


Интеграционные тесты в микросервисах

Обсуждаем несколько подходов к тестированию микросервисов, чтобы понять, сколько нужно тестов и какие кейсы они должны покрывать.
12К открытий14К показов

Константин Яковлев
Senior Developer в DataArt
Кто любит, когда в пятницу вечером из продакшена прилетает баг и надо срочно его фиксить? Или когда все юнит-тесты зеленые, а на тестовом энвайроменте сервис не запускается? Скорее всего — никто. Все мы заинтересованы в качестве продукта, над которым работаем. Не только потому что мы ответственные разработчики, но и потому что любим отдохнуть в выходные.
Но появление багов неизбежно. Чтобы обеспечить качество продукта, нам необходимо выявлять их как можно раньше — в идеале, до того как наше решение ушло в продакшн. Для этого есть разные виды автоматического тестирования, начиная с выявления ошибок компиляции, заканчивая UI-тестированием на препродакшене и хорошо настроенными CI-процессами.
Написание тестов — не такая простая задача, какой кажется на первый взгляд. Мы всегда должны выбирать правильные подходы и где-то чем-то жертвовать для максимальной выгоды. В статье я хотел бы сфокусироваться на интеграционном тестировании и обсудить несколько подходов к нему — не всегда понятно, сколько нужно таких тестов и какие кейсы они должны покрывать.
Для начала определимся, что такое интеграционное тестирование или, как его еще называют, тестирование сервиса. Рассмотрим на примере небольшого проекта, какие вообще бывают типы тестов. Проект состоит из двух микросервисов: 1) сервис A — stateful и хранит состояние в некой DB; 2) сервис B — stateless и может являться некоторым воркером. Еще у нас есть WebApp, через которое мы взаимодействуем с нашими сервисами.
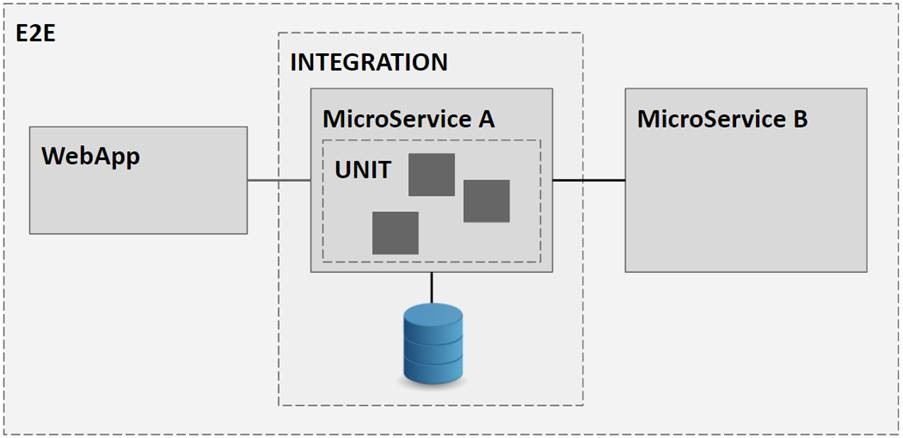
Самый первый вид тестирования — Unit-тестирование. Не буду углубляться в подробности, т. к. он всем хорошо известен. Просто скажу, что Unit-тестирование или, как его еще называют, изолированное тестирование — тестирование на уровне класса или группы классов, с помощью которого можно проверить каждый метод или функцию. Такое тестирование дает уверенность, что отдельные части кода работают, но не говорит, работает ли код в целом.
Этот минус решает Integration-тестирование, или тестирование сервиса. Здесь мы проверяем весь сервис в изоляции. Т.е. мы мокаем все внешние зависимости на другие сервисы. В нашем примере получаются сквозные тесты микросервиса A от HTTP request до DB и обратно. При этом виде тестирования мы можем быть уверены, что правильно настроен DI, все компоненты нормально работают вместе, и поведение соответствует бизнес-сценариям.
Но мы живем в микросервисном мире, и проверка каждого сервиса по отдельности не дает уверенности, что вся система работает. Тут на помощь приходит последний вид тестирования — end-to-end (E2E), или UI-тестирование. Оно может быть автоматическим и ручным. Проверяется работа всех компонентов системы вместе на соответствие бизнес-требованиям. Если Unit- и Integration-тестирование — по большей части, проверка с технической точки зрения, то E2E — проверка ожиданий пользователя от работы системы.
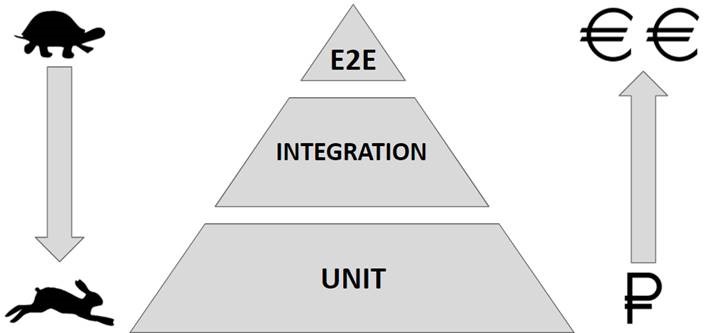
Ни одно обсуждение тестирования нельзя считать полным без упоминания пирамиды тестирования, предложенной Майком Коном в книге «Succeeding with Agile». Согласно пирамиде, самые многочисленные тесты — Unit. Они маленькие, изолированные и могут проверить любую отдельную часть вашего сервиса, вплоть до строчки кода. Далее — Integration. Это более объемные тесты, которые проходят через весь pipeline сервиса. И на вершине — E2E тесты, которые дают нам большую уверенность в работе системы, но самые долгие в имплементации и самыми неинформативные, поэтому их должно быть меньше всего. Также пирамида говорит, что, чем ближе к основанию, тем больше скорость написания тестов. Чем дальше, тем дороже написание, поддержка, и, в случае дефекта, — поиск причины.
Это была классическая стратегия тестирования, давайте рассмотрим и другие.
Перевернутая пирамида, или рожок тестирования. В этой стратегии основной упор — на E2E-тесты, т. к. они дают наибольшую уверенность, что работа всей системы полностью соответствует ожиданиям конечного пользователя. Одновременно это ловушка. С одной стороны, мы уверены в качестве продукта, а с другой — тратим огромное время на получение фидбека, что система работает после внесения каких-либо изменений. Если каждый Unit-тест выполняется за миллисекунды, Integration — за секунды, E2E может занимать несколько десятков секунд или минуты. И даже если тест выявил дефект, мы точно не знаем, в каком сервисе и в каком месте кода произошел сбой. Мы должны будем потратить достаточно много времени на поиск причины бага.

Я работал над одним проектом, в котором основными тестами были E2E, и полный прогон занимал несколько часов, поэтому их запускали только по ночам. Т. е. фидбэк по новой фиче мы получали только на следующее утро, и в случае дефекта начался долгий поиск причин. При таком подходе очень много времени расходовалось на поиски. В ожидании прохождения тестов параллельно могла начаться работа над другой задачей. Тогда приходилось отложить текущую задачу и вернуться к предыдущей. Это всеотрицательно сказывалось на продуктивности. Как разработчик я хочу максимально быстро узнавать о наличии дефекта. В идеале — на своей локальной машине во время имплементации. Этот подход не дает такой возможности. Поэтому я не рекомендую его никому.
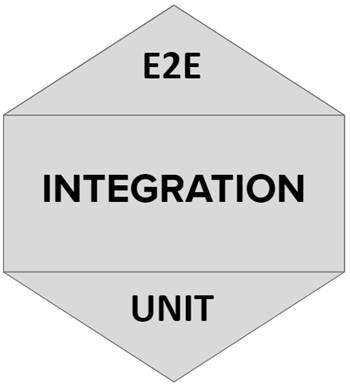
Следующая стратегия — сота тестирования (testing honeycomb). Здесь основной упор делается на integration-тесты. Она идеально подходит для микросервисов, в частности, ее используют в Spotify.
Kогда сервис небольшой (как говорят, размер микросервиса должен быть таким, чтобы agile-команда смогла его полностью переписать за 1 спринт) и в нем мало бизнес-логики, этот подход дает большие плюсы:
- Уверенность, что код делает то, что должен. При этом виде тестов вы проверяете только реалистичный input сервиса и ожидаемый output. Вам нет никакого дела, как все реализовано внутри.
- Мы можем рефакторить код внутри без изменения тестов. Например, мы можем полность изменить БД и/или переписать бизнес-логику, это никак не повлияет на тесты.
Но есть и минусы:
- Некоторые потери в скорости выполнения тестов. Как мы уже знаем, каждый Integration-тест выполняется несколько секунд, что приводит к потерям времени. Но в случае микросервисов потери незначительны, потому что объем тестов небольшой.
- Мы можем потерять некоторый фидбэк, если тесты упали. Но хоть мы точно и не знаем место, где произошел сбой, можем быстро его найти и устранить.
Время идет, и наш сервис развивается, в нем появляется больше кода, и становится сложнее бизнес-логика. При использовании стратегии призмы тестирования у нас могут возникнуть большие проблемы. Какие? Давайте разберем.
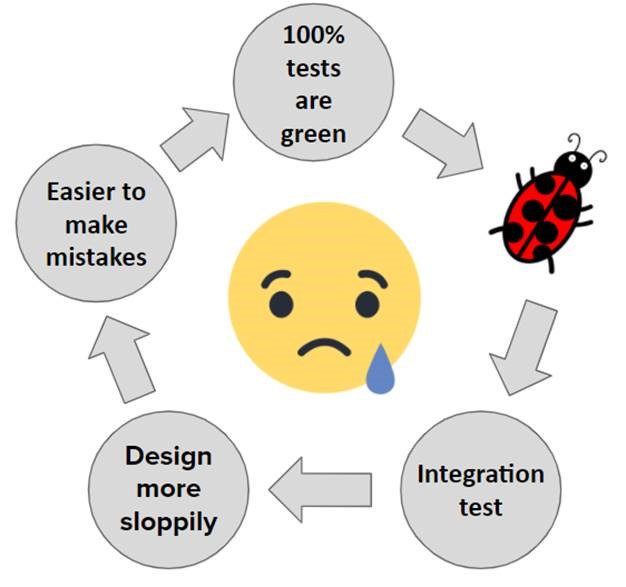
Все мы сталкивались с ситуацией, когда все тесты зеленые, но выявляется баг. Что мы можем сделать после этого? Найти причину, закрыть ее Integration-тестом, который воспроизводит проблему, пофиксить и выпустить патч. И в этом кроется основной недостаток Integration и любого другого вида сквозного тестирования. Мы упускаем из виду проблемы в архитектуре приложения. Как бы удивительно ни звучало, Unit-тесты нужны не только для проверки бизнес-логики и поиска багов, но и для выявления проблем в дизайне. Всем известно, что если вы не можете покрыть какую-то часть кода Unit-тестами, у вас проблемы в архитектуре. Unit-тесты позволяют заметить их на ранних стадиях. Например, если для написания одного Unit-теста вам необходимо замокать кучу зависимостей, есть проблема, необходимо провести рефакторинг.
Таким образом, Unit-тесты помогают не только находить логические ошибки, но и выявлять проблемы в дизайне. А что происходит, если вы их не пишете? Архитектура ухудшается и становится более запутанной. Повышается вероятность сделать ошибку при каких-либо изменениях. Это как гидра: пофиксили что-то здесь — сломалось что-то там. И круг замкнулся, у вас опять все тесты зеленые, но появляется ошибка, вы покрываете ее Integration-тестом, фиксите следствие, а не причину. И так опять, и опять, и опять. В итоге ваш проект состоит только из костылей, а вы — несчастны.
Другая проблема — время. Чем больше у вас Integration тестов, тем больше времени занимает их полный прогон. Для микросервисов со сложной бизнес-логикой и взаимодействием прогон всех тестов может занять ни один десяток минут. Это снова негативно сказыается на производительности и качестве кода. Вы будете очень редко запускать все тесты, а, скорее всего, их полный прогон будет только на CI после открытия PR.
Каков же рецепт? Универсального решения не существует. Найти стратегию на все случаи жизни невозможно, каждая имеет сильные и слабые стороны. И только одним видом тестирования не обойтись, необходимо брать лучшее от всех подходов и грамотно их сочетать.
Основная рекомендация — используйте Integration-тесты для проверки сервиса на соответствие бизнес-требованиям. Воспроизведите основные бизнес-кейсы для сервиса в Integration-тестах, но не пытайтесь проверять бизнес-логику через них. Для этого есть Unit-тесты. Тогда при рефакторинге и/или переезде на другую DB вам ничего не нужно будет делать с самими тестами. Вы всегда будете уверены, что работа сервиса соответствует требованиям.
Пока ваш сервис живет и функционирует, вы можете менять стратегию, если видите, что предыдущий подход больше не дает бенефитов. Допустим, у вас маленький сервис с небольшим количеством CRUD-операций, используйте подход «соты тестрования». С развитием сервиса, если заметите, что тесты начинают занимать все больше и больше времени, а внесение изменений становится все сложнее, переходите к стратегии пирамиды тестирования.При выявлении баги все-таки закрывайте ее Unit-тестами, а не интеграционниками.
Спасибо за внимание. Безбажных вам сервисов.

12К открытий14К показов

Подробный туториал по установке и настройки n8n. Примеры интеграции с Python, Node.JS и PHP и взаимодействия с LLM Mistral AI.

Самые лучшие курсы по чат-ботами. В предложенной подборке актуальные варианты обучения от проверенных школ, а так же рейтинги и цены на курсы по разработке чат-ботов

Продолжаем нашу серию статей о хакерах и тайных IT-сообществах. Сегодняшний пациент — Chaos Computer Club.

Go 1.25, кодовые агенты, тулчейн, наблюдаемость, безопасность, тестирование, производительность и работа высокодоступных систем.