


API на гугловом gRPC: чем хорош и сложности во время работы с ним

Рассказ об опыте и сложностях внедрения gRPC вместе с небольшим введением в технологию.
41К открытий46К показов


Ярослав Брагинец
бэкенд-разработчик в SPD-Ukraine
История началась почти 4 года назад, с началом роста возможностей и сервисов на проекте. Почти каждый из этих сервисов должен был считывать и иногда модифицировать данные, которые касались пользователей системы. Одним из требований была консистентность данных.
Чтобы соблюсти это требование, наша команда решила создать отдельный сервис, который бы давал API с четким набором функций. Согласно специфике проекта этот API должен был быть быстрым и обратно совместимым.
Все мысли сводились к REST API. Но в то же время снова начала набирать популярность технология RPC — вызов удаленного кода на других машинах. Эта технология намного старше, чем REST. Со временем она потеряла свою популярность, пока в 2015 году Google не вдохнул в нее новую жизнь, выпустив фреймворк gRPC.
Введение в gRPC
gRPC – это новый этап эволюции фреймворка Stubby, который разрабатывался в Google более 10 лет. Компания хотела сделать его open-source, но проект не удовлетворял и один из стандартов. Тем временем в 2014-2015 произошел релиз протокола HTTP/2. В Google решили сделать свой фреймворк, базированный на этом же протоколе.
Несколько терминов
- Канал (channel) – длительное соединение.
- Стаб (stub) – клиент, у которого есть три метода:onNext(Message)onError (Throwable)onCompleted()
- Сообщение (message) – структура данных, которая передается через канал.
Обычно коммуникация реализовывается с помощью формата protobuf (формат от Google 2008 года). Основная его специфика в том, что он сохраняет данные в бинарном виде, а ключами выступают числовые индексы, а не имена полей.
Как это работает?
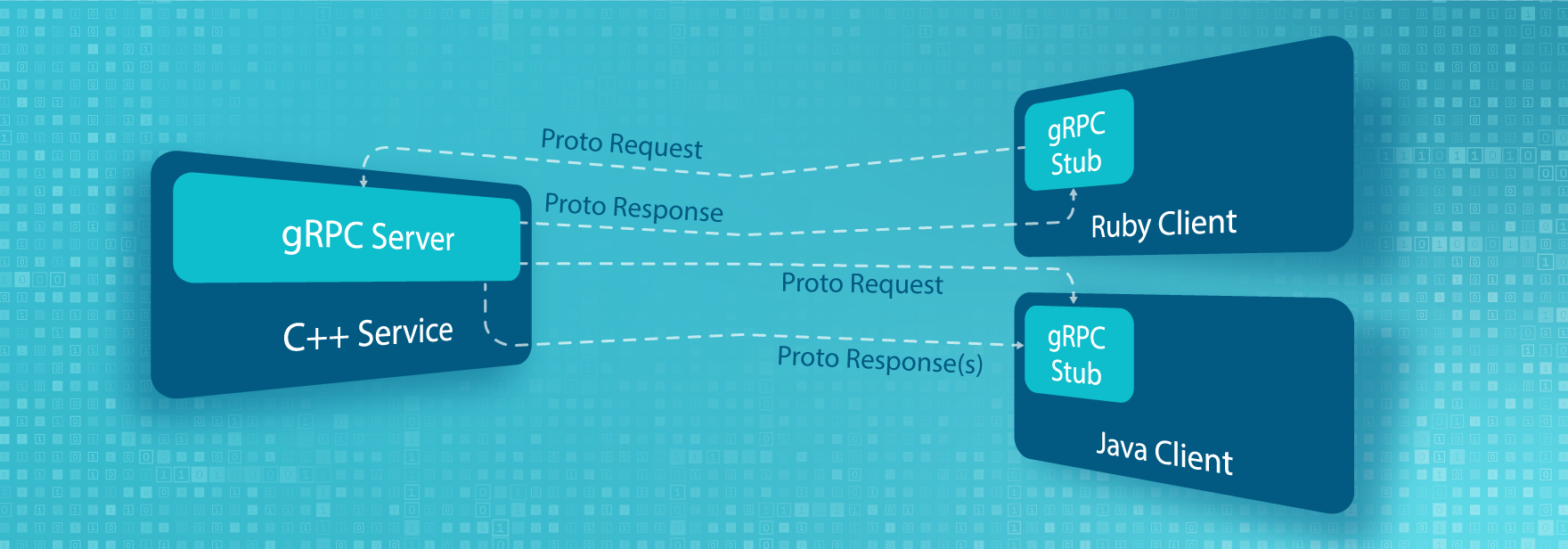
gRPC поддерживается более чем 11 языками (Java, C++, Ruby, Python и т.д.). Плюсом этого является то, что клиент и сервер могут быть написаны на разных языках. Это дает достаточно много свободы.
Для передачи данных используются proto-запросы и proto-ответы. Что такое proto? Это язык разметки интерфейсов, декларативное описание нашей модели и контрактов в целом. Рассмотрим пример.

Каждый сервис имеет имя, список методов (с ключевым словом RPC), входящие данные и результирующие данные. В message тоже есть имя и список полей, имя поля и индекс. И именно индекс используется при сериализация в формат protobuf.
Полноценный клиент генерируется с proto-класса (например, Java-код в нашем случае). Это можно сделать с помощью как отдельного proto-компилятора, так и Gradle\Maven плагинов. Плагин добавляет в проект несколько новых таcок таких, как: generateProto, extractProto и другие. Больше деталей можно почерпнуть с официальной документации.
Вместе с этим вся эта универсальность и крутость чаще всего неочевидна. Поэтому здесь мы делимся опытом нашей команды.
Наш опыт, полон проб и ошибок
Челлендж 1: меньше кода, больше проблем
Рассмотрим hello-сервис, который просто отвечает на приветствие. На вход передается имя того, кого мы хотим поприветствовать, а в результате возвращается сообщение Hello ${UserName}. Описываем proto и генерируем клиент и сервер:
server
client
На клиенте запрос выглядит примерно так:

Обратим внимание на сгенерированный код — потеряна информация о том, что сервер ждет в запросе. Нет никакой информации об именах параметров, есть лишь типы параметров. Зная тип, тяжело угадать, что клиент должен указать в запросе — UserName или адрес. Что делать? Использовать свою модель для каждого метода. На первый взгляд, это нарушение DRY-принципа, но не стоит спешить с выводами.
Введем hello-запрос и hello-ответ. Proto-описание выглядит приблизительно так.
server
client
Мало что изменилось, но на клиенте уже есть намного больше информации для построения запроса. Есть информация о полях, поскольку названия полей сохраняются после компиляции кода. Запрос стал более понятным.
Надо отметить, что интеграцию структуры данных мы сделали полностью обратно совместными. Если в месседже первым полем выступает тот же тип данных, который был у нас до этого, вместо всего месседжа (string в нашем случае) можно заменить один тип данных на другой (помните, что ключами выступают индексы полей и не более?).
Челлендж 2: необязательные поля
Продолжим рассматривать вышеупомянутый сервис приветствия. Теперь на вход он получает имя и флаг, есть ли у пользователя домашний любимец — кот. В зависимости от этого сервер будет возвращать сообщение «покорми кота» или «заведи кота».
Попробуем вызвать наше API:
Вот оно! Со временем находится пользователь, который не указал в запросе этот параметр и в ответ получил сообщение Hello Johny, Please get cats! Мы, не зная есть ли коты или нет, дали рекомендацию. Чтобы это исправить, добавим проверку.
Как видим, не все работает так, как бы хотелось. Почему? В gRPC все поля не nullable — то есть они имеют альтернативные значения, как значения по умолчанию. Таким образом все, что не передается, есть равным такому значению, которое по сети не передается в целях оптимизации трансфера. Так что для проверки наличия поля в запросе необходимо использовать методы сгенерированные прото-компилятором во время построения модели с прото-файла, например hasCats().
Челлендж 3: необязательные поля перечислений
Продолжим дальше. Давайте дополнительно на вход передавать пол пользователя. В зависимости от пола генерируется ответ с использованием обращения Mr/Ms.
Аноним решил не указывать свой пол и получил ответ с обращением Ms, что некорректно. Стандартным значением enum в gRPC выступает значение под нулевым индексом. То есть если не указывать это поле в запросе, то на сервер приходит enum со значением поля с нулевым индексом. Для этого необходимо всегда резервировать нулевой элемент с названием unspecified. Тогда сервер сможет корректно распознать — если пришел unspecified, то пол не был указан.
Челлендж 4: уникальность перечислений
Это еще не все с типом перечислений. Давайте введем еще один enum — регион, где живет персонаж (север, юг, запад, восток или не указано). В этот раз у нас не проходит даже компиляция.
Причиной этого является все та же универсальность gRPC — фреймворк поддерживается более чем 11 языками. Все эти реализации должны быть совместимы. И вот на C++ реализация enum выглядит не так, как на Java. Там нельзя делать значения двух enum одинаковыми, если они находятся в рамках одного пакета. Google рекомендует добавлять префикс с именем до каждого значения. Поправим это и у нас:
Компиляция происходит.
Выглядит не очевидно и немного излишне, но это помогает делать наш сервис совместимым с реализациями на разных языках и не связывать руки разработчикам одним стеком технологий.
Челлендж 5: тайм-аут первого запроса
День за днем случайным образом начал падать первый запрос на сервер в разных приложениях. Причину долго не могли понять. Рассмотрим самый простой вариант, где на запрос выделяется одна секунда:
Оба запроса вкладываются в одну секунду. Уменьшим лимит времени:
Как видим, обработка запроса укладывается даже в 500 миллисекунд. Идем дальше и уменьшаем лимит на первый запрос.
Первый запрос не укладывается в лимит времени. Другой успешно завершился. Хотя лимит времени у обоих был одинаковый.
Оказалось, что в gRPC соединение инициируется в ленивом режиме. То есть оно начинается только в момент первого запроса. Чтобы соединение инициировалось не с первым запросом, а раньше, можно использовать такой метод канала как getState с аргументом true. getState возвращает состояние соединения с сервером, а флажок true показывает, что нужно инициировать соединение, есть его еще нет.
Таким образом уменьшается шанс того, что первый запрос не уложится в лимит времени. Но все еще есть вероятность, что первый запрос будет падать сразу после того, как вызвать метод getState. Такой метод принужденной инициализации связи рекомендует Google в своем GitHub репозитории. Но не стоит недооценивать форумы по gRPC, которые являются большим источником информации.
Челлендж 6: тайм-аут последующих запросов
Разобравшись с падением первого запроса, иногда все еще падали реквесты в случайном порядке. Какой-то закономерности не прослеживалось. Например:
Оказывается, когда мы указываем лимит для нашего запроса, отсчет времени начинается уже с момента вызова метода withDeadline. Соответственно построение сообщения уже входит в этот лимит времени. Иногда подготовка запроса занимает некоторое время. По этому все построения месседжей рекомендуется выполнять еще до момента указания дедлайна запроса. Наш запрос начал работать, когда мы переделали его следующим образом.
Стоит упомянуть, что дедлайн указывает граничное время выполнения запроса относительно UNIX времени. То есть нужно быть готовыми к приключениям, если на сервере часы «спешат» или отстают относительно клиентов. В общем данная особенность была выявлена благодаря IDE, которая постоянно предлагает «заинлайнить» переменную, если она используется только один раз.
Челлендж 7: возврат ошибок
Чаще всего на сервере есть валидация данных перед их обработкой. Например, обновим наш сервис, чтобы он не приветствовал Луиджи. В gRPC для этого используется метод onError. Соответствующая валидация на сервере возвращает IllegalArgumentException. Клиенты, которые вызвали этот API с аргументом Луиджи, получали не многословный ответ — unknown status, а в логах сервера красовался непонятный exception.
Server:
Client:
В чем же дело? На примере выше сервер всегда пытается вернуть результат (onNext и onCompleted), несмотря на то вызывался onError или нет. Как указано в документации, onError — для ошибок, а пара onNext и onComplete — для успешного выполнения. Одновременно их использовать нельзя (было бы хорошо ловить это еще на этапе компиляции). Соответственно нам необходимо завершить наш метод после того, как мы вернули ошибку через метод onError. После минорных изменений на клиенте уже получаем ошибку с понятным статусом и информативным сообщением.
Server:
Client:
Челлендж 8: удаление поля
Со временем некоторые данные в запросах и ответах становятся не актуальными, и их необходимо удалять или заменять на новые. Например, удаление поля name можно было бы реализовать следующим образом:
Но что случится, когда придет новый разработчик и захочет добавить новое поле? Какой индекс он будет использовать? Скорее всего следующий свободный индекс — 2! Но старые клиенты все еще могут ожидать, что под индексом 2 будет приходить старое поле name — то, которое мы удалили. Если же сервер начнет возвращать какой-то регион, это сделает сервер не совместимым со старыми клиентами. Решить данную ситуацию можно просто закомментировав поле. Со временем список может разрастись, и будет легко проглядеть, какие индексы были заняты, но сейчас закомментированы, а какие нет. Пример ниже успешно компилируется, а клиенты будут получать неожиданные ошибочные значения.
Корректным вариантом будет резервирование полей и уменьшение рисков, перенеся проверки с разработчика на компилятор. Это реализовывается с помощью ключевого слова reserved. Важно то, что стоит резервировать не только индекс поля, но и имя. Это необходимо, чтобы никто позже не использовал повторно ни индекс, ни имя через годы эволюции проекта.
Челлендж 9: стрим более 1 млн сообщений
Еще одна неожиданность — это стриминг. Так как gRPC построен на HTTP/2 протоколе — поддерживается возможность стриминга как из сервера, так и с клиента. И даже больше — стриминг в обе стороны. IDL для стриминга с клиента на сервер будет выглядеть следующим образом.
Однажды нам пришлось переслать с клиента на сервер 1 миллион сообщений. Во время запроса появилась интересная ошибка — OutOfMemory.Direct buffer memory:
Что мы делаем, когда видим OutOfMemoryError? Увеличиваем объем хипа. Сначала подняли до 4GB. Это позволило нормально стримить 1,25 млн сообщений. Дальше 8GB и 2,5 млн. Но все равно была граница, когда падал OutOfMemory.
Немного предыстории. Еще со времен Java 1.4 в JVM в придачу к хипу появился дополнительный блок памяти NativeMemory. Эта область оперативной памяти намного эффективней в плане ІО в сравнении с хипом. Когда передаются данные через ІО, эти данные не попадают в хип, а взаимодействуют напрямую с оперативной памятью. Таким образом эффективнее используются ресурсы сервера. Интересно, что в коде она указана 64 Мб, но выше в документации значилось, что это значение не влияет ни на что, а ее объем равен объему хипа (контролированный аргументом запуска JVM Xmx).
Но объем памяти, который контролирует direct memory, можно модифицировать отдельно — с помощью аргумента MaxDirectMemorySize. Указав его равным в 4GB, 1,2 млн сообщений проходило хорошо, а потом та же ошибка. Интересно, что при 12 мегабайтах, стриминг проходил успешно даже для 2-3 млн элементов, но эффективность работы самой JVM значительно падала. Это связано с тем, что все процессы с IO разделяют эти 12МB, и этого мало.
Причина кроется немного глубже. JVM присылает в очередь на сетевой адаптер сообщения, пока они не закончатся или не исчерпается память. В gRPC это можно решить, ограничив отправку новых сообщений до того момента, когда сервер будет готов их обрабатывать. Это называется flow control. Клиент теперь будет выглядеть следующим образом:
Сначала надо отключить стандартное поведение и описать логику, когда можно отправлять новый элемент. Например, в нашем случае мы сделали передачу по одному сообщению — то есть не передавать следующее сообщение, пока сервер не получит предыдущее от клиента. При необходимости можно отправлять пачками. Таким образом задача стриминга большого количества сообщений больше не приносить проблем.
Челлендж 10: каша из зависимостей
Со временем все больше и больше наших сервисов реализовывались с помощью gRPC. Для удобства каждый из этих сервисов предоставлял свой java-клиент, который подключался на пользователях. В скором времени транзитивные зависимости дали о себе знать.
В одного чудесный день загадочным на тот момент образом во время запуска падала ошибка INTERNAL: Panic! This is a bug! Быстрый поиск показал, что эта ошибка возвращается в одной из gRPC библиотек. Попытка перейти к реализации не завершилась успешно. Оказалось, что в ClassPath проекта было несколько разных версий одних и тех же библиотек.
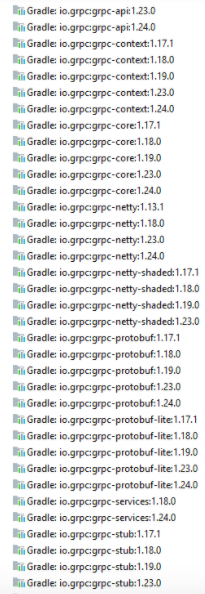
Объяснение этому следующее. Подключено три клиента от троих сервисов, где один клиент сгенерирован с gRPC версии 1.17, другой — 1,20, третий — 1.21. Как оказалось, не всегда код, сгенерированный разными версиями компилятора, совместим. Мы это решили так называемым Monkey-Patch — принудительное использование определенной фиксированной версии транзитивных зависимостей. Таким образом на консьюмере использовалась всегда только эта версия транзитивных зависимостей.
От этого не элегантного решения надо было избавляться, и что-то решать с первопричиной — клиентами. Приняли решение адаптировать систему на публикацию только контрактов вместо готовых клиентов. В случае с gRPC это протофайл. Консьюмеры же генерируют себе с этого файла код уже с их версией компилятора. На первый взгляд, это приведет к дублированию кода между проектами. Но не забываем, что это автосгенерованный код, который не содержит бизнес-логики и не требует ручных модификаций.
Неудобства использования gRPC
Более сложный процесс проверки качества
Когда команда тестировщиков вошла в работу, то сразу отметила, что в отличии от REST, запросы нельзя затриггерить с браузера. Браузер не умеет превращать JSON в бинарный формат, с которым работает наш gRPC сервер. Для этого нужна прослойка, которая выполняла бы эту адаптацию. Мы это реализовали с помощью отдельного Gаtеway сервиса (по типу Swagger-UI) и библиотеки Vertex. Сервис переводит входящие данные в бинарный формат, далее отправляет на gRPC сервер, так же и в другую сторону. Это немного неудобно, поскольку при любых изменениях дизайна прото-структуры, необходимо апдейтить и Gаtеway. В нашем случае с каждым gRPC сервером запускается еще соседний и Gаtеway сервер на отдельном порту.

Конечно можно использовать и внешние программы (аналоги Postman), например Bloom RPC.
Неудобная передача деталей об ошибках
Вернемся к случаю с запретом приветствовать Луиджи. Как вернуть дополнительные данные об ошибке? Как сервер поймет, что он должен считать эти данные? Откуда он их должен брать?
В gRPC эти реализованно с помощью meta-data / трейлеров / хедеров. Это может быть необязательно информация про ошибку, а любая информация, объем файлов, например, или подсказки. Передача метаданных выглядит следующим образом:
Server:
Накопив meta-data, кладем в ответ с определенным ключом (в нашем случае это badrequest). На клиенте происходит вычитка по тому же ключу. Другими словами клиент и сервер должны знать, под каким ключом что лежит. Надо договариваться на словах или прописывать в контрактах. Также вычитка на клиенте достаточно громоздкая.
Client:
Неудобная сгенерированная из прото-файлов Java-документация
Например, есть прото-файл, в котором описано API:
Сгенерированный Java-doc будет выглядеть следующим образом:
Как видим, все наши ссылки и форматирование исчезают. Для того чтобы сгенерировать адекватную Java-доку, приходиться использовать сторонние решения.
HealthCheck
HealthCheck — это проверка того работает ли наш сервис должным образом. В случае с REST мы можем вернуть JSON, где имя компонента, что проверяется — это ключ, а значение — строка ок/не-ок.
В случае с gRPC просто вернуть JSON нельзя. Но можно реализовать новый gRPC endpoint, который бы возвращал такую же модель, как и обычный business endpoint. Но этот endpoint нельзя вызывать прямо из браузера. В случае с gRPC необходима дополнительная программа, которая вызывала бы healthcheck.
Мониторинг (prometheus) overhead
Для мониторинга сервисов мы используем Prometheus, который периодически вычитывает статистику с сервиса через технический endpoint.
Проблема в том, что Prometheus умеет работать только с http и не умеет с gRPC. Чтобы можно было собирать метрики из gRPC приложения, нужен еще один http сервер на отдельном порте, который будет использоваться только для сбора метрик. То есть одно приложение занимает уже три порта:
- gRPC для бизнес-логики;
- http для сбора метрик;
- http для Gateway aka swagger-ui.
Выводы из нашего опыта использования gRPС
Минусы
- Неплохая документация, но большинство ответов находится на форумах и ишьюсах в официальном репозитории на GitHub. Там кстати есть целая экосистема с дополнительными библиотеками от Google и других разработчиков.
- Осложненный процесс тестирования — необходимость иметь транскодер сервис усложняла начальное тестирование в сравнении с REST.
- Нечитабельный формат данных.
- Не стандартизована и громоздкая модель ошибок.
Плюсы
- gRPC — очень быстрый. Сравнение каждой из версий gRPC можно глянуть тут.
- Контракты с коробки в виде proto-файлов. Это помогает отловить большинство ошибок еще на этапе компиляции.
- Обратная совместимость при многих видах изменений.
- Встроенный менеджер дедлайнов и deadline propagation.
- Хорошо поддерживается в интегрированных средах разработки.
Вывод
Если ваша разработка проходит в основном на Go — gRPC must-have в инструментарии, поскольку для Go существует много плагинов и библиотек, которые упрощают работу с gRPC. В случае с Java все немного хуже, и обычно приходиться писать свои решения. Но фреймворк все еще имеет не высокий порог входа и приносит кучу преимуществ в сравнении с REST. Рекомендуем попробовать.
Интересный факт о gRPC
Что означает «g» в gRPC? Здесь можно посмотреть трактование буквы для каждой версии. g is not for Google
Полезные ссылки

41К открытий46К показов

Google обновила логотип впервые с 2015 года — теперь буква «G» получила градиентные цвета и новый стиль для современных интерфейсов

Виртуальное авто под управлением тысяч пользователей — Internet Roadtrip стал вирусным проектом на основе Google Street View

В статье расскажем о невидимых метках, которые оставляет ChatGPT во время работы, а также о «мировом заговоре», который возник из-за этого, и как удалось его раскрыть.

Как сделать на HTML и CSS. Показываем, какими навыками нужно обладать для создания сайтов. Рассматриваем пошаговую инструкцию и основные нюансы ✔ Tproger