Как сделать матчинг товаров: тайтлы, БЕРТы и две сестры

Как сделать матчинг товарных позиций на маркетплейсе с 2 миллионами товаров от иностранных и российских продавцов? Опыт AliExpress.
Итак, у нас маркетплейс с примерно 2 миллионами товаров от иностранных и российских продавцов, инфраструктура крупнейшей китайской платформы — и задача сделать собственный матчер, который будет работать не хуже, чем написанный командой Alibaba.
Матчинг — это…
Product Matching — это сравнение описаний товаров, полученных из разных источников (маркетплейсов, магазинов, отдельных продавцов и так далее), а матчер — инструмент, который этот процесс производит.
Зачем нам матчинг товарных позиций? Чтобы собирать одинаковые товары от разных продавцов — и попадать в ожидания покупателей. Так, автомобильные коврики попадают в раздел с автотоварами, а коврики для ванной отображаются вместе с товарами для дома — хотя и то и другое коврики, вряд ли кто-то готов видеть их в одном разделе.
При этом у нас есть карточка товара, которую заполняет продавец, она же Item — то есть группа товаров, которые объединены по общему признаку, но различаются характеристиками, типом доставки, ценой и так далее. Также есть SKU — конкретные продукты с определённым типом доставки, характеристиками и ценой.
Сложности задаче добавляет и то, что продавцы не всегда корректно заполняют данные о своих товарах. Например, китайские продавцы иногда описывают цвета так:
- Yellow — жёлтый;
- BL — голубой;
- мы — белый (продавец заполняет его как we, сокращённо от WhitE, а автоперевод превращает это в «мы»)
- Red — синий;
- 0451 — мы сами до сих пор не знаем, что это.
«Из коробки» модель с таким не справится, и нужно разбираться самостоятельно. Так, мы посмотрели около семи миллиардов атрибутов, из которых три миллиарда касались цветов. Понять, что цвет — это действительно цвет, мы смогли только в половине случаев.
Почему? Китайские продавцы вписывают в атрибут «цвет» самые разные характеристики: количество, размер, пол, возраст, случайные числа и ещё много всего. Кроме того, одни и те же атрибуты разные селлеры заполняют по-своему: у каждого свои стандарты, свой язык, сокращения и так далее.
Сначала мы решили просто почистить всё вручную и написать правила — но атрибутов очень много (и их количество постоянно растёт). Тогда мы отобрали топовые — но популярность атрибута зависит от категории. Стали чистить внутри категории — но категории тоже разные. Например, наша категория «чехлы» на другом маркетплейсе называется «кейсы».
Кроме того, некоторые продавцы вообще не заполняют атрибуты, а оставляют всю информацию в заголовке (кстати, именно отсюда берутся легендарные названия товаров AliExpress).
И что делать?
У нас двухстадийный пайплайн. На первом этапе ищем соседей. Берём базы данных с названиями и изображениями товаров. В каждой из баз мы выбираем топ-100 ближайших соседей — это и будут кандидаты на матчинг — и смотрим, насколько отличаются в паре картинки, названия товарных позиций и так далее.
А на втором этапе передаём информацию в мета-модель, которая решает, одинаковые товары или нет.
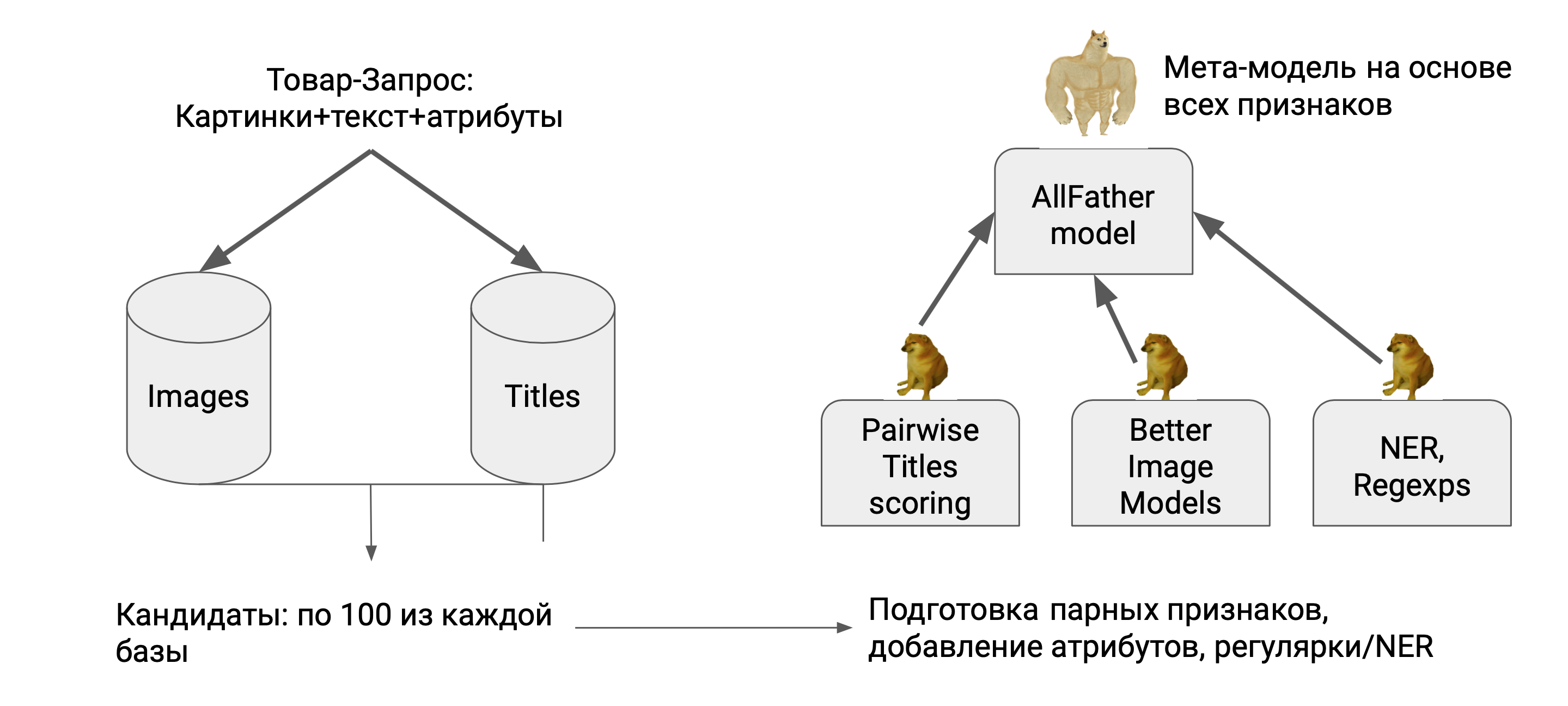
Так поиск кандидатов на матчинг работает на Item-уровне, но сами матчи мы рассматриваем на SKU-уровне — это позволяет использовать быстрые и легковесные модели для поиска соседей и отсеивать миллиарды неправильных кандидатов. А оставшиеся сотни проверять на более точных, но медленных моделях.
Матчер: часть картиночная
Для «картиночной» модели мы решили использовать модель ArcFace, изначально созданную для распознавания лиц. Она учится различать лица, снятые с разных ракурсов — и для этого старается развести эмбеддинги классов как можно дальше.
Но чтобы использовать ArcFace для матчинга изображений товаров, мы сделали условные «лица» — кластеры похожих товаров. Сначала взяли информацию о совпадениях изображений из базы, размеченной с помощью сервиса Яндекс.Толока, а затем объединили товары в группы по визуально одинаковым изображениям.
Задача осложнилась тем, что часто одна и та же картинка сопровождает разные товары: например, фотография чехлов на автомобильные сиденья встречается 320 раз, а фотография с текстом объединяет примерно 39 тысяч разных товаров.
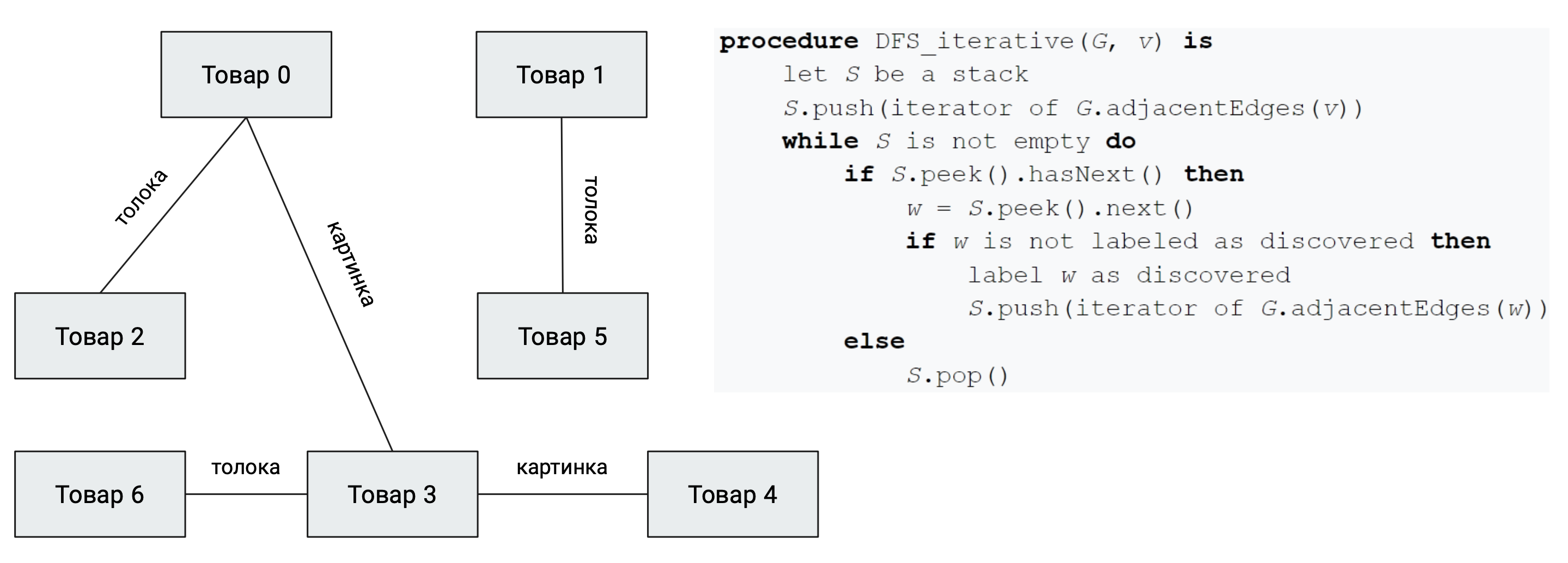
Решить эту проблему помог TrashPred — модель, определяющая ценность картинок для матчинга. Благодаря ему мы определяли, какие картинки нужны для обучения модели, а какие — нет. Как он работает:
- берём все известные матчи – в первую очередь, размеченные с помощью Яндекс.Толоки;
- находим почти одинаковые картинки;
- строим и анализируем граф связности товаров,
- обучаем и прогоняем TrashPred;
- исключаем неинформативные картинки, обновляем выборку треша и снова возвращаемся к третьему пункту;
- повторяем, пока данные не очистятся.
Так у нас получилось 300–400 тысяч групп (или «лиц») товаров, на которых уже можно было обучать модель. Эмбеддинги, которые получались на выходе, уже были достаточно хороши, для того чтобы искать ближайших соседей, но работа с только картиночной моделью оказалась не такой точной, как нам хотелось.
Текстовая часть
Текстовый матчинг основан на BERT’ах — они помогают различать названия с разницей всего в один символ, тогда как тот же Word2Vec с этой задачей уже не справляется. Например, диоптрии +1,5 и -1,5 делают контактные линзы принципиально разными, а для анализа текста разница в один символ будет несущественной.
В трансформерах мы можем устанавливать связь каждого токена в запросе с каждым токеном в документе. То есть, подаём в модель название и атрибуты товара в запросе и товара в документе — и она сама выносит решение.
Способ точный, но медленный. А у нас миллиарды товаров. Как всё оптимизировать?
Мы использовали ColBERT, где считается схожесть каждого токена в запросе со всеми токенами документа. При этом использовали более быструю и лёгкую модель, которая обучалась с помощью metric learning (triplet loss).
Почему же она так хорошо работает? Разберём на примере. Допустим, у нас есть документ и запрос с тремя токенами. Мы, с точки зрения косинусной схожести, находим лучшие совпадения и считаем итоговое сходство как сумму трёх похожестей. При этом нам не нужно запускать сетевые модели для поиска соседей. Достаточно использовать FAISS, потому что модель напрямую училась делать похожие эмбеддинги с помощью metric learning подхода.
В итоге модель ColBERT работает в качестве ранжирующей и ищет ближайших соседей. А классификационная модель BERT уже работает на финальном скоринге пар-кандидатов на матч. И она уже умеет «говорить нет» похожим, но разным товарам.

Суперматчинг
Мы используем несколько разных моделей для матчинга: старый матчер, BERT’ы, картинки, артикулы. И матчим разные магазины и разные категории товаров (качество контента и распределения товаров по категориям тоже разные). Качество в итоге может быть непостоянным.
Как мы работали раньше:
- для каждой модели делали выборку товаров, которую прогоняли через процесс матчинга;
- отправляли эту выборку на толоку и получали ответ от людей: матч это или не матч;
- на основе результатов выставляли порог, выше которого считали предсказание модели верными;
- использовали полученные данные для всех последующих задач.
Теперь мы для каждого таска на матч собираем небольшую случайную выборку, которую отправляем на разметку в Яндекс.Толоку, и затем оцениваем её и получаем порог для конкретного задания на матчинг.
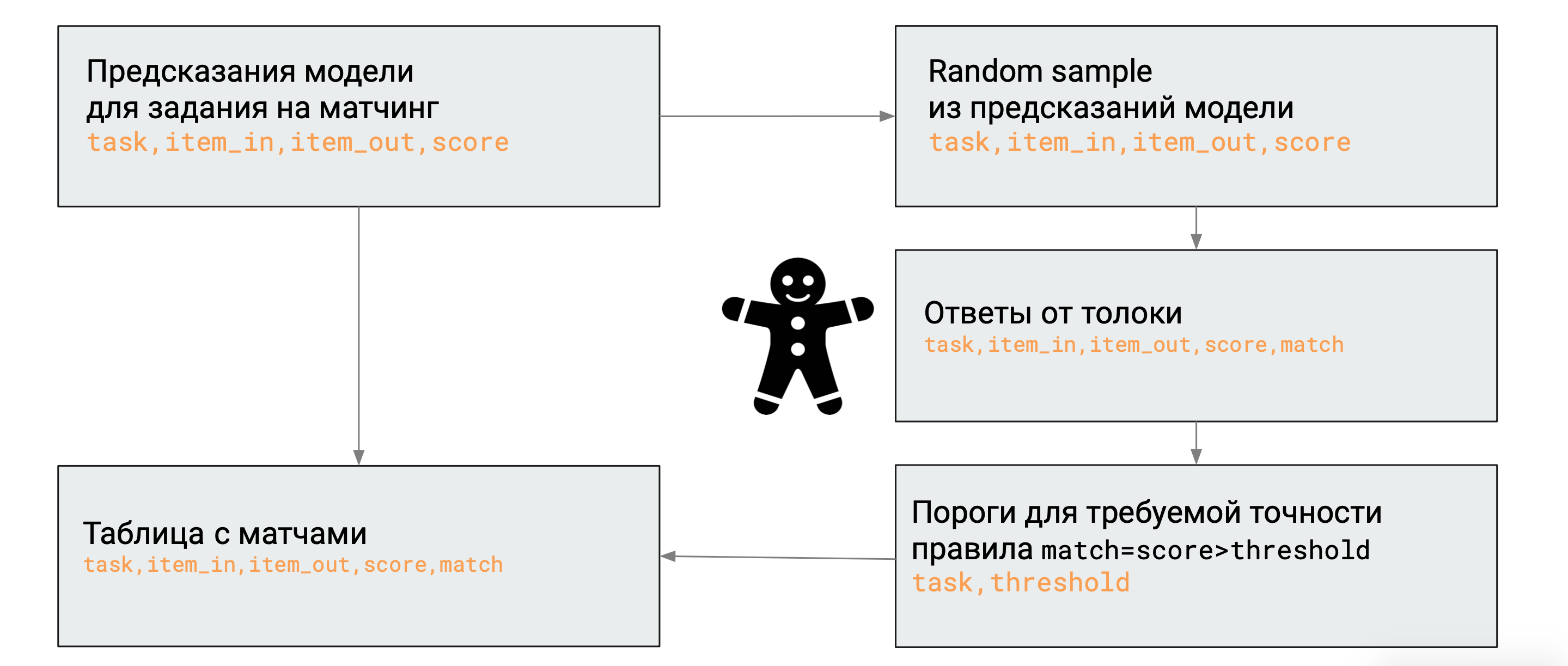
Так у нас выходит несмещённая оценка. Благодаря ей мы можем сказать, какие из матчей у нас более точные. Кроме того, мы:
- не зависим от флуктуации данных;
- можем поддерживать несколько разных моделей;
- сделали стандартизированный интерфейс взаимодействия с толокой, при помощи которого можем отправить товар на ручную разметку;
- получаем очень хороший hard negative samples для обучения наших моделей.
Матчинги товаров у нас автоматические, и мы можем на один товар, на один SKU, привозить несколько сравнений. И это не стоит дополнительных денег, в отличие от ручного сравнения товарных позиций. Наконец, мы можем настраивать точность в зависимости от той или иной задачи — в склеивании карточек товаров важна абсолютная точность, а для определения категории достаточно куда меньшей степени сходства.
Что в итоге?
Как выглядит наша модель.
Мы пропускаем картинки товаров «картиночную модель» и полученные эмбеддинги картинок складываем в базу. Затем ищем ближайших соседей и получаем, зная принадлежность картинки к тому или иному товару, кандидатов на матчинг.
Текстовая часть работает похожим образом. Мы считаем эмбеддинги по названиям, ищем ближайших соседей и складываем в базу. После чего берём наших кандидатов на матчинг и пропускаем через финальную модель, которая выдаёт score для матча. То есть мы можем сделать вывод, матч это или не матч.
Дальше перескоренные матчи поступают в суперматчинг, который выдаёт ответ с настраиваемой точностью, а также выдаёт hard negative samples для обучения моделей.

3К открытий4К показов
Продолжаем рассказывать о локализации глобальной платформы AliExpress России. В этой части поговорим о системах, которые мы написали с нуля.
Расскажем про организацию проекта, где задействованы несколько команд из разных стран и часовых поясов, на примере AliExpress Россия.
Рассказываем, как мы «от запроса до ответа» сделали свою систему рекомендаций, которая будет удобной для покупателей.
История про локализацию платформы AliExpress Россия. В первой части расскажем про Frontend, Backend и мобильные приложения