


Дата-аналитик и ML-инженер: разбираем обязанности специалистов

Рассказываем, чем занимается ML-инженер на примере задач в Дзене и разбираемся, как с этим связан дата-аналитик.
5К открытий8К показов
Продукт можно разделить на две глобальные части: продакт-менеджмент и разработку. Первая помогает принимать решения, которые основаны на рыночных или внутренних данных компании. Вторая воплощает эти решения в жизнь. Если в продукте пытаются предугадать, что понравится пользователям, и оперируют большим количеством данных, роли разработчика и продуктового аналитика трансформируются в ML-инженера и аналитика данных.

Максим Новиков
Руководитель аналитики ML Дзена
Над какими задачами работает аналитик данных
В построении ленты Дзена есть много аспектов, которые можно совершенствовать.
- Достаточно ли разнообразные документы отображаются?
- Строится ли лента рекомендаций с учётом форматных предпочтений пользователя — текстов, постов или видео?
- Достаточно ли контент увлекательный, чтобы пользователь вернулся в сервис?
- Понимают ли авторы, что нужно делать, чтобы находить своего читателя, «залетать» в широкие рекомендации и набирать подписочную базу?
Аналитик данных исследует все эти вопросы. Он эксперт по измерениям. Его задача не просто предлагать изменения в сервисе, основываясь на своём мнении, а по внутренним и внешним данным выводить метрики, которые растят ML-инженеры и продакт-менеджеры.
Особенность многих задач аналитики в Дзене в том, что нужно держать в голове интересы трёх сторон: пользовательского блока, авторского и бизнесового.
Например, мы хотим начать показывать в ленте больше контента от авторов, на которых пользователь подписался. Это кажется логичным, ведь подписка — это ценный и понятный сигнал. Но если начать разбираться, то могут получиться противоречивые результаты.
Больше подписного контента помогает авторам донести свои материалы до пользователей, а пользователям читать тех, кто им интересен. В то же время можно быстро попасть в «пузырь», когда читатель после нескольких подписок больше не видит материалов других авторов. Одновременно с этим авторы, которые не успели набрать свою аудиторию, не понимают, как им расти и набирать подписки. Это к тому же влияет на выручку компании. И аналитик должен разобраться, стоит ли выкатывать такое изменение, объяснить его влияние на метрики в моменте и спрогнозировать ситуацию в долгосрочной перспективе.
У аналитика много исследовательских задач, связанных с поиском проблем и точек роста сервиса. Например, пользователи, которым нравится гейминг, реже пользуются Дзеном и остаются в продукте. Значит, нужно изменить алгоритмы этой тематики. Для этого нужно сделать deep dive, чтобы понять, чего именно там не хватает. Может, нужно поменять контент или форматы материалов, или привлечь новых авторов, пишущих на эту тему.
Помимо поиска точек роста, аналитик вовлечён в широкий спектр процессов компании. Он оценивает перспективность идей и возможный эффект от них до начала реализации. Для этого он находит метрики, по которым будет приниматься решение о пользе изменения. Если таких метрик ещё нет, то создаёт их и валидирует. Дата-аналитик генерирует гипотезы, проверяет их, проводит A/B тесты, анализирует результаты и выносит свой вердикт.
Аналитик данных может и обучать модель, если она нужна для прогнозирования нужного показателя, но он не углубляется в инженерную специфику. Чтобы выкатить модель в прод, нужны ресурсы разработки. Тогда аналитик ставит разработчикам подробное ТЗ для модели: например, какие данные нужно поставлять, какие ограничения на скорость установить и к какому целевому показателю качества стремиться. Это будут реализовывать уже ML-инженеры.
Какие знания нужны дата-аналитику
- Обладать продуктовым мышлением. Нужно понимать потребности бизнеса и уметь прозрачно доносить свои мысли.
- Делать простые запросы в базы данных, знать SQL.
- Писать простой код на Python для анализа данных и визуализации.
- Разбираться в статистических методах анализа данных.
- Ориентироваться в основах ML: что такое таргет в модели, на основе каких данных она считается.
Такая комбинация hard- и soft-скилов необходима, так как дата-аналитик, по сути, является связующим звеном между продуктом и разработкой. Он помогает ML-инженерам понять, как их изменения влияют на пользователей сервиса и бизнес в целом, а продакт-менеджерам предлагает варианты применения ML для решения задач.
Подробнее узнать требования к роли специалиста по анализу данных можно в вакансиях аналитика качества поиска и аналитика краудсорса.

Андрей Зимовнов
ML-директор Дзена
Над какими задачами работает ML-инженер
ML-инженеры умеют не только обучать модели машинного обучения, но и доводить их до высоконагруженного прода, находя компромисс между сложностью и эффективностью моделей. Они знают, как правильно применять алгоритмы, как эффективно построить систему в проде, чтобы она быстро работала.
Вот как, например, выглядит работа с холодной лентой в Дзене.
Большинство пользователей уже давно присутствуют на платформе. Они лайкают статьи, подписываются на авторов, за это уже можно цепляться и что-то им рекомендовать. И есть пользователи, которые пришли в приложение в первый раз, или пассивные пользователи, которые заходят часто, но никуда не кликают. Для них сложно подобрать рекомендации, потому что информации об их интересах мало.
Для начала контент можно показывать максимально разнообразно по темам. Не будем показывать всем только борщи или машины, покажем микс — может, что-то зацепит. Если есть хотя бы один позитивный отклик на что-нибудь в этой ленте, то уже можно перестраивать рекомендации, используя сложные модели.
При этом также можно использовать внешние данные: какие характерные для своей категории сайты посещает пользователь, например, люди определённого возраста. По визитам в интернете и cookie в браузере можно предсказать пол, возраст и строить дальнейшие рекомендации.
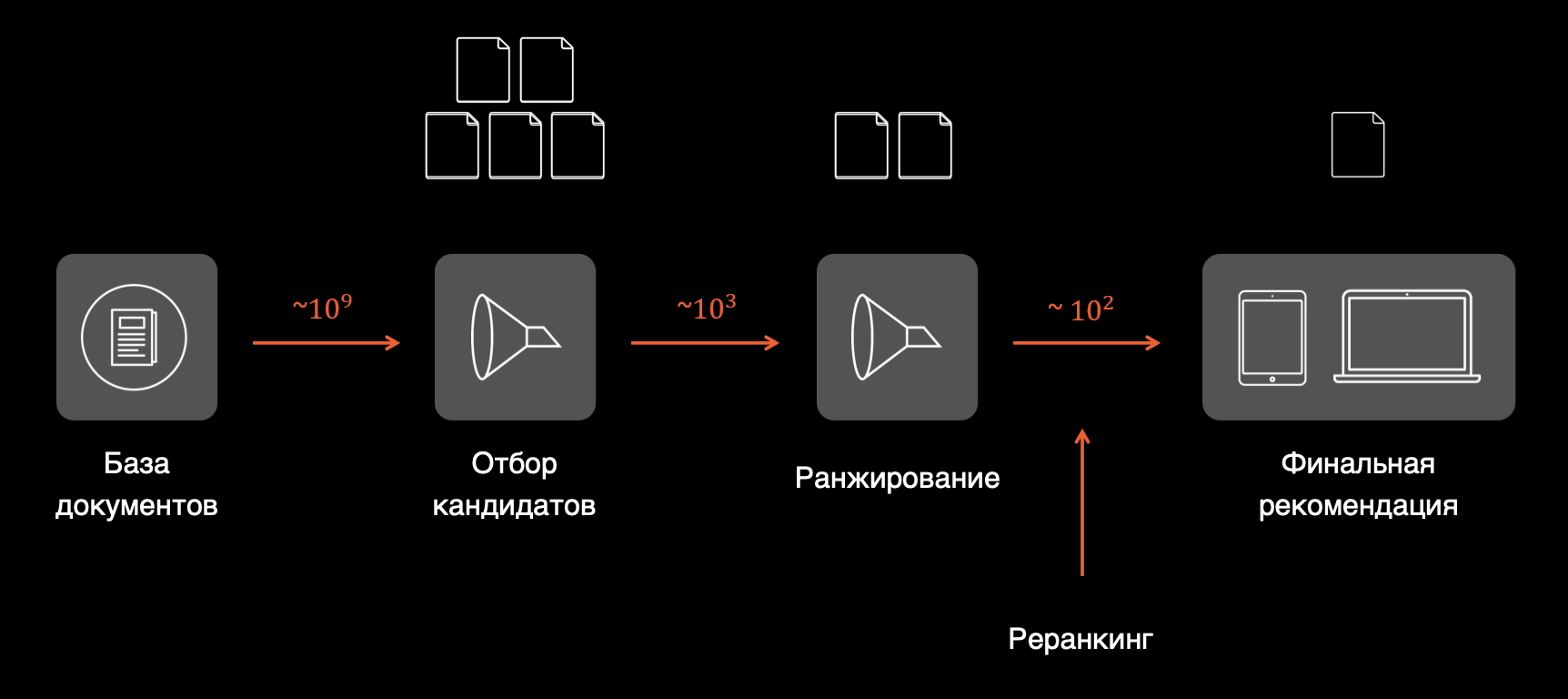
Также ML-инженер умеет подбирать факторы — характеристики, помогающие предсказывать поведение пользователей. В холодной ленте кроме соцдема и быстрой адаптации под пользователя с технической стороны практически больше ничего не нужно. В ленте для горячих пользователей, у которых много кликов, всё интереснее. Нужно из миллионов публикаций выбрать несколько десятков, которые поместятся на экране для показа. Как это сделать?
Мы это делаем в два этапа. Первый — отбор кандидатов. Из миллионов мы находим тысячи грубым быстрым способом: кто что раньше лайкал, смотрел и читал, и подбираем связанные материалы. Они могут быть связаны тематически, или это может быть тот же автор. Второй этап — ранжирование тысяч отобранных кандидатов с использованием более сложных моделей, вроде нейросети и градиентного бустинга. Достаточно за раз отдать пользователю 20 рекомендаций и подгружать дополнительные по мере необходимости, пока пользователь крутит ленту.
Пользователю может быть интересно много разных тем, он читает их с разной периодичностью. ML-инженер должен узнать, что прямо сейчас на этом устройстве в это время суток лучше показать, в каких пропорциях, в каком формате.
Можно проверить такой фактор: как часто пользователь смотрит посты в определённой теме. Допустим, в теме «Кино» он тратит в среднем минуту на показ, а в теме «Искусство» — две минуты. Модель учтёт, что пользователь смотрит чаще, и покажет скорее «Искусство», чем «Кино». Дальше этот фактор нужно внедрить во всю нашу инфраструктуру: добавить этот показатель в обучение модели и на бэкенд.
Какие знания нужны ML-инженеру
- Уметь писать алгоритмы. Важно, чтобы у кандидата было алгоритмическое мышление. Мы можем дать такую задачу: в строке с пробелами некоторые повторены несколько раз, нужно их соединить в один.
- Знать основы машинного обучения. Мы даём проблему, просим поставить задачу машинного обучения, придумать, какие характеристики нужно использовать, чтобы её решить, как оценивать решение, и какие могут быть проблемы при внедрении.
- Писать код на Python для построения моделей.
- Знать SQL-подобный язык для запросов к данным. Например, Hive. Это нужно, чтобы провести первичную аналитику, собрать семпл или построить простые графики.
- Развёртывать модели в продакшене. Мы используем Java, потому что Python медленный. При этом мы не требуем наличие Java на входе, языку мы готовы научить.
Также можно посмотреть, какие ещё навыки нужны ML-разработчику и Java-разработчику в ML-команду.
Для нас ML-инженер — это специалист, который разбирается и в программировании, и в ML. В огромных компаниях с тысячами специалистов в штате бывает и более чёткое разделение обязанностей: кто-то делает прототипы, а кто-то потом их внедряет. Когда команда небольшая, то удобнее, чтобы у специалиста были обе компетенции. Так он сможет и понять задачу бизнеса, и сделать прототип, и довести её до конца — для компании это очень ценный профессионал.

5К открытий8К показов

Получите оффер в VK за два дня
За два года мы переписали инфраструктуру приложения так, что пользователи не заметили перехода. В статье расскажем, как это удалось.
Какие этапы проходит продукт перед тем, как стать MVP, как его тестировать и отрабатывать возражения, если фичу уже внедрили.