Машинное обучение с CNTK от Microsoft: анализ временных рядов

Продолжаем знакомство с библиотекой CNTK. В этот раз мы познакомимся с регрессионным анализом.

Эта часть будет посвящена регрессионному анализу, если быть точным — анализу временных рядов. Чем эта задача принципиально отличается от задачи классификации, которую мы рассматривали в предыдущих 2 частях (первая, вторая)? Тем, что мы исследуем не принадлежность какого-либо объекта классу (собака, кошка и т.д.), а пытаемся построить функцию y = f(x), которая вычисляет значение переменной y (зачастую количественной, например, частота звука, стоимость и т.д., иными словами, — что-то, что можно измерить) в зависимости от входных параметров.
Многие из вас не раз видели подобную картинку:
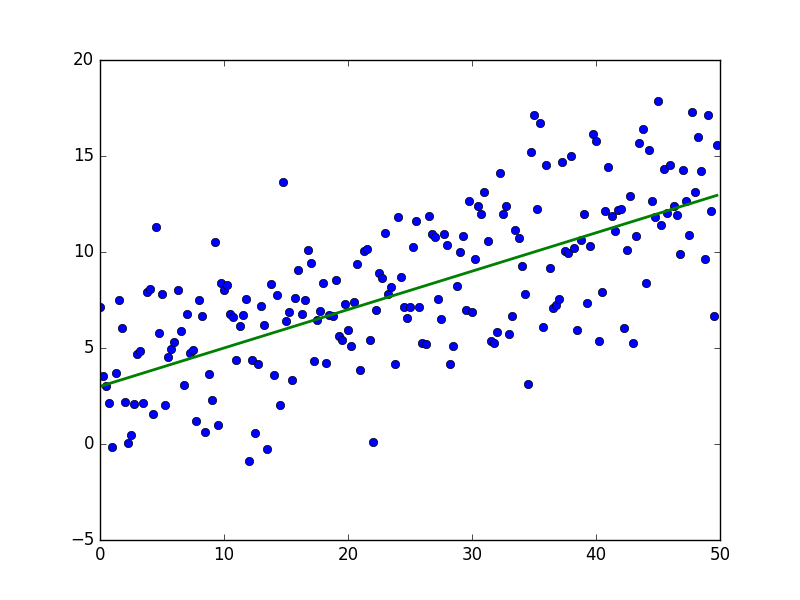
Это обычная линейная регрессия, даже не нейронная сеть, хотя они имеют много общего, можно даже сказать, что это нейронная сеть всего из одного нейрона и без функции активации. Что это значит? Это значит, что, работая с нейронной сетью, сразу можно выявить нелинейные зависимости в наших данных. Одним из примеров выявления нелинейной зависимости является тот же XOR, который строили в первой части. Это «базовые» преимущества нейронной над обычной моделью регрессии.
Помимо этого рассмотрим также предварительную обработку данных при регрессионном анализе и разберемся, зачем она нужна. Для примера возьмем «шаблонный» набор данных Auto MPG, который содержит характеристики автомобилей 70–80-х годов. Исходя из них нужно оценить расход топлива автомобиля при езде в городском цикле. Проводя регрессионный анализ, очень важно понимать, какого типа у нас переменные и под какие типы распределений они подпадают. Пока что импортируем все необходимые модули, загрузим датасет и посмотрим, что там внутри:
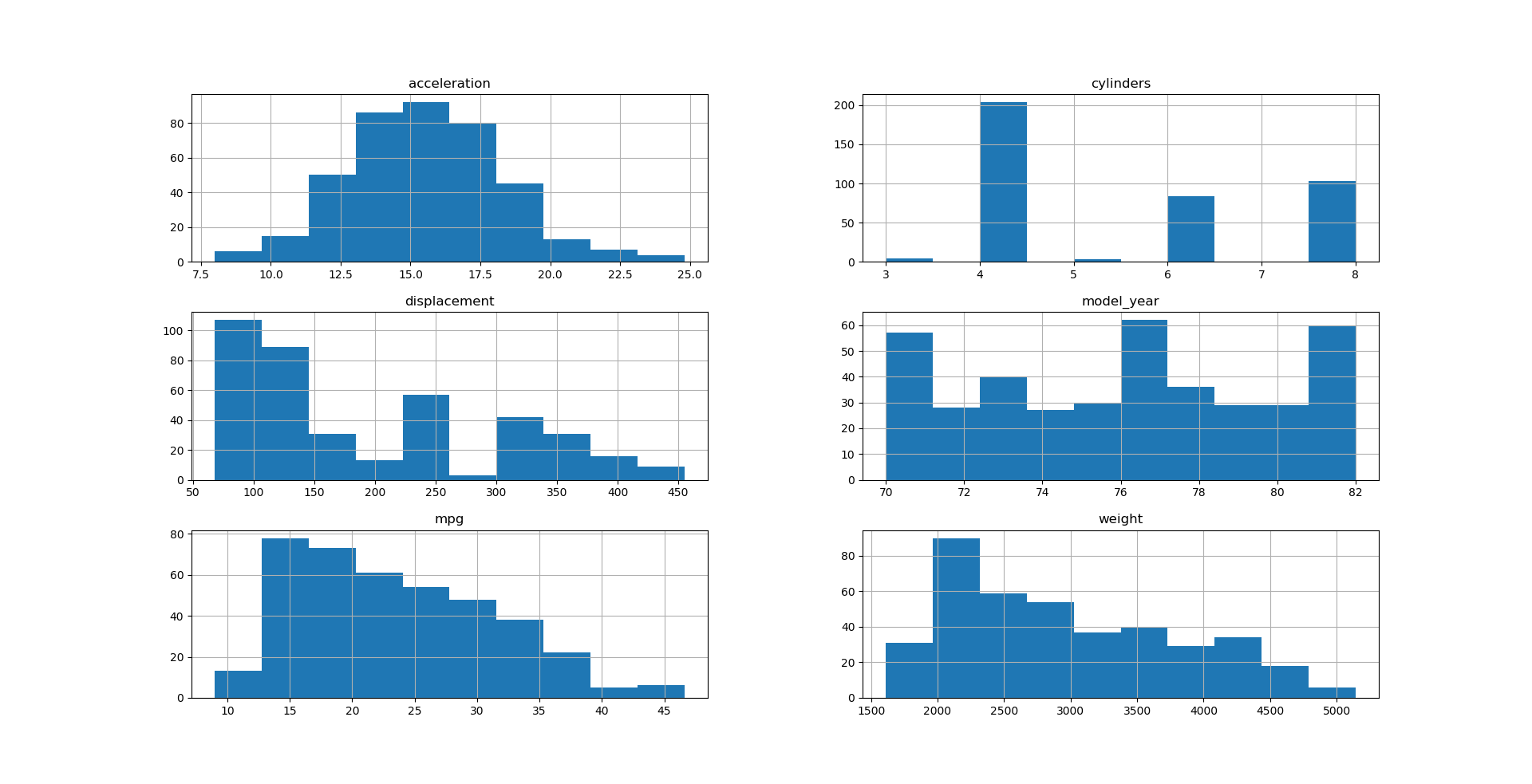
Почему-то нет гистограммы для лошадиных сил (horsepower), почему же? Потому что присутствуют не все значения. Отсутствие и неполнота данных — это вполне нормальное явление, пока для наглядности заменим эти значения на 0 в csv файле.

Теперь по очереди: очевидно, что поле acceleration имеет нормальное распределение, cylinders больше похоже на дискретное, но неравномерное распределение, поэтому над ним будет сложно сделать какое-либо преобразование.
displacement похоже на логнормальное распределение с просадкой между 250 и 300. Потому что не так много двигателей в то время имело объем между 250 и 300 кубическими дюймами (4-4.9 литра).
horsepower — точно так же логнормальное распределение, отсутствующие значения (которые временно заменили 0) можно заменить средним значением, либо же найти соответствующие характеристики автомобилей исходя из объема/года выпуска и т.д.
model_year — то же самое, что и cylinders. mpg и weight, которые имеют логнормальное распределение.
К чему мы сейчас описывали данные так подробно? К тому, что мы будем обучать не одну, а две сети сразу и сравним их в действии. Одна будет учиться на «голых» (raw в англоязычной литературе) данных, вторая получит на вход преобразованные в соответствии с распределениями, описанными выше. Во многих туториалах и гайдах датасет нормализуют или стандартизируют «не глядя», тем самым «ломая» свойства и природу первоначальных распределений.
Попробуем сеть с такой конфигурацией:
Функция активации — SELU (подробнее читаем здесь, очень хорошо описаны свойства каждой из функций, будет полезно «продвинутым» data scientist’ам). CNTK содержит большинство функций активаций из этого списка. Если вы захотите реализовать свою функцию, вам придется не просто создать Function, а работать с UserFunction, вот пример из официальной документации.
Гиперпараметры:
Теперь давайте разобьем данные на тренировочные (70%), тестовые (15%), валидационные (15%) для обычной сети (без предварительных преобразований):
Этой функцией будем преобразовывать дата-фрейм в массив, который сможет понять CNTK:
Далее все как и в предыдущей части: конфигурируем модель, «подвязываем входы и выходы», проводим обучение. Поскольку это модель регрессионного анализа, целесообразно в качестве функции ошибки взять Squared Error. Метод оптимизации — Adam:
Не отходя от кассы, обучим вторую сеть. Но сначала обработаем датафреймы следующей функцией:
Конфигурируем новую сеть:
Проводим обучение:
Теперь самый интересный момент. Сравниваем результаты сетей:
Для наглядности отсортируем значения по возрастанию, для того чтобы было подобие прямой линии (когда увидите график, станет понятнее, зачем это, уже совсем скоро):
Получается следующая картина (синим цветом показаны результаты сети без предварительной обработки на тестовых и валидационных данных, зеленым — с предварительной обработкой):
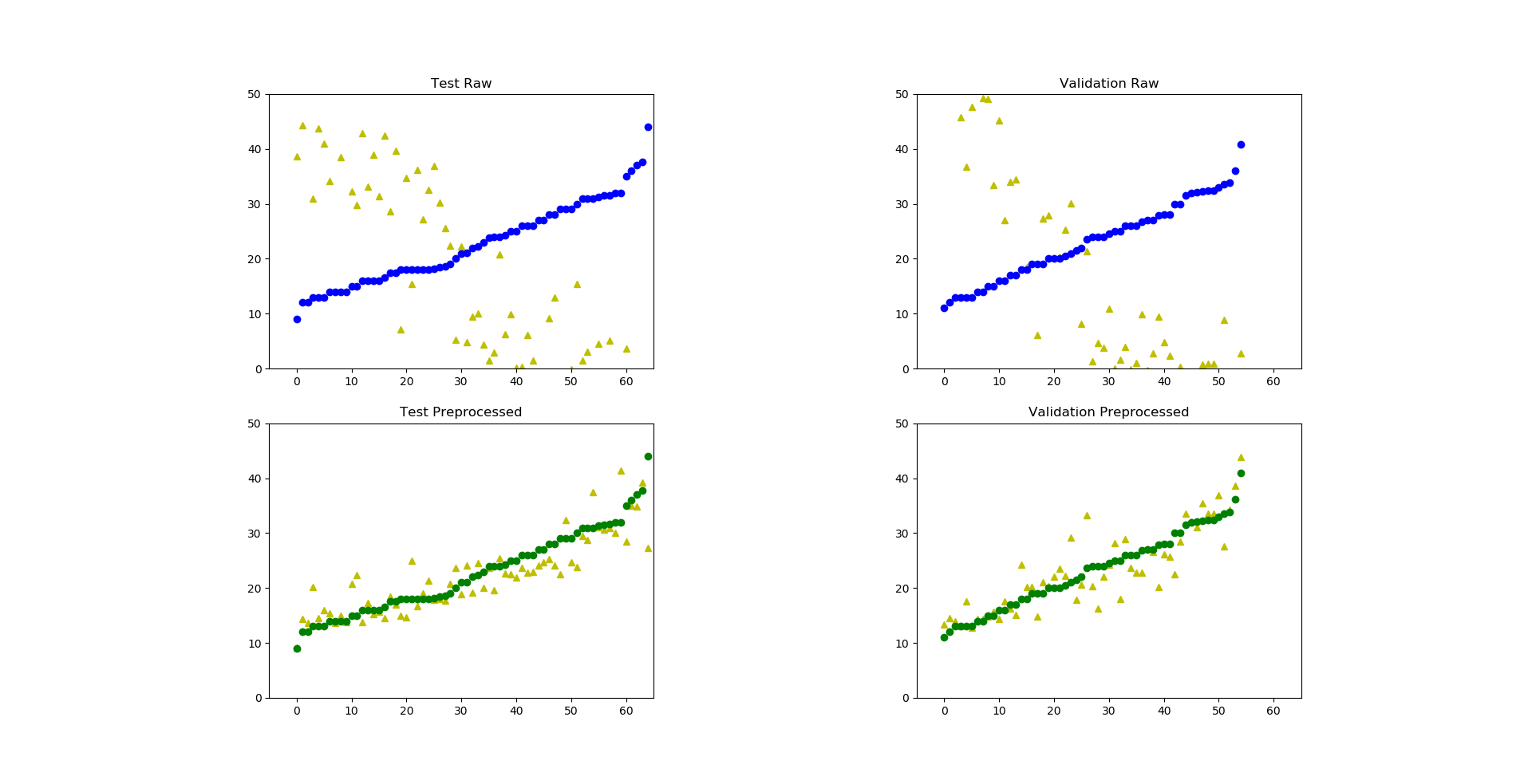
У вас может быть несколько иной, но в целом схожий результат (за счет перемешивания данных при каждом запуске). Очевидно, что сеть без предварительных преобразований даже не смогла обучиться.
Давайте добавим в первый слой еще 25 нейронов:
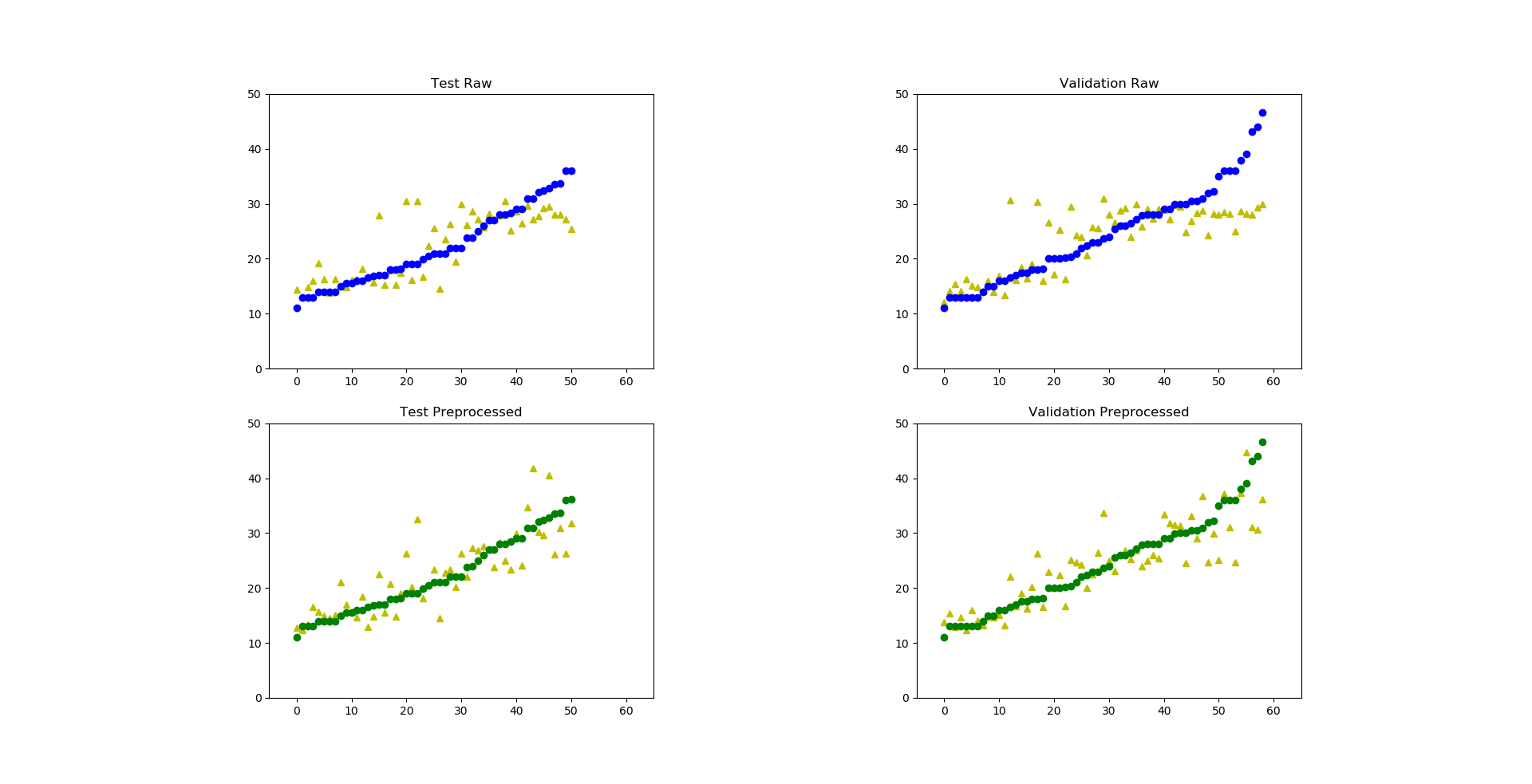
Уже лучше, сети практически сравнялись в точности своей работы. Почему так происходит и что из этого следует? Это проблема сходимости методов градиентного спуска и обусловленность Гессиана, порождаемая нашими данными и сетью. Это весьма продвинутая в плане изучения тема, и если вы хотите понять/разобраться, что вы сейчас прочитали, то рекомендуем также прочитать вот эту книгу.
Продолжение следует…
Авторы:
Александр Ганджа, CTO DataTrading
Богдан Домненко, Data Scientist DataTrading

3К открытий3К показов
Рассказываем, почему C# лучший язык программирования для начала пути в клиентской разработке игр на самых популярных игровых движках.
В этой статье мы указали 30 инструментов на основе ИИ, которые улучшат вашу жизнь и значительно упростят работу.

Разобрали на примере, как начинающим писать тесты для Python-кода и проверять вводимые почты на валидность

Геймджемы — отличная возможность разработать игру за два дня. В статье рассказали, в чем их плюс, как попасть и где найти команду.