


Как хранить лайки социальных сетей в базе данных ScyllaDB

Разбираемся, как обновлять большие данные в базах на ScyllaDB, если они постоянно меняются. В качестве примера используем социальные сети.
3К открытий4К показов
Задумывались ли вы когда-нибудь о том, как Instagram, Twitter, Facebook или другие платформы социальных сетей отслеживают, кому понравились ваши посты? Давайте разберемся в этом посте!
Это — перевод оригинальной статьи Database 101: How social media “likes” are stored in a database на английском языке. Повествование ведется от лица автора — Daniel Reis.
Пролог
Недавно меня пригласили выступить на мероприятии под названием «CityJS». Но вот в чем дело: я парень из PHP. Я вообще не занимаюсь JS, но я принял вызов.
Для мероприятия мне нужно было найти хороший пример работы высокомасштабируемой база данных с низкой задержкой.
Я попросил одного из коллег поискать примеры. Он предложил искать большие числа внутри любой платформы вроде счетчиков. В этот момент я понял, что любой тип метрик может подойти под этот пример: лайки, просмотры, количество комментариев и подписок.
В этой статье вы найдете мои исследования о том, как сделать правильное моделирование данных для счётчиков с помощью ScyllaDB.
Начинаем исследовать

Сперва я должен был понять, как построить эту модель данных.
Нам понадобится таблица posts и также таблица post_likes, в которой указывается, кому понравился каждый пост. Пока этого кажется достаточно, чтобы сделать наш счетчик лайков.
Мой первый вариант запроса для подсчета всех лайков был примерно таким:
Хорошо, если я просто сделаю запрос SELECT count(*) FROM social.post_likes, это может сработать, верно?
Что ж, это сработало, но оказалось не таким производительным, как ожидалось, когда я провел тест с парой тысяч лайков в одном посте. Чем больше было лайков, тем запрос становился медленнее.
Но ScyllaDB может легко обрабатывать тысячи строк… Почему же она не так производительна в нашем случае?
ScyllaDB — даже как база данных с классными возможностями — не решит проблему плохого моделирования данных.
Нам нужно подумать, как сделать все быстрее.
Изучение типов данных
Давайте подумаем: что если я создам новую строку как целое число в таблице posts и буду увеличивать/уменьшать число каждый раз, когда будет поставлен или убран лайк?
Это кажется хорошей идеей, но есть проблема: нам нужно отслеживать каждое изменение в таблице posts, и при обновлении данных мы создадим кучу бессмысленных записей в БД.
Это особенность ScyllaDB: каждый раз, когда нужно обновить имеющиеся данные, вы фактически создаете новые данные.
Таким образом, на каждое увеличение постов и лайков будет создаваться еще один ряд записей, если только вы не меняете ключи кластеризации или не заботитесь о временных метках (очень глупая идея).
После этого я залез в документацию ScyllaDB и обнаружил, что существует тип под названием counter, который подходит для наших нужд и считается ATOMIC.
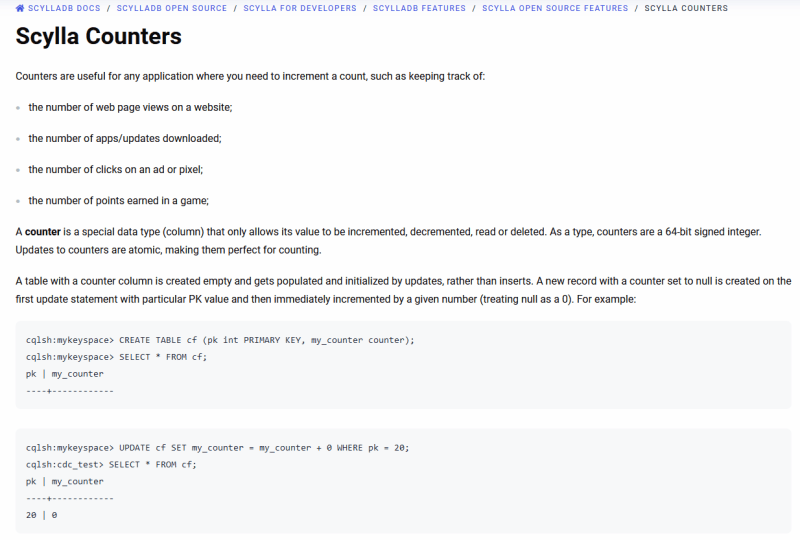
Хорошо, он подходит для наших нужд, но не для моделирования данных. Чтобы использовать counter, мы должны следовать правилам, и некоторые из них вызывают проблемы:
- Единственными другими столбцами в таблице со столбцом счетчика могут быть только столбцы первичного ключа (который нельзя обновлять).
- Никакие другие типы столбцов не могут быть включены.
- Для работы с таблицами, имеющими тип данных counter, необходимо использовать запросы UPDATE.
- Вы можете только увеличивать или уменьшать значения, установка конкретного значения не допускается.
Это ограничение защищает корректную обработку обновлений со счетчиками и без счетчиков, не допуская их в одной операции.
Итак, мы можем использовать этот счетчик, но не в таблице постов… Хорошо, кажется, мы нашли способ решить эту задачу.
Правильное моделирование
Учитывая информацию о том, что тип счетчика не должен быть «смешан» с другими типами данных в таблице, единственный вариант, который нам остается — это создать НОВУЮ ТАБЛИЦУ и хранить в ней данные этого типа.
Итак, я создал новую таблицу post_analytics, в которой будут храниться только типы счетчиков. На данный момент будем работать только с лайками, так как у нас уже создано отношение Many to Many (post_likes).

Следующие запросы — это то, что вы, вероятно, будете выполнять для проверки нашего примера:
Теперь у вас в голове могут появиться новые вопросы: «Значит, каждый раз, когда мне нужен новый счетчик, связанный с какими-то данными, мне понадобится новая таблица?».
Зависит от того, как использовать данные.
В случае с социальными сетями, если вы хотите хранить данные о том, кто видел сообщение, вам, вероятно, понадобится таблица post_viewers с session_id и кучей других данных.
Простые запросы, которые можно выполнять без джойнов, будут намного быстрее, чем запросы типа count(*).
Заключение
Я многому научился, не только изучая новые способы моделирования данных, но и изучая TypeScript для создания презентации CityJS и построения этого сценария использования.
Не забудьте поставить лайк этому посту и наполнить свою бутылку водой.

3К открытий4К показов

Работать на удалёнке прекрасно, за исключением одного — всё время нужно что-то готовить. А для этого — придумать, что бы такого вкусного тебе хотелось съесть сегодня.
Меня зовут Лена Райан, я фронтенд-разработчик в Точка Навыки. Недавно закончила свой новый пет-проект — приложение, которое анализирует, какие продукты уже есть дома, и даёт подсказки, что можно из них сделать. В этой статье рассказываю, с какими сложностями пришлось столкнуться, и что в итоге получилось.

Развитие ИТ с 1950 до наших дней рассмотрим 5 волн развития, что было со специалистами и технологиями. Попробуем угадать тренды и сделать рекомендации по развитию
Рассказываем, как мы заставили GX подружиться с Impala.

Газпромбанк.Тех совместно с Научно-технологическим университетом «Сириус» объявляет о старте отбора на образовательный интенсив для будущих специалистов в области анализа данных и машинного обучения. Участие в программе полностью бесплатное.