Индексы в PostgreSQL
На примере PostgreSQL коротко рассматриваем несколько разных типов индексов и классов задач, для которых они применимы.

Виталий Сушков
Full Stack Developer в DataArt
В статье я расскажу о предназначении и основах принципов работы объектов баз данных — индексов. На примере СУБД PostgreSQL коротко рассмотрим несколько разных типов индексов и классов задач, для которых они применимы. В конце материала поделюсь ссылками на статьи с более глубоким описанием внутреннего устройства индексов в PostgreSQL.
Статья может быть полезна начинающим разработчикам и студентам, имеющим общие представления о реляционных базах данных, и опытным разработчикам, не сталкивавшимся раньше с индексами и их устройством.
Предназначение индексов
Простейший метод решения задачи поиска записей в базе данных, удовлетворяющих определенному критерию, — полный перебор. Но с ростом количества записей производительность такого подхода будет заметно падать. Для повышения производительности поиска создаются вспомогательные структуры — индексы. Используя индексы, можно существенно поднять скорость поиска, потому что данные в индексе хранятся в форме, позволяющей нам в процессе поиска не рассматривать области, которые заведомо не могут содержать искомые элементы.
Если провести аналогию между базой данных и книгой, индексами можно считать оглавление книги и предметный указатель. Действительно, если бы у нас не было таких «индексов», для поиска конкретной главы или для поиска определения какого-то понятия пришлось бы листать и читать всю книгу целиком, пока не найдем то, что нужно. Имея оглавление и предметный указатель, нам нужно просмотреть существенно меньший объем данных, после чего мы точно узнаем номер страницы книги, на которой находится то, что мы ищем. Индексы в базах данных по сути устроены так же, как оглавление или как предметный указатель книги.
Важно, что использование индексов не только сокращает время поиска в абсолютном выражении, но и уменьшает алгоритмическую сложность процесса поиска. Это значит, что время, необходимое на поиск с помощью индексов, при росте объема базы данных будет расти существенно медленнее, чем при использовании полного перебора.
В качестве примера рассмотрим задачу поиска в списке чисел. Используя перебор элементов списка, в худшем случае, нам придется просмотреть список целиком. Алгоритмическая сложность такого метода — O(n). Но если мы будем хранить наши числа особым образом — отсортированными по возрастанию или по убыванию — сможем использовать алгоритм бинарного поиска.
2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
Допустим, необходимо определить, содержит ли этот отсортированный список число 158. Для этого:
- Смотрим на число в середине списка — 114. Наш список отсортирован по возрастанию, и мы ищем число 158 > 114. Значит, левую половину списка до числа 114 мы можем отбросить: в ней гарантированно не может быть искомого элемента.2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
- Теперь делаем то же самое для правой половины списка. В середине у нее число 134, значит, мы снова можем отбросить элементы левее.2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
- Делаем то же самое для элементов правее 134. В середине у них число 158 — искомый элемент. Поиск закончен.
В итоге метод бинарного поиска дал нам результат всего за три шага. При полном переборе с начала списка нам потребовалось бы 16 шагов. Бинарный поиск имеет алгоритмическую сложность O(log(n)). Используя формулы алгоритмической сложности O(n) и O(log(n)), мы можем оценить, как будет меняться приблизительное количество операций при поиске разными способами с ростом объема данных:
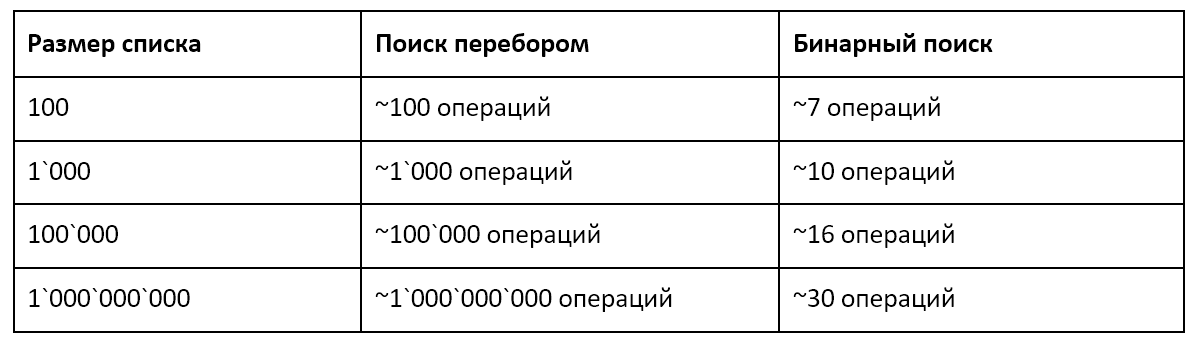
Результат впечатляет. Храня данные в отсортированном виде, мы не только снизили скорость поиска по ним, но и колоссально сократили скорость замедления поиска при росте объема данных.
Использование индексов в базе данных дает аналогичный результат. Принцип работы одного из важнейших индексов в базе данных (индекс на основе B-дерева) основан именно на рассмотренном нами выше принципе — возможности хранить данные в отсортированном виде.
Индексы в PostgreSQL
В базах данных, таких как PostgreSQL, индекс формируется из значений одного или нескольких столбцов таблицы и указателей на строки этой таблицы.
Рассмотрим запрос:
SELECT * FROM table_name WHERE P(column_name) = 1
Здесь выражение P(column_name) = 1 означает, что значение в колонке column_name удовлетворяет некоторому условию (предикату) P.
В отсутствии индекса для колонки column_name, PostgreSQL для выполнения этого запроса был бы вынужден просмотреть таблицу table_name целиком, вычисляя для каждой строки значение предиката P и, если значение истинно, добавлял бы строку к результатам запроса.
Имея индекс для колонки column_name, PostgreSQL может быстро, не просматривая таблицу целиком, получить из индекса указатели на строки таблицы, которые удовлетворяют условию P, и затем уже по этим указателям прочитать данные из таблицы и сформировать результат. Это аналогично тому, как мы, вместо того чтобы просматривать всю книгу целиком, смотрим только ее оглавление, читаем номера страниц, соответствующие интересующим нам главам, а затем переходим на эти страницы.
Предикат P может вычисляться от значения нескольких колонок. В этом случае для ускорения запроса используется индекс, построенный не для одной колонки, а для нескольких. Такие индексы называют составными.
Если мы хотим ускорить выполнение запроса, условие которого вычисляется по одной или нескольким колонкам, в PostgreSQL нам необходимо создать для этих колонок индекс с помощью команды CREATE INDEX:
Эта команда имеет большой перечень дополнительных параметров, с полным списком которых можно ознакомиться в документации.
Например, индекс может поддерживать ограничение на уникальность и не допускать появления в таблице нескольких строк, значения индексируемых столбцов у которых совпадают. Для этого при создании индекса указывают ключевое слово UNIQUE:
Или мы можем создать индекс не по полю таблицы, а по функции или скалярному выражению с одной или несколькими колонками таблицы (такие индексы называют функциональными или индексами по выражению). Это позволяет быстро находить данные в таблице по результатам вычислений. Например, мы хотим ускорит запрос регистронезависимого поиска по текстовому полю:
Если мы создадим обычный индекс по полю text_field, он нам никак не поможет, т. к. PostgreSQL проиндексирует те значения, которые хранятся в этом поле в исходном виде (необязательно в нижнем регистре), а мы хотим искать по значениям этого поля, приведенные к нижнему регистру вызовом функции lower. Однако мы можем создать индекс по результатам вычисления выражения lower(text_fields):
CREATE INDEX index_name ON table_name(lower(text_field))
И такой индекс уже может успешно применяться для ускорения нашего запроса.
В зависимости от типа индексируемых данных, для индексирования применяются разные подходы. По умолчанию при создании индекса используется индекс на основе B-дерева. Но PostgreSQL поддерживает разные типы индексов для очень широкого круга задач, и при необходимости мы можем указать другой тип индекса, отличный от B-tree. Для этого перед списком индексируемых полей необходимо указать директиву USING <тип_индекса>. Например, для использования индекса типа GiST:
CREATE INDEX index_name ON table_name USING GIST (column_name)
B-tree
Этот тип индекса используется по умолчанию и покрывает очень широкий круг задач (базы данных большинства приложений успешно могут обходиться только индексами на основе B-деревьев).
С помощью B-дерева можно проиндексировать любые данные, которые могут быть отсортированы, т. е. для которых применимы операции сравнения больше/меньше/равно. Сюда можно отнести числа, строки, даты и время, логический тип и любые данные, которые можно ими закодировать.
Какой тип запросов может быть ускорен с помощью B-дерева? На самом деле, практически любой запрос, условие которого является выражением, состоящим из полей входящих в индекс, логических операторов и операций равенства/сравнения. Например:
- Найти пользователя по его email:SELECT * FROM users WHERE email='user@mail.com'
- Найти товары одной из двух категорий:SELECT * FROM goods WHERE category_id = 10 OR category_id = 20
- Найти количество пользователей, зарегистрировавшихся в конкретный месяц:SELECT COUNT(id) FROM users WHERE reg_date >= 01.01.2021 AND reg_date <= 31.01.2021
Выполнение этих и многих других запросов может быть ускорено с помощью B-дерева. Кроме того, индекс на основе B-дерева ускоряет сортировку результатов, если в ORDER BY указано проиндексированное поле.
Принцип работы индекса на основе B-дерева основан на рассмотренном нами ранее алгоритме бинарного поиска: т. к. все значения упорядочены, мы можем быстро определять области, в которых гарантированно не может быть данных, удовлетворяющих запрос, существенно снижая таким образом количество перебираемых записей.
Однако хранить индекс просто в виде отсортированного массива мы не можем, т. к. данные могут модифицироваться: значения могут меняться, записи — удаляться или добавляться. Чтобы эффективно поддерживать хранение индексируемых данных в отсортированном виде, индекс хранят в виде сбалансированного сильно ветвящегося дерева, называемого B-деревом (B-tree).

Корневой узел B-дерева содержит в упорядоченном виде несколько значений из общего набора, допустим, t элементов. Тогда все остальные элементы можно распределить по t+1 дочерним поддеревьям по следующему правилу:
- Первое поддерево будет содержать элементы, которые меньше, чем 1-й элемент корневого узла (на рисунке выше первое поддерево содержит числа, меньшие 30).
- Второе поддерево будет содержать элементы, которые находятся между 1-м и 2-м элементами корневого узла (на рисунке выше второе поддерево содержит числа между 30 и 70).
- И т. д. — последнее поддерево будет содержать элементы, большие элемента корневого узла с номером t (на рисунке выше третье поддерево содержит элементы, большие 70).
Каждое поддерево, в свою очередь, тоже является B-деревом, имеет корневой элемент и строится далее рекурсивно по такому же принципу.
За счет того что элементы в каждом узле отсортированы, при поиске мы сможем быстро определить, в каком поддереве может находиться искомый элемент, и не рассматривать вообще другие поддеревья. Допустим, нам нужно найти число 67:
- Корневой узел содержит числа 30 и 70, значит, искомый элемент следует искать во втором поддереве, т.к. 67 > 30 и 67 < 70.
- Корневой узел второго поддерева содержит элементы 40 и 50. Т. к. 67 > 50, искомый элемент следует искать в третьем потомке этого узла.
- На третьем шаге мы получили узел, не имеющий потомков, среди элементов которого находим искомое число 67.
Таким образом, при поиске в B-дереве необходимо максимум h раз выполнить линейный или бинарный поиск в относительно небольших списках, где h — это высота дерева. Т.к. B-дерево — сильно-ветвящееся и сбалансированное (т. е. при его построении и модификации применяются алгоритмы, сохраняющие его высоту минимальной, см. статью), число h обычно совсем невелико, и при росте общего количества элементов оно растет логарифмически. Как мы уже видели ранее, это приносит очень хорошие результаты.

Кроме того, важное и полезное свойство B-дерева при его использовании в СУБД — возможность эффективно хранить его во внешней памяти. Каждый узел B-дерева обычно хранит такой объем данных, который может быть эффективно записан на диск или прочитан за одну операцию ввода-вывода. B-дерево даже может не помещаться целиком в оперативной памяти. В этом случае СУБД может держать в памяти только узлы верхнего уровня (которые вероятно будут часто использоваться при поиске), читая узлы нижних уровней только при необходимости.
Индекс на основе B-дерева может ускорять запросы, которые используют не целиком входящие в индекс поля, а любую часть, начиная с начала. Например, индекс может ускорить запрос LIKE для поиска строк, которые начинаются с заданной подстроки:
SELECT * FROM table_name WHERE text_field LIKE 'start_substring%'
Если индекс построен по нескольким колонкам, он может ускорять запросы, в которых фигурируют одна или несколько первых колонок. Поэтому важен порядок, в котором мы указываем колонки при создании индекса. Допустим, у нас есть индекс по колонкам col_1 и col_2. Тогда он может использоваться в том числе для ускорения запроса вида:
SELECT * FROM table_name WHERE col_1 = 123
И нам не нужно создавать отдельный индекс для колонки col_1. Будет использоваться составной индекс (col_1, col_2).
Однако для запроса только по колонке col_2 такой составной индекс уже использовать не получится.
Подробнее, как индекс на основе B-дерева реализован в PostgreSQL, см. статью.
GiST и SP-GiST
GiST — сокращение от «generalized search tree». Это сбалансированное дерево поиска, точно так же, как и рассмотренный ранее b-tree. Но b-tree применимо только к тем типам данных, для которых имеет смысл операция сравнения и есть возможность упорядочивания. Но PostgreSQL позволяет хранить и такие данные, для которых операция упорядочивания не имеет смысла, например, геоданные и геометрические объекты.
Тут на помощь приходит индексный метод GiST. Он позволяет распределить данные любого типа по сбалансированному дереву и использовать это дерево для поиска по самым разным условиям. Если при построении B-дерева мы сортируем все множество объектов и делим его на части по принципу больше-меньше, при построении GiST индексов можно реализовать любой принцип разбиения любого множества объектов.
Например, в GiST-индекс можно уложить R-дерево для пространственных данных с поддержкой операторов взаимного расположения (находится слева, справа; содержит и т. д.). Такой индекс доступен в PostgreSQL и может быть полезен при разработке геоинформационных систем, в которых возникают запросы вида «получить множество объектов на карте, находящихся от заданной точки на расстоянии не более 1 км».
SP-GiST похож GiST, но он позволяет создавать несбалансированные деревья. Такие деревья могут быть полезны при разбиении множества на непересекающиеся объекты. Буквы SP означают space partitioning. К такому типу индексов можно отнести kd-деревья, реализация которых присутствует в PostgreSQL. Его, как и R-дерево, можно использовать для ускорения запросов геометрического поиска. Свойство непересечения упрощает принятие решений при вставке и поиске. С другой стороны, получающиеся деревья, как правило, слабо ветвисты, что усложняет их эффективное хранение во внешней памяти.
Кроме того, GiST и SP-GiST могут служить своеобразным фреймворком, облегчающим расширение PostgreSQL и добавление в него совершенно новых видов деревьев для индексации новых типов данных.
Подробнее об алгоритмах, лежащих в основе R- и kd-деревьев см. раз и два, а об их реализации и использовании в PostgreSQL см. в этой и этой статье.
Заключение
Индексы — важнейший инструмент баз данных, ускоряющий поиск. Он не бесплатен, создавать много индексов без лишней необходимости не стоит — индексы занимают дополнительную память, и при любом обновлении проиндексированных данных СУБД должна выполнять дополнительную работу по поддержанию индекса в актуальном состоянии.
PostgreSQL поддерживает разные типы индексов для разных задач:
- B-дерево покрывает широчайший класс задач, т. к. применимо к любым данным, которые можно отсортировать.
- GiST и SP-GiST могут быть полезны при работе с геометрическими объектами и для создания совершенно новых типов индексов для новых типов данных.
- За рамками этой статьи оказался ещё один важный тип индексов — GIN. GIN индексы полезны для организации полнотекстового поиска и для индексации таких типов данных, как массивы или jsonb. Подробнее см. в статье. Современные версии PostgreSQL имеют вариацию такого индекса под названием RUM (см. статью).
Ссылки на полезные материалы
- Создание индекса в PostgreSQL
- Алгоритмы работы с B-деревом
- Релизация B-дерева в PostgreSQL
- R-дерево
- Kd-дерево
- Индекс типа GiST в PostgreSQL
- Индекс типа SP-GiST в PostgreSQL
- Индекс типа GIN в PostgreSQL
- Индекс типа RUM в PostgreSQL















