🔥Как быстро и эффективно работать с большими JSON-файлами
Как работать с большими JSON файлами. Показываем основные способы работы с Big JSON и возможные проблемы. Рассматриваем пошаговую инструкцию ✔ Tproger

Разработчики используют API каждый день, и подавляющее их число отдает данные в виде JSON-массивов, будь то логи бота или резюме кандидатов с площадок по поиску работы. С небольшими файлами.json учат обращаться на многих курсах программирования, но что делать, если объем такого вывода становится некомфортно большим? Или вы регулярно «упираетесь» в ошибки, вызванные разнородной структурой элементов? В этой статье мы познакомим вас с тремя решениями, которые помогут эффективно работать с большими JSON файлами.
Если вы только-только начали изучать способы хранения, знания JSON можно освежить здесь.
Способ первый: параллельная обработка
Классическое решение, задействующее навыки параллелизации. К примеру, если признак name каждого элемента требует обновления:
Мы можем задать две функции. Первая из них добавляет значению name префикс Test:
А вторая пушит обновление:
В итоге мы распараллеливаем запуск этих функций с помощью asyncio:
Способ второй: пакетная обработка в binary
В комьюнити Hadoop и Spark (для хранения больших данных) особое признание обрел формат Parquet. Когда речь идет об огромных объемах информации, удобство ее обработки превалирует над читаемостью. Здесь вообще рекомендую избегать подключения pandas и перевода в человекочитаемый формат в промежутке.
Такой код:
- «Заморозит» вашу программу, если файл слишком большой;
- Не учитывает массивы с меняющейся структурой.
А до этого RAM вообще может закончится на шаге конвертации JSON в датафрейм.
В такой ситуации поможет библиотека ijson:
К примеру, конверсия кортежа в binary:
Превратит числа вот в такую компактную и быстродейственную абракадабру:
Способ третий: перейти в другой формат
На курсах повышения квалификации нашу группу познакомили с Redis — альтернативой классическим базам вроде PostgreSQL. Так здорово осознавать, что до тебя немало людей уже отстрадались на ниве JSON и даже создали целое решение, «бьющее» самые распространенные проблемы — разнородность элементов массива, вложенные узлы.
Представьте, сколько энергии потребуется даже с ChatGPT, чтобы написать скрипт на Python, который «схлопнет» до табличного состояния данные кандидатов ниже?
Пару лет назад я занималась подобным перед загрузкой логов бота в BigQuery (SQL-подобная база), а потом была вынуждена обрабатывать ситуацию «забытых» полей (они проявлялись реже, чем раз в неделю, на которой опробовали скрипт выгрузки). Это приводило к необходимости обновлять схему таблицы, заниматься перезаливом и в целом фрустрироваться ситуацией.
Теперь понимаю: лучший способ сократить мороку при обращении с массивами — отойти от формата строго заданной структуры как можно раньше. Redis буквально создан для этого. В подгружаемом массиве через месяц появился экземпляр кандидата с новым полем portfolio? «Редиска» положит к себе и такое, причем без множественных ошибок. Захотите в дальнейшем использовать данные таблично? Вычитайте сет с помощью самописной функции:
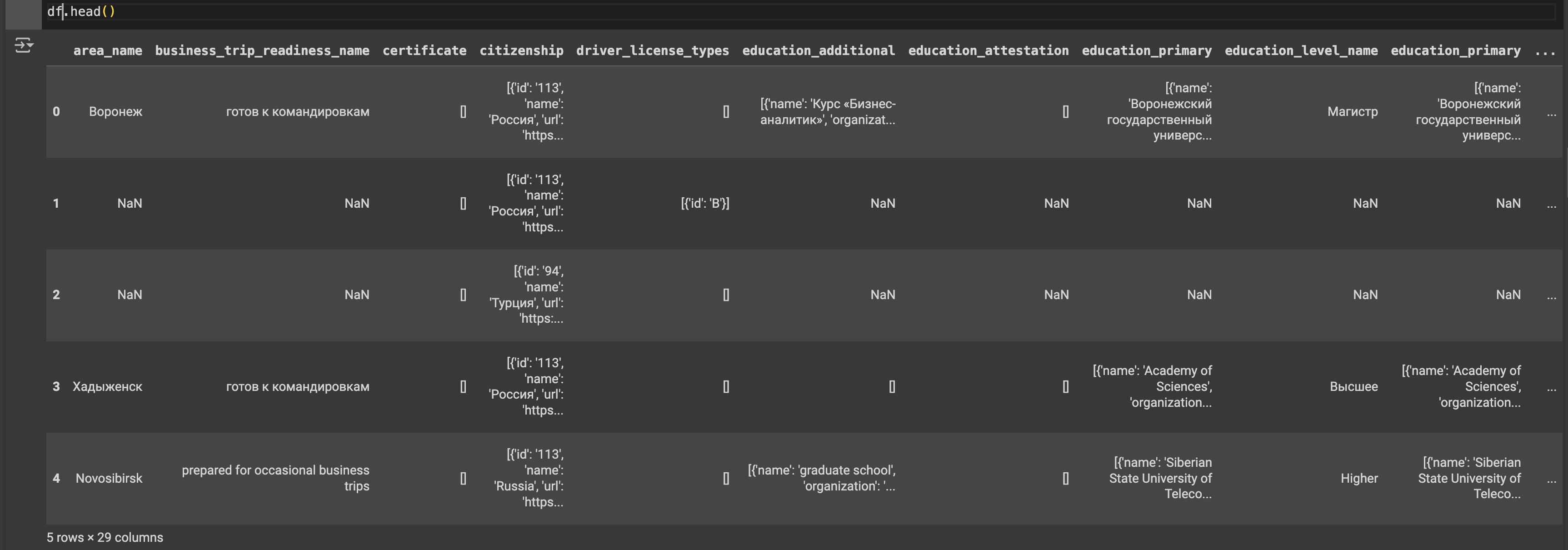
И что немаловажно, данные хранятся в оперативной памяти сервера, что ускоряет обращение с ними, даже в случае с большими порциями. Если ваша компания, конечно, не испытывает проблем с масштабируемостью.
Приятный бонус: логика сета (это аналог таблицы в базе) подразумевает уникальные значения. То есть очистка от повторений будет произведена автоматически. И тут ощущаются спасенные человекочасы.

Многие провайдеры облачных серверов предлагают преднастроенный Redis, который за 5-10 минут встанет из-под Docker-контейнера, и цены на такие услуги стремятся к тем же минимумам, что и голый Ubuntu на миникалках (300 рублей в месяц против 130).
Среди недостатков «редиски» отмечу, что переход от таблиц к сетам может вызвать у разработчика с информационной перегрузкой дополнительный стресс: документация весьма непростая и перестроиться на нетабличное восприятие поначалу потребует много энергии. Но тут очень здорово помогает ChatGPT.
Заключение
Если вы дорасли до проектов с массивными объемами данных, это уже прекрасно. Порой стоит позволить себе наошибаться при обращении с ними, пока не подберете наилучшее для ситуации решение. ijson немного сложнее поддерживать, Redis плохо подходит новичкам, asyncio тоже не идеален. В каждом проекте свои тонкости — они и определят, какое из решений оптимальное.

