


Где точно не стоит использовать ChatGPT
Разбираем минусы и проблемы ChatGPT. А также рассказываем, в каких сферах с ней пока не получится работать.
5К открытий13К показов

Михаил Степнов
Директор по AdTech Big Data МТС
ChatGPT последние месяцы на пике популярности. О нём говорят и пишут, его тестируют в разных ситуациях и пытаются внедрить в продукты — для решения серьёзных задач или ради развлечения. Но действительно ли он так полезен разработчику? И насколько эффективно помогает с повседневными и не очень задачами? Разберём в статье.
Почему ChatGPT оказался так популярен
ChatGPT — продукт на основе языковой модели GPT-4, разработанной OpenAI. До 2022 года специалисты, работающие с нейросетями, были хорошо знакомы с предыдущей версией этого алгоритма, GPT-3, и использовали его для различных задач.
Что так отличает ChatGPT от своих предшественников и делает его таким популярным:
- У ChatGPT интуитивно понятный и удобный интерфейс, позволяющий пользоваться продуктом без особых технических навыков.
- Алгоритмы обучения GPT-3,5 и 4 хитрее, чем у предыдущих поколений. Фундаментального прорыва — как даже между GPT-2 и 3, — конечно, нет. Но объём данных, на которых обучали модель, вырос, появилась возможность работы с кодом и инструкциями.
- В архитектуру ChatGPT добавили RLHF — Reinforcement Learning на основе человеческого фидбэка. Благодаря этому модель может выбирать из нескольких вариантов ответа тот, что с наибольшей вероятностью подойдёт и будет хорошо воспринят конкретным пользователем, основываясь на предыдущих коммуникациях с ним.
Многие видели, как искусственный интеллект играет в компьютерные игры. Это как раз реализуется с помощью Reinforcement Learning, когда модели показывается целевая метрика, например, счёт в игре, и инструменты, которыми она может пользоваться, чтобы менять этот счёт (например, кнопки движения персонажа в игре). Задача алгоритма в таком случае — ситуативно находить решения, которые позволят максимизировать результат.
Насколько серьёзно можно относиться к модели?
На мой взгляд, ChatGPT — в том виде, в каком он существует сейчас — только игрушка, цель которой — привлечь внимание людей и показать им, на что сегодня способен искусственный интеллект. У системы есть свои минусы:
- Модель не может обучаться в real time, а данные загружены вплоть до 2021 года. Поэтому, даже если спросить у версии с GPT-3,5 под капотом, что лучше: ChatGPT-3,5 или GPT-4, — модель скажет, что GPT-4 ещё не существует.

- Модель плохо работает, когда нужен конкретный ответ: назвать исторический факт, найти литературный источник, решить математическую задачу.

- Модель не понимает устоявшиеся выражения, жаргонизмы и иронию.

Поэтому в реальной работе продукт лучше не использовать, постараюсь доказать на примерах.
ChatGPT и бизнес-процессы
Внедрить систему в бизнес-процесс, который требует точности и эффективности — а для корпораций ещё и прозрачности и безотказности — практически невозможно. Потому что модель размещена на сервере где-то в Америке. И никто не может гарантировать, что завтра её не отключат, что она не будет виснуть и так далее.
Кроме того, ответы на запросы всегда нужно проверять — что не всегда реально. Например, мы активно используем рекламные SMS-рассылки. И если подключить к ним ChatGPT, клиентам будут приходить случайные сообщения, которые могут не только не отвечать интересам пользователя, но и вовсе не иметь смысла.

В идеале модель стоило бы дообучить на основе русскоязычной базы данных, «обложить» другой моделью, которая будет прогнозировать CTR этих SMS. Но у нас нет этой возможности, потому что нет доступа к исходному коду.
Microsoft активно использует GPT-3,5 и 4 для своих сервисов, но при этом дообучают их. Так что модели open source такого типа реально применять в процессах, если есть исходный код, который можно доработать под свои задачи.
ChatGPT и службы поддержки
В теории большие языковые модели можно использовать в call-центрах — но их опять же нужно обучить на релевантных данных. Без доработок и объединения с другими системами это сделать невозможно. Модель — такая как ChatGPT — будет только прогнозировать наиболее вероятное следующее слово в ответе. И снова выдаст абракадабру.
Альтернативный вариант — использовать GPT-like модель только для «очеловечивания» поисковой выдачи (поиск может осуществляться, например, с помощью knowledge graphs, не менее захватывающей технологии), чтобы точный результат был облечён в удобочитаемую форму.

ChatGPT и разработка
Один из разработчиков в моей команде пробовал использовать ChatGPT для простых задач и рассказал об опыте.
Действительно, система может сгенерировать код. Но гарантий того, что она напишет его без багов, нет. Причём баги будут спрятаны довольно глубоко, потому что для обучения использовали базу StackOverfow, где в основном запросы типа «У меня не работает этот код, баги не вижу, что случилось?».
Так что, по большому счёту, ChatGPT за секунду генерирует код, который нужно дебажить несколько часов.
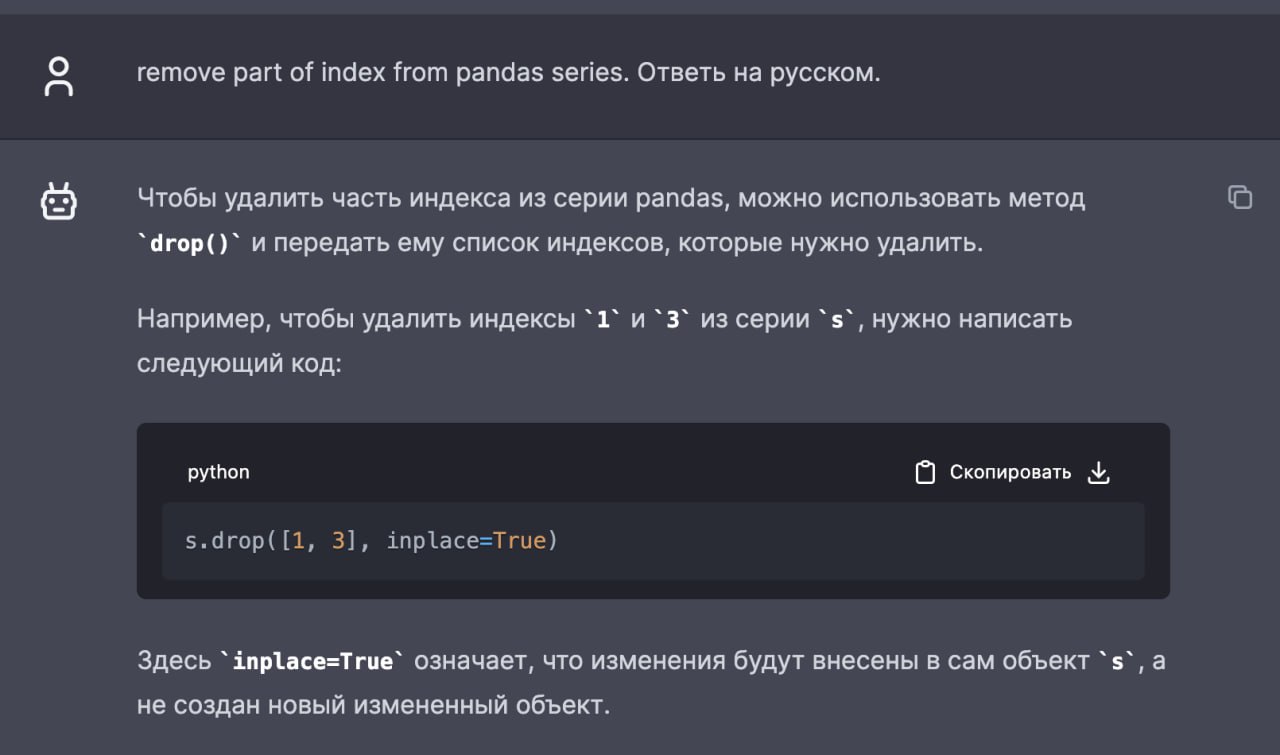
Правильный ответ: s.reset_index(level=[0,1],drop=True)
То есть вместо pandas.DataSeies.drop(), который дропает данные, нужно использовать pandas.DataSeies.reset_index(), который работает с индексами.
На GitHub есть целая коллекция косячного кода, который генерирует система: https://github.com/giuven95/chatgpt-failures.
Что в итоге
По сути, все примеры успешного использования ChatGPT в бизнесе — или просто задачах разработчика — случайность, либо так называемые cherry picking. Человек раз за разом прогоняет одно и то же через модель, пока не получит приемлемый результат и показывает только его. И неизвестно, сколько времени на это тратит.
Кроме того, все якобы сэкономленные ресурсы уходят на то, чтобы поправить ответ. Для определённого бизнеса, например, создания иллюстраций, такой подход может быть нормальным. Но точно не для разработки, когда после генерации кода приходится часами отлавливать баги.
Есть ли у таких продуктов перспектива стать полезными в будущем? Да, причём в ближайшем.
Но на мой взгляд, ChatGPT сейчас — Jack of all trades, master of none.

5К открытий13К показов

«Защитник» определяет, кто звонит пользователю, даже если номера нет в телефонной книге. А также позволяет пожаловаться на спам в два клика.
Начинающие программисты зачастую совершают одни и те же ошибки. В статье рассмотрены самые частые мысли и фразы, которые могут быть у джунов.
Java популярна во многих сферах разработки, и одна из них — backend. Рассказываем, как начать изучать Java самостоятельно и войти в IT.

Книги из этой подборки необходимо иметь каждому начинающему тестировщику у себя на полке. Сохраняйте, чтобы не забыть!