Низкоуровневая модель памяти
В прошлой статье мы разбирались с высокоуровневой памятью. Сегодня мы рассмотрим принципы её работы на низком уровне.

В прошлой статье была рассмотрена высокоуровневая часть модели памяти. В этой статье подробно описано, что на самом деле происходит с памятью в компьютере на примере Intel x86_64.
Обзор
Схематично и очень упрощённо модель памяти выглядит так:

Статья детально описывает эту модель, а также принципы работы виртуальной памяти в защищённом режиме.
Регистры
Регистр процессора — блок памяти, расположенный прямо на кристалле процессора и образующий сверхбыструю оперативную память (СОЗУ). В x86_64 размеры регистра, за исключением векторных, варьируются от 8 до 64 бит.
Программа может быстро работать только с памятью, находящейся в регистрах процессора. Даже для простого инкремента ячейки памяти из RAM (Random Access Memory) необходимо выполнить 3 операции: сначала загрузить эту ячейку из RAM или кэша в регистр, затем инкрементировать и после выгрузить ячейку из регистра обратно в RAM или кэш.
Количество и специализация регистров зависит от архитектуры процессора, но типы регистров можно разделить на две группы: регистры общего назначения, необходимые для хранения и использования переменных, принадлежащих программам, и специализированные регистры, хранящие различную метаинформацию, которая может даже менять поведение процессора.
Если с регистрами общего назначения всё понятно, то вот некоторые специализированные регистры в x86_64 и их назначение:
- Instruction Pointer (IP) — указатель на текущую инструкцию программы. После выполнения каждой команды IP увеличивается на длину этой команды (во многих архитектурах размер инструкции неконстантный), и тем самым начинает указывать на следующую команду.
- Stack Pointer (SP) — указатель на вершину стека.
- Регистр флагов (RFLAGS) — содержит текущее состояние процессора и некоторую информацию о результате предыдущей команды (бит переполнения при сложении и умножении; бит нуля при вычитании и т. д.).
- Управляющие регистры (CR0–CR15) — основные регистры для управления поведением процессора.
- Регистры отладки (DR0–DR15) для отладки и сбора статистики работы процессора.
Также существуют векторные регистры общего назначения (ZMM0–ZMM31), необходимые для математических операций над несколькими числами (вектором) одновременно.
L1–L3 кэширование
Многогигабайтную память в процессор не засунуть, поэтому в нём есть относительно небольшое количество регистров и кэш, а остальная память хранится в RAM.
Но RAM имеет очень большую задержку (около 230 тактов процессора i7-4770), поэтому часть этой памяти кэшируется в самом процессоре. Кэширование многоуровневое, чем меньше память и непосредственно ближе к регистрам, тем проще её адресовать и тем она быстрее.
L1-кэш находится в каждом ядре процессора, кэширует как данные, так и инструкции (которые в свою очередь тоже являются данными; один и тот же набор двоичного кода может быть интерпретирован и как данные, и как инструкции). Задержка минимальна — 4 такта на i7-4770 и размер 64 КБ (32 КБ на данные и 32 КБ на инструкции) на каждое виртуальное ядро.
L2-кэш также находится в каждом ядре, но кэширует только данные — 12 тактов и 1 МБ на ядро.
L3-кэш — общий для всего процессора, кэширует только данные — 36 тактов и 8 МБ.
Задержка в тактах примерная и не отражает реального положения дел, цифры приведены на основе бенчмарков только для того, чтобы показать относительную разницу кэшей и RAM.
Детали кэширования на примере L1 и Haswell
Кэш L1 представляет собой таблицу из сетов, каждый из которых формируется из записей, состоящих из битов состояния, тега и кэш-линии. Вот урезанная версия такой записи:

Индекс — это номер сета в таблице, а также с 6-го по 11-й биты указателя на память в RAM. Поэтому от расположения в RAM (номер адреса) зависит то, в каком сете будет кэшироваться этот блок памяти размером в кэш-линию.
С 0-го по 5-й биты — это смещение внутри кэш-линии.
Сет состоит из нескольких записей, в случае с Haswell их 8.
Тег — это остальная часть указателя с 12-го бита для нахождения нужной записи в сете.
Биты состояния указывают на то, модифицировалась ли кэш-линия, а также актуальность кэш-линии. У каждого ядра свой L1- и L2-кэш, поэтому их нужно синхронизировать. Для этого и существуют биты состояния. Более подробно на Хабре.
Кэш-линия — это несколько физически подряд расположенных байтов из RAM, в нашем случае 64 байта.
В i7-4770 128 сетов в L1-кэше на одно виртуальное ядро — 64 на данные и 64 на инструкции. Поэтому для индексирования этих кэш-сетов необходимо 6 бит (2^6 = 64).
Всего выходит 1024 записи (128 сетов по 8 записей), в каждой из которых по 64 байта в кэш-линии. В сумме 64 КБ L1-кэша на ядро.
Здесь есть небольшая проблема: если произвести небольшие вычисления, можно понять, что каждые 64 КБ в памяти будут кэшироваться в одном и том же сете. Поэтому использование только каждых 64 КБ или бо́льшей степени двойки, полностью нивелирует профит от использования L1-кэша. Это доказывается многими бенчмарками, но в реальной работе никто так делать не будет. Кэши прочих уровней имеют эту же проблему, только для индекса используются больше бит.
Атомарность
При попытке двух ядер одновременно инкрементировать один и тот же байт RAM памяти, допустим, равный 0, в зависимости от «фазы луны» мы можем получить любое число от 0 до 2. Например, оба процессора прочитали из RAM 0, затем оба инкрементировали свои регистры до 1, затем оба записали 1 обратно в RAM.
Это одна из самых основных проблем многопоточных программ и разных программ с общей памятью.
Решается это добавлением префиксного байта LOCK в начало ассемблерной инструкции (например xaddl), что делает её атомарной. Данная операция посылает сигнал в другие ядра, запрещая использование данных, пока не будет завершена ассемблерная инструкция. Таким образом, пока одно ядро занято инкрементом, другое будет ждать.
Защищённый режим
Во времена DOS-систем процессоры работали в «реальном режиме», где используется сегментная адресация памяти, при которой любому процессу доступна вся память компьютера, и он может выполнить любую допустимую инструкцию процессора. Когда процесс работает в среде ОС монопольно, это очень выгодно с точки зрения производительности, но появляются проблемы при нескольких работающих одновременно процессах. Для того, чтобы один процесс не смог случайно или специально несогласованно использовать память другого процесса или исполнить привилегированную инструкцию, которая может повлиять на работу ОС и других процессов, и был придуман «Защищённый режим».
Для этого во все операции необходимо добавить проверку прав доступа. Права доступа на инструкции определяются через кольца защиты, а памяти — через виртуальную адресацию.
За исключением некоторых тонкостей, ненужных в этой статье, для переключения в защищённый режим x86_64 (есть ещё классический защищённый режим x86) необходимо установить биты PE (Разрешение защиты, бит 0) и PG (Страничный режим, бит 31), включающий MMU, в регистре CR0, а также указатель на таблицу PML4 в регистре CR3 (c 13 по 63 бит). Именно в таблице PML4 и хранится информация об адресах, правах доступа и прочем.
Кольца защиты
В процессорах x86 используется система колец защиты. Каждая инструкция имеет свои требования к правам процесса. Текущий уровень прав выполняющегося процесса указан в таблицах дескрипторов, указатели на которые лежат в соответствующих регистрах. В x86 существует 4 кольца защиты, от полных прав доступа (0) до пользовательских прав (3). Но для переносимости на другие платформы некоторые ОС используют только два кольца. Даже Windows NT, которая раньше была очень даже кроссплатформенной, сейчас имеет редакцию только для x86 и ARM-систем.
Виртуальная адресация
Виртуальная адресация — метод управления памятью компьютера, позволяющий выполнять программы, требующие больше оперативной памяти, чем имеется в компьютере, а также изолировать память процессов друг от друга.
Виртуальный указатель не соответствует физическому указателю на ячейку в RAM. Это сделано для того, чтобы виртуальная память могла быть больше реальной RAM-памяти, например для файла подкачки (физическая память + подкачка явно больше, чем просто физическая память) или поблочного отображения файлов и устройств в память.
А также для того, чтобы при разыменовании указателя проходил процесс проверки прав доступа к этой памяти при трансляции адреса из виртуального в физический, чтобы случайно или специально не залезть в чужую память.
Трансляция адресов
В защищённом режиме сам процессор и L1-кэш работают с виртуальным адресом, а L2, L3 и RAM — с физическим. Трансляцией адресов из виртуального в физический, а также проверкой прав доступа занимается MMU (Memory Management Unit) — блок управления памятью, использующий PML4.
PML4
Таблица выглядит следующим образом:
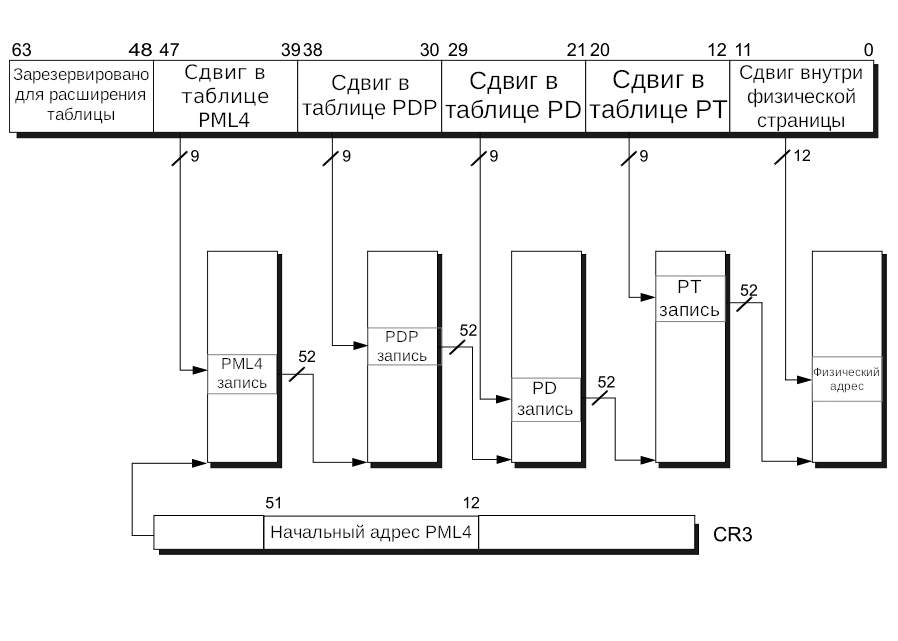
Виртуальный указатель делится на две части: с 12-го по 47-й бит — сдвиги внутри таблиц в PML4, с 0-го по 11-й бит — сдвиг внутри физического адреса для поддержки арифметики указателей.
Указатель на начало PML4-таблицы лежит в CR3 с 12-го по 51-й биты. С 39-го по 47-й бит виртуального указателя — номер страницы из PML4-таблицы, в которой лежит указатель на начало PDPT-таблицы. С 30-го по 38-й бит находится номер страницы из PDPT-таблицы, в которой лежит указатель на начало PD. Аналогично и с PT, но в ней уже лежит физический адрес, к которому добавляется сдвиг виртуального указателя — с 0-го по 11-й биты. В итоге получается физический адрес, по которому MMU и обращается к физической памяти.
Внимательный читатель мог заметить две сложности:
- В виртуальном режиме виртуальный указатель имеет размер только 48 бит, что позволяет адресовать только 2^48 байт или 2^8 ТБ или 256 ТБ. Если бы были все 64 бит, тогда таблица PML4 была бы ещё больше, что увеличило бы задержку при разыменовании указателя. В современных серверных процессорах Intel есть виртуальная адресация вплоть до 57 бит (128 ПБ), которая добавляет перед PML4 ещё одну таблицу.
- Даже с 4 таблицами разыменование очень долгое. Для решения этой проблемы используют TLB-кэш для кэширования PML4-таблицы.
TLB-кэш внутренне схож с LX-кэшами, только служит для трансляции виртуальных адресов и представляет собой таблицу из сетов, внутри которых записи: «виртуальный адрес ↔ физический адрес». PML4 адресована только по физическим адресам, поэтому сама PML4 может кэшироваться только в L2-L3 кэшах.
Сдвиг внутри страницы — 12 бит, поэтому минимальный размер такой страницы — 4 КБ. Процессу очень редко нужны сразу 4 КБ памяти (а меньше выделить у ОС нельзя). Поэтому процессы используют аллокаторы, о которых было сказано в прошлой статье.
Для увеличения скорости трансляции виртуальных адресов можно убрать некоторые промежуточные таблицы, но в таком случае освободившиеся биты будут использованы для сдвига внутри страницы, что увеличивает размер таких страниц. В x86_64 размеры страниц бывают 4 КБ (12 бит), 2 МБ (12 + 9 бит вместо PT), 1 ГБ (12 + 9 + 9 бит вместо PD). Использование большого количества 4 КБ страниц может привести к сильному увеличению размера PML4, которая перестанет помещаться в L2-L3 кэши, что сильно увеличит время разыменования.
Подробнее о TLB на примере Haswell
TLB представляет собой схожую с LX-кэшами структуру. В процессоре Intel Haswell существует два TLB разного уровня. Индексация и тегирование производятся аналогично, но кэш-линия заменена на адрес физической таблицы и её атрибуты и права доступа из PML4, но не всегда полностью (об этом в разделе про Meltdown). TBL тоже многоуровневый и тоже отдельно кэширует указатели на данные и указатели на инструкции.
TLB первого уровня в Haswell делится на ITLB (instructions) и на DTLB (data). Минимальная задержка — 1 такт, размер сета — 4 записи, только для 4 КБ сегментов, либо только для 2 МБ сегментов (зависит от ОС и её настроек). Размер — 32 записи для 2 МБ сегментов и 64 — для 4 КБ.
TLB второго уровня (STLB) — только для данных, задержка — 22 такта, размер сета — 8 записей, размер — 1024 записи для 2 МБ и 4 КБ сегментов одновременно.
При смене контекста TLB приходится сбрасывать из-за возможного совпадения виртуальных адресов.
Ещё немного о кэшировании
По отношению к виртуальной адресации кэши данных и инструкций могут быть поделены на 3 используемых в реальных процессорах типа.
Physically indexed, physically tagged (PIPT) — физически индексируемые и физически тегируемые (тег и индекс берутся из физического адреса). Такие кэши просты и избегают проблем с наложением (aliasing), но они медленны, так как перед обращением в кэш требуется запрос физического адреса в TLB. Этот запрос может вызвать промах в TLB и дополнительное обращение в PML4.
L2 и L3 расположены после MMU, поэтому они могут использовать только этот тип. L1 остаётся либо каждый раз лезть в MMU, что слишком долго, либо использовать другой тип, что L1 и делает.
Virtually indexed, virtually tagged (VIVT) — виртуально индексируемые и виртуально тегируемые. И для тегирования, и для индекса используется виртуальный адрес. Благодаря этому проверки наличия данных в кэше проходят быстрее, не требуя обращения к MMU.
Однако возникает проблема наложения, когда несколько виртуальных адресов соответствуют одному и тому же физическому. В этом случае данные будут закэшированы дважды, что сильно усложняет поддержку когерентности. Другой проблемой являются омонимы, ситуации, когда один и тот же виртуальный адрес (например, в разных процессах) отображает различные физические адреса. Становится невозможно различить такие отображения исключительно по виртуальному индексу.
Возможные решения: сброс кэша при переключении между процессами, требование непересечения адресных пространств процессов, тегирование виртуальных адресов идентификатором адресного пространства (address space ID, ASID) или использование физических тегов. Также возникает проблема при изменении отображения виртуальных адресов в физические: требуется сброс кэш-линий, для которых изменилось отображение.
Virtually indexed, physically tagged (VIPT) — виртуально индексируемые и физически тегируемые. Для индекса используется виртуальный адрес, а для тега — физический. Преимуществом перед первым типом является меньшая задержка, поскольку можно искать кэш-линию одновременно с трансляцией адресов в TLB, однако сравнение тега задерживается до получения физического адреса. Преимуществом перед вторым типом является обнаружение омонимов (homonyms), так как тег содержит физический адрес. Для данного типа требуется больше бит для тега, поскольку индексные биты используют иной тип адресации.
Но даже у VIPT-кэша есть проблема: при изменении кэш-записи в кэше одного ядра или в RAM придётся искать эту же кэш-запись в кэшах других ядер для инвалидации. Но искать придётся по физическому адресу (два одинаковых виртуальных адреса у разных процессов могут указывать на разную физическую память), поэтому использование индексации по виртуальному адресу заставляет пробегать весь кэш и сравнивать каждый тег.
В процессорах Intel это решается индексацией и по виртуальному, и по физическому адресу. Из-за того, что биты с 0-го по 11-й — это смещение внутри страницы в таблице PML4, они совпадают у физического и виртуального адреса. Поэтому используемые для индекса с 6-го по 11-й биты указателя совпадают и у физического, и у виртуального адреса. Благодаря этому L1-кэш имеет тип как PIPT, так и VIPT, но его максимальный размер в процессорах Intel равен минимальному размеру страницы из таблицы PML4, умноженному на количество записей в сете кэша: 64 КБ * 8 = 512 КБ — L1-кэш на все ядра и 64 КБ — L1 на одно ядро. Но увеличение размера записей в сете увеличивает задержку. Поэтому в современных процессорах Intel L1-кэш особо не растёт, ибо это увеличит задержку.
Процесс трансляции
В защищённом режиме разыменование идёт следующим образом:
1. Идём параллельно в L1 и в TLB. Далее весь процесс делится на две части: поиск нужной кэш-линии (п. 2) и трансляция виртуального адреса (п. 3).
2.1. Берём индекс из виртуального указателя и ищем нужный сет. Далее ждём, пока закончится процесс трансляции виртуального адреса (п. 3).
2.2. После получения физического адреса сравниваем теги в записях внутри сета. Если нашлось совпадение, это нужная нам кэш-линия. Если нет, идём дальше в L2.
2.3 Производим аналогичные действия, но уже с кэшами L2 и L3. В них используются только физические адреса, благо такой мы уже получили, ведь процесс трансляции (п. 3) закончился до начала этапа (п. 2.2).
2.4 Если в кэшах не нашлось, идём в медленный RAM.
3.1 Идём в TLB и сравниваем индексы и теги по аналогии с кэшами. Если нашли совпадение, возвращаемся в этап 2.1.
3.2 Если нет (такая ситуация называется Page walk), берём физический адрес из регистра CR3 и повторяем этапы 2.3–2.4, но для поиска и чтения PML4. Если нашли совпадения в таблице, проверяем права доступа и возвращаемся на этап 2.1 с полученным физическим адресом.
3.3 Если совпадения в таблице нет, либо были нарушены права доступа, например, попытка произвести запись, когда доступно только чтение (такая ситуация называется Page fault), то генерируем прерывание. Далее вызывается обработчик прерываний ОС, который решает, что делать с этой ситуацией.
Роль ОС в виртуальной памяти на примере Linux
Вот тут мы плавно подходим к высокоуровневой памяти.
Запуск процесса
Перед запуском процесса ОС выделяет ему сегменты необходимого размера в PML4 (выбирая среди 4 КБ, 2 МБ, 1 ГБ) для стека и статической памяти. У каждого процесса своя таблица PML4. При смене контекста ОС выставит указатель в CR3 на нужную таблицу.
При необходимости процесс может запросить у ОС дополнительный сегмент, например, через системный вызов mmap. ОС при возможности добавит запись в PML4, а также в свои таблицы, и вернёт указатель на начало этой памяти процессу, иначе — вернёт нулевой указатель.
Получается, что на низком уровне автоматическая, статическая, динамическая память — это всё сегменты.
Виртуальная память в ОС
PML4 изначально была создана для виртуальной памяти, но ОС использует её и для других задач.
Файл подкачки
Часть памяти может находиться в файле подкачки. При нехватке памяти ОС может часть этой памяти перенести на диск. Вместе с этим ОС удаляет запись из PML4, чтобы при попытке обратиться к этой памяти был сгенерирован Page Fault. Это было сделано для того, чтобы при попытке обратиться к памяти, которая была отгружена на диск, вызвать ОС, которая загрузит память из диска обратно в ОС, вернёт запись в PML4 и передаст управление обратно процессу, который на сей раз благополучно повторит процесс разыменования.
Файл или устройство, отображённое в память
mmap можно использовать и для отображения файла (в *nix системах устройства — тоже файлы) в память. Для этого создаётся буфер в физической памяти, в которую записывается часть файла, и создаётся запись в PML4. Если процесс выйдет за границу виртуальной памяти в PML4, то ОС загрузит новый кусок файла в буфер и отредактирует PML4, сдвинув виртуальный указатель, но оставив физический.
В итоге для процесса внешне будет казаться, что весь файл загружен в память, когда на самом деле только часть этого файла в буфере.
COW-память и ленивая аллокация
При вызове mmap в некоторых ОС никакой памяти на самом деле не выделяется, только добавляется запись в структурах самой ОС. При первом обращении процесса к ещё не аллоцированной памяти будет Page Fault, во время которого ОС произведёт полную аллокацию. Это удобно в случае, когда процесс аллоцировал память, но никогда её не использовал. В таком случае пройдёт только первый, ленивый и относительно быстрый этап аллокации.
С COW дела обстоят схоже.
Copy On Write память — это память, общая для чтения у нескольких объектов в системе (под объектами имеется в виду что угодно, начиная от объектов в ООП и заканчивая процессами с разделяемой памятью). Если же один из объектов начинает писать в память, то перед этим такая память делится на две части: одна остаётся у всех остальных объектов, а другая становится памятью только для объекта, который хочет её изменить. В итоге мы получаем экономию памяти, а в случае необходимости записи в эту память, мы её копируем.
У всех процессов с COW-памятью в PML4 ставится флаг «только чтение» для того, чтобы при записи вызвать ОС через Page Fault для разделения памяти. Реальные же права доступа на запись ОС хранит в своих таблицах.
Это были несколько примеров того, как ОС по-хитрому использует PML4 для своих нужд.
Meltdown
Во многих современных процессорах обнаружили уязвимость в этой системе виртуальных адресов и кэшей. Её назвали Meltdown.
Ещё немного о PML4
Перед тем как продолжить, рассмотрим немного подробнее таблицу PML4. В ней и в каждой подтаблице есть не только адрес следующей таблицы, но и биты с метаинформацией этой таблицы. Рассмотрим некоторые из них.

- P (Present) указывает на то, что далее идёт таблица следующего уровня. Если 0, то вместо указателя на следующую таблицу лежит указатель на физическую страницу без смещения. Если в PT будет лежать сразу указатель на физический сегмент, то такой сегмент будет размером 2 МБ. C 1 ГБ сегментами аналогично, только в PD-таблице.
- R/W (Read/Write) указывает на доступ для чтения. Если стоит 0, то разрешено только чтение.
- NX (No Execute) (самый левый), установленный в 1, запрещает исполнение данных как программный код.
- U/S (User/Supervisor), установленный в 0, запрещает использовать данные процессам (User, кольцо защиты 3), память может быть использована только ОС и драйверами (Supervisor, кольцо 0) (это по сути самый важный флаг для Meltdown).
- A (Accessed) указывает на то, была ли память, на которую указывает таблица, использована хотя бы раз.
Принцип работы
Наконец, перейдём к самому принципу работы уязвимости Metldown.
Ранее уже было написано о спекулятивном исполнении команд в статье об архитектуре процессора. Цитата из статьи: «Спекулятивное исполнение команд — это выполнение команды до того, как станет известно, понадобится эта команда или нет».
Суть атаки в том, что современные ОС всё своё адресное пространство отображают в адресном пространстве каждого пользователя (процесса). Другими словами добавляют в PML4-таблицу процесса указатели на подтаблицы ОС, но с флагом U/S, установленным в 0. Это сделано для того, чтобы при переключении контекста процесса уменьшить количество операций перезаписи CR3 и улучшить кэширование данных ОС с чистыми VIPT- или VIVP-кэшами (PML4 первого процесса → PML4 второго процесса вместо PML4 первого процесса → PML4 ОС → PML4 второго процесса), но эту защиту можно обойти в некоторых процессорах Intel и ARM (у AMD обнаружили только уязвимость Spectre, у которой другой принцип работы).
Некоторые ОС используют одну PML4-таблицу на всю систему, а при переключении контекста меняют только подтаблицы. Отсюда в той же Windows максимальный размер ОЗУ 256 ГБ — максимальный размер таблицы PDP.
При спекулятивном исполнении в уязвимых процессорах часть команд может выполниться до того, как будет проверено, стоит ли бит 0 в U/S флаге. Причём благодаря спекуляции код атаки может быть выполнен из недостижимого кода, например, в ветке else при всегда истинном условии в if, перед тем, как процессору станет известно, что этот код недостижим. После того, как процессор поймёт, что доступа к этой памяти нет, он обнулит результат команд доступа к памяти, сбросив соответствующие регистры, но TLB- и L1-кэш он сбрасывать не будет. А в них уже не хранится флаг U/S, поэтому процесс может получить полный доступ к успевшей закэшироваться закрытой памяти ядра ОС, ведь процессор, который нашёл нужную запись в L1 и TLB, не будет проверять её в PML4. Решается эта проблема либо аппаратно — добавлением флагов из PML4 в TLB, либо программно — удаление таблиц памяти ОС из PML4-процессов, что увеличит время смены контекста и системных вызовов.
Вывод
Это далеко не всё, что можно рассказать про низкоуровневую память и уж тем более про всю архитектуру ПК пусть даже одного x86_64. Это лишь некоторая часть базы, сильно привязанная к конкретной архитектуре, в других архитектурах используются схожие, но не одинаковые подходы.
Для более подробного изучения этой темы вы можете прочитать литературу, например, трёхтомник Э. С. Таненбаума или документы от Intel про x86_64 — благо они есть в свободном доступе — или другую микроархитектуру, а также посмотреть доклад с конференции C++ Russia 2018 для уточнения некоторых мелочей про кэши и виртуальную адресацию, не описанных в этой статье.

















