


Как искать данные в пространстве невероятно быстро? R*-tree в Go

Как быстро работать с любыми пространственными данными, чтобы это было быстро и эффективно
4К открытий5К показов
Всем привет! Я являюсь игровым разработчиком в трехмерных играх с большим опытом и в данный момент перехожу на язык Go и перехожу в Highload. Сегодня я бы хотел рассказать о том, с какой интересной задумкой я столкнулся и решил одну интересную проблему.
Задумывались ли Вы, как быстро работать с любыми пространственными данными, чтобы это было быстро и эффективно?
Предыстория
На моём опыте я участвовал проектах с нагруженностью 2-3 тысячи человек.В среднем, на одном игровой «машине» располагается примерно 500-1000 человек.На опыте был один проект, где вовсе было 3 тысячи человек: два игровых сервера по 1500 тысячи человек
По большей своей части, я занимался клиентом и логическим ядром сервера в виде обращений к БД, работе с кэшем и связью между клиентом и сервером.
Поэтому во всех этих игровых проектах, к сожалению, у меня не было доступа к более низкому уровню сети вроде «синхронизации игроков между другими игроками», кроме одного проекта, где мне помог один человек. Он рассказал мне о том, как работает синхронизация между игроками в его игре.
Представим себе трехмерную игровую карту с 1000 игроков на сервере. Карта достаточно большая, поэтому нет смысла, чтобы игроки видели друг друг друга на огромных расстояниях. Это бессмысленная нагрузка.
Эффективнее всего игроку давать какую-то область видимости (например, круг или квадрат вокруг игрока), где он бы видел игроков поблизости. Так это и устроено в игре, а такая область видимости называется «зона стрима».
Как просчитывается эта зона стрима?
Не будем углубляться в в жизненный цикл игрового сервера… Буквально каждую секунду на сервере происходит перерасчет зоны видимости игрока. Они — игроки — постоянно двигаются, перемещаются по карте на автомобилях или пешком.
Так вот, тот самый человек, который помог мне, рассказал, что в его игре при 1000 онлайне сервера расчет происходит так: берется игрок — к нему просчитываются все остальные игроки, и так для всех игроков. То есть, это цикл 1000 * 1000.
Я был очень сильно удивлен, поэтому начал копать…
Подходим к R-tree. Что это, почему и зачем?
Пока я копался в базах данных для подготовки к собеседованиям на Go, я наткнулся на GiST индекс, который является подвидом структуры R-tree. Я начал изучать, что это такое — и это ровно то, что и было нужно!
Что такое R-tree? R-tree — это древовидная структура данных, которая позволяет довольно быстро работать с геопространственными данными.
А R*-tree что тогда такое? R*-tree — это подвид структуры R*-tree, который более ёмок в построении, но при этом позволяет обращаться к данным быстрее, чем обычный R-tree
Ещё чуть-чуть о той сфере, в которой я работаю
Я рассказал этому человеку об этой структуре данных (R-tree) и скинул одну интересную статью, и он с удовольствием принял эту идею и в ближайшее время её реализует.
Я показал разработчику буквально на примере, взяв библиотеку rtreego, с какой разницей можно работать с этими данными по времени. Нагрузка при 4000 игроков с R-tree может быть такой же, как у него с 1000 игроков при его реализации!
Я был очень сильно доволен, так как решил одну интересную проблемку, но тут было ещё более интересно… Сам же я бегло прочитал ту статью, которую скинул, и этот человек указал мне на то, что в статье описан R*-tree, а не только R-tree.
Мне было крайне интересно узнать разницу между этими алгоритмами, поэтому я стал копать дальше…
В чём же разница между R-tree и R*-tree?
R-tree невероятно прост в построении и так же невероятно прост в поиске. У этого дерева нет никаких требований.
R*-tree сложнее в построении, но при этом более эффективен в поисковых запросах.
Что же сложного в построении R*-tree?
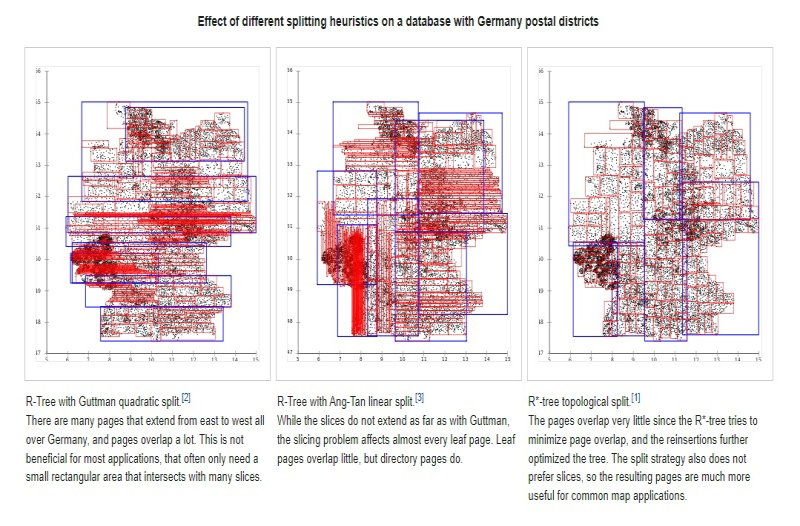
Возьмем в пример построение R-tree, R-tree с линейным разделением и R*-tree:
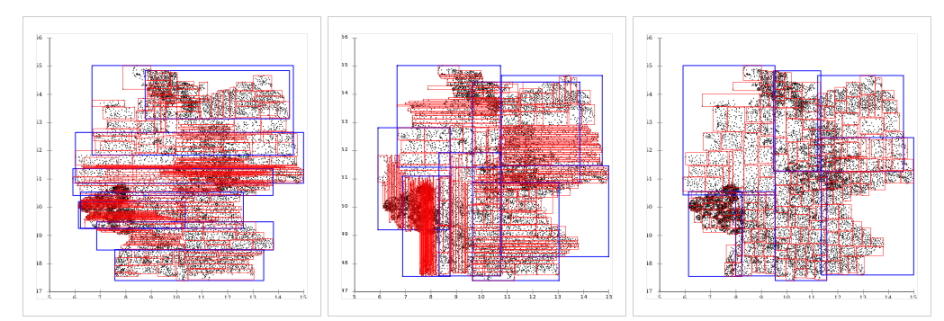
В третьем варианте мы можем увидеть более четкое и явно разделение элементов по веткам (красным квадратикам) и деревьям (синим квадратикам), в то время как в первом и втором варианте у нас самая настоящая каша.
При обычной вставке элемента в R*-tree дерево работает так же как и в R-tree, но.
Когда «листья», на которых хранятся элементы, необходимо разделить — R-tree делает это не запариваясь, в то время как R*-tree старается сделать так, чтобы:
- Листья занимали как можно меньшую площадь
- Листья как можно меньше накладывались на другие листья поблизости
- Листья были равно распределены
За счет соблюдения трех этих правил, построение может быть по времени в 2-3 раза сложнее, но! Поиск по элементам будет эффективнее в 1.5 — 3 раза.
Если Вам нужно использовать статические данные, R*-tree будет для Вас!
Так где нужно использовать R-tree, а где R*-tree?
Мы поняли, что R-tree довольно быстрый при вставке, но медленнее по поиску.
Просто взять и «перемещать» данные по дереву невозможно, а лишь можно удалять элемент и вставлять его заново.
Поэтому мы приходим к выводу.
Где можно использовать R-tree?
- Игровой стриминг (область видимости игрока в пространстве)
- Карты, где элементы могут перемещаться (те же карты с курьерами или такси, например!)
- Любые геоданные, которые довольно часто обновляются, но чтение чуть менее важно.
Где можно использовать R*-tree?
- Тот же игровой стриминг, но статических объектов! Например, у игрока есть огромная карта с множеством элементов (как города в GTA, например). Поиск по этим элементам, даже если их миллион, можно делать за мили (или даже нано) секунды!
- Карты, где невероятно множество статических элементов. (Например, карта заведений, домов или элементов, которые меняются довольно редко)
- Любые геоданные, которые почти не обновляются, но требуют невероятно быстрого чтения
Эти две структуры данных можно комбинировать.
Например, карта курьерской доставки, на которой располагаются обычные дома в одной структуре, а во второй будут курьеры, которые перемещаются.
Таким образом, я выяснил, где конкретно в играх (и не только) можно невероятно эффективно пользоваться этими данными, поэтому возьму эту структуру данных на вооружение.
Возвращаемся к вопросу об R*-tree на языке Go…
У меня ушло довольно много времени, ради того, чтобы понять, как это работает.
Сначала я попытался переписать R*-tree с Delphi на Go. У меня это заняло два дня и… не получилось, потому что я не понимал устройства этой структуры.
Тогда я выяснил для себя путь:
- Полностью переписать и разобрать каждое мелкое действие в готовом решении R-tree (rtreego)
- Разобрать статью об R*-tree, в которой были исходники на Delphi и псевдокоде
- Сделать из R-tree — R*-tree
Спойлер: у меня это удалось
Исходники того, что было сделано и из чего это было сделано
Во-первых, хочу проявить огромную благодарность человеку, создавшему rtreego — dhconnelly (автор этой библиотеки).
Во-вторых, хочу выразить невероятную благодарность человеку, который буквально на пальцах описал статью об R*-tree на своём опыте. Информации было невероятно мало, но именно эта статья ответила на многие вопросы! Статья *тык*
Ну, и в третьих, статьи из вики: R*-tree (wikipediam), R-tree (wikipedia на русском)
Из rtreego я взял за основу R-tree и, переварив код на Delphi и псевдокод из статьи, мне удалось создать R*-tree на языке Go, который работает ровно так, как описано по алгортиму.
Ссылка на репозиторий:
Самое важное —
Всем огромное спасибо за внимание и за то, что смогли осилить эту невероятно не маленькую статью!

4К открытий5К показов

Что такое Security Operations Center. Показываем, как SOC защищает данные. Рассматриваем основные метрики и нюансы ✔ Tproger

Пройди наш квиз и проверь, какой язык программирования тебе подходит больше всего. Проверь свои текущие знания и выбирай новое направление!

Самые лучшие курсы по Big Data. В предложенной подборке актуальные варианты обучения от проверенных школ, а так же рейтинги и цены на курсы для аналитиков Big Data

Microsoft переписала компилятор TypeScript на Go: сборка быстрее в 10 раз, но код работает так же. Что это меняет для разработчиков