


Как стать самым быстрым программистом?
Рассказали, как можно оптимизировать вашу работу, как быстрее писать код и как качественнее его проверять, на примере команды HP.
4К открытий5К показов
Это — вторая серия проекта «Код Раковского», где Александр Раковский, Senior Java разработчик компании ITentika, рассказывает о том, что считает важным и интересным в сфере программирования. Первый выпуск можно посмотреть здесь.

На первый взгляд, стать самым быстрым программистом — отличная цель. Кто успевает сделать больше фич, тот и приносит компании больше денег, да? А кто приносит больше денег, тому и самую большую зарплату, правильно?
Уверен, кто-то сейчас ухмыльнулся, вспомнив своего коллегу, который всех в команде бесил своими быстрофиксами и костылями. Похоже, компаниям важны не столько быстрые программисты, сколько быстрые команды.
Ну хорошо, а как замерить скорость программиста или команды?
Можно вводить разные странные метрики: число строк кода, число сторипоинтов или доставленных фич. Совершенно очевидно, что эти метрики никуда не годятся. При желании любая команда легко может ими манипулировать: писать сотни тысяч строк кода, который никогда не запустится, закладывать в оценки тысячи сторипоинтов, дробить большие фичи на маленькие.
Давайте зайдем с другой стороны. Как можно оптимизировать вашу работу? Может, надо быстрее писать код? Или качественнее проверять код, чтобы потом меньше времени тратить на отладку? Может быть, стоит меньше времени проводить на митингах? Сколько вообще времени ваша команда тратит на самое главное — реализацию нового функционала?
Кейс HP LaserJet
В 2008 году компания Hewlett Packard обнаружила себя в трудной ситуации. Исследование показало, что на разработку нового функционала HP LaserJet у компании оставалось лишь 5% всего времени — все остальное съедали сложности, возникающие при разработке кода под множество устройств.

Это заставило компанию запустить большую перестройку процессов. Новые процессы базировались на идеях экстремального программирования.
Ключевые нововведения:
- Практически полностью автоматизированное тестирование;
- четыре уровня проверки кандидата к релизу — от самых быстрых тестов с частотой до 12 прогонов в день до самых медленных с частотой до 1 раза в сутки;
- автоматизация инфраструктуры и развертываний. Любые изменения вплоть до конфигураций проходили через систему контроля версий и тесты, откуда автоматически развертывались на стенды;
- короткие циклы планирования вместо разработки больших проектов на много месяцев вперед;
- и самое радикальное — разработка на одной ветке, или, как сейчас говорят, trunk based development. Каждый день в главную ветку вливались по 10-14 коммитов, что позволило предотвратить все варианты интеграционных конфликтов.
В результате удалось добиться сокращения затрат на большинство активностей в разы. Это позволило высвободить время для инноваций: процент времени, затрачиваемого на новый функционал, увеличился с 5% до 40%.

Самое интересное тут то, что времени на тестирование не стало меньше, оно даже, наоборот, удвоилось: несмотря на то, что ручное тестирование сократилось в три раза, теперь 23% всего времени уходило на автоматические тесты. То есть, увеличив время на автоматическое тестирование и автоматизацию инфраструктуры, компания смогла тратить меньше на остальные активности. Таким образом скорость разработки выросла на невероятные 700%.
Сильные и слабые команды
Это не столько частный случай, сколько общая практика. В 2016 году организация DORA в ежегодном исследовании State of Devops опубликовала свои замеры.
Оказалось, что сильные команды тратили на переделывание и незапланированную работу на 22% меньше, а на новую работу на 29% времени больше, чем слабые. Через год разрыв увеличился: сильные команды стали тратить на переделывание и незапланированную работу на 26% меньше и на 44% больше на новую работу. Таким образом, сильные команды в среднем тратят почти в полтора раза больше времени на полезную работу.
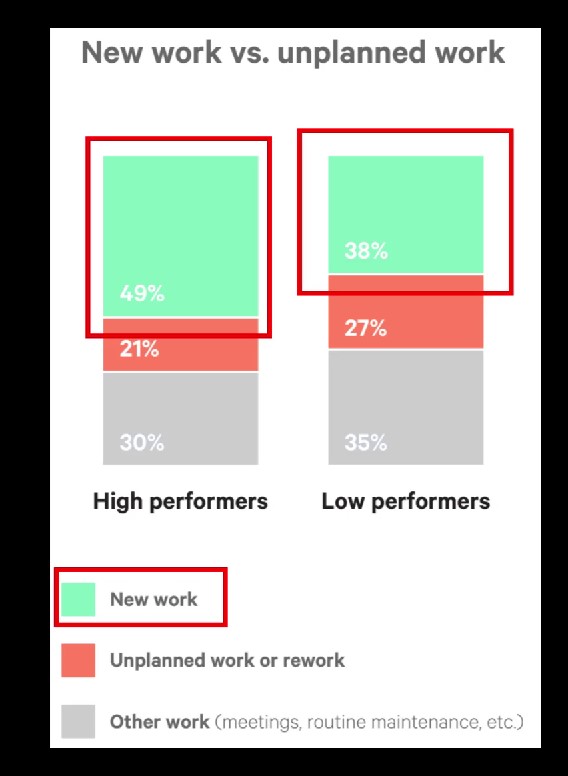
Дизайн исследования специально был построен таким образом, чтобы сильные команды объединял все тот же высокий уровень автоматизации тестирования и развертывания. В слабых командах же, напротив, значительно больше было ручной работы.
Зачем нужна автоматизация
Важно понимать, почему высокий уровень автоматизации, требуя в среднем больше затрат, чем ручная работа, освобождает больше времени на разработку нового функционала. Если вы вспомните собственный опыт, то совершенно точно согласитесь, что даже при разработке нового функционала большая часть времени у вас уходит на поиск ошибок и попытки заставить что-то работать. Дефекты могут скрываться как в коде, так и в самой конфигурации системы, о чем мы нередко забываем. И вот тут многоуровневые автоматические тесты становятся настоящим спасением, потому что именно они дают почти моментальную обратную связь, если где-то что-то сломалось.
Другой важный эффект: чем больше времени проходит с момента совершения ошибки до момента ее обнаружения, тем сложнее эту ошибку найти и исправить. Во-первых, возрастает объем изменений и непонятно, какое именно вызвало ошибку. Во-вторых, поверх этой ошибки нередко успевает вырасти целый конструкт, который плотно связан с ней, и починив одно, можно сломать другое.
Ну хорошо, а кто должен писать все эти тесты?
Здесь все то же исследование State Of Devops демонстрирует еще более удивительную связь: тесты, написанные тестировщиками или даже отдельными командами, как оказалось, ничем не помогают. Только тесты, написанные самими разработчиками, позволяют добиться повышения эффективности команды.
Почему так?
Тут, на самом деле, нет единого ответа. Статистика указывает на корреляцию, но не объясняет, в чем дело. Может быть, когда разработчики пишут тесты сами, не происходит классического расщепления ответственности за качество кода между кодерами и тестерами. Может быть, дело в том, что к таким тестам у самих программистов гораздо больше доверия. А возможно, здесь важна именно комбинация множества факторов.
Суть остается неизменной: разработчики, одержимые тестами, добиваются значительно лучших результатов, чем их более консервативные коллеги.
Ладно, автоматизация важна. Как и что автоматизировать?
Это крайне обширная тема, которая максимально подробно освещена в книге «Непрерывное развертывание программного обеспечения» (Continuous Delivery) авторства Дейва Фарли и Джеза Хамбла.
Давайте попробуем вкратце описать процесс разработки в условиях полной автоматизации тестирования, развертывания и инфраструктуры.
Центральным элементом такого процесса является паттерн «Конвейер развертывания» (Deployment pipeline). Согласно этому шаблону, каждый коммит, попавший в главную ветку в системе контроля версий, запускает старт этого конвейера.
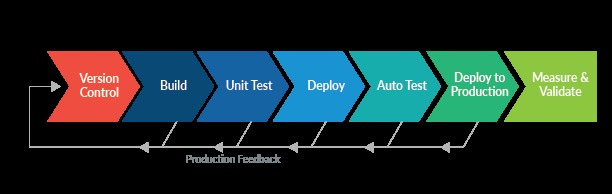
На первом шаге код собирается и на нем запускаются быстрые тесты, не требующие развертывания приложения. Этот шаг должен длиться не более 5 минут, чтобы не сдерживать доступ остальной команды к ветке.
Согласно практике, в случае красных тестов у автора коммита есть 5 минут на то, чтобы восстановить работоспособность ветки — устранить проблему или откатить свои изменения до последней рабочей версии.
После успешного прохождения тестов вторым шагом в репозиторий публикуется собранный кандидат к релизу, например docker-контейнер или иной артефакт.
За этим следует шаг с развертыванием приложения на тестовый стенд и конфигурацией стенда. Здесь происходят все накаты миграций баз данных и все изменения настроек приложений.
Очень важно, что любые изменения конфигурации должны проходить исключительно через конвейер: это дает возможность откатиться на предыдущую версию конфигурации в случае каких-то проблем. Эта практика называется «Инфраструктура как код».
Ни в коем случае нельзя настраивать вашу инфраструктуру вручную. Это приводит к антипаттерну «Сервер-снежинка» (Snowflake Server), когда ваш сервер уникален и неповторим, подобно снежинке. Нет ни малейшей гарантии, что то, что работает на вашей снежинке, будет работать хоть где-то еще.
Следующим шагом конвейера обычно становится шаг автоматических приемочных тестов на развернутом приложении. Эти тесты проверяют, что все требования к приложению выполнены: на этом этапе гоняются бизнес-сценарии, нагрузочные тесты, UI-тесты, security-тесты, инфраструктурные тесты.
Лучшая практика тут — приложить все усилия, чтобы этот шаг длился не более часа, чтобы у команды была возможность прогнать за день несколько попыток в случае какого-то падения. Другая популярная практика — катать приемочные тесты по ночам — приводит к тому, что команда может проверить лишь одну гипотезу в день. Это нередко выливается в то, что конвейер краснеет на несколько недель, парализуя работу всей команды.
Другой совет — ни в коем случае не пишите функциональные тесты через UI. Функционал и UI меняются по разным причинам: функционал меняется из соображений бизнеса, UI — из соображений эстетики и эргономики. Приемочные тесты, написанные через UI, приведут к тому, что любое изменение графического интерфейса будет требовать переписывания огромного массива функциональных тестов и, как следствие, ваш UI навеки замрет в том состоянии, в котором вы его однажды зафиксировали своими тестами.
Последний шаг конвейера — развертывание приложения в промышленную эксплуатацию. Тут надо понимать следующую идею: развертывание в продакшн — это бизнес-решение. Может быть, нет никаких проблем в том, чтобы после каждого коммита разработчика в течение часа на продакшене была уже новая версия. Почему нет — если все тесты зеленые, то есть требования к приложению удовлетворены. Может быть, как в случае, например, с драйверами устройств, такое невозможно по определению.
Может даже быть такая ситуация, что некоторые приемочные тесты покраснели, но бизнес все равно заинтересован в развертывании: например, появление критически важного функционала для бизнеса оказывается приоритетнее, чем падение производительности и покраснение нагрузочных тестов.
И еще раз: все эти тесты, изменения инфраструктуры стенда, миграции, изменения самого конвейера заезжают в репозиторий вместе с функционалом, к которому они относятся. Необязательно в одном коммите, но обязательно должно выполняться условие — зеленые тесты означают, что система готова к релизу с точки зрения бизнеса, а зелеными они должны быть всегда. Лакмусовая бумажка: вы должны быть способны откатиться на коммит годичной давности с последующим развертыванием его через конвейер в продакшн.
Главный результат такой автоматизации: код непрерывно находится в готовом к развертыванию в продакшн состоянии, каждый новый коммит — новый релиз.
У кого-то вышеописанные процессы могут вызвать лишь ухмылку. Мол, в идеальном мире розовых единорогов такое бы, может быть, и было возможно. Отнюдь. Именно такого преобразования и удалось добиться компании HP Laser Jet и многим другим известным крупным компаниям. Но соглашусь, это высший пилотаж, требующий высокой грамотности разработчиков в области тестирования и автоматизации инфраструктуры. Впрочем, в этом и цель моего повествования: указать на ориентиры в профессиональном развитии специалиста.
Ну хорошо, автоматизация рулит, договорились. Есть ли какие-то другие способы ускорить команду?
Командам очень дорого обходится возрастающая со временем сложность системы. Каждая новая фича повышает ценность продукта в глазах пользователя — и, к сожалению, каждая новая фича ложится тяжелым грузом на плечи разработчиков, тестировщиков и техподдержки. Чем больше кода написано, тем сложнее добавлять новый.
Эта идея называется гипотезой выносливости дизайна, и вот уже больше полувека наша отрасль страдает от этой напасти — от проклятия кодовых баз, которые невозможно изменить из-за накопленной сложности. Бессменными спутниками таких систем становятся крайне запутанная структура кода и, самое страшное, опасные и дорогие баги, которые очень сложно исправлять.
Как с этим бороться? Есть три способа:
- Приоритизировать простоту (правило: пишем самое простое, что может работать).
- Рефакторинг. Всегда оставляйте код в лучшем состоянии, чем вы его застали. Наряду с первой практикой это позволит вам не только не вносить новую сложность в систему, но и постоянно ее сокращать.
- Постепенно заменяйте ручные операции (тестирование и развертывание) автоматизированными.
Но самое дорогое в разработке программного обеспечения — работать не туда
Давайте рассмотрим конкретный пример компании, которая делала игры для Facebook. Однажды владелец компании пришел к разработчикам и сказал, что следующей большой фичей станут уровни и достижения для всех игр. Он принес с собой толстую папку диаграмм, чертежей, скриншотов и всего, что отдел маркетинга разработал для этой фичи.
Разработчики, посмотрев на это безобразие, выдали грубую оценку всей работы в 9 месяцев. Это был тоннель, в который команда бы въехала с одного конца и только через 9 месяцев, выехав с другого конца, узнала бы, был ли это успех или провал. Факт того, что команда могла выпускать новые релизы каждые пару недель, позволял не ждать 9 месяцев, чтобы проверить идею. Поэтому команда вернулась к заказчику с вопросом, как это решение может изменить чье-то поведение. Этот вопрос застал владельца врасплох:
—Что значит «изменить чье-то поведение»?—Если через 9месяцев, когда фича будет готова, все будут делать тоже, что исейчас, как будто ничего непроизошло, это будет провал?—Конечно, провал!—Тоесть кто-то должен что-то делать иначе?—Мыхотим, чтобы пользователи публиковали свои достижения в«Фейсбуке».—Уже лучше. Зачем?—Всмысле— зачем? Чтобы ихдрузья увидели эти посты.—Тоесть насамом деле мыхотим изменить поведение людей, которые неиграют вигру. Нухорошо, апочему это важно?—Если другие люди прочитают эти посты, то, возможно, они придут попробовать эту игру.—Хорошо, это еще одно изменение поведения, но все еще недает общей картины. Почему это важно?

Владелец был потрясен:
—Это глупый вопрос. Чем больше игроков, тем больше денег.—Хорошо, тоесть мыхотим больше игроков?—Конечно!—Насколько больше?—Чем больше, тем лучше.—Если спустя 9месяцев эта фича приведет 5 новых игроков, это будет успех?—Нет, конечно, мырассчитываем намиллион игроков.
Бинго! Эта цифра все время была в голове у владельца, но до разработки дошла лишь после этого разговора. В итоге первое, что требовалось сделать, — проверить, насколько идея жизнеспособна. За пару часов работы была реализована возможность опубликовать сообщение о победе в игровом турнире, однако оказалось, что за 3 дня никто так и не нажал кнопку «поделиться» — никто не хотел спамить своим друзьям сообщениями о какой-то игре в «Фейсбуке». Таким образом, это направление оказалось заблокировано.
Поступило другое предложение: теперь игрокам предоставили возможность приглашать друзей — и, о чудо, игроки начали приглашать друзей. Проблема лишь в том, что никто так и не пришел по ссылке. Отдел маркетинга предположил, что это из-за того, что в письме была плохо видна ссылка на игру. Вместо маленькой ссылки в тексте сделали большую кнопку «присоединиться» — и тут игроки пошли. Спустя две недели полировки механизма приглашений и введения разных бонусов реферальной программы у игры был миллион игроков.
Эта история позволяет сформулировать очень интересные выводы::
- Во-первых, невероятно важно, чтобы все участвующие в решении понимали проблему, которую они решают. То есть задача должна декларироваться не в виде фичи «уровни и достижения», а в виде тезиса о привлечении в игру миллиона новых игроков.
- Во-вторых, очень важно ввести правильные способы измерения прогресса в достижении решения проблемы. В контексте предыдущего примера такими метриками стали количество игроков, число публикаций, число приглашений и пришедших по приглашениям игроков.
- В-третьих, нужно ошибаться быстро и недорого. Важно помнить: никто точно не знает, как решить проблему, все только лишь высказывают гипотезы. Поэтому необходимо быстро отвергать нерабочие гипотезы, проверяя их на прочность c помощью метрик.
Согласно исследованию компании Microsoft, 2/3 всего разработанного функционала в лучшем случае не принесло никакой пользы. Это означает, что можно иметь крутейшую архитектуру, в которой нет ни строчки лишнего кода и избыточной сложности, можно иметь невероятные процессы, в которых каждый коммит после прогона всех видов автотестов тут же деплоится в прод — но если вы работаете не туда, то 2/3 вашей работы в лучшем случае не принесут никакой пользы. И, как правило, такие фичи лежат в кодовой базе и мешаются под ногами, съедают время в прогонах тестов, техподдержке приходится поддерживать эти фичи до самого конца продукта — а ведь ими никто и не пользуется.
Получается, что компании выгоднее было бы, если бы вы эти 2/3 времени провели на пляже, ну или на горнолыжном курорте, или просто с родными…
Вывод
Подведем итоги:
- Автоматизация тестирования и инфраструктуры приводит к росту продуктивности в среднем в полтора раза. В отдельных случаях удавалось зафиксировать рост в 8 раз.
- Центральным элементом такой автоматизации является шаблон «Конвейер развертывания». Главный результат: код непрерывно находится в готовом к развертыванию в продакшн состоянии, каждый новый коммит — новый релиз.
- Другой проблемой становится трясина легаси-кода. Главные сдерживающие факторы — запутанная структура и дорогие баги. Главные лекарства — простой дизайн, рефакторинг и автотесты.
- Самое дорогое препятствие к решению проблем бизнеса — неверно выбранный вектор работы. Очень важно, чтобы все участники процесса хорошо понимали цель, правильно выбирали метрики и работали в коротких циклах, позволяющих ошибаться быстро и дешево.
На этом у меня все. Спасибо за внимание, пишите хороший код, тесты и до новых встреч.

4К открытий5К показов

Лучшие курсы по автотестированию. Рейтинг вариантов онлайн-обучения для тестировщиков, обзор обучающей программы и стоимости курсов.

Лучшие курсы по цифровой трансформации. Рейтинг вариантов онлайн-обучения с нуля, обзор обучающей программы и стоимости курсов.

Vibe coding ускоряет написание кода, но несёт скрытые риски. Эксперт FabricaONE.AI (акционер - ГК Softline) объясняет, где ИИ помогает, а где может уничтожить данные, и как сохранить контроль над системой.

Чем AI-агент отличается от обычного бота, посчитаем стоимость тикета (оператор vs AI), разберем два кейса с цифрами и дадим чеклист для техлидов по запуску и мониторингу.