


Почему не hadoop: создаём свое решение на node + mongo + lxd

Разбор кейса highload-приложения, который показывает, что решение не всегда лежит на поверхности и часто есть более рациональный подход.
3К открытий3К показов

Кирилл Ефимов
техлид в Dunice
Иногда к нам приходят клиенты с уже определенным стеком технологий для своего проекта. Так было и в этот раз. Клиент хотел проект по обработке больших объемов данных, твердо уверенный, что Hadoop это серебряная пуля.
Disclaimer В данной статье речь пойдет о проекте которому на текущий момент около трех лет. Некоторые решения, в том числе и выбор технологий обуславливался временем разработки.
Клиенту нужно было регулярно проводить электронную инвентаризацию оборудования, каждый отчет по такой инвентаризации содержал более 100k строк. Клиент видел лишь одну проблему — отчеты генерировались слишком долго (в районе 12 часов – 24 часа на каждый отчет). По мнению клиента, эта проблема вытекала из следующих факторов:
- Используется неподходящая СУБД. MongoDB не может в много данных и их обсчет. В результате этого, сложный анализ этих данных занимал слишком много времени и памяти.
- Выходной формат отчетов — excel (xlsx). Для этого использовались скрипты на Node.js, каждый из которых выдавал отчет в своем виде. При построении таких отчетов, оперативная память заполнялась (~8Гб) и любое обращение к базе данных — MongoDB просто падало с ошибкой.
Задача: Поднять Hadoop кластер, настроить миграцию данных из БД Клиента и обработку этих данных средствами Hadoop.
На тот момент времени, у Hadoop была очень слабая поддержка, неразвитая инфраструктура, длительное время не было обновлений и неполная документация. Это всегда накладывало свой отпечаток на время и стоимость проекта.
Примечание На текущий момент, Hadoop имеет более дружелюбную инфраструктуру, благодаря docker и k8s.
При анализе необходимых действий для того, чтобы перенести все необходимые данные в Hadoop, мы выявили что мало того, что данные не имеют четкой структуры, так и в некоторых местах существенно различаются по типу и свойствам (спасибо Mongo за гипергибкость, которая попадает в руки не заботящихся о проектировании данных людей). Ну и в чем проблема, спросите вы. А проблема заключается в том, что Hadoop это SQL-based система. Т.е. все интерфейсы взаимодействия с данными идут через структурированный SQL. И у нас нет возможности мигрировать в эту систему данные без схемы, типов и прочего.
Для того чтобы нормально проработать схемы данных, потребовалось бы очень много времени. А клиенту нужно было как можно скорее. Поэтому на очередной сессии мозгового штурма, мы выделили какие есть проблемы на наш взгляд и придумали как можно их решить.
После глубокого исследования, мы составили свой список причин, почему у них проблема с производительностью:
- Нет четкой схемы данных в БД. Это приводит к тому, что агрегации должны выполнять больше количество действий для расчета результата.
- В текущей БД свалка данных. При разработке системы, которая генерировала эти данные, формат меняли несколько раз, при этом сама БД никогда не очищалась. В результате чего, операции обсчета документов выполнялись даже над теми документами, которые не соответствуют нужной схеме.
- Часть логики по обработке данных было перенесено на сторону Node.js.
- Отчеты генерировались в памяти, и после полной генерации сохраняли это все в excel файл (естественно, когда данных много, оперативной памяти не хватает и вся система рушится).
А также придумали как эти проблемы решить.
- За архитектурную модель мы взяли принцип по которому работают все распределенные системы, в том числе Hadoop. (Есть один мастер и несколько агентов.)
- Мастер управляет нагрузкой и взаимодействием с внешним миром.
- Каждый из агентов выполняет свою задачу по обработке данных.
- Все данные нужно разделить на несколько взаимонезависимых scope, основываясь на локальности данных при их использовании, для того чтобы можно было максимально распараллеливать задачи по обработке этих данных.
- Каждый scope хранить в отдельной БД, для снижения нагрузки на БД.
- Использовать документоориентированную базу данных, чтобы упростить переход, но прописать вариации схем данных.
- Для отказоустойчивости и предотвращения потери данных, каждая БД должна быть представлена replica set как минимум на 3-х разных физических машинах.
- Мы понимали, что система будет большой и сложной для поддержки. Поэтому нам необходим был инструмент, который бы автоматизировал большинство действий с системой за нас.
Общую схему как выглядела система вы можете увидеть на следующем рисунке.

Изображение компании Dunice
Superhost и каждый хост это отдельная физическая машина, со своими ресурсами и настроенным Raid 0 (или Raid 5).
Superhost (он же мастер) состоит из:
- Основного сервиса (Main Web Server, MWS), который обрабатывает запросы от пользователей по специальным ендпоинтам, мониторит состояние всех хостов, запускает и мониторит состояние миграций данных из внешней БД. Извне, мы в любой момент можем увидеть статистику по использованию ресурсов и текущему состоянию системы.
- Metadata service — это сервис хранилище данных о состоянии кластера (какой scope на какой реплике, какой агент с этой репликой лучше работает, когда была последняя миграция для каждого scope и т.д.). Взаимодействовал с этим сервисов только MWS и CLI
- CLI — это терминальный интерфейс для развертывания и управлением кластером. Назван в честь самой системы.
- Планировщик задач. Этот сервис отвечал за запуск миграций в нужное время.
Каждый из host N состоит из:
- Один или несколько контейнеров с агент-сервисом на каждом хосте. Нужен, для того чтобы взаимодействовать с базами данных, выполнять миграцию, запускать агрегацию, в режиме потока строить отчет нужного формата и отправлять на MWS.
- Контейнер с базой данных, которая реплицирована на несколько хостов (min 3).
В базе данных хранились мигрированные данные из основной БД клиента, но разбиты по scope на разные группы реплик. При инициации миграции, данные брались с некоторым условием, так чтобы в одной группе реплик были данные только для одного scope.
Это позволило нам сократить нагрузку на обработку данных и увеличить скорость выдачи отчета. После окончания миграции, мы запускали процесс агрегации (предвычисления). Эта операция предназначена для того, чтобы посчитать все нужные данные для отчетов и положить их в отдельную таблицу. В итоге при построении отчета, мы просто берем данные с фильтрацией из этой таблицы-кеша (получается по сути индекс). Данное решение позволило нам генерировать отчеты на 30 колонок и 200к+ строк за пару минут.
Когда приходило время новой миграции, мы таблицу с закешироваными данными переименовывали и работали с ней. После того как миграция окончилась и появилась таблица с новыми закешироваными данными, мы удаляли старую и работали с новыми данными.
А для того чтобы как то удобно говорить об этой системе, мы решили дать ей имя MoNoRe — по первым слогам ключевых технологий (Mongo, Node, Redis).
Принцип работы при миграции данных:
- Посылаем запрос на адрес
<superhost>/migration/<scopeId>/start - При первом обращении к MWS с запросом на миграцию будет выбран наименее нагруженный хост и на нем создается первый «data» контейнер с настройками репликации. После этого по этому же принципу будут выбрано некоторое количество хостов для создания «data» контейнеров в количестве указанном в файле inventory.ini как replicaCount. Как только все необходимые контейнеры будут готовы, система инициирует создание replicaSet, дожидается окончания этого процесса и возвращает MWS IP адреса всех участников.
- MWS создает расписание на ежедневную миграцию для указанного scope
- Записывает данные о репликах в Redis
- Запрашивает наименее нагруженный «compute» и отправляет ему команду на запуск процесса миграции для указанной фирмы.
- Агент, получив команду на миграцию соединяется с replicaSet, создает(если она отсутствует) новую базу и начинается процесс миграции.
- Прогресс миграции периодически отправляется в MWS и сохраняется в Redis. В любой момент, извне, мы можем запросить состояние миграции нужного scope у MWS
<superhost>/migration/<scopeId>/status. - Когда все данные успешно перенесены, на суперхост будет отправлено сообщение об успешном выполнении миграции.
- Запускается механизм агрегации данных для построения будущих отчетов в коллекцию report_rows, при этом, если на данный момент такая коллекцию существует — она будет переименована в report_rows_cache, а запись будет осуществляться в новую report_rows.
- Прогресс агрегации периодически отправляется в MWS и сохраняется в Redis. В любой момент, извне, мы можем запросить состояние агрегации нужного scope у MWS
<superhost>/migration/<scopeId>/status. - Когда коллекция report_rows будет готова, на суперхост будет отправлено сообщение об успешном выполнении агрегации.
- Записывает данные о времени последней миграции в Redis
При последующих запросах на миграцию суперхост берет всю необходимую информацию из Redis, запрашивает наименее нагруженный «compute» и отправляет ему команду на запуск процесса миграции для указанного scope.
Принцип работы при получении отчета:
- Посылаем запрос на адрес
<superhost>/report/<reportId>?additionalParams=" - При первом обращении к MWS с запросом на миграцию будет выбран наименее нагруженный хост и на нем создается первый «data» контейнер с настройками репликации. После этого по этому же принципу будут выбрано некоторое количество хостов для создания «data» контейнеров в количестве указанном в файле inventory.ini как replicaCount. Как только все необходимые контейнеры будут готовы, система инициирует создание replicaSet, дожидается окончания этого процесса и возвращает MWS IP адреса всех участников.
Как видно из схемы для реализации нашей системы мы решили взять следующие инструменты:
- Node.js (with express) — Использовался для создания HTTP(S) серверов MWS и CS
- MongoDB (with replication) — Так как у команды клиента есть опыт работы с MongoDB, при этом она была достаточно мощной для обработки больших массивов данных за счет Agregation Pipeline, было принято решение ее и использовать как основное хранилище данных.
- ПримечаниеLXD / LXC (Linux Containers) — Система виртуализации, реализующая концепт контейнеров. Использовался для добавления слоя абстракции между элементами системы и серверами на которых происходит разворачивание. В настоящее время имеет смысл использовать Docker + Docker Swarm)
- SSH – Использовался как транспорт для управления между хостами
- Node.js (with Yargs and Ora) — Использовался при построении CLI.
- Cron(Linux) — выполнял роль планировщика задач.
- PM2 — Использовался для повышения отказоустойчивости Node-Express сервисов.
- Redis — Выполнял роль Metadata service.
- Nginx — На master машине выполняет роль прокси сервера, для взаимосвязи с внешним миром. На каждом хосте выполняет роль прокси сервера для общения между MWS и агентом.
Развертывание и управление большой системой = боль?
Система на первый взгляд выглядит непросто. Мы понимали что управлять всем этим руками будет не удобно и будет вызывать много вопросов и проблем у заказчика. Чтобы руками развернуть такую систему необходимо очень четко понимать все ее модули, взаимодействие между ними и потратить пару часов. А это очень не устраивало нас как 0-пользователей системы.
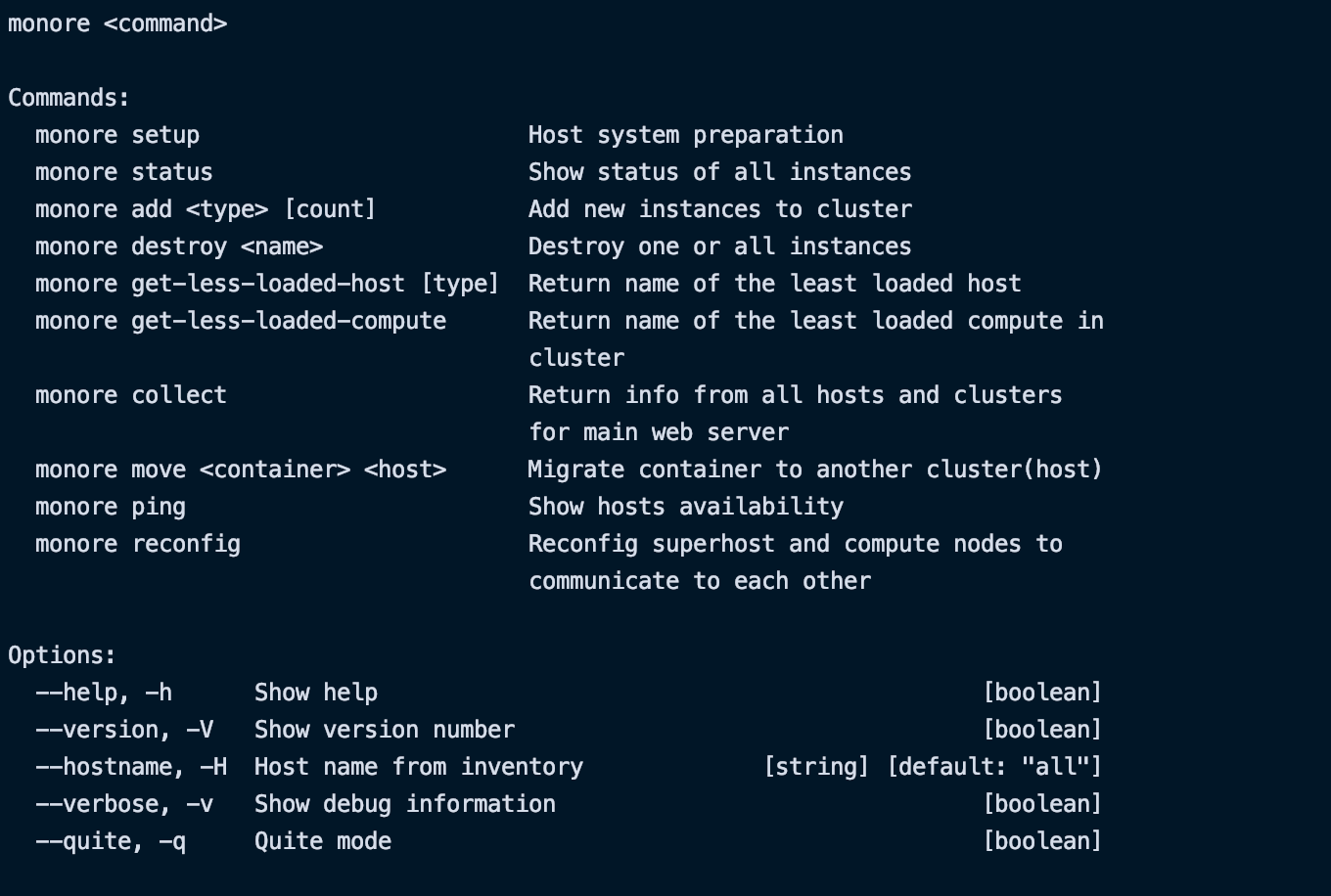
Чтобы решить эту проблему, мы создали CLI c набором команд, позволяющий привести систему в рабочее состояние за 5 минут. Для этого необходимо просто заполнить inventory.ini (см. рис 2) файл с необходимыми данными и запустить команду monore setup. Система сама зайдет на все указанные хосты системы, развернет там необходимые модули, создаст нужные файлы с настройками(nginx, mongo и так далее) и переведет систему в рабочее состояние.

Изображение компании Dunice
Изображение компании Dunice
На первом демо, у тех. директора со стороны заказчика был крайне негативный настрой (оказалось, что до самой демонстрации он не был подключен в наш разговор, и решение о замене Hadoop на наше решение Клиент принимал самостоятельно). Однако, по мере демонстрации возможностей и характеристик системы, интерес возрастал, негодование сменилось удовлетворением, а глаза начали блестеть.
Это было тяжелое демо с нашей стороны, но все участники были довольны достигнутым, оставалось лишь одно НО…. Уровень отказоустойчивости который у нас был на текущий момент, оказался недостаточным для инициирования процесса приёма-передачи продукта. У нас появилось новое требование, нужно чтобы с системой могло произойти все что угодно (отключили от сети или вышло из строя железо хоста или супер хоста, временные проблемы с доступностью хоста), но система должна продолжать работу, и при этом нормально реагировать на возращении хоста (предотвращение коллизий и несогласованности данных).
Таких жестких требований к жизнеспособности системы не мог поддержать и Hadoop. Однако мы не стали спорить с Клиентом, и принялись думать как нам это реализовать.
Тот самый момент, когда грамотная архитектура решает проблемы за тебя
На самом деле, часть этих требований у нас уже были покрыты за счет правильно подобранной архитектуры и программных решений. Например, вопросом коллизий и согласованности данных полностью занималась MongoDB с настроенным Replica Set. А за счет того, что мы храним некоторые метаданные о кластере, потеря одного хоста вообще не является проблемой.
Однако для достижения поставленных целей этого недостаточно. Все еще могут быть проблемы, если откажет Superhost или больше половины host.
Решить эту проблему мы смогли с помощью более крупной кластеризации за счет LXD Cluster (теперь контейнеры на всех хостах находились как бы на одном хосте, видели друг друга и могли спокойно общаться, однако появилось требование, чтобы хосты (в том числе и суперхост) должны быть в одной подсети (16 или 24 ранга)), обновлении логики работы MWS (упростился механизм выборки и взаимодействия с агентами, появилась логика регенерации) и CLI (усложнилась логика разворачивания системы, однако упростился механизм сбора статистики с каждого модуля, появилась логика регенерации), и обновление количества и качества хранимых метаданных о системе.
Шаг с кластеризацией, помог нам более гибко управлять кластером из любого места кластера. Т.е. по факту, любой хост мог стать супер хостом.
Общий алгоритм работы:
- Если теряется связь с хостом, то админу отправляется оповещение со всей необходимой информацией о хосте. А так же, о том что в систему имеет смысл добавить еще хостов, для поддержания высокой отказоустойчивости. При добавлении нового хоста, через CLI, система в автоматическом режиме начинает его полноценное использование.
- Если выходит из строя суперхост, то устраивается кворум, и один из хостов становится суперхостом. Инициируется процесс регенерации. Устанавливается Redis, MWS, CLI. Происходит сбор информации о кластере (за счет того, что в каждой реплике БД есть минимальное количество метаданных о самой реплике, о данных которые в ней хранятся и о последней миграции). В итоге через примерно 30 секунд на кластере из 20 машин, система снова становится обрабатывать запросы извне. Так же отправляется письмо администратору, с информацией о произошедшем и результатом.

Изображение компании Dunice
Итогом данного проекта стало успешное внедрение сначала в тестовый контур, а в последствии и в продакшен. Итоговые характеристики системы при построении отчета:
- Оперативная память не поднимается выше 500мб при формировании отчета ~200к строк из таблицы с > 1млн записей
- Время получения отчета ~60 секунд (для ~200к строк).
А для нас, результатом был ценнейший опыт построения Enterprise систем. Мы еще раз убедились, что правильно подобрать инструмент под задачу, это всего лишь полдела, нужно еще уметь правильно готовить с помощью этого инструмента (ну, и грамотная архитектура дает огромную свободу развития и масштабирования приложения).
Изначально, клиент был недоволен результатом, который получился у его команды. Мы же, взяли те же инструменты, добавили немного новых, правильно определили архитектуру и применили весь наш опыт в разработке Enterprise систем.

3К открытий3К показов

Как подключиться к базе данных. Показываем основные запросы к базам данных. Рассматриваем пошаговую инструкцию по использованию ✔ Tproger

Сравниваем 5 VPS-провайдеров, которые стабильно работают под нагрузкой в 2025 году. Разбираем стоимость, примеры использования, производительность и uptime.

Разработчик показывает, как из простого приложения сделать дорогостоящее — за счет трат на сервера, инфраструктуру и многое другое.

Что такое Hexagonal Architecture. Показываем основные возможности применения гексагональной архитектуры в программировании. Рассматриваем пошаговую инструкцию и основные нюансы