Как устроена RecTools — OpenSource–библиотека для рекомендательных систем
RecTools — это библиотека, где собраны самые часто используемые модели для рекомендательных систем. В статье рассказываем, как она устроена.
В работе с рекомендательными системами ещё не сформирован единый пайплайн работы. Есть верхние уровни таксономии: как методы выглядят, какие являются базовыми, а какие производными, как реализовано дерево методов, какие возникают требования при переходе от уровня к уровню. Но универсальных стандартов их создания нет. Поэтому мы решили сделать более простой инструмент, который содержал бы в себе больше функциональности и который можно было бы использовать для быстрого прототипирования.
RecTools — это библиотека, в которой собраны самые часто используемые модели для построения рекомендаций. Также с её помощью можно максимально просто и быстро оценивать необходимые метрики. Вот как устроена RecTools.

Даниил Потапов
Руководитель направления Data Science в МТС
Даниил Потапов
Руководитель направления Data Science в МТС
Даниил Потапов
Руководитель направления Data Science в МТС
Какие модели используются в библиотеке
Как устроена предобработка данных в RecTools
Как рассчитываются метрики в RecTools
Вспомогательные функции
Что мы дорабатываем
Какие модели используются в библиотеке
«Классические» подходы для работы с рекомендательными системами — библиотеки Implicit и LightFM.
Implicit реализует базовые методы для работы с неявным фидбэком. То есть для создания рекомендательных систем используются не только ответы самого пользователя, например, какой он рейтинг поставил, но и неявные действия: человек долго задержался в ленте на объекте или просто на него кликнул.
LightFM помогает сделать систему, которая будет учитывать не только взаимодействия пользователей и объектов, но и их фичи — атрибуты. Для пользователей это пол, возраст, доход, регион и так далее. Для объектов, например, фильмов — это жанр, режиссёр, бюджет, аннотация фильма.
Верхнеуровнево пайплайны работы Implicit и LightFM похожи, но в деталях это два разных кода, написанных по разным стандартам. Если нужно добавить что-то более современное — например, библиотеку RecBole, которая реализует нейросетевые подходы — то надо дополнительно расписать обвязку для работы с ней. Потому что данные там приводятся к другому формату.
Помимо Implicit и LightFM в RecTools есть наша реализация нейросетевого подхода DSSM. Мы реализовали его с помощью фреймворка PyTorch Lightning.
ПримечаниеДля обучения модели используем Triplet loss. Чтобы его посчитать, нужен якорь (наш пользователь) и 2 примера: позитивный (айтем, с которым было взаимодействие) и негативный. Предварительно мы их выбираем, а здесь считаем их эмбеддинги, прогоняя через «головы» нейросети.
Другая модель в RecTools — популярное, она самая базовая. Она ищет в данных, с чем пользователи чаще всего взаимодействуют — что чаще всего смотрят или покупают. Это легко сделать и проинтерпретировать, но опыт не самый лучший. Потому что в топе будут попадаться либо фильмы, о которых пользователь и так слышал, либо они не будут подходить ему по интересам. Поэтому в RecTools подключены и другие библиотеки.
Последняя модель — Pure SVD, которая реализует векторизацию пользователей и объектов. Она берёт исходную разреженную матрицу взаимодействий и представляет её в виде произведений трёх матриц. В этом суть SVD — Singular Value Decomposition. Из этих трёх матриц складываются две матрицы, которые потом интерпретируются как матрица пользователей и матрица объектов. Там каждая строчка — это вектор пользователя (объекта).
Делаем обычное SVD разложение и превращаем три матрицы в две.
Как устроена предобработка данных в RecTools
Implicit и LightFM требуют похожие, но тем не менее разные форматы данных. Первая библиотека не может работать с дополнительными атрибутами, в отличие от второй. Из-за этого их методы различаются: где-то есть аргумент user features, где-то нет. Мы решили это с помощью единого контейнера для данных, который агрегирует всё, что есть по задаче. При передаче его в модель она сама решает, что ей нужно и не нужно использовать. Можно также дополнительно указывать, какие данные брать.
Более часто встречаемый формат для рекомендательных систем — это разреженные матрицы. Где строки — это пользователи, а столбцы — айтемы. На пересечении пользователя и айтема стоит число, отражающее взаимодействие пользователя с айтемом.
Этот формат использует мало данных, что удобно. Но из него сложно генерировать фичи. Более читабельный для человека формат — это высокая таблица, где каждая строка отражает одно взаимодействие: в первом столбце записан идентификатор пользователя, во втором — объекта (айтема), а в третьем — «значение» взаимодействия, например, рейтинг, который пользователь поставил фильму. Эти два формата полностью эквивалентны, но у таблички преимущество — она расширяема. Туда можно добавлять новые столбцы с дополнительной информацией: временем взаимодействия или обстоятельствами, например, локацией пользователя. Добавить ещё одну размерность в разреженную матрицу сложно и тяжело для восприятия человеком.
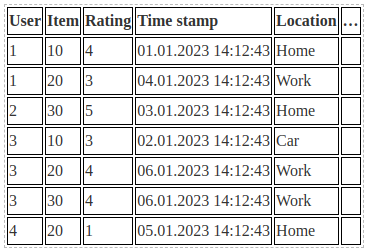
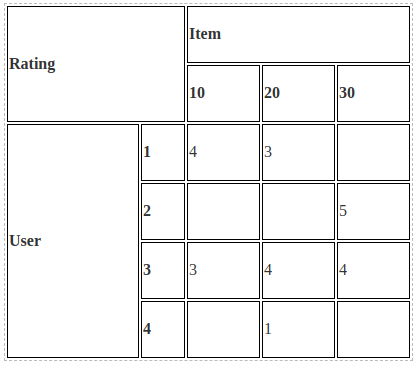
Вот пример, как соотносятся «высокая таблица» и разреженная матрица взаимодействий. В двумерную матрицу не получится уместить дополнительную информацию.
Поэтому в RecTools есть Dataset, который вбирает в себя разные данные. В контейнере используется как раз табличный формат. А на выходе можно агрегировать данные как в виде таблиц, так и в виде разреженных матриц — мы предусмотрели эти модули.
Как рассчитываются метрики в RecTools
Их сложно рассчитывать и за счёт объёма данных, и за счёт нестандартного формата данных. Обычно для этого используют методы реализации, основанные на циклах. Например, мы построили рекомендации для 1 000 пользователей. И для каждого нужен топ-100 рекомендаций. Вместе это даёт таблицу вида 1 000 Х 100, где каждая строка — это пользователь и рекомендация.
Если использовать классические циклы и для каждого пользователя проходиться по топ-100, то можно потратить очень много времени. Этот подход хоть и гибкий, с ним можно реализовать что угодно, но крайне медленный.
Тогда мы решили использовать подход, который позволяет считать метрики на основе табличных данных. Это похоже на Single Instruction Multiple Data. То есть это инструкции в самом процессоре, которые могут применять одну и ту же простую операцию (типа сложения и умножения) к нескольким блокам данных.
Чтобы посчитать для каждого пользователя сумму атрибутов, достаточно взять два столбца и сложить их, как в скалярном произведении, в каждой строке. В цикле это долго, а благодаря операциям над столбцами это как минимум занимает меньше кода, сохраняет интерпретируемость, так ещё и работает в сотни раз быстрее.
Вспомогательные функции
Некоторые пользователи формируются в кластеры, которые, например, часто смотрят какие-то жанры или подмножества жанров. На основе этой информации можно строить рекомендации для нового человека. Нужно оценить его ближайших соседей, то есть на каких пользователей он похож, сформировать список фильмов, которые эти пользователи смотрели, а он нет. И из этого создаётся набор рекомендаций.
Самый простой способ поиска ближайших соседей — это брутфорс. Нужно посчитать расстояние от пользователя до всех остальных и отсортировать этот список. Когда данных мало, то этот способ действенный. Но когда их уже миллион или даже 100 000, то сложность и скорость алгоритма увеличиваются.
Этот вопрос мы решили с помощью Approximate nearest neighbors (ANN) — группы методов для приближённого поиска ближайших соседей. Они строят вспомогательные структуры данных, которые позволяют ускорить поиск за счёт потери в точности. С помощью таких методов можно искать ближайших соседей с невероятной скоростью, вплоть до миллисекунд на пользователя.

Кроме этого, у нас реализована обёртка над способом создания этих пространств — библиотекой nmslib. Она достаёт вектора пользователей и объектов из векторной модели, отправляет в ANN библиотеку и получает ускорение при построении рекомендаций.
Что мы дорабатываем
За счёт того, что мы используем много разных фреймворков, мы забираем и их проблемы, в том числе с установкой. Сейчас мы придерживаемся парадигмы, что должно сохраняться полное описание зависимостей: нужно ставить каждый модуль. Но это таит в себе много проблем: некоторые библиотеки плохо устанавливаются на Windows или определённые Python-версии, в итоге что-то не компилируется. Мы поняли, что от этого нужно отказаться.
Теоретически наш подход правильный. Не должно оставаться окон и моментов, где человек может ошибиться, что-то не поставить или забыть. Но некоторые библиотеки нужно вынести из основного пула, чтобы упростить установку. Как у Python есть extras, когда дополнительные зависимости устанавливаются отдельно. Мы хотим некоторые сложные фреймворки вынести в свой extras, чтобы пользователь при установке сам через квадратные скобки указывал, что ещё поставить.
Мы думаем, как реализовать модули таким образом, чтобы, с одной стороны, была гибкость, а с другой — можно было написать обвязки для других библиотек или фреймворков и сохранить функциональность, который даёт RecTools.

