Гайд по обработке данных с помощью Pandas: часть вторая
Второй выпуск гайда по работе с библиотекой Pandas. Разбираемся, как эффективнее анализировать данные, и даём список альтернатив.

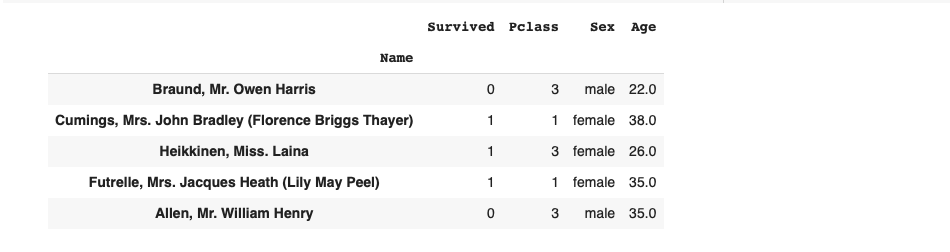
В первой части гайда мы сконцентрировались на азах: разобрались, что такое Series и DataFrame, узнали, какими функциями можно выполнять чтение, запись, объединение данных. Также прошлись по индексам, групповым операциям, разобрались, как визуализировать графики и поработали с временными рядами. В этой части гайда по работе с Pandas мы разберём, как ещё эффективнее использовать библиотеку, а также какие у неё есть альтернативы.

Андрей Дугин
Руководитель группы видеоаналитики MTS AI
Как сделать работу с Pandas эффективнее
Модификация данных на месте
Многие методы Pandas могут принимать флаг inplace, который в случае выставления значения True модифицирует данные на месте, а не создаёт новый объект. Если модифицировать исходные данные некритично, имеет смысл его использовать. Так не произойдёт аллокации дополнительной памяти:

View vs copy
В Pandas, как и в библиотеке Numpy, особое внимание уделяется оптимизации хранения данных в памяти и минимизации лишних аллокаций. Для этого используются «представление» (view) и «копирование» (copy) данных.
Представление — это ссылка или «окно» на исходные данные, через которое можно производить чтение и изменение. Так новые массивы данных в памяти не создаются. Следовательно, модификация данных через представление приведёт к изменению исходных данных.
На контрасте с этим, копирование данных означает аллокацию нового блока памяти и создание дублирующего объекта. Изменения в такой копии не затрагивают исходные данные. Однако чем больше копий, тем ниже производительность кода. В Pandas они часто создаются при выполнении операций срезов данных.
Чтобы определить является ли объект представлением или копией, можно использовать внутреннее свойство ._is_view:






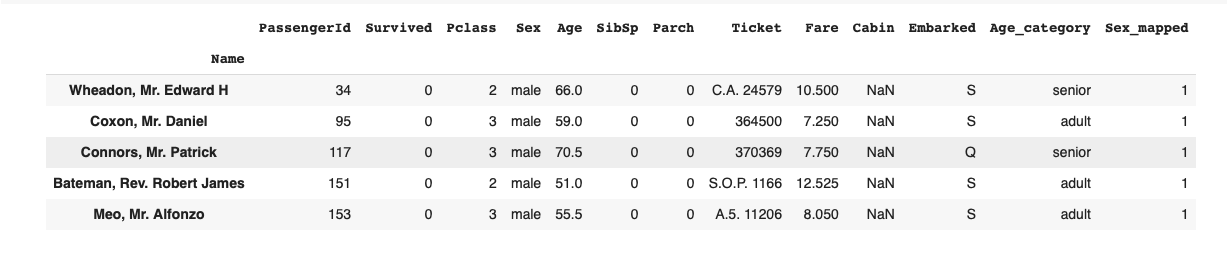
Так как сейчас в датафрейме df все колонки одного типа, Pandas оптимизирует их «под капотом», на уровне массивов Numpy. Но что будет, если изменить тип одной из колонок?




Можно сделать и явную копию:
Тема views и copies в Pandas довольно сложная и понимание приходит с опытом. Если попытаться присвоить значения копии датафрейма там, где по мнению Pandas этого быть не должно, то появится предупреждение SettingWithCopyWarning:

Чтение и обработка данных частями
Если объём данных, читаемых из файла, больше объёма памяти на компьютере, а оптимизация типов данных при чтении не помогла, то бывает эффективно читать и обрабатывать данные по частям, используя параметр chunksize.
Прочитаем CSV-файл частями по несколько строк:

Также можно использовать параметр usecols, чтобы загрузить только необходимые столбцы:
Чейнинг методов
Методы Pandas по умолчанию (если inplace=False) возвращают новый объект (DataFrame или Series). Так, несколько подряд идущих методов можно объединить в цепочку вызовов. Это позволяет избежать использования промежуточных переменных и может улучшить читаемость кода, но влечёт за собой копирование данных и лишние аллокации памяти на каждом шаге. Так что чейнинг эффективен, только если скорость или память не критичны:

Использование query
Метод .query() позволяет писать выражения в упрощённом виде, ссылаться на внешние переменные, использовать альтернативные бэкенды. Так запросы выполняются быстрее и эффективнее:
Что почитать о работе с Pandas
Даже если вы освоили азы работы с библиотекой, всегда найдётся, чему ещё поучиться. В этом вам помогут такие источники:
- Документация Pandas;
- Книга «Python для сложных задач»;
- Статьи на Towards Data Science;
- Статьи на Хабре;
- Разборы и блокноты Jupyter на Kaggle.
Какие есть альтернативы
Мы уже упоминали, что Pandas не всегда может похвастаться своей эффективностью, например, в промышленных проектах. Поэтому следует присмотреться и к другим альтернативам. Вот инструменты, которые также помогают обрабатывать большие данные:
- Pandas 2.0 — новая версия, построенная на эффективном бэкенде Apache Arrow.
- Polars — альтернативная библиотека для более быстрой обработки данных. Написана на языке Rust и использует бэкенд Apache Arrow.
- Dask — похож на Pandas, но разработан для параллельных вычислений и больших наборов данных.
- Modin — использует тот же API, что и Pandas, но производительность у неё лучше за счёт параллелизма.
- Vaex — предназначен для работы с очень большими наборами данных, которые не умещаются в оперативную память. Особенно полезен для визуализации и исследования данных.
- PySpark DataFrame — библиотека для распределенных вычислений, часть экосистемы Apache Spark. Подходит для работы с очень большими наборами данных.
- SQL databases — базы данных, такие как SQLite, MySQL, PostgreSQL, предоставляют мощные средства для работы с табличными данными, хотя и требуют отдельного языка запросов (SQL).
Расскажите в комментариях, какие ещё фишки и лайфхаки по работе с Pandas вы знаете и используете!