Как работает Sharding в базах данных?
Что такое Sharding. Показываем, как работает шардинг в базах данных. Рассматриваем пошаговую инструкцию и основные нюансы ✔ Tproger

Когда данных становится слишком много для одного сервера, на помощь приходит шардинг — способ разбить базу на части и разложить их по разным машинам. Это помогает масштабироваться, ускоряет запросы и снижает нагрузку. Но вместе с плюсами шардинг приносит и новые сложности: как искать данные, как проводить транзакции между серверами, как считать агрегаты. Сегодня разбираемся, как всё устроено, какие бывают подходы к шардингу и что нужно учесть при его внедрении.
Как работает database sharding
Database sharding (шардирование базы данных) — это техника горизонтального масштабирования, при которой большая база разделяется на несколько частей. Их называют шардами. Эти шарды распределяются по другим серверам и связываются в одну систему. Рассмотрим подробнее.
Принцип: разбиение данных на независимые сегменты (шарды)
Каждый шард работает как отдельная независимая база данных. Ключевым элементом здесь выступает ключ шардирования (shard key). Это правила, которые определяют, в какой именно шард попадёт конкретная строка данных.
Например, мы можем задать правило: если у нас есть user_id и его значение меньше тысячи, то данные попадают в шард 1, если значение больше тысячи, то в шард 2.
Главная цель такого разделения — добиться независимости шардов. В идеале запрос, касающийся данных одного пользователя (или одного документа, заказа и т. д.), должен обрабатываться только одним шардом.
Так, мы можем параллельно обрабатывать много запросов и увеличивать пропускную способность системы.
Общая архитектура: клиент — роутер — шард
Чтобы приложение могло понять, в какой шард отправить запрос, нужна особая архитектура.
Клиент: Программа на стороне пользователя, которая отправляет стандартный запрос к базе данных (например, SELECT * FROM users WHERE user_id = 123).
Маршрутизатор запросов или роутер (Query Router): Это что-то вроде посредника между клиентом и шардом, который выполняет роль диспетчера. Он принимает запрос, при помощи sharding ключа определяет, что это за данные, в какой шард и с какой целью их надо отправить. Далее он отправляет запрос на нужный шард.
Шард (Shard): Получает запрос, выполняет и возвращает результат обратно маршрутизатору, который затем передаёт его клиенту.
Благодаря такой архитектуре мы можем «скрыть» database sharding на стороне клиента и обеспечить централизованное управление запросами. Не надо сильно заморачиваться с кодом и архитектурой приложений, ведь вся логика будет на серверах.
Основные компоненты: шард, маршрутизатор, реплика-сеты
Мы уже рассмотрели, что такое шарды и маршрутизаторы, теперь обратим внимание на реплика-сеты. Это сервера с копией данных шардов. Если главный сервер шарда выходит из строя, одна из реплик автоматически берёт на себя его роль. Так, мы можем повысить отказоустойчивость нашей системы.
Ещё в этой схеме обычно применяют серверы конфигурации. Это отдельный компонент, который хранит метаданные о шардах. Он содержит информацию о том, какие диапазоны ключей или хеши какому шарду соответствуют. Маршрутизаторы периодически обращаются к серверам конфигурации, чтобы получить актуальную карту распределения данных и лучше понять, в какой шард направить тот или иной запрос.
Виды шардинга
Существует много вариантов, как разбить базу данных на шарды. Этот выбор будет зависеть от множества факторов: структуры данных, типичных запросов, требований к производительности и сложности управления. Разберём основные виды шардинга.
Горизонтальный sharding (по строкам): самый популярный
При горизонтальном шардинге мы «нарезаем» нашу базу данных по строкам. Допустим, у нас таблица с клиентами. Мы задаём диапазон ключу шардирования с user_id от 1 до 1 000 000. Данные в этом диапазоне, построчно будут храниться в шадре 1. Если user_id попадает в диапазон от 1 000 001 до 2 000 000, то эти данные отправляем на шадр 2. И так далее.
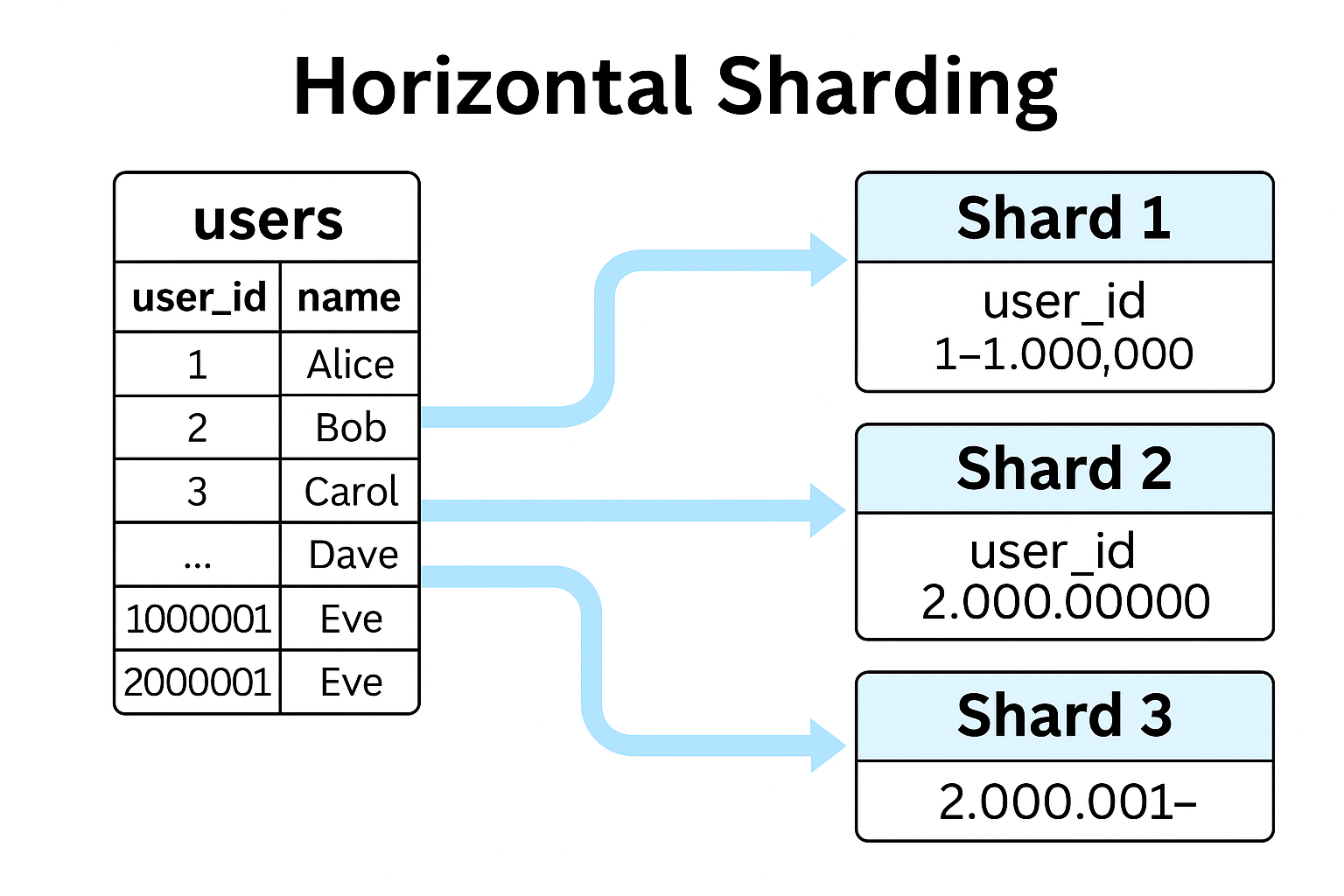
Благодаря этому способу мы можем равномерно распределять данные, и нам будет проще масштабировать систему при помощи создания новых шадров и добавления серверов.
Горизонтальный sharding — идеальный вариант, когда основная проблема — это огромное количество строк в таблицах и высокая нагрузка на чтение/запись.
Вертикальный шардинг (по столбцам): разделение по функциональности
Если горизонтальный шардинг режет таблицу поперёк (по строкам), то вертикальный — вдоль, разделяя столбцы. Таблица делится на несколько с меньшим количеством столбцов. Обычно они группируются по частоте использования или по смысловой нагрузке. Например, в таблице юзеров можно выделить часто запрашиваемые user_id, username, email в одну таблицу, а редко используемые — biography, preferences, last_login_details — в другую.
Это полезно, когда у таблицы очень много столбцов или когда группы столбцов имеют совершенно разные паттерны доступа. Мы можем улучшить производительность запросов, так как они работают с таблицами меньшей ширины.
Directory-based sharding: использование хеш-таблицы маршрутов
При горизонтальном и вертикальном шардинге маршрутизатор часто сам, при помощи специальных функций, определяет, какие данные в какой шадр отправить. Это не всегда удобно. При таком подходе мало гибкости. Поэтому был придуман вид шардинга, который опирается на хеш-таблицы и называется directory-based. Его суть в том, что мы создаём централизованный каталог, который связывает наши ключи шардирования и шарды.
Вот пример того, как это работает:
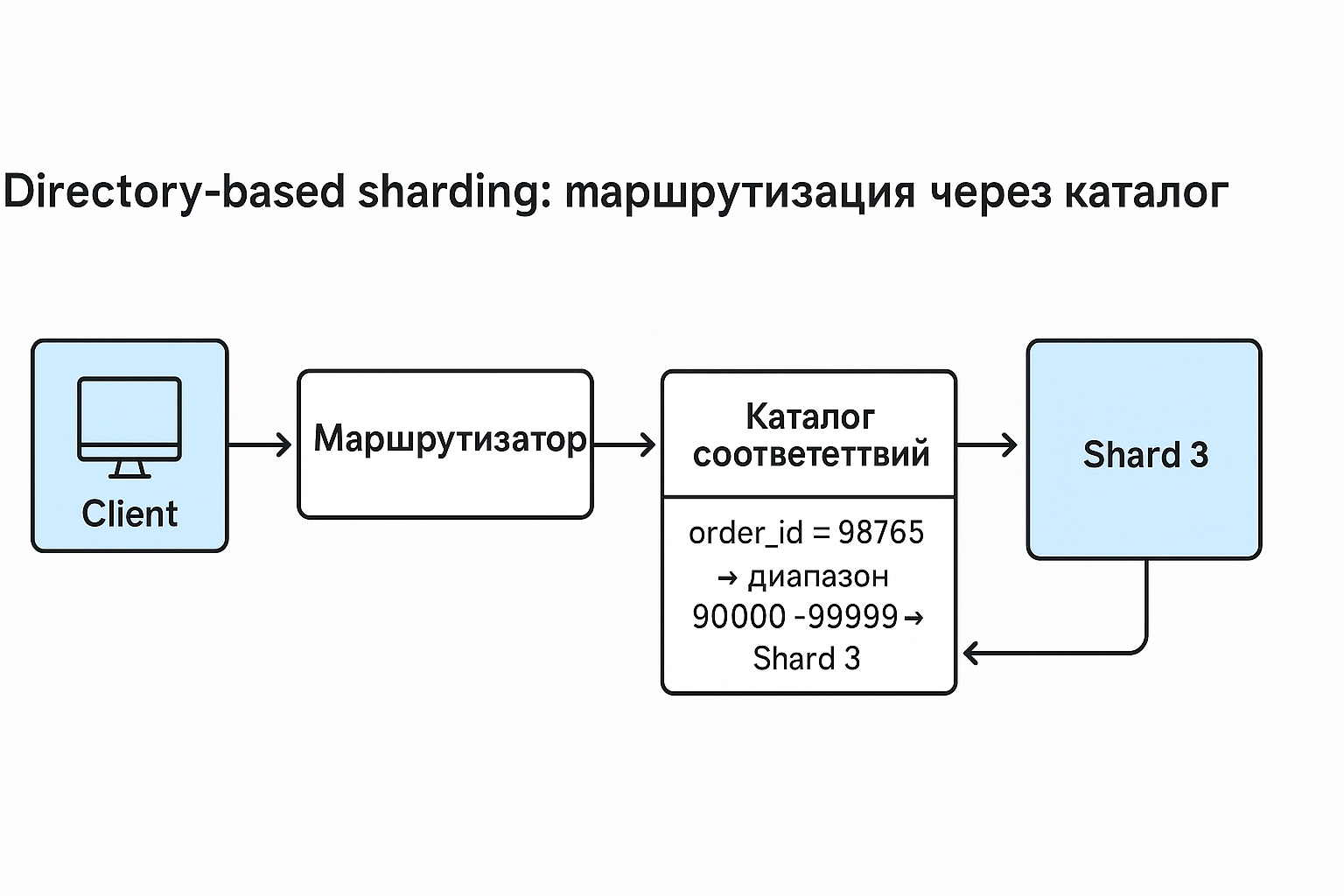
- Клиентское приложение отправляет запрос (например, получить данные для order_id = 98765).
- Маршрутизатор запросов перехватывает его.
- Маршрутизатор обращается к каталогу: с запросом, где найти order_id = 98765.
- Каталог ищет в своей таблице соответствий правило, под которое подпадает order_id = 98765. Для быстрого поиска он часто использует эффективные структуры данных, такие как хеш-таблицы или B-деревья (это внутренняя деталь реализации самого каталога).
- Допустим, каталог находит правило «Диапазон order_id 90000-99999 → Shard-3» и сообщает это маршрутизатору.
- Маршрутизатор перенаправляет исходный запрос на Shard-3.
При таком подходе удобнее перемещать данные между шардами, изолировать их и менять логику.
Range-based sharding: разбиение по диапазонам значений
По сути, это тот же горизонтальный sharding с разбиением данных на кусочки по строкам при помощи диапазонов.
Администратор системы (или автоматизированный инструмент) определяет границы диапазонов для ключа шардинга. Маршрутизатор получает запрос, смотрит на значение этого ключа и сравнивает его с известными диапазонами, чтобы определить целевой шард.
Этот способ простой, логичный и отлично подходит для работы с данными за определённый период. Но у него есть проблема. Допустим, мы запустили форум и проводим шардирование по трём ключам:
- id от 1 до 1000 — шард 1;
- id от 1001 до 2000— шард 2;
- id от 2001 до 3000 — шард 3.
Когда пользователи начнут регистрироваться, у нас будет активен шард 1, потом шард 2. Далее вся нагрузка перейдёт на шард 3. Они не будут одновременно равномерно работать. Это может стать проблемой при оптимизации.
Hash-based sharding: равномерное распределение по хешу ключа
Этот подход помогает добиться максимально равномерного распределения нагрузки по всем шардам. Работает следующим образом:
Берём значение ключа для конкретной строки данных (например, user_id = 2001).
Применяем к нему хеш-функцию. Хеш-функция (например, MD5, SHA-1, MurmurHash) — это алгоритм, который превращает входные данные (наш user_id) в строку или число фиксированной длины (хэш), которое выглядит почти случайно. Даже небольшое изменение на входе (например, user_id = 2001 и user_id = 2002) обычно даёт совершенно разные хеши.
Вычисляем номер шарда. Чаще всего делим значение хеша на количество шардов и берём остаток от деления. Например, 548291 % 3 = 2. Далее в зависимости от остатка распределяем данные по шардам. Значение с остатком 2 пойдёт в шард 2, если остаток 1, то в шард 1 и так далее.
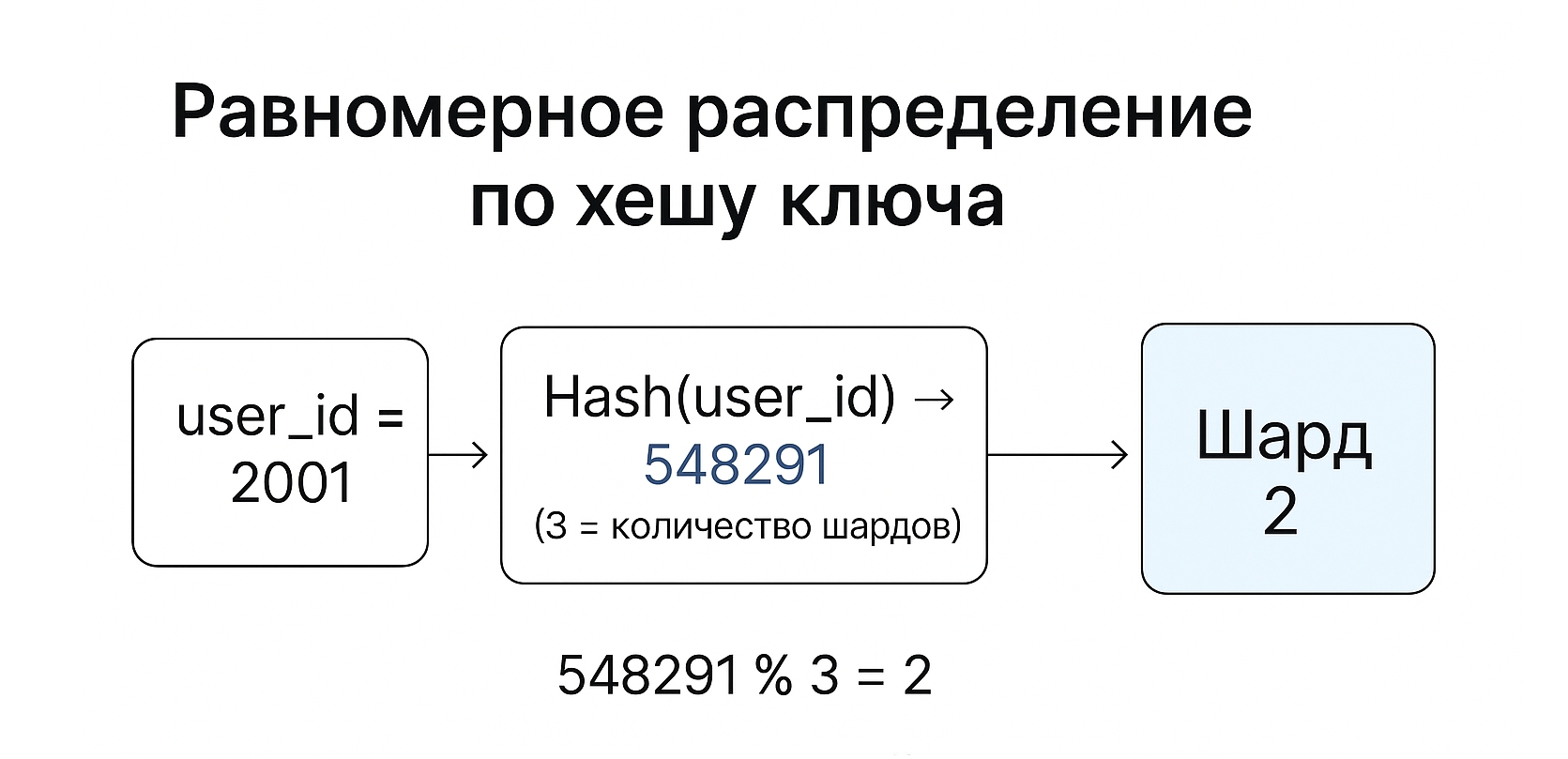
Так мы получаем более равномерное распределение данных. Но из минусов — в такой базе сложно обрабатывать диапазоны и добавлять новые шарды в систему.
Примеры реализации
MongoDB: встроенная поддержка шардинга
MongoDB — это NoSQL база данных, которая была разработана с закосом на горизонтальное масштабирование. То есть она адаптирована к тому, чтобы работать на нескольких серверах и расширять это число по мере необходимости. Поэтому sharding здесь доступен из коробки, нам не надо заморачиваться со внешними расширениями.
Рассмотрим пример, как настроить sharding и работать с ним:
- sh.addShard() — добавляем сервер в кластер как шард. MongoDB понимает, что может использовать этот сервер для хранения части данных.
- use socialApp; sh.enableSharding("socialApp") — переключаемся на базу данных «socialApp». При помощи команды sh.enableSharding() разрешаем шардинг в этой БД.
- sh.shardCollection("socialApp.users", { "user_id": 1 }) — применяем sharding к коллекции users. Мы указываем полное имя коллекции (socialApp.users) и ключ шарда ({ "user_id": 1 }). Цифра 1 означает, что мы используем шардинг по диапазонам. Эти диапазоны не нужно задавать вручную, MongoDB определяет их самостоятельно.
- db.users.insertMany([...]) — вставляем данные в коллекцию users. MongoDB автоматически определяет, на какой шард поместить каждого пользователя.
- db.users.findOne({ user_id: 1 }) — запрашиваем данные пользователя user_id = 1. Mongos сам определит, на каком шарде они находятся.
PostgreSQL + Citus
В PostgreSQL нет поддержки встроенного шардинга, поэтому приходится устанавливать на сервер Citus. Это популярное расширение, которое как раз добавляет возможности горизонтального масштабирования и шардинга. Оно превращает кластер стандартных серверов PostgreSQL в распределённую базу данных.
Посмотрим на пример использования SQL-команд для настройки шардинга с помощью Citus:
- CREATE EXTENSION citus; — активируем Citus в текущей базе данных.
- CREATE TABLE app_logs (...) — создаём таблицу app_logs на узле-координаторе точно так же, как создали бы обычную таблицу в PostgreSQL.
- SELECT create_distributed_table('app_logs', 'service_name'); — при помощи этой команды включаем sharding. Citus понимает, что таблицу app_logs нужно распределить по рабочим узлам, используя поле service_name как ключ шардинга. Citus по умолчанию применяет Hash-based sharding, то есть, равномерно распределяет по шардам при помощи хеш-функций.
- INSERT INTO app_logs — добавляем данные логов. Citus перехватывает запрос, вычисляет хеш от значения service_name для каждой строки и распределяет данные по шардам.
- SELECT ... FROM app_logs — запрашиваем данные. Если фильтруем по service_name (как в первом SELECT), Citus направит запрос на нужный шард.
MySQL + Vitess
MySQL — ещё одна система управления базами данных, у которой по умолчанию нет поддержки шардинга. Ситуацию спасает Vitess. Это система кластеризации баз данных — что-то вроде сторонней платформы, которая помогает организовать работу в рамках кластера.
Vitess вместо прямых команд для шардинга определяет его правила в отдельном JSON-файле, который называется VSchema (Vitess Schema).
Допустим, у нас есть база данных commerce. Вот как она выглядит в виде кода:
А вот так она выглядит в виде таблицы:
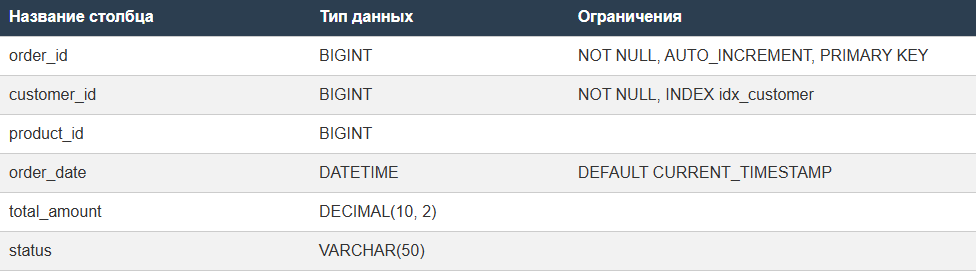
В базе данных есть таблица orders, её мы и хотим шардировать по customer_id при помощи хеширования (hash-based sharding).
Файл VSchema (vschema.json) может выглядеть примерно так:
- "sharded": true — указываем, что база данных шардирована.
- "vindexes" — определяем hash_index типа hash, который будет использовать хеш-функцию для распределения.
- "tables" — описываются правила для конкретных таблиц.
- "orders" — настраиваем таблицу orders.
- "column_vindexes" — определяем, какой столбец является ключом ("column": "customer_id") и какой vindex ("name": "hash_customer_id") использовать для него.
Проблемы шардирования
Перераспределение шардов (resharding)
Со временем может потребоваться изменить количество шардов или способ разделения данных. Например, добавить серверы для увеличения мощности или изменить ключ шардирования. Этот процесс называется решардингом.
При решардинге часто приходится перегонять большие объёмы данных между серверами. Если используется хеш-шардинг, и мы меняем количество шардов, то пересчитываются ключи, по которым распределяются данные.
Например, раньше у нас было 4 шарда. Мы брали user_id, например 9, делили на 4 и получали остаток — 1. Значит, данные шли на шард номер 1. После масштабирования стало 5 шардов, и 9 % 5 = 4 — теперь те же данные должны храниться на шардe 4.
Такое перемещение затратно по ресурсам: грузит сеть, диски, может занять часы или даже дни. Иногда для этого приходится останавливать запись, что делает процесс ещё рискованнее.
Неравномерная нагрузка (hot shards)
Вспомним вид шардирования Range-based sharding. Это когда мы разбиваем данные по диапазонам. У нас был пример выше с форумом и шардингом user_id:
- id от 1 до 1000 — шард 1;
- id от 1001 до 2000— шард 2;
- id от 2001 до 3000 — шард 3.
Мы столкнулись с проблемой, что шард 1 и шард 2 после завершения диапазонов простаивали, а вся новая нагрузка приходилась на шард 3.
Такую проблему называют горячим шардом (hot shards). Производительность всей системы начинает зависеть от самого загруженного шарда. Преимущества шардирования снижаются.
Чтобы этого избежать, приходится либо более въедливо продумывать ключи шардирования, либо вручную разделять слишком нагруженный шард.
Сложности с глобальными транзакциями и агрегациями
Допустим, нужно перевести деньги со счёта А на счёт Б — операция состоит из двух шагов: списание и зачисление. Транзакция позволяет объединить их в единое целое: либо всё выполнится, либо ничего. Это защищает от потери данных и ошибок. В классических базах данных за это отвечают принципы ACID — они гарантируют надёжность в пределах одного сервера.
Но если счёт А находится на одном шарде, а счёт Б — на другом, стандартная транзакция не сработает. Между независимыми серверами нельзя просто так обеспечить ACID-гарантии. Для этого нужны сложные и медленные механизмы координации, например двухфазный коммит (2PC). Либо приходится идти на компромисс и использовать eventual consistency — когда данные приходят в согласованное состояние с небольшой задержкой. Например, деньги уже списались, но ещё не зачислились.
Аналогичная проблема и с агрегациями: посчитать сумму продаж или число пользователей уже не получится одной SQL-командой. Каждый шард сначала считает свою часть, а потом результат нужно собрать и объединить — это требует дополнительной координации и может усложниться при фильтрации или группировках.
Сложность управления и мониторинга
Шардированный кластер — это распределённая система, управлять которой сложнее, чем одним сервером.
Больше компонентов: Вместо одной базы данных появляется множество шардов (часто с репликами), маршрутизаторы запросов, серверы конфигурации. Всё это нужно настраивать, обновлять и обслуживать.
Мониторинг: Требуется отслеживать состояние каждого шарда, равномерность распределения нагрузки, задержки в сети, работу маршрутизаторов. Нужны более сложные инструменты мониторинга.
Отладка: Найти источник проблемы в распределённой системе сложнее. Ошибка может быть где угодно: в приложении, маршрутизаторе, на одном из шардов или в сети.
Резервное копирование: Создание согласованных резервных копий и восстановление данных со множеством независимых шардов требует более сложных процедур.
Когда стоит применять Sharding
Рост объёма данных и нагрузок
Sharding стоит применять, если БД сильно разрослась, хранить её на одном сервере становится сложно и дорого. Серверу приходится обрабатывать много данных, и поэтому увеличивается время отклика.
Иногда серверу приходится одновременно читать и записывать слишком много запросов. Система становится перегруженной, пользователи замечают задержки и нестабильную работу. Здесь тоже поможет sharding.
Не справляется один сервер/реплика
Допустим, у нас один сервер и он не справляется с запросами и большими данными. Конечно, мы можем заняться вертикальным масштабированием, поставить CPU производительнее, добавить больше ОЗУ и так далее. Однако у этого подхода есть ограничения. Во-первых, каким бы мощным ни был бы сервер, он со временем упрётся в потолок своей производительности. Во-вторых, иногда дешевле купить несколько новых серверов помощнее, чем прокачивать старый. Поэтому создание кластера и распределение в нём нагрузки при помощи шардинга — часто более выигрышное решение, чем один сервер.
Потребность в геораспределённости или отказоустойчивости
Если пользователи находятся в разных частях света, то деление данных и хранение ближе к ним может ускорить работу приложения. Мы можем при помощи шардинга размещать данные в разных дата-центрах, ближе к определённым группам пользователей. Например, так делает Youtube. Компания размещает свои сервера в разных странах, чтобы видео прогружались быстрее и в более высоком качестве.
Мы можем хранить все данные и обрабатывать запросы на одном сервере и сделать его реплику с копией данных. Если этот сервер падает, то его заменяет реплика. Но что, если эта реплика тоже упадёт? Тогда нам и помогает sharding с репликацией. В случае сбоев отвалятся только отдельные серверы с некоторыми наборами данных. Конечно, здесь тоже, в теории, можно положить весь кластер, включая реплики, но сделать это сложнее.
Шардирование — полезный инструмент при работе с СУБД. А узнать про большее число подобных инструментов можно в нашем телеграм канале!










![Обложка: Как стать аналитиком данных за 6–12 месяцев [гайд]](https://media.tproger.ru/uploads/2025/12/1c7c4818-f579-4330-b4fe-56704d1972e0.jpg)

