем. Однако это не повод этого не делать! Чтобы переразметить данные, нам понадобится:
- исходная выборка с «неверной» разметкой,
- несколько разных по архитектуре методов машинного обучения,
- время и высокие мощности вашего железа.
Допустим, исходные данные выглядят следующим образом. Здесь X={x1,x2,…, xn} — вектор признаков, описывающих каждого игрока, а y — целевая переменная, соответствующая тому, участвовал игрок в событии или нет (1 — участвовал, 0 — не участвовал соответственно).
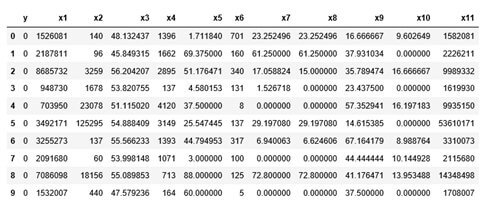
Для начала обучим базовый классификатор для того, чтобы понимать качество модели на неверно размеченной выборке. В качестве классификатора выберем Random Forest и его реализацию в Sklearn.
Посмотрим на качество модели: выведем матрицу ошибок и основные метрики качества.

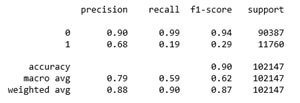
Видим, что качество классификации для 1-го класса, т. е. участников события, очень низкая: recall1= 0,19, а f1-score= 0,29. Средний для модели f1-score= 0,62.
Если бы вы не собирались делать переразметку данных, то вряд ли бы решились остаться на таких результатах, учитывая, что модель практически всех участников события отнесла к тем, кто не будет участвовать. В итоге вы бы вернулись к подсчётам базовых статистик.
Будем надеяться, что вы решили идти дальше. Схематично вся переразметка данных сведётся к следующему. Исходные данные разобьём на N частей с равным распределением объектов из 0-го и 1-го классов. На каждых (N-1) частях обучим 5 или более методов машинного обучения, желательно разных по архитектуре и предсказывающих вероятность. В нашем случае используем уже знакомый Random Forest, а также Logistic regression, Naive Bayes, XGBoost, CatBoost.
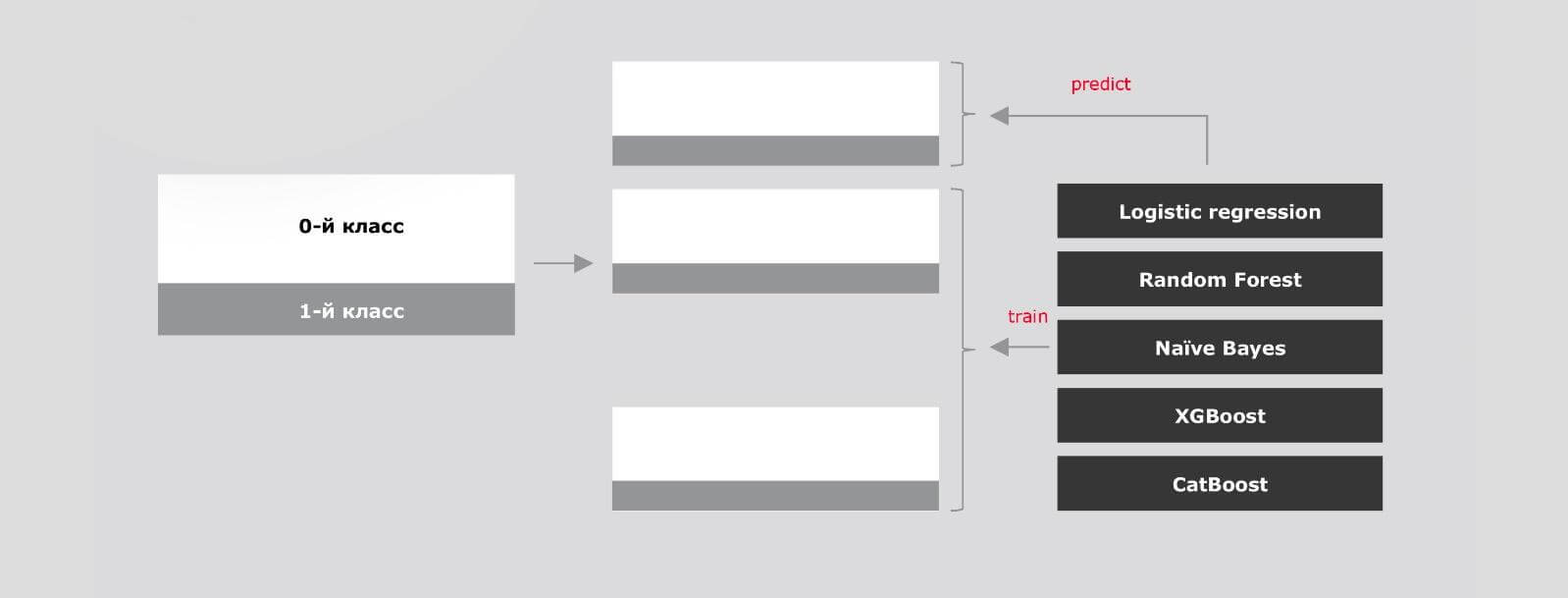
Для этого инициализируем модели с нужными параметрами. Параметры, к слову, уже на этом этапе лучше выбирать путем оптимизации гиперпараметров.
Далее исходные данные разбиваем на 5 частей с равномерным распределением примеров 0-го и 1-го классов.
И наконец, производим переразметку данных, итерируясь по каждой из 5-и частей выборки и используя для прогнозирования каждую из 5-и вышеобъявленных моделей.
В результате переразметки каждая модель предскажет вероятность того, что игрок был участником события. Переразметка целевой переменной происходит в том случае, если все модели предсказали вероятность выше некоторого порога (threshold). В текущем примере threshold=0.5. Данные будут выглядеть следующим образом:

Возникает логичный вопрос: как проверить качество переразметки? Как вариант, построить распределения признаков, характеризующих игроков, в разрезе реальных участников события, потенциальных участников (т. е. тех, кого мы переразметили с 0-го класса в 1-й), и не участников события. В результате вы получите следующее:
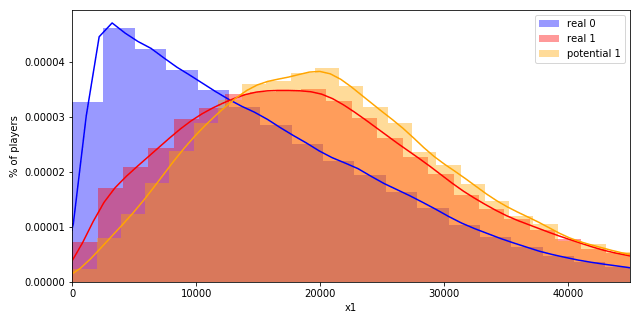

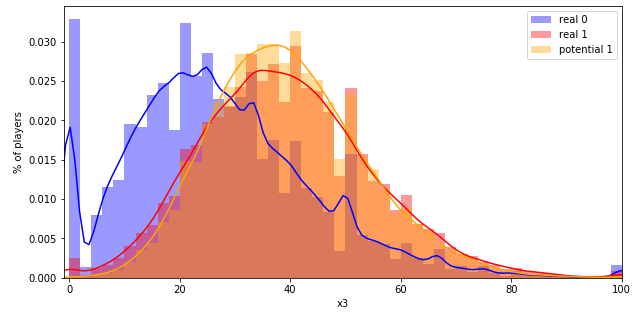

Отчётливо видно, что распределения основных метрик потенциальных участников (в прошлом «не участников») практически совпадают с распределениями реальных участников.
Снова обучаем Random Forest, чтобы сравнить качества моделей до и после переразметки. Также полученную модель уже можно использовать для прогнозирования участия новых игроков в следующем событии.

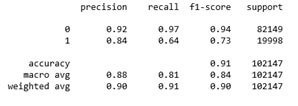
Видим, что качество классификации, f1-score, вырос до 0.84, т. е. на 35%! Также теперь recall1= 0,64, при этом мы не потеряли в recall0. А значит, мы начали гораздо правильнее классифицировать потенциальных участников события.
Что дальше?
Я рассказала об одном из вариантов повышения качества исходных данных. Чтобы улучшить финальный алгоритм классификации, можно ещё поэкспериментировать:
- Финальный метод классификации. Кроме Random Forest можно попробовать другие методы. Также нужно провести оптимизацию гиперпараметров алгоритма и порогового значения вероятности, при котором модель относит объект к 1-му классу.
- Пороговое значение вероятности для переразметки. В нашем примере это значение 0.5. Его можно «двигать» в обе стороны в зависимости от результата, который вы хотите получить: переразметить как можно больше или как можно меньше игроков. В целом,при выборке порогового значения нужно, в первую очередь, руководствоваться здравым смыслом, каким-либо референсом (если он, конечно, есть) и, как было продемонстрировано, используя сравнения распределений основных метрик в фактическом и переразмеченном классах.
- Попробовать другой подход к переразметке выборки. На просторах интернета можно найти реализации переразметки выборки основанные, к примеру, на сегментации. Изначально решается задача обучения без учителя, все данные делятся на сегменты. После этого, каждому сегменту присваивается метка класса, которая наиболее часто встречается среди объектов в данном сегменте. Таким образом, объекты с меткой, отличной от присвоенной, будут являться переразмеченными.
Надеюсь, в вашей работе такие ситуации будут встречаться очень редко, но если и будут, то данный материал окажется вам полезным!

8К открытий8К показов

Глава Microsoft заявил, что ИИ уже пишет до 30% кода в компании. К 2030 году его доля может достичь 95%, особенно в Python

Что такое хэш-таблицы. Показываем основные преимущества хэш-таблиц в программировании. Рассматриваем пошаговую инструкцию и основные нюансы ✔ Tproger

Разбираемся, зачем они нужны и когда их использовать

Продвинутая версия Gemini от Google DeepMind завоевала золотую медаль на IMO 2025, решив 5 из 6 задач. Впервые модель на естественном языке прошла официальную проверку жюри олимпиады — и доказала, что способна рассуждать, как лучшие молодые математики планеты.