Логирование как инструмент повышения стабильности веб-приложения
Статья о том, как в крупном проекте уменьшить время на выявление, отладку и устранение ошибок и при этом не потерять в качестве с помощью логирования.

Евгений Холодов
техлид в Dunice
Каждый проект так или иначе имеет жизненные циклы: планирование, разработка MVP, тестирование, доработка функциональности и поддержка. Скорость роста проектов может отличаться, но при этом желание не сбавлять обороты и двигаться только вперёд у всех одинаковые. Перед нами встаёт вопрос: как при работе над крупным проектом минимизировать время на выявление, отладку и устранение ошибок и при этом не потерять в качество?
Существует много различных инструментов для повышения стабильности проекта:
- статические анализаторы (ESLint, TSLint, Pylint и др.);
- контейнеризация (Docker, Vagrant и др.);
- различные виды тестирования (функциональное тестирование, тестирование производительности, системное тестирование, модульное тестирование, тестирование безопасности);
- менеджеры зависимостей (npm, yarn, pip и др.);
- логирование + мониторинг;
- менеджеры процессов;
- системные менеджеры.

В данной статье я хочу поговорить об одном из таких инструментов — логировании.
Логи — это файлы, содержащие системную информацию о работе сервера или любой другой программы, в которые вносятся определённые действия пользователя или программы.
Логи полезны для отладки различных частей приложения, а также для сбора и анализа информации о работе системы с целью выявления ошибок. Всё это необходимо для контроля работы приложения, так как даже после релиза могут встретиться ошибки, а пользователи не всегда сообщают о багах в техподдержку. Чем больше процессов у вас автоматизировано, тем быстрее будет идти разработка.
Допустим, есть клиентское приложение, балансировщик в лице Nginx, серверное приложение и база данных.
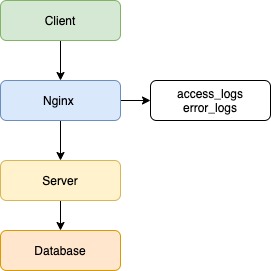
В данном примере не важны язык/фреймворк бэкенда, фронтенда или тип базы данных, а вот про веб-сервер Nginx давайте поговорим. В данный момент Nginx популярнее остальных решений для высоконагруженных сайтов. Среди известных проектов, использующих Nginx: Рамблер, Яндекс, ВКонтакте, Facebook, Netflix, Instagram, Mail.ru и многие другие. Nginx записывает логи по умолчанию, без каких-либо дополнительных настроек.
Логи доступны 2 типов:
- логи ошибок (logs/error.log) — хранят запросы, которые завершились с ошибкой;
- логи доступа (logs/access.log) — хранят информацию обо всех запросах, которые были отправлены на сервер.
Клиент отправляет запрос на сервер, и в данной ситуации Nginx будет записывать все входящие запросы. Если возникнут ошибки при обработке запросов, сервером будет записана ошибка.
2020/04/10 13:20:49 [error] 4891#4891: *25197 connect() failed (111: Connection refused) while connecting to upstream, client: 5.139.64.242, server: app.dunice-testing.com, request: "GET /api/v1/users/levels HTTP/2.0", upstream: "http://127.0.0.1:5000/api/v1/users/levels", host: "app.dunice-testing.com"
Всё, что мы смогли бы узнать в случае возникновения ошибки, — это лишь факт наличия таковой, не более. Это полезная информация, но мы пойдём дальше. В данной ситуации помог Nginx и его настройки по умолчанию. Но что же нужно сделать, чтобы решить проблему раз и навсегда? Необходимо настроить логирование на сервере, так как он является общей точкой для всех клиентов и имеет доступ к базе данных.
Первым делом каждый запрос должен получать свой уникальный идентификатор, что поможет отличить его от других запросов. Для этого используем UUID/v4. На случай возникновения ошибки, каждый обработчик запроса на сервере должен иметь обёртку, которая отловит эти самые ошибки. В этой ситуации может помочь конструкция try/catch, реализация которой есть в большинстве языков.
В конце каждого запроса должен сохраняться лог об успешной обработке запроса или, если произошла ошибка, сервер должен обработать её и записать следующие данные: ID запроса, все заголовки, тело запроса, параметры запроса, отметку времени и информацию об ошибке (имя, сообщение, трассировка стека).
Собранная информация даст не только понимание, где произошла ошибка, но и возможную причину её возникновения. Обычно для решения ошибки информации из лога достаточно, но в некоторых случаях может быть полезен контекст запроса. Для этого необходимо при старте запроса не только генерировать ID запроса, но и сгенерировать контекст, в который мы будем записывать всю информацию по работе сервера, начиная от результата вызова функции и заканчивая результатом запроса к базе данных. Такая реализация даст не только входные данные, но и промежуточные результаты работы сервера, что позволит понять причину появления ошибки.

При микросервисном подходе система не ограничивается одним сервером, и при запросе от клиента происходит взаимодействие нескольких серверов внутри системы. Наша реализация логирования на сервере позволит выявить дефект в работе конкретного ресурса, но не позволит понять, почему запрос вернулся с ошибкой. В данной ситуации поможет трассировка запросов.
Трассировка — процесс пошагового выполнения программы. В режиме трассировки программист видит последовательность выполнения команд и значения переменных на каждом шаге выполнения программы.
В нашем случае требуется передавать метаинформацию о запросе при взаимодействии серверов и записывать логи в единое хранилище (такими могут быть ClickHouse, Apache Cassandra или MongoDB). Такой подход позволит привязать различные контексты серверов к уникальному идентификатору запроса, а отметки времени — понять последовательность и последнюю выполненную операцию. После этого команда разработки сможет приступить к устранению.

В некоторых случаях, которые встречаются крайне редко, к ошибке приводят неочевидные факторы: компилятор, ядро операционной системы, конфигурации сервера, юзабилити, сеть. В таких случаях при возникновении ошибки потребуется дополнительно сохранять переменные окружения, слепок оперативной памяти и дамп базы. Такие случаи настолько редки, что не стоит беспочвенно акцентировать на них внимание.
С сервером разобрались, что же делать, если у нас сбои даёт клиент и запросы просто не приходят? В такой ситуации нам помогут логи на стороне клиента. Все обработчики должны отправлять информацию на сервер с пометкой, что ошибка с клиента, а также общие сведения: версия и тип браузера, тип устройства и версия операционной системы. Данная информация позволит понять, какой участок кода дал сбой и в каком окружении пользователь взаимодействовал с информацией.

Также есть возможность отправлять уведомления на почту разработчикам, если произошли ошибки, что позволит оперативно узнавать о сбоях в системе. Такие подходы активно используются в системах мониторинга и аналитики логов.
Способы, которые мы рассмотрели в статье, помогут следить за качеством продукта и минимизируют затраты на исправление недочётов в системе.

