


Как эффективно анализировать статистику в PostgreSQL с помощью pg_profile
Разбираем pg_profile — инструмент для анализа статистики запросов к базе данных. Рассказываем про установку, отчёты и примеры использования.
24К открытий42К показов
pg_profile — это расширение для Postgres (PL/pgSQL), которое собирает статистику запросов к базе данных и делает их снимки. Оно позволяет найти места, которые создают наибольшую нагрузку, c его помощью можно понять, что нужно изменить в структуре, чтобы база данных работала с необходимой скоростью. Как с ним работать, рассказал инженер разработки Газпромбанка.

Александр Булгаков
Установка pg_profile
Примеры использования
Как собранная статистика отображается средствами расширения
Как получить выгоду от отчётов
Стандартная статистика Postgres сохраняет информацию только по ограниченному количеству запросов, что может привести к потере информации по большому количеству запросов. Расширение же делает снимки за заданный интервал времени, что помогает минимизировать эту потерю или даже исключить её полностью. Благодаря этому также можно посмотреть статистику в конкретный период времени, какие обрабатывались запросы, насколько быстро они работали.
Установка pg_profile
Расширение можно поставить, не перезагружая базу данных и не останавливая работу связанных сервисов.
Сейчас на наших серверах используется поставка Postgres Pro с модулем pgpro_pwr версии 0.3.2. pgpro_pwr — это расширенная версия pg_profile для работы в дистрибутивах PostgresPro. В ней собрано больше статистик производительности.
Устанавливаем файл расширения
Создаём необходимые параметры расширения
Модуль dblink нужен для подключения к другим базам данных из сеанса базы данных.
Этот модуль отслеживает статистику по всем базам данных на сервере. Для её получения и обработки есть и вспомогательные функции: pg_stat_statements_reset и pg_stat_statements.
Модуль pg_stat_statements нужно загрузить в shared_preload_libraries в файле postgresql.conf, так как ему требуется дополнительная разделяемая память. Для загрузки или выгрузки модуля нужно перезапустить сервер.
Получаем более полную статистику
Для статистики по операторам можно установить расширение pgpro_stats. Обратите внимание на этот параметр:
- pgpro_stats.max
Когда объём статистики близок к значению pgpro_stats.max, то в отчёте об этом появится предупреждение.
С помощью конфигурационных параметров, которые нужно установить в файле postgresql.conf можно настроить выборочное выполнение сбора статистики. Их можно включать и выключать в отдельных сессиях командой SET.
- Параметр track_activities отслеживает текущие команды, выполняемые любым серверным процессом.alter system set track_activities = ‘on’;
- Параметр track_counts обращается к таблицам и индексам, чтобы определить необходимость сбора статистики.alter system set track_counts = ‘on’;
- Параметр track_functions отслеживает использование пользовательских функций.alter system set track_functions = ‘all’;
- Параметр track_io_timing отслеживает время чтения и записи блоков.alter system set track_io_timing = ‘on’;
- Параметр track_activity_query_size задаёт объём памяти, необходимый для хранения текста выполняемой команды. По умолчанию значение задаётся в байтах — 1024. У нас — 2048.alter system set track_activity_query_size = ‘2048’;
Перезагрузить конфиг можно через select pg_reload_conf();
Установить подключения:
Устанавливаем обновления
Для обновления нужно только установить файлы расширения и обновить расширение:
Примеры использования
Как сделать снимок статистики через SQL:
Как сделать снимок статистики через shell:
Как построить отчёт за определённый отрезок времени, определяемый относительно:
Как построить отчёт для локального сервера за интервал из выборки:
Как построить отчёт из последних произведённых запросов:
Как сохранить отчёт в html-файл через SQL:
Как получить список снимков за сутки через SQL:
По умолчанию количество объектов в отсортированных таблицах (и снимках) равно 20:
Время хранения снимков (в сутках) равно 7 дням также по умолчанию:
Как собранная статистика отображается средствами расширения
Разработчику важно, чтобы запросы, которые он отправляет к базе данных, работали с желаемой скоростью. Расширение поможет ускорить процесс анализа и покажет состояние базы данных: размер каждой таблицы, эффективность индексов. Оно автоматически собирает информацию, которая в базе данных разложена в разных местах. Если делать это вручную, то может уйти много времени на поиск нужной информации в БД. Тогда как расширение делает это самостоятельно каждый час. Для этого в отчёте pg_profile есть таблица, которая поможет понять, какие запросы работают медленно.
Top SQL by execution time
Таблица отчёта показывает запросы с наибольшей длительностью выполнения, определяемой по значению поля total_time представления pgpro_stats_statements или pg_stat_statements.

Что означают столбцы таблицы
- Query ID — шестнадцатеричное представление queryid. Хеш от идентификатора запроса, идентификатора базы данных и идентификатора пользователя находится в квадратных скобках.
- Database — имя базы данных, в которой выполнялся запрос.
- Exec (s) — время, потраченное на выполнение плана запроса.
- %Total — отношение времени плана запроса к общему времени выполнения всех запросов.
- Read I/O time (s) — время чтения страниц при выполнении плана.
- Write I/O time (s) — время записи страниц при выполнении плана.
- Rows — число полученных или обработанных строк.
- Mean execution times (ms) — среднее время выполнения плана.
- Min, max execution times (ms) — минимальное и максимальное время выполнения плана.
- StdErr execution times (ms) — стандартное отклонение времени выполнения плана.
- Executions — количество выполнений плана.
Из таблицы можно сделать некоторые выводы:
- ab11b1b1c5 — скорость выполнения запроса допустимая (по среднему значению).
- 5c6664c234 — выполнение запроса желательно оптимизировать.
- 9b07051c9b — выполнение запроса желательно оптимизировать.
Top tables by estimated sequentially scanned volume
Показывает таблицы с наибольшим приблизительным объёмом, отсканированным последовательным образом. С помощью отчёта можно понять, для каких таблиц не хватает индексов. Эта информация основана на представлении pg_stat_all_tables.
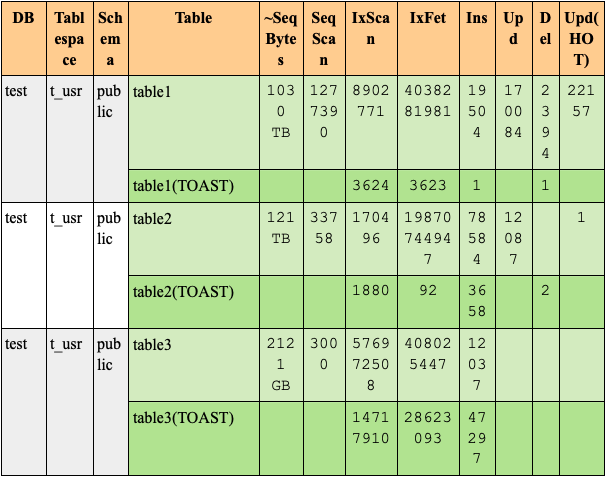
Что означают столбцы таблицы
- DB — имя базы данных.
- Tablespace — имя табличного пространства таблицы.
- Schema — имя схемы с таблицей.
- Table — имя таблицы.
- ~SeqBytes — приблизительный объём, просчитанный при последовательном сканировании.
- IxScan — количество сканирований по индексу.
- IxFet — количество отобранных строк при сканировании.
- Ins — количество вставленных строк.
- Upd — количество изменённых строк.
- Del — количество удалённых строк.
- Upd (HOT) — количество строк, изменённых по системе HOT.
Unused indexes
Если за отчётный интервал было больше всего изменений, требующих поддержания индекса, но при этом сами индексы не использовались, то он покажет такую таблицу. Индексы ограничений при этом не учитываются. Эта информация основана на представлении pg_stat_all_tables.
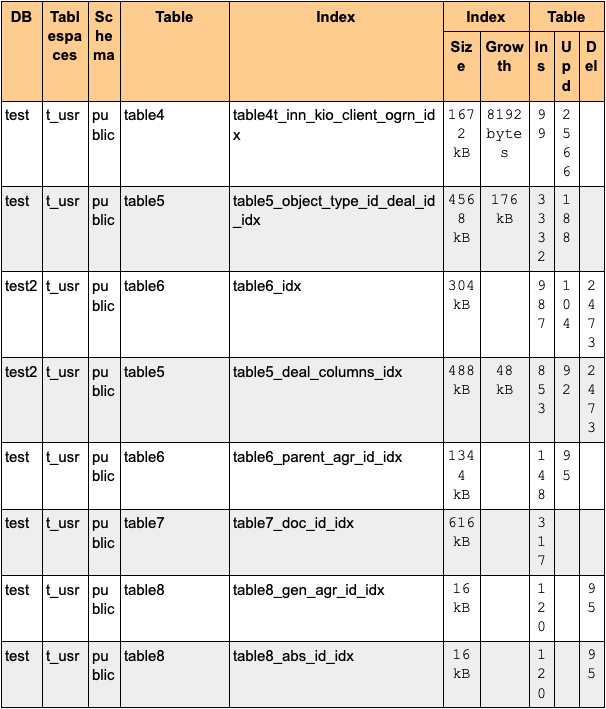
Что означают столбцы таблицы
- Index — имя индекса.
- Index Size — размер индекса при получении последней выборки отчётного интервала.
- Index Growth — прирост объема индекса за отчётный интервал.Выводы из таблицы:
- Выполнение запроса (выборка из лога обмена с АСК по статусу и признаку отправки) желательно оптимизировать.
- Выполнение запроса (выборка из лога обмена с АСК по идентификатору запроса) желательно оптимизировать.
Как получить выгоду от отчётов
Расширение позволяет анализировать статистику и не терять полезную информацию. Но как получить профит от этого отчёта?
Здесь пригодится Tensor Explain — сервис для разбора и визуализации планов запросов. С его помощью можно ещё быстрее и нагляднее представить, как выглядит запрос для базы данных: лёгкий ли он, есть ли у него проблемы и в каких местах.

План запроса может включать в себя много параметров, например, примерный расчёт выполнения запроса: какие таблицы объединяются, как они объединяются, используется ли индекс для анализа при выборке данных.
Какими средствами анализа статистики запросов пользуетесь вы? Расскажите в комментариях, какие инструменты считаете наиболее эффективными.

24К открытий42К показов
Хотите в Data Science, но не знаете, какое направление выбрать? Собрали признаки, которые помогут определиться и выбрать профессию.

В статье Максим Морев расскажет, что такое подход As Code, как он развивался и почему он нужен компаниям.

На стажировке от Газпромбанка для студентов новый набор: 13 направлений, практика и оформление в штат с зарплатой. Успейте подать заявку!

Рассказываем, где и над чем работают Perl-разработчики, и делимся подборкой полезных материалов для изучения языка.