httpx vs. requests vs. aiohttp: кто лучше?
Разобрали на примере, какая из библиотек справляется лучше и как псинхронность влияет на скорость исполнения массовых запросов

С библиотекой requests питонисты знакомятся в первый же год, ведь на взаимодействии программ с веб-приложениями держится очень многое. HTTP-запросы позволяют общаться с API всевозможных сервисов, автоматизировать сбор данных с веб-страниц и в целом дают всевозможным системам взаимодействовать на расстоянии.
Если вы уже научились работать с re и захотели большего, статья поможет взглянуть поглубже на конкурентов, познакомиться с отличиями. Вы также узнаете, для какой задачи какой инструмент подойдет лучше.
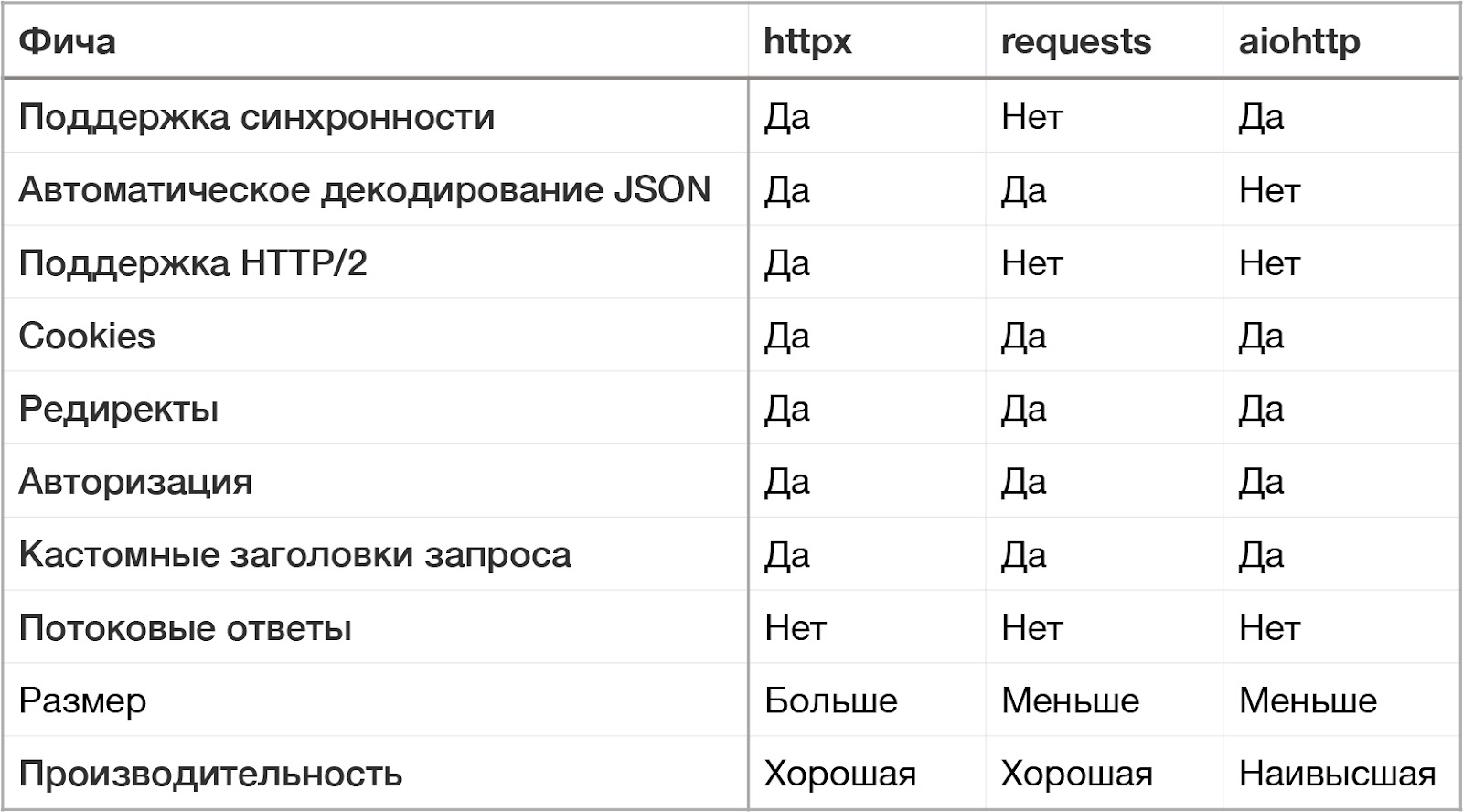
Сравнительная таблица характеристик HTTP-клиентов:
Разница в синтаксисе
Базовый GET-запрос
Давайте сопоставим правила обращений для нашей тройки утилит. Так выглядит стандартный GET-запрос на requests:
А так — эквивалент на httpx:
В качестве альтернативы в httpx даже можно создать экземпляр HTTP-клиента:
aiohttp написан специально для асинхронности, поэтому его стандартный код отправится в следующий раздел.
Поддержка одновременных запросов
Сниппет ниже — запрос на получение на aiohttp. Клиент задействует asyncio:
httpx тоже поддерживает параллельные вычисления:
Код запроса на httpx/aiohttp немного длиннее из-за async/await. Однако это небольшая цена за возможность запускать составные процессы одновременно.
Поддержка http/2
Существует новая версия протокола HTTP под названием HTTP/2, которая обеспечивает более эффективную транспортировку данных и лучшую производительность. Если вы хотите узнать больше о нем, изучите статью. Из нашей троицы только httpx предлагает поддержку этого стандарта.
Чтобы использовать HTTP/2 с httpx, сначала установите дополнительный компонент:
Затем задайте необязательному флагу http2 значение True при создании экземпляра клиента:
Сравним производительность
Давайте создадим простую программу, которая отправляет на веб-сайт конструктора ботов Aimylogic несколько запросов. Вот пример на requests:
requests — синхронный инструмент, то есть будет исполнять запросы строго один за другим. Вот результаты запуска этого кода на Mac с 2,6 GHz 6‑ядерный процессор Intel Core i7 и интернетом (37 Мбит / сек):
Если мы запустим аналогичный код на httpx и aiohttp, то блокировки предшествующим запросом не будет:
Результат приятно удивляет, ведь скорость возросла в 45 и 55 раз для httpx и aiohttp соответственно:
Еще одно отличие состоит в том, что httpx поддерживает async/sync-программирование, тогда как aiohttp является строго асинхронной библиотекой. Если вы хотите разобраться, в чем разница между этими понятиями, посмотрите это видео. Автор собирает две такие версии скриптов и создает с помощью нейронки NVidia лица несуществующих людей (thispersondoesnotexist.com).
Aiohttp отправляет запросы, и позволяет создавать HTTP-серверы.
httpx также автоматически декодирует JSON и другие распространенные форматы, что сэкономит время и усилия при работе со структурированными ответами.
Заключение
Цифры выше говорят сами за себя: с одновременными запросами стоит разбираться. re — хороший выбор, если вам нужна простая и удобная в использовании библиотека, или вы только приступили к теме запросов. Но когда требуется более многофункциональное решение с поддержкой асинхронности, httpx и aiohttp подойдут лучше.
А с какой альтернативой requests вы познакомились впервые? Поделитесь в комментариях.

















