Как упростить работу с временными рядами: 14 библиотек от эксперта Росатома

Временные ряды — важный инструмент в Data Science. Росатом рассказывает, как работать с ними эффективно.
Ритейл, банкинг, телеком и многие другие бизнесы используют машинное обучение (machine learning, ML) для работы с данными. ML позволяет анализировать большие объемы информации, выделять закономерности, прогнозировать будущие состояния, проводить эксперименты и в целом решать сложные задачи, особенно при достаточности исходных данных. Как правило, для ML-специалистов (дата-сайентистов) всегда есть интересные и нетривиальные проекты.

Юрий Кацер
руководитель направления предиктивной аналитики в Блоке цифровизации ГК «Росатом»
Но, если говорить про Росатом, то у нас практически каждая задача — челлендж. Это связано со спецификой отрасли и компании. Во-первых, у нас высокие требования к безопасности и надежности. Мы не можем допустить ошибку, потому что отвечаем за жизнь и здоровье людей. Например, на наших атомных электростанциях одна из сильнейших в мире систем обеспечения безопасности на протяжении всего производственного цикла.
Еще у нас достаточно ограничений. Так, мы не всегда можем проводить эксперименты, а количество накопленных данных по аномалиям и поломкам минимально. Это связано с тем, что у нас на наиболее важных единицах оборудования, к счастью, сбои либо не случаются, либо случаются крайне редко. Все это приводит к намного меньшим объемам информации, чем в других доменных областях, и к ограничениям использования некоторых методов и алгоритмов машинного обучения.
Нам приходится работать с тем, что есть, во многом опираясь на собственный накопленный опыт и опыт экспертов с производств. При этом, предварительная обработка данных порой занимает до 70% времени всей работы над проектом, потому что приходится тщательнее и глубже разбираться с данными из-за сложившихся ограничений.
Однако именно ограничения и специфика Росатома мотивируют нашу команду. Мы в непрерывном поиске наиболее оптимальных решений, чтобы выполнять работу быстрее и эффективнее. Так, задачи с временными рядами можно решать классическими методами типа градиентного бустинга, представляя, что работаете с табличными данными, но мы предпочитаем использовать специализированные библиотеки для различных задач.
Зачем писать 20 строк кода для преобразования временных рядов к классическому табличному виду, если с помощью библиотек можно работать непосредственно с исходными временными рядами и уложиться в две строки для обучения модели? Расскажу, какие библиотеки лучше подходят для решения основных задач на временных рядах.
Временной ряд — упорядоченная последовательность точек или признаков, измеренные через определенные временные интервалы, и которая представляет характеристику процесса.
Прогнозирование
Прогнозирование — предсказание будущих значений временного ряда. Если объяснить точнее, то поиск функции от предыдущих значений ряда, которая на горизонте прогнозирования выдает ответы, приближенные к реальным значениям ряда в эти моменты времени.

Прогнозирование — одна из самых распространенных задач. Она позволяет узнать примерное значение требуемого показателя в будущем. Самый простой пример использования — прогноз погоды: будет завтра дождь или нет. Мы, конечно, решаем промышленные задачи, например, рассчитываем поведение температуры подшипника в течение следующих двух часов. Использование библиотек позволяет быстро построить оптимальную модель.
Prophet
Библиотека с открытым исходным кодом. Предназначена для прогнозирования временных рядов, особенно с ярко выраженными сезонными эффектами. Библиотека устойчива к недостатку данных, хорошо справляется с выбросами. Удобная, легко кастомизируется и не требует глубоких знаний в аналитике.
Prophet отлично подходит для обработки больших временных рядов. В сочетании с графической библиотекой Plotly можно строить наглядные интерактивные графики, с которыми удобно работать: изменять масштаб, сохранять отдельные участки, получать информацию по каждой точке.
Statsmodels
Библиотека с открытым исходным кодом. Построена на библиотеках NumPy и SciPy. Statsmodel позволяет строить и анализировать статистические модели, в том числе модели временных рядов. Также включает в себя статистические тесты, возможность работы с большими данными и др.
Что еще подойдет
Sktime
Darts
Kats
- [прим. ред. — библиотека разрабатывается запрещенной в России организацией, поэтому мы не можем привести ссылки на ее GitHub-репозиторий]
- Kats Python package
- Учебные материалы
Merlion
Pytorch-Forecasting
Grey Kite
Классификация
Классификация — отнесение объекта или показателя к одной из установленных категорий или классов на основании информации об объекте.
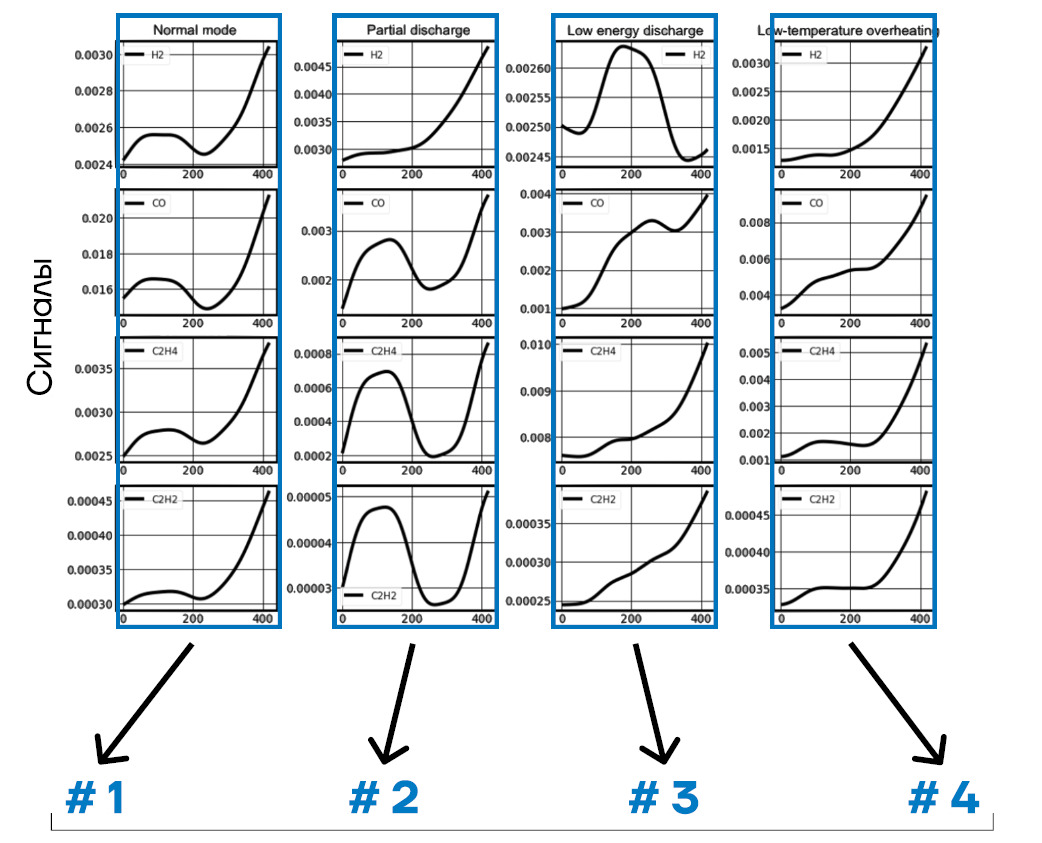
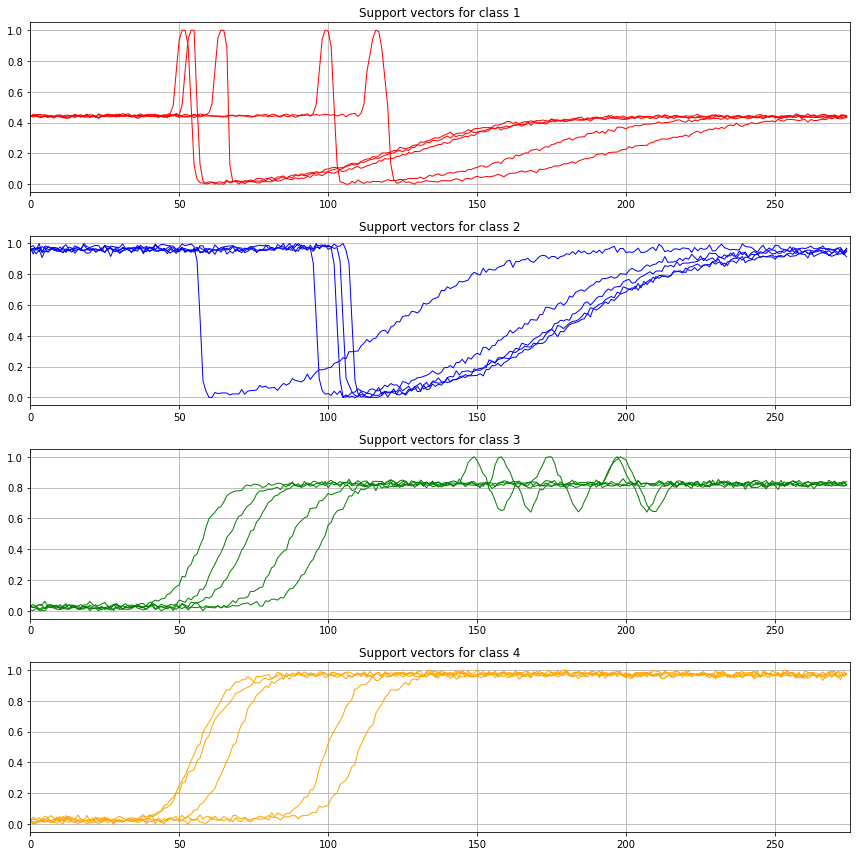
В машинном обучении классификация помогает распознавать классы, к которым принадлежат анализируемые объекты или данные. Важно, что распределение происходит по заранее известным классам. Самый простой пример классификации — распределение электронной почты по папкам «спам»/«не спам».
Sktime
Библиотека с открытым исходным кодом для машинного обучения на Python. Она разработана специально для работы с временными рядами. Sktime включает специальные алгоритмы машинного обучения и отлично подходит для задач прогнозирования и классификации временных рядов.

Что еще подойдет
tslearn
pyts
Кластеризация
Кластеризация — это разбиение исходной совокупности данных на группы таким образом, чтобы внутри группы были минимальные различия между объектами, а между группами — максимальные. В отличие от задачи классификации у нас нет заранее определенных групп, к которым мы будем относить объекты.

Например, у нас есть общая запись голосов птиц. Какие именно это птицы и сколько их, мы не знаем. Но с помощью кластеризации можем разбить их на группы по звучанию, т.е. у нас нет разметки, но мы формируем группы без нее. Кластеризация также используется во многих областях: в медицине разбивают пациентов по результатам анализов или исследований, в поисковой аналитике — целевые запросы по частоте использования, в маркетинге — потребителей по объемам покупок.
tslearn
Универсальная библиотека предназначена для анализа временных рядов с помощью Python. Она основана на библиотеках scikit-learn, numpy и scipy. Предлагает инструменты для предварительной обработки и извлечения признаков, а также специальные модели для кластеризации, классификации и регрессии.
Что еще подойдет
Sktime
Агрегация
Агрегация временного ряда — выделение его признаков. Мы применяем агрегацию, когда преобразуем временной ряд в классический табличный тип, в котором каждая строка представляет собой независимую точку данных.

Агрегация — частая задача при анализе временных рядов. Нам необходимо выделить признаки временного ряда за определенный период, например, максимальное, минимальное, среднее значения показателя. Список возможных признаков и показателей может исчисляться тысячами и ограничен только вашей фантазией. Чтобы посмотреть варианты признаков, которые могут быть выделены, рекомендую заглянуть в описание библиотеки tsfresh. Агрегированные признаки формируют матрицу объектов-признаков, которую можно использовать для обучения классических моделей типа линейных моделей, градиентного бустинга и др.
Kats
Комплексная библиотека для разнообразного анализа временных рядов. Она универсальна и проста в использовании. Содержит не только классические, но и продвинутые методы моделирования данных. Kats помогает прогнозировать и находить аномалии, а также работать с признаками: очищать, извлекать, генерировать и др.
- [прим. ред. — библиотека разрабатывается запрещенной в России организацией, поэтому мы не можем привести ссылки на ее GitHub-репозиторий]
- Kats Python package
- Учебные материалы
Tsfresh
Библиотека tsfresh отлично подходит для подготовки данных к классическому табличному виду с целью постановки и решения задач классификации, прогнозирования и прочих. С ее помощью можно быстро и в автоматическом режиме выделить большое количество признаков временных рядов, а затем отобрать только необходимые. В tsfresh есть разные варианты извлечения признаков от минимального списка (наиболее очевидных и простых признаков), который предоставляет MinimalFCParameters, до полного списка (продвинутые, нетривиальные признаки) ComprehensiveFCParameters.

Поиск аномалий
Поиск аномалий — это задача по обнаружению необычного поведения временного ряда или несвойственного поведения процесса. Эту задачу называют по-разному: поиск выбросов или точечных аномалий, поиск коллективных аномалий или точек изменения состояния. Лучше разобраться с задачей и деталями позволит мой доклад.

Одна из приоритетных задач в Росатоме — поиск аномалий во время мониторинга технологических процессов. Мы ищем возможные отклонения на ранней стадии, чтобы предотвратить потенциальные сбои в работе. Как только аномалия обнаруживается, мы локализируем этот участок и диагностируем его. А затем прогнозируем, как будет развиваться найденная неисправность и насколько достаточен остаточный ресурс агрегата или оборудования. Все это помогает оперативно принимать решения на основе актуальной диагностической информации, а также обеспечивает надежность на производстве.
Merlion
Библиотека с открытым исходным кодом. Предназначена для работы с временными рядами, главным образом — прогнозирования и обнаружения коллективных аномалий. Имеет типовой интерфейс для большинства моделей и наборов данных. Позволяет быстро разработать модель для решения распространенных задач в области временных рядов и тестировать ее на различных наборах данных.
PyOD
Python Outlier Detection или PyOD — это Python-библиотека, которая помогает обнаружить в данных точечные аномалии или выбросы. В библиотеки реализовано более 30 алгоритмов, начиная с классических алгоритмов типа Isolation Forest и заканчивая недавно представленными в научных статьях методами, типа COPOD и другие. Также PyOD позволяет объединять модели поиска выбросов в ансамбли для повышения качества решения задачи. Библиотека проста и понятна, а примеры в документации подробно рассказывают, как ее можно использовать.
Что еще подойдет
Ruptures
Kats
- [прим. ред. — библиотека разрабатывается запрещенной в России организацией, поэтому мы не можем привести ссылки на ее GitHub-репозиторий]
- Kats Python package
- Учебные материалы
Grey kite
Alibi-detect
Библиотек очень много. Часть из них сырые и требуют доработки, потому что разрабатываются независимыми командами. Часть ограничены по кастомизации, а часть имеют не очень удобный интерфейс. У некоторых дублируется функционал, иногда практически полностью. Но несмотря на все недостатки, некоторые библиотеки здорово упрощают работу и высвобождают ценное время. Просмотрите собранные в статье. Они все протестированы лично мной и точно подходят для работы с временными рядами и применения в промышленности. Выбирайте подходящую библиотеку, а если есть вопросы, задавайте их в комментариях.
А если вы хотите поработать с этими и многими другими задачами на практике — переходите на карьерный портал Росатома — возможно, там есть вакансия специально для вас.

8К открытий8К показов
Opera анонсировала выпуск первой стабильной версии браузера Opera One, в который был встроен чат-бот Aria на базе GPT.

FRVR Forge создает простые игры с нуля за несколько минут. Достаточно предложить идею и, при генерации кода, задавать команды.

Рассмотрели основы хэширования в Java и объясним цели использования HashMap и HashSet с примерами синтаксиса.
Какие этапы проходит продукт перед тем, как стать MVP, как его тестировать и отрабатывать возражения, если фичу уже внедрили.