


Как обучить ChatGPT на личных данных

Рассказываем об архитектуре LLM и требованиях к данным для создания «частного ChatGPT», который использует ваши собственные данные.
21К открытий33К показов
С появлением больших языковых моделей (LLM), таких как ChatGPT и GPT-4, многие задаются вопросом, можно ли создать частный ChatGPT, обучив модель на личных или корпоративных данных. Осуществимо ли это? Могут ли такие языковые модели предложить эти возможности?
В этой статье мы поговорим об архитектуре LLM и требованиях к данным для создания «частного ChatGPT», который использует ваши собственные данные. Мы изучим преимущества этой технологии и то, как вы можете преодолеть её ограничения.
Это перевод статьи «How to create a private ChatGPT with your own data» от автора Mick Vleeshouwer. Здесь и далее повествование ведётся от лица автора.
Отказ от ответственности: в этой статье представлен обзор архитектурных концепций, которые не относятся к Azure, но проиллюстрированы с использованием служб Azure, поскольку я — Solution Architect в Microsoft.

1. Недостатки тонкой настройки LLM на личных данных
Часто люди называют тонкую настройку (то есть обучение) хорошим решением, которое позволяет добавить собственные данные поверх уже обученной модели.
Однако у такого подхода есть недостатки: у модели могут быть сбои в ответах, она может выдавать нерелевантную запросу информацию. У GPT-4 такое явление назвали риском галлюцинаций. Всё потому, что GPT-4 обучался только на данных до сентября 2021 года.
Недостатки при тонкой настройке LLM:
- Можно отследить, из какого датасета берется ответ.
- Нельзя ограничить доступ к документам с информацией для отдельных пользователей.
- Добавление новой информации для LLM требует переобучения модели.
Эти проблему делают почти невозможным использование тонкой настройки для персональных ответов на вопросы.
Как преодолеть ограничения и по-прежнему получать выгоду от LLM?
2. Отделите свои знания от вашей языковой модели
Чтобы пользователи получали точные ответы, нам нужно отделить нашу языковую модель от нашей базы знаний. Это позволит пользователям получать наиболее актуальную информацию. Отделить данные можно в режиме реального времени, и обучение модели не требуется.
Будет хорошей идеей передавать все документы в модель во время выполнения. Однако это сложно сделать из-за ограничения количества символов (измеряемого в токенах), которые могут быть обработаны за один раз.
Например, GPT-3 поддерживает токены до 4 КБ, GPT-4 — до 8 КБ или 32 КБ. Поскольку цены указаны за 1000 токенов, использование меньшего количества токенов также может помочь сократить расходы.
Вот, каким будет алгоритм:
- Пользователь задает вопрос.
- Приложение находит наиболее релевантный текст, который (скорее всего) содержит ответ.
- LLM отправляется краткая подсказка с соответствующим текстом документа.
- Пользователь получит ответ или ответ «Ответ не найден».
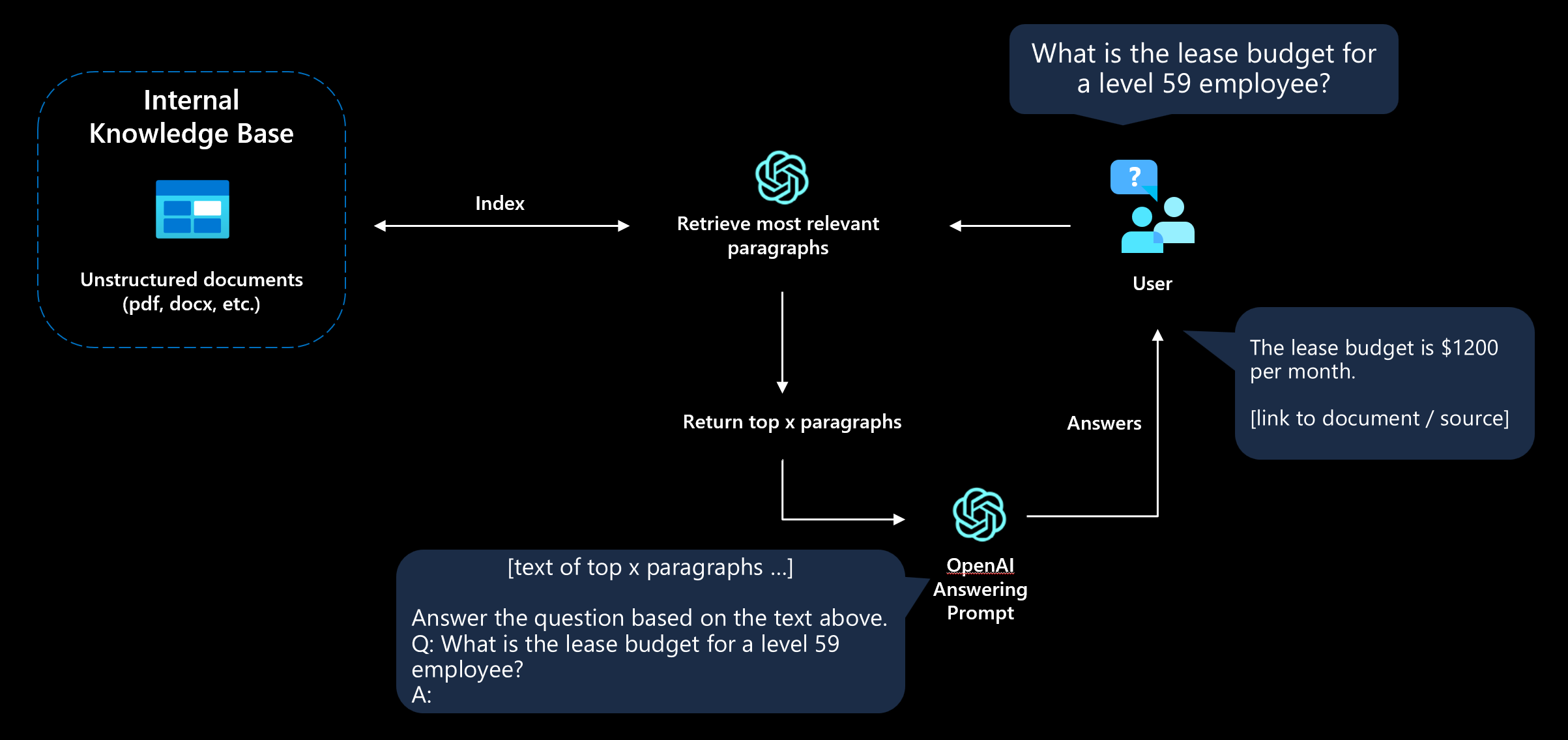
Этот подход часто называют обоснованием модели. Мы предоставим дополнительный контекст для LLM, чтобы она отвечала на вопросы на основе соответствующих ресурсов.
3. Получите наиболее релевантные данные
Контекст — это ключевой аспект в настройке.
Чтобы гарантировать, что языковая модель использует нужную информацию, нам необходимо создать базу данных, которую можно использовать для поиска релевантных документов с помощью семантического поиска.
Так мы предоставим языковой модели правильный контекст, и она сможет генерировать правильный ответ.
3.1 Разбивайте и разделяйте данные
Поскольку в подсказке для ответа есть ограничение на токены, нам нужно дробить наши документы на более мелкие куски.
Можно начать с простого разделения документа на страницы, чтобы текст страницы был равен длине токена.
После этого нужно создать поисковые индексы для фрагментов текста, которые можно запрашивать с вопросом пользователя.
Вариант 1: Используйте поисковый продукт
Самый простой способ создать индекс семантического поиска — использовать существующую платформу «Поиск как услуга».
Например, в Azure можно использовать Cognitive Search, который предлагает управляемый конвейер приема документов и семантическое ранжирование с использованием языковых моделей Bing.
Вариант 2: Используйте вложения для создания собственного семантического поиска
Вложение — это вектор (список) чисел с плавающей запятой. Расстояние между двумя векторами измеряет их родство. Небольшие расстояния предполагают высокое родство, а большие расстояния предполагают низкое родство.
Если вы хотите использовать новейшие семантические модели и лучше контролировать свой поисковый индекс, вы можете использовать модели встраивания текста от OpenAI. Для всех ваших разделов вам нужно будет предварительно вычислить вложения и сохранить их.
В Azure можно хранить вложения в управляемой векторной базе данных, такой как Azure Cache для Redis (RediSearch), или в векторной базе данных с открытым исходным кодом, такой как Weaviate или Pinecone.
Во время работы приложения вы должны превратить вопрос пользователя во вложение, чтобы сравнить косинусное сходство встраивания вопроса с вложениями документов.
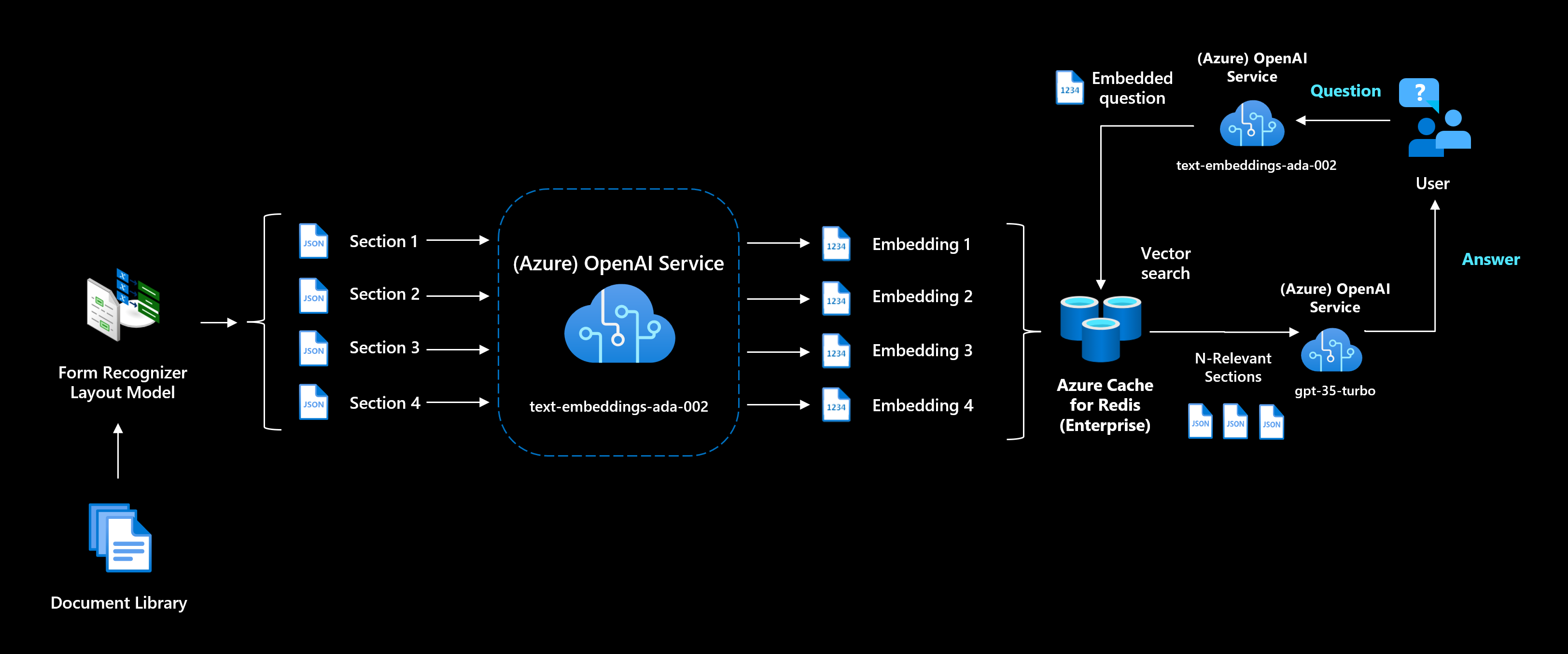
3.2 Повышение релевантности с помощью различных стратегий фрагментации
Чтобы находить наиболее актуальную информацию, важно, чтобы вы понимали свои данные и потенциальные запросы пользователей. Это знание поможет понять, как лучше всего разделить данные на фрагменты.
Общие шаблоны, которые могут улучшить релевантность:
- Фрагментация по странице или по токену может привести к потере контекста. Используйте связанный друг с другом контент во фрагментах, чтобы увеличить выдачу наиболее релевантной информации.
- Обеспечьте больше контекста. Создайте очень структурированный документ с разделами, вложенными в несколько уровней (например, с разделами вида 1.3.3.7). Такой подход будет удачным, поскольку он даёт дополнительный контекст вроде названия главы и раздела.
- Создайте фрагменты с кратким содержанием более крупного раздела документа. Это позволит включить в ответ самый важный текст и объединить всю информацию в один блок.
4. Пишите краткие промпты, чтобы избежать галлюцинаций
Разработка промптов — это то, как вы «программируете» модель, обычно предоставляя ей инструкции в промпте или несколько примеров.
Промпт — это важная часть в работе с ChatGPT для предотвращения нежелательных ответов. Сегодня создание промптов считается новым навыком, и каждую неделю публикуется все больше и больше примеров промптов.
В промптах вы должны четко указать, что модель должна быть краткой в ответе и использовать только данные из релевантного контекста.
Если модель не может ответить на вопрос, она должна дать предопределенный ответ «нет ответа».
Выходные данные должны включать сноску (цитаты) к исходному документу, чтобы пользователь мог проверить его фактическую точность, просмотрев источник.
Пример промпта:
Такое обучение модели нужно для улучшения качества ответов. Мы предоставляем модели пример того, как нужно обрабатывать вопрос пользователя. Также мы предоставляем источники с уникальным идентификатором и пример ответа, который состоит из текста из нескольких источников.
Во время выполнения {q} превратится в вопрос пользователя, а {retrieved} будет заполнен соответствующими разделами из БД для запроса.
Не забудьте установить низкую температуру в ваших параметрах, если вы хотите получать предсказуемые ответы. Повышение температуры приведет к более неожиданным или творческим ответам.
Этот промпт используется для создания ответа через (Azure) OpenAI API.
Если вы используете gpt-35-turbo (ChatGPT), можно сохранять историю разговора, чтобы была возможность задавать уточняющие вопросы или другие логические задачи (например, резюмирование ответа).
Отличный ресурс, чтобы узнать больше о проектировании промптов — это dair-ai/Prompt-Engineering-Guide на GitHub.

5. Следующие шаги
В этой статье я обсудил архитектуру и паттерны проектирования, необходимые для реализации личной языковой модели, не вдаваясь в особенности кода.
Вот, какие проекты вы можете изучить для вдохновения, чтобы приступить к созданию индивидуальной модели.
- Плагин извлечения ChatGPT, позволяющий ChatGPT получать доступ к актуальной информации. На данный момент плагин поддерживает только общедоступный ChatGPT, но мы надеемся, что в будущем возможность добавления плагинов будет добавлена в ChatGPT API (OpenAI + Azure).
- LangChain, популярная библиотека для объединения LLM и других источников знаний.
- Azure Cognitive Search + OpenAI accelerator для работы с личными данными. Он аналогичен ChatGPT и готов к развертыванию.
- OpenAI Cookbook, пример того, как использовать вложения OpenAI для вопросов и ответов в Jupyter (инфраструктура не требуется).
- Semantic Kernel, новая библиотека для смешивания традиционных языков программирования с LLM.
Можно улучшить «собственный ChatGPT», связав его с другими системами при помощи LangChain или Semantic Kernel. Возможности безграничны.
Заключение
В заключение, полагаться исключительно на языковую модель для создания информационного текста — ошибка.
Тонкая настройка модели также не поможет, так как она не даст модели никаких новых знаний и не даст вам возможности проверить ее реакцию.

Чтобы создать механизм вопросов и ответов поверх LLM, отделите свою базу знаний от большой языковой модели и генерируйте ответы только на основе предоставленного контекста.

21К открытий33К показов

Рассказываем, как прошла конференция ArenaDAY 2025.
ChatGPT запустил персональные итоги года: статистика чатов, темы, стиль общения и креативный recap. Рассказываем, как посмотреть отчет за 2025 год

Разбираемся, почему классический поиск уступает место ИИ-поисковикам, как генеративный ИИ меняет привычные правила поиска и что ждёт SEO эпоху ИИ-агентов ✔ Tproger

Фотореалистичный генератор изображений в ChatGPT стал доступен бесплатно, но в таком случае у OpenAI есть лимит в 3 запроса в день