Как использовать Redis для кэширования и очередей в веб-приложениях
Как использовать Redis для кэширования и очередей в веб-приложениях. Показываем основные возможности Redis. Рассматриваем пошаговую инструкцию ✔ Tproger

Ускорение работы приложений — один из краеугольных камней веб-разработки. Практически все веб-приложения основаны на взаимодействии пользователя или клиента с данными, хранящимися на удаленном сервере.
Для того чтобы получение и отправка данных были не только успешными, но и занимали как можно меньше времени, создано множество паттернов и инструментов. К ним относится, например, key-value система Redis, позволяющая загрузить необходимую информацию в оперативную память сервера.
О том, как установить и настроить Redis на популярных ОС и какие подходы использовать для повышения отказоустойчивости, читайте далее. Если вас интересует более глубокое погружение в веб-разработку, рекомендуем курс «Фулстек-разработчик».
Что такое Redis?
Redis — это система хранения данных в формате «ключ-значение». Основная его особенность в том, что данные хранятся in-memory, то есть в оперативной памяти, и время для их получения значительно сокращается.
Основные возможности Redis
Перечисление возможностей Redis начнем с поддерживаемых типов данных:
Строка (String): «Это текст»
- Список (List): [A B C B A D]
- Множество (Set): {B, D, C, A}
- Упорядоченное множество (Sorted set): {1:AA, 2:AB, 3:B, 4:BD, 5:C}
- Битовое поле (Bitfield): {122435}
- Битовая карта (битовый массив) (Bitmap): 001101010011010
- Геопространственные данные (Geospatial): {A: 12.03, B: 78.56}
Несмотря на то, что Redis нельзя назвать полноценной СУБД, он умеет многое из того, что доступно в нереляционных базах данных. Перечислим ключевые особенности его функциональности:
- Возможность хранения данных в оперативной памяти сервера.
- Обработка и изменение хранящихся в памяти данных.
- Библиотеки для работы с Redis есть во всех популярных языках программирования.
- Разнообразные подходы к конфигурации системы позволяют достичь высокого уровня отказоустойчивости без потери скорости работы.
- Специализированные клиенты с графическим интерфейсом позволяют просматривать информацию в удобном виде.
- Плагины для работы с Redis имеются в популярных CRM-системах, в том числе в WordPress.
Дополнительно стоит обратить внимание на существенные плюсы Redis:
- Высочайшая скорость работы и доступа к данным
- Простота горизонтального масштабирования
- Поддержка репликации
- Высокая отказоустойчивость Redis Cluster
- Легкость обслуживания
Сценарии использования Redis
In-memory система позволяет существенно снизить нагрузку на основную базу данных и ускорить обработку запросов благодаря работе в оперативной памяти. Среди основных целей использования Redis были и остаются:
- Кеширование
- Работа с пользовательскими сессиями
- Хранение счетчиков и метрик
- Отображение лент событий и сообщений
- Обработка очередей
Примеры и кейсы использования Redis рассмотрим чуть позже.
Установка и настройка Redis
Разберемся, как установить Redis на самые популярные серверные ОС. Так как Redis был написан под Linux, на серверы с Windows он устанавливается через wsl, а на Ubuntu, Debian и другие дистрибутивы – с помощью пакетного менеджера.
Для установки Redis на Windows Server первым делом нужно запустить WSL, после этого можно будет выполнять линукс-приложения и команды. В командной строке пишем:
На сервере начнется установка дистрибутива Ubuntu. После ее окончания нужно будет задать имя пользователя и пароль. Если Linux уже был установлен ранее, он просто будет запущен. В последующем можно будет пользоваться командой wsl без параметров.
Дальше установка идет одинаково для обоих вариантов ОС. В Windows вводим linux-команды после запуска wsl, в unix-системах – без дополнительных действий.
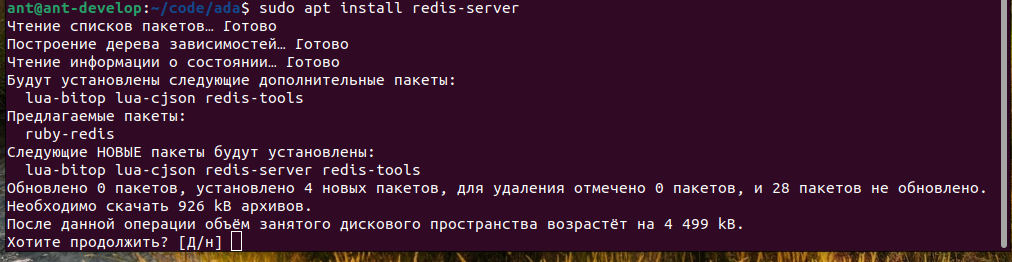
Если нужный пакет не найден, добавляем репозиторий и повторяем попытку:
Основные команды и конфигурация Redis
Когда Redis установлен, запускаем redis-cli и пингуем сервер для проверки работоспособности:
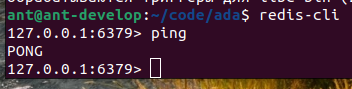
В ответ на эту команду в консоли должно отобразиться: PONG.
По умолчанию система использует порт 6379, при желании его можно изменить в конфигурации Redis. Там же можно дать доступ к серверу из внешней сети (после установки он доступен только по локальной) и установить пароль. Для этого открываем файл:
В файле делаем следующее:
- Меняем bind 127.0.0.1 -::1 на bind 0.0.0.0 — это обеспечит доступ всем сетевым интерфейсам, однако снизит безопасность!
- Раскомментируем строку requirepass, тем самым включая необходимость ввода пароля.
- В этой же строке прописываем сам пароль, желательно его сделать достаточно сложным, например: requirepass VeRy_vErY-GooDpa$$w0rD.
- Имя пользователя по-умолчанию — default.

Чтобы настройки применились, перезапускаем Redis:
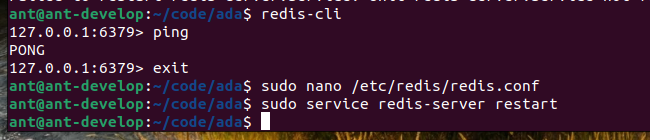
Проверяем активацию пароля с помощью redis-cli.
Клиенты для работы с Redis
Работать с Redis можно напрямую из, например, Python, а можно использовать специализированные GUI-клиенты с визуальным отображение данных — ниже некоторые из низ.
RedisInsight
Самый популярный на сегодня бесплатный инструмент для работы с Redis от Redis-Labs. Поддерживает все доступные типы данных и может их визуализировать. Ведет мониторинг нагрузки на сервер и использования оперативной памяти в режиме реального времени.
REST.app (RedisDesktopManager)
Еще один GUI-клиент для работы с данными, хранящимися в Redis. Обновлений не было с 2022 года, но на GitHub можно найти работоспособную версию с установщиком для Windows.
Redsmin
Облачный клиент для удаленного управления запущенным Redis-сервером в онлайн-режиме через веб-интерфейс.
Использование Redis для кэширования
Скорость отклика системы на действия пользователя — один из важнейших параметров веб-приложения, особенно когда это касается коммерческих разработок. Пользователи не любят долго ждать. Если сайт не загрузится или не обновит информацию за несколько секунд, велика вероятность того, что клиент просто закроет вкладку и уйдет к конкуренту.
Что такое кэширование и зачем оно нужно
Что позволит разработчику существенно ускорить отклик приложения без усиления серверного «железа»? В первую очередь с такой задачей справится кэширование: создание эдакого слепка наиболее часто используемых данных, который хранится либо на пользовательском устройстве, либо на стороне сервера. Причем кэш может быть как «теплым», так и «холодным». В первом случае данные подтягиваются в процессе работы с приложением, во втором — пакет информации формируется на сервере в момент его запуска. Холодный кэш актуален для сложных проектов, где нужно хранить, например, много актуальных счетчиков и метрик.
Благодаря наличию кэшированных данных пользователю не приходится ждать, пока приложение отправит запрос на сервер и получит от него ответ: информация отобразится практически без задержки.
Реализация кэширования с Redis
Один из популярных способов хранения кэша на сервере — запуск key-value хранилища Redis. Эта система позволяет хранить достаточно большое количество данных, ограниченное по сути лишь ресурсами системы, и быстро получать к ним доступ по уникальному ключу.
При записи данных в кэш Redis каждому ключу присваивается время жизни: этот параметр повлияет на то, как будут применяться механизмы удаления при переполнении выделенной для Redis памяти.
Чуть позднее мы рассмотрим варианты работы с истекшими ключами. Также данные можно удалить из Redis принудительно.
Считывание и удаление данных можно проводить как единично, так и передать в функцию массив ключей.
Паттерны кэширования
Разберемся, какие варианты реализации кэширования доступны в Redis:
- Приложение в первую очередь ищет данные в кэше, а в случае отсутствия — подтягивает их в кэш из основного хранилища, а потом отдает клиенту.
- Кэш обновляется в случае, если в нем обнаружена ошибка.
- Кэш обновляется каждый раз при обновлении данных в основном хранилище.
- Кэш обновляется по истечении определенного периода времени.
При разработке можно как пользоваться одним из указанных паттернов кэширования, так и применять их комбинацию.
Решение проблем с кэшированием
Рассмотрим основные проблемы, которые могут возникнуть при кэшировании данных с Redis, и приведем варианты их решения.
Возникновение ошибки в данных
Операции в Redis выполняются атомарно, а значит, случаются ситуации, когда какая-то часть информации не добирается до кэша. Например, в него записывается имя пользователя, но не записывается его фамилия. Решается применением первого паттерна, когда кэш синхронизируется с основным хранилищем при нахождении пробела в данных.
Оперативная память или ее объем, выделенный для хранения кэша, переполняется
Redis поддерживает несколько политик освобождения места. Выбрать их можно при конфигурации хранилища:
- volatile-lru — удаляются ключи с истекшим сроком действия, которые при этом не были недавно использованы
- volatile-ttl — удаляются ключи с истекшим или коротким оставшимся сроком службы
- volatile-random — удаляется случайный ключ из тех, чей срок службы завершился
- allkeys-lru — удаляет ключи, которые не использовались недавно, выбирая из среди всех ключей
- allkeys-random — удаляет любые случайные ключи
Заполнение кэша занимает большое количество времени.
Для сложных приложений и сайтов актуальны случаи, когда в кэш нужно загрузить большое количество сложно собираемых данных. Например, это могут быть счетчики и метрики для крупного интернет-магазина. Решается такое созданием так называемого «холодного кэша»: данные рассчитываются при старте сервера и грузятся в кэш еще до того, как клиент пытается получить к ним доступ.
Использование Redis для очередей сообщений
О существовании и механизме действия очередей знает, пожалуй каждый, кто бывал в магазине, поликлинике или на почте. Это такая вереница людей, присоединиться к которой можно только вслед за последним в ней стоящим. А первым к прилавку или заветной двери идет тот, кто первым занял место в этой самой очереди. Разберемся, как связаны очереди и веб-разработка.
Что такое очереди сообщений и зачем они нужны
Очереди сообщений или Message Queue — это метод взаимодействия между частями приложения в случае его микросервисной архитектуры. По сути, один из механизмов их реализации мало отличается от очереди в поликлинике: положить новые данные можно только в конец очереди, а получить — лишь из ее начала. Такие очереди называются FIFO (first in – first out), а их альтернатива, LIFO-очереди (last in – first out), знакомы многим под названием «стек». В стек данные добавляются «сверху», как блины в стопку, и для получения доступен именно последний добавленный элемент.
Очереди сообщений позволяют передавать данные от одной части приложения к другой, не храня в каждом из них лишней информации и делясь лишь тем, что требуется в текущий момент. При этом каждый сервис забирает свое сообщение из очереди только тогда, когда готов его обработать, а очередь выступает в роли буферной зоны даже в случае неработоспособности сервиса-получателя.
Реализация очередей с Redis
Несмотря на то, что чаще всего веб-разработчики используют Redis для кэширования, он позволяет также реализовать и очереди, хотя и имеет в этом отношении несколько существенных недостатков.
Во-первых, Redis «из коробки» не является полноценным брокером сообщений и атомарное выполнение операций не дает уверенности в 100% доставке пакета. Как и в случае с потерей данных при загрузке в кэш, из очереди может быть передано сообщение №1, но не передано или утеряно сообщение №2. Если клиент пропустил сообщение, не принял, подписался на доставку позже — информация потеряна. Сервис-подписчик взял сообщение, но завис и перезагрузился — потеряна снова.
Тем не менее, очереди в Redis реализуемы при помощи переменных типа List или SortedSet в зависимости от задач. Приведем пример работы с ними:
Для работы с очередями в Redis доступна также команда getQueueLength (определяет размер массива элементов).
Обработка очередей в многопоточном окружении
С обработкой данных в один поток все предельно ясно: FIFO и LIFO очереди вполне справляются со своими задачами. Но что делать в случае многопоточности, когда к одной из очередей одновременно могут обратиться несколько клиентов или, наоборот, ни одного? Фактически, скорость работы Redis позволяет работать с многопоточным окружением точно так же, как и с однопоточным. Но ускорить взаимодействие и снизить шансы отказа может кластеризация, о которой мы поговорим позднее.
Паттерны использования очередей с Redis
Вот три основных подхода к очередям в Redis:
- Формат публикация-подписка (pub/sub). Доступ ко всем сообщениям в конкретной очереди имеют все «подписчики». Если никто не запрашивает данные (никто не подписан на очередь), они удаляются.
- FIFO-очередь с помощью простого list. Сообщение из очереди получает только первый его запросивший.
- Собственный тип данных Stream (поток). Похож на вариант pub/sub, но при отсутствии подписчиков сообщение не удаляется, а ждет запроса.
Обработка ошибок и повторное выполнение задач
Как уже было упомянуто, атомарность операций в Редисе может стать причиной ошибок. Часть данных может быть не записана или не доставлена, при этом Redis не определит проблему до того, как клиент попытается считать необходимую информацию. Именно поэтому бремя отслеживания ошибок в данных ложится на программиста. Например, может использоваться отдельный массив, в него клиенты будут добавлять ключи, информация по которым не была найдена. А дополнительный сервис будет отслеживать его наполнение и инициировать повторное выполнение задач по записи необходимых данных в Redis.
Оптимизация производительности с Redis
Redis по праву считается очень быстрой системой, но как нет предела совершенству, так нет предела и оптимизации производительности. Даже миллисекунды, отыгранные у процессов, в итоге вырастают в ощутимое ускорение работы приложения. Далее рассмотрим, какие настройки и способы помогут увеличить скорость обработки данных в Redis.
Настройка памяти и политики вытеснения
Редис хранит данные в оперативной памяти, а она, как известно, не бесконечна, если не приравнивать к ней файлы подкачки. Последний лежит на жестком диске, и даже на твердотельном накопителе обрабатывается в разы медленнее. Redis позволяет отключить возможность автоматического создания файла подкачки и ограничить доступный объем оперативной памяти. Для этого в конфигурационном файле указывается maxmemory, например, 1gb. Если в момент добавления новых данных он уже достигнут, Редис произведет запись, а после этого начнет автоматически удалять некоторые ключи. Какие именно — определяется политикой вытеснения. о которой и поговорим ниже.
Мы уже касались параметра «время жизни», когда говорили о кэшировании. Теперь подробнее разберем, какие варианты удаления ненужных данных может реализовать Redis.
- Установка параметра maxmemory-policy noeviction в файле конфигурации. При достижении лимита памяти ключи не удаляются, сервер выдает ошибку при попытке записи новых данных и отвечает только на команды чтения.
- Алгоритм LRU (last recently used). При переполнении памяти начинается удаление ключей, к которым не было обращений в последнее время.
- Алгоритм LFU (Least Frequently Used). Редис первыми удаляет ключи, имеющие минимальный счетчик обращений в целом.
Кластеризация Redis и шардирование
Повысить отказоустойчивость системы можно, убрав единую точку вероятного нарушения работоспособности. Для этого при запуске Redis создают кластеры: системы из нескольких экземпляров. Если одни из них выйдет из строя, клиент сможет получить нужное от другого.
Дополнительный бонус от кластеризации Redis в том, что работа системы не остановится в случае обработки тяжелого запроса, следующую задачу сможет выполнить другой экземпляр.
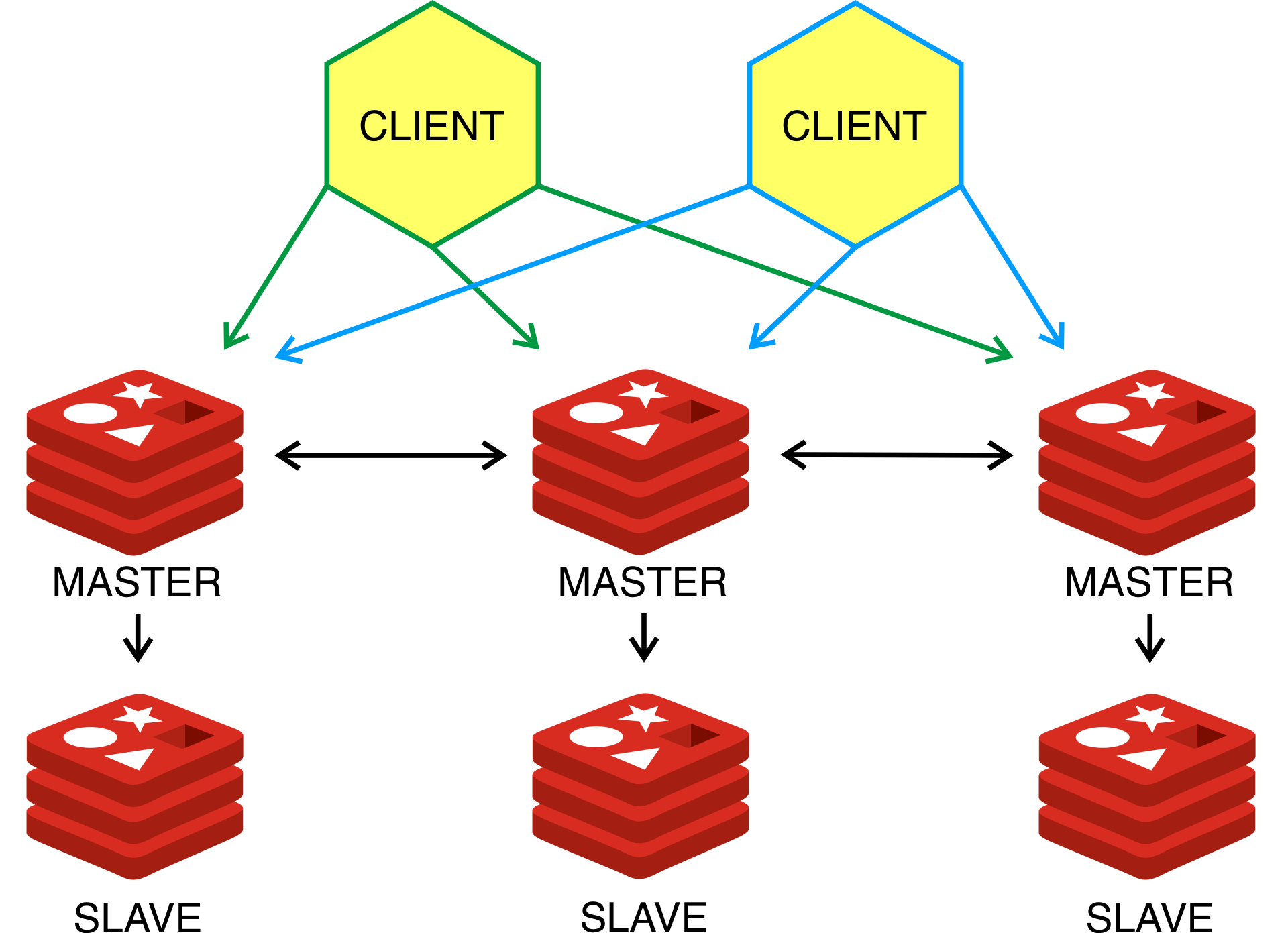
Также при запуске нескольких экземпляров Redis можно использовать шардирование, то есть распределение данных по разным экземплярам, а не их дублирование. Есть разные способы шардирования, но по сути они все сводятся к двум вариантам:
- Логику распределения данных определяет приложение-клиент, отправляя запросы на чтение и запись к определенному экземпляру системы.
- В случае с запуском Redis-кластера логика может быть задана на сервере. Так, информация о данных, хранящихся на каждом Slave, доступна каждому Master, а запросы клиента автоматически перенаправляются.
Мониторинг и управление Redis
Как театр начинается с вешалки, так и многие веб-приложения сегодня начинаются с Redis. А значит, его работоспособность и скорость отклика — важнейшие параметры, которые необходимо отслеживать, причем желательно делать это постоянно и оперативно. Для управления и мониторинга запущенного экземпляра Redis можно использовать, например, GUI-клиенты из тех, которых мы касались выше. Также мониторинг доступен с помощью Prometheus, специального сервиса для сбора и хранения различных метрик.
Просматривать его данные можно через веб-интерфейс или графические клиенты, например, Grafana.
Можно узнать многое о текущем состоянии системы и через терминал — для этого в redis-cli нужно ввести команду info. При ее выполнении в командной строке отобразятся:
- redis_mode – выбранная структура системы (одиночный экземпляр, кластер и другие)
- порт
- расположение файла конфигурации
- количество подключенных клиентов
- объем используемой памяти
- общее количество подключений и другие параметры
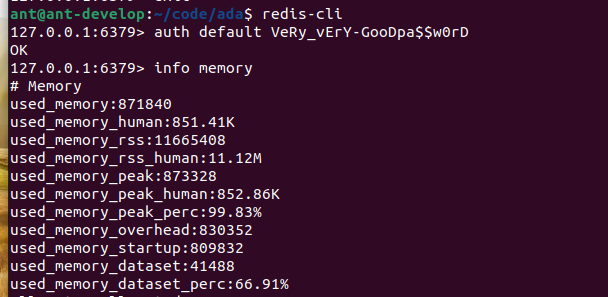
Основные изменения конфигурации системы вносятся в файл config, после его редактирования сервер необходимо перезапустить для применения внесенных правок.
Безопасность и резервное копирование данных в Redis
Как и для любой другой системы, для Redis важна безопасность как с точки зрения недоступности для злоумышленника, так и в вопросе сохранения данных в случае отключения.
Защита Redis
Чтобы повысить безопасность Redis в первую очередь стоит придерживаться базовых правилам:
- Пользоваться межсетевым экраном
- Установить действительно сложный пароль
- Ключевые команды (отключение или очищение кэша) можно переименовать
- Не запускать Redis с root-доступом
- Настроить политики доступа для разных пользователей
Конечно, не стоит забывать и об элементарных и так любимых системными администраторами вещах, как хранение пароля на наклейке под монитором, доступ посторонних к серверу и прочем.
Резервное копирование и восстановление данных
Но даже если к вашему серверу и не могут получить доступ злоумышленники, он все равно не застрахован от рисков. Даже банальное отключение электричества и не справившиеся ИБП могут стать причиной потери всех данных. А значит, лозунг «делай бэкапы!» актуален и в случае с Redis. Для резервного копирования в нем можно использовать моментальные копии базы данных, получаемые по команде save или bgsave. Разница этих команд в том, что save приостанавливает работу Redis, а bgsave выполняется в фоновом режиме. При их запуске создается файл rdb, из которого при желании можно восстановить базу данных на текущем или любом другом Redis-сервере.
Еще один вариант повышения сохранности данных — их репликация в редис-кластере на экземпляр, находящийся на другой физической или виртуальной машине.
Практические примеры и кейсы
Перейдем к некоторым кейсам практического применения Redis.
Реализация сессий с помощью Redis
Для хранения пользовательских сессий требуется запущенный экземпляр Redis и доступ к нему для веб-сервера. Если на сервере используется php, то нужно будет установить пакет php5-redis и поменять в файле php.ini следующие строки:
После этого все сессии будут автоматически сохраняться в Redis без каких-либо дополнительных действий со стороны разработчика.
Кэширование API-запросов
Кэширование — один из наиболее часто используемых вариантов применения Redis. В данном случае рассмотрим ситуацию, когда в кэше будут храниться данные, полученные по запросу от API вашего приложения. Для реализации этого нужно будет пройти следующие шаги:
- Установить и запустить Redis.
- Определить, какие именно данные нужно хранить в кэше.
- Написать на используемом вами языке программирования их получение или рассчет по API-запросу.
- Добавить полученные данные в кэш Redis.
- При запросе от API сначала проверять, имеется ли нужная информация в кэше, и запрашивать их у основной системы только при отсутствии.
Кэш для API может применяться, например, для хранения информации о подключениях пользователей к приложению. При каждом взаимодействии пользователя с нашим API мы должны обновлять значение last_visit в таблице user и отображать эти данные. Но если пользователей много и они очень активно взаимодействуют с API, то они просто заспамят основную базу данных постоянными запросами update. Удобный и простой вариант — хранить эти данные в redis, например, в sorted_set, и написать механизм периодической отправки большого обновления в основную БД.
Управление очередями задач в крупномасштабных приложениях
Один из примеров того, как можно использовать Redis и его механизм очередей в больших и сложных приложениях — это задача кредитного скоринга. Когда подсчитаны данные по конкретному клиенту, система должна уведомить об этом менеджера, отправив ему письмо на email. Для того, чтобы не занимать ресурсы сервера, эту задачу можно делегировать отдельному сервису, а сами подсчитанные данные хранить в Redis для быстрого доступа и отправки. Микросервис, отвечающий за рассылку сообщений, сможет получать из очереди электронные адреса менеджеров и предназначенные им пакеты информации.









![Обложка: Как стать аналитиком данных за 6–12 месяцев [гайд]](https://media.tproger.ru/uploads/2025/12/1c7c4818-f579-4330-b4fe-56704d1972e0.jpg)


