


Методы сжатия данных: алгоритмы и инструменты

Сжатие используется повсеместно. Оно нужно, чтобы обмениваться информацией в интернете, компактно сохранять фото и видео на телефоне, устанавливать АПК на Android и много для чего еще. В этой статье рассмотрим основные алгоритмы и инструменты для сжатия данных.
5К открытий10К показов
Классификация методов сжатия данных
Наверняка вы сталкивались с zip–архивами, сохраняли фото в jpeg или смотрели видео в 144p — всё это примеры сжатых данных. Когда мы говорим о сжатии (компрессии), то имеем в виду уменьшение исходного размера без потери содержимого. Так можно хранить больше информации, быстрее её передавать и считывать.
Методы сжатия данных принято делить на 2 категории: с потерей и без потери. Рассмотрим их подробнее.
Сжатие с потерями (lossy)
При сжатии данных с потерями мы безвозвратно удаляем часть информации. Но делаем это так, чтобы не потерять общую суть.
Например, надо сжать картинку для сайта, чтобы он быстрее прогружался. Ниже два варианта одного изображения. Один исходник, второй сжатый. Как думаете — какой где?


По идее исходник должен уступать оригиналу в визуальном плане, однако разницы между этими изображениями практически не видно.
Оригинал — первое изображение в формате png. Второе — сжатый вариант в формате jpeg.
Казалось бы, вариант 2 должен был потерять качество, и это произошло. При компрессии были удалены некоторые похожие оттенки цветов и лишние детали, а размер файла уменьшился с 2.38МБ до 145 КБ. При этом визуально он все еще выглядит неплохо.
То же самое происходит и при работе с аудио и видео. В файле могут содержаться звуки, которые не воспринимает человеческое ухо, статичные элементы, которые не изменяются от кадра к кадру. Всё это излишки, которые можно отбросить без потери смысла.
Сжатие данных без потерь (lossless)
При методах сжатия без потерь мы не удаляем лишние данные, а стараемся упаковать их более компактно.
Допустим, нам нужно составить список покупок. Мы можем записать его так:
Однако некоторые продукты повторяются здесь несколько раз, поэтому эту запись можно сделать более компактной вот так:
Популярные алгоритмы сжатия данных без потерь
Давайте рассмотрим три наиболее распространенных метода сжатия без потерь.
Huffman coding
Метод Хаффмана позволяет нам компактно закодировать данные при помощи манипуляций с частотой объектов и выстраивания дерева. А еще его включают в себя многие другие алгоритмы и форматы сжатия.
Рассмотрим пошагово кодирование Хаффмана на примере сжатия слова: «compression».
Шаг 1 — строим таблицу частотности
Определяем, сколько раз тот или иной символ встречался в тексте. Записываем символы в таблицу в порядке убывания. Под ними указываем частоту.

Шаг 2 — строим дерево
Записываем символы как листья дерева. Их частотность будет весом.

Находим два крайних правых листа и строим над ними новый. Записываем в него символы и сумму их частот.
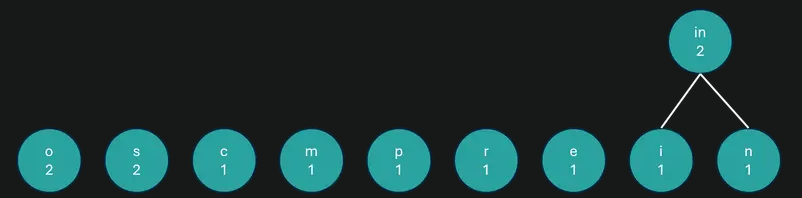
Мы создали лист «in» с весом 2. Формируем листы дальше.

Теперь мы построили лист «ein» с весом 3 из «in» и «e». Продолжаем до тех пор, пока не создадим последний лист.
Шаг 3 — кодируем текст
Мы закончили строить дерево. Теперь можно приступить к кодированию знаков.

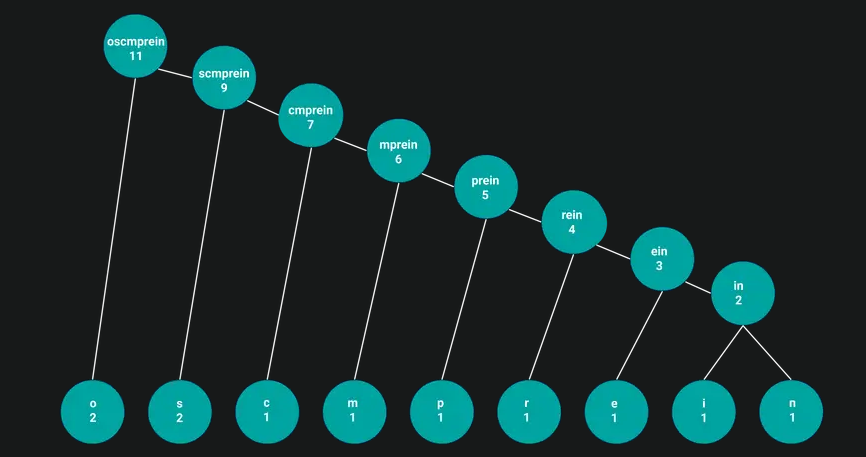
Вершина «oscmprein» является корнем нашего дерева, так как обладает наибольшим весом — 11.
Каждая линия означает один бит. Для линий справа это единица, слева — ноль. Теперь при помощи битов линий мы кодируем каждый символ. Для этого необходимо представить путь от корня до нужного знака. Сочетание битов линий на пути будет нашим кодом.
Например, между «o» и корнем «oscmprein» есть только одно ребро, которое равно нулю. Следовательно, «o» это 0. От корня до «s» ведут две линии: один и ноль. Значит, код будет 10. И так до узла «n», код которого 11111111.
В итоге получим следующую кодировку символов:

В изначальном варианте «compression» весит 88 бит, но благодаря методу Хаффмана мы сжали его до 48 бит.
Lempel-Ziv-Welch (LZW)
Метод Лемпеля создает словарь, где кодирует символы, слова и сочетания слов. Давайте рассмотрим принцип работы данного алгоритма на примере текста: «The big big big cat sat on the mat mat mat. The big big cat ate the fat fat rat. The cat cat cat sat sat sat.»
Шаг 1 — создаем словарь
Начнем с создания словаря, содержащего все возможные одиночные символы и их коды. В нашем случае мы будем использовать ASCII-коды для простоты:
Шаг 2 — сжимаем текст и расширяем словарь
Теперь будем читать каждый символ из фразы. Если он уже есть в словаре, то считаем комбинацию символов:
- Читаем «T». Проверяем его в словаре. Записываем код (84).
- Проверяем его сочетание со следующим символом. «Th» нет в словаре.
- Присваиваем для «Th» код 256.
- Читаем «h». Есть в словаре, пишем код (104).
- Проверяем «he». Этого сочетания нет в словаре.
- Присваиваем код 257.
Продолжаем этот процесс для всей фразы. Как только данный метод наткнется на комбинацию знаков, которая уже есть в словаре, он заменит её кодом. Не каждый знак по отдельности, а всё сочетание.
Например, слово «big» повторяется пять раз. Первое повторение мы закодируем по коду символов «b», «i», «g»: 98 105 103.
Так как в словаре нет сочетаний «bi» и «ig», присвоим им новые коды и добавим в словарь:
При следующем повторении мы закодируем «big» как 260 261, а не 98 105 103.
В итоге получим вот такой код:
Исходная фраза весила 73 байта, но мы сжали её до 53 байт.
Deflate
На самом деле с этим алгоритмом мы уже сталкивались. Ну, почти. Он основан на двух методах сжатия без потерь: LZ77 и коде Хаффмана. LZ77 — более старая версия LZW. Они отличаются только тем, что LZ77 не создает словарь с кодами — вместо этого он использует ссылки. Для примера возьмем текст: «The big big big cat sat on the mat mat mat».
Шаг 1 — определяем повторяющиеся подстроки
Это будут:
- big;
- cat;
- mat.
Шаг 2 — создаем ссылки
Ссылки записываем в следующем формате:
Например, буква «b» в слове «big» является пятым по порядку символом, если смотреть относительно всего текста. При счете с нуля её индекс — 4. Слово состоит из трех букв. Поэтому наша ссылка выглядит так:
Аналогично с cat (16,3) и mat (31,3).
Шаг 3 — сжимаем текст
Последовательно записываем наш текст, заменяя повторения ссылками:
Шаг 4 — применяем метод Хаффмана
Далее в дело вступает сжатие данных методом Хаффмана. По вышеописанному принципу мы разбиваем этот код на отдельные знаки, ранжируем их по частотности, строим дерево и кодируем каждый символ.
Алгоритмы сжатия с потерями
JPEG (для изображений)
Сжатие данных исходного изображения в jpeg происходит в четыре этапа.
Этап 1 — переводим в цветовое пространство YCbCr
YCbCr — цветовой профиль, который условно можно представить как три маски.
Y — чёрно-белая картинка, которая демонстрирует уровень яркости.

Cb — синий канал.

Cr — красный канал.

Так мы сможем отделить цвета от яркости.
Если что, отсутствие синих и красных оттенков нормально, потому что каналы Cb и Cr не представляют напрямую синий и красный цвета. Они показывают отклонения от нейтрального серого в сторону сине-желтого (Cb) и красно-зеленого (Cr) спектров.
Этап 2 — Дискретное косинусное преобразование (DCT)
На этом этапе нужно понять, как много деталей содержится в разных частях изображения. Для этого делим картинку на блоки 8 на 8 пикселей. Далее раскладываем каждый блок на паттерны при помощи дискретного косинусного преобразования. Паттерны — это пространственные волны, которые мы можем представить в виде 64 картинок.

Комбинируя их, можно повторить любое изображение 8x8 пикселей.
У каждого паттерна есть свой вес, который можно менять — его называют коэффициентом. DCT определяет, на какие паттерны с какими коэффициентами можно разложить блок.

Этап 3 — Квантование
Есть объекты, которые человеческий глаз не видит, либо почти не видит, поэтому некоторые детали на фото не нужны. Найти их помогает таблица квантования. В ней прописаны значения коэффициентов, по которым становится понятно, важны детали на блоке или нет. При помощи этих значений мы округляем коэффициенты паттернов до целых чисел. Если они близки или равны нулю, то содержат минимум важных деталей. Последовательности нулей удаляем, и вместо них записываем в скобках один ноль и число его повторений.
Этап 4 — сжатие Хаффмана
Да-да. Здесь опять вступает в игру метод сжатия Хаффмана, который сжимает нашу последовательность еще сильнее.
MP3 и ACC (для аудио)
MP3 и ACC — это два формата компрессии аудио с потерями. Сжатие в них работает аналогично сжатию в jpeg.
Этап 1 — раскладываем звук на волны
Мы раскладываем звук на несколько кусочков — фреймов. Эти фреймы разделяем на волны.
Этап 2 — находим у волн лишние частоты
У каждой волны есть своя частота. Некоторые частоты человек не воспринимает, поэтому MP3 использует психоакустическую модель. Она удаляет такие частоты, а еще заменяет похожие волны одной.
ACC использует более свежую и, потому, совершенную версию психоакустической модели, благодаря чему точнее определяет излишние частоты.
Этап 3 — округляем коэффициенты частот
Далее начинается квантование. Мы округляем коэффициенты частот. Те, что слышим хуже, получают меньше битов, и наоборот.
Если последовательность частот равна нулю, то удаляем нули и заменяем их записью по типу:
(0, количество повторений). Точно как с jpeg.
Этап 4 — пропускаем через алгоритм Хаффмана
В конце получаем последовательность битов, которые означают коэффициенты частот. Проводим сжатие данных алгоритмом Хаффмана.
H.264 и HEVC (для видео)
H.264 и HEVC — это стандарты видео сжатия. Еще их называют кодеки. Вот основные этапы сжатия видео:
Этап 1 — разбиение на кадры и блоки
Разбиваем видео на кадры. Каждый кадр раскладываем на блоки:
- 16x16 пикселей в H264.
- 64x64 в HEVC (H.265).
Благодаря этим небольшим блокам мы можем отслеживать изменения в кадрах.
Этап 2 — формируем I,P,B-кадры
Далее мы сравниваем последовательности блоков кадров между собой. Если видим смещения, то создаем векторы, в которые записываем информацию о направлении смещений и их длине в пикселях.
Этим методом формируем три категории кадров:
- I-кадры (intra-coded frames) — это опорные кадры, которые кодируются без учета других кадров. Они содержат полную информацию о текущем изображении и служат отправной точкой для декодирования других кадров. Такие кадры наиболее «тяжелые» по объему, но необходимы для восстановления видео.
- P-кадры (predictive frames) основываются на предыдущих I- или P-кадрах. В них кодируется только информация о различиях между текущим кадром и предыдущим, что значительно сокращает объем данных.
- B-кадры (bi-predictive frames) используют как предыдущие, так и последующие кадры для предсказания текущего кадра. Это делает их наиболее эффективно сжимаемыми, поскольку они могут использовать информацию из двух направлений — как вперед, так и назад. Однако их обработка требует больше вычислительных ресурсов.
P и B кадры — это не статичные изображения, а всего лишь информация о том, какая часть кадра изменилась, в каком направлении и как.
Представим последовательность кадров:
В I-кадре статичная картинка. В первом P-кадре мы повторяем предыдущий I-кадр и благодаря информации о смещении дорисовываем его часть. То же самое проделываем со вторым P-кадром относительно первого P-кадра.
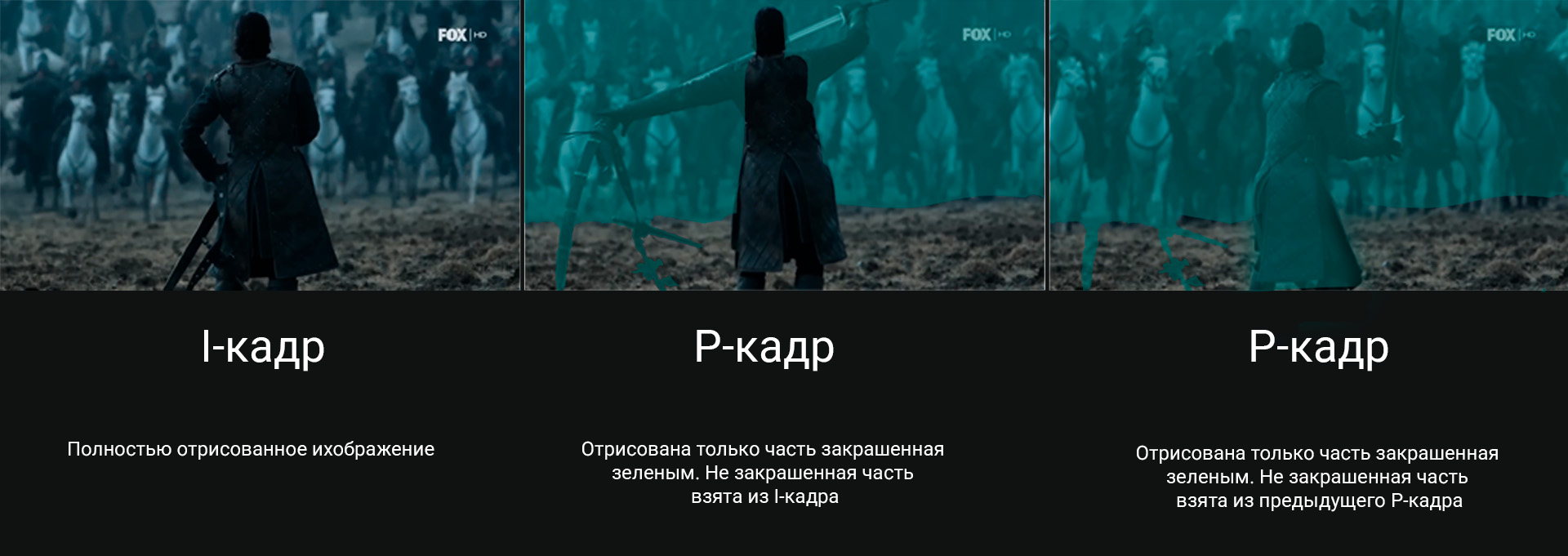
Таким образом, мы как бы изучаем все кадры, создаем болванку и дублируем её в следующих кадрах, дорисовывая некоторые фрагменты.
Этап 3 — выводим коэффициенты
Далее работаем с кадрами так же, как с jpeg. Прогоняем через дискретное косинусное преобразование и выводим коэффициенты деталей.
Этап 4 — округляем, убираем излишки и кодируем по Хаффману
Округляем их при помощи квантования, сокращаем коэффициенты близкие или равные нулю и используем метод сжатия Хаффмана.
Инструменты для сжатия данных
ZIP и GZIP
ZIP и GZIP — это утилиты для архивирования файлов. Они уменьшают размер данных без потери информации.
- ZIP использует алгоритмы из метода Deflate, который мы рассматривали выше. Преимущества ZIP в том, что он поддерживается практически на всех операционных системах и способен сжимать несколько файлов.
- GZIP используется на серверах для уменьшения объёма данных, передаваемых по сети. GZIP также основан на алгоритме Deflate, но в нем нет реализации методов сжатия многокомпонентных архивов. Это значит, что он не умеет сжимать несколько файлов.
FFmpeg
FFmpeg — фреймворк, который применяется для сжатия, конвертации и обработки медиафайлов.
FFmpeg поддерживает широкий набор кодеков и форматов, включая H.264, H.265 для видео и AAC, MP3 для аудио.
Но его возможности не ограничиваются только сжатием. По сути, это движок с инструментами для редактирования медиафайлов. Здесь мы можем сделать нарезку, применить фильтры, конвертировать в другие форматы и много чего еще.
7-Zip
7-Zip — бесплатная утилита для сжатия данных, которая поддерживает формат 7z, а еще там есть ZIP, RAR, и TAR.
Основное преимущество 7-Zip в его высоком уровне сжатия. Здесь применяется метод сжатия LZMA. Это модифицированная версия LZ77.
LZMA, так же как и LZ77, ищет повторяющиеся последовательности и заменяет их ссылками. Но еще он использует метод Маркова для предсказания вероятности появления символов.
7-Zip также поддерживает создание защищённых паролем архивов с шифрованием и работает на большинстве платформ, включая Windows и Linux.
Преимущества и недостатки различных методов сжатия
Баланс между эффективностью сжатия, скоростью и качеством данных
Сжатие без потерь
Лучше всего подходит для текстов, программного кода, баз данных и других типов данных, где принципиально важно сохранить всю информацию. При этом приходится мириться с ограниченным уровнем сжатия, особенно если мы используем данные, где мало повторяющихся элементов. Это может быть критично при работе с медиафайлами.
Поэтому методы сжатия данных без потерь лучше применять, когда сохранение качества данных важнее эффективности сжатия и скорости.
Сжатие с потерями
Позволяет достичь значительно большего уменьшения размера файлов за счёт удаления излишков данных, таких как мелкие детали изображения или неслышимые частоты в аудио.
Подходит только для данных, где не критично потерять часть информации. При этом стоит иметь в виду, что алгоритмы сжатия с потерями могут сильно убить качество, если использовать высокую степень сжатия.
Методы сжатия с потерями уместны когда для нас важнее скорость и компактность, чем изначальное качество.
Как выбрать метод сжатия данных
Выбор способа сжатия данных зависит от задачи.
Для хранения архивов
Zip, 7-zip или RAR-архивы станут отличными инструментами, если нам нужно просто сохранить набор файлов на компьютере.
Они умеют компрессировать сразу несколько файлов при помощи методов сжатия без потери данных.
Для сжатия веб-сайтов
Для оптимизации сайта подойдет формат gzip. Он умеет сжимать html и css без потерь, благодаря чему веб-страницы быстрее прогружаются.
Для изображений
Когда мы делаем снимки на смартфон для соцсетей, JPEG формат будет оптимальным выбором, поскольку сохраняет баланс между качеством и размером файла.
Но если мы увлекаемся профессиональной фотографией, то стоит выбрать RAW формат — он содержит максимум данных, которые нужны для обработки.
Для видео
Для любительской съемки и просмотра видео подойдет Кодек H264. Но если мы занимаемся видеопроизводством профессионально, то для редактирования нам подойдут форматы вроде ProRes. А финальную версию можно сохранить в H.265 (HEVC).
Для аудио
Чтобы послушать музыку на смартфоне или в машине, нам хватит MP3 или ACC формата. Но для аудиофилов и тех, кто занимается музыкой профессионально, подойдет формат без потери данных FLAC.
А с какими методами сжатия работаете вы? Расскажите в комментариях👇

5К открытий10К показов

21-летний основатель Pilgrim вскрыл себе ногу ради теста повязки Kingsfoil — видео помогло привлечь \$4,3 млн инвестиций в стартап

Старый ftape-драйвер для QIC-лент, удалённый из Linux в 2006 году, ожил в ядре 6.8: разработчик с помощью Claude Code адаптировал код под современные API

ТОП ИИ для программистов в 2025 году. Показываем основные виды нейросетей для программирования. Рассматриваем основные плюсы и минусы каждого AI ✔ Tproger

Топ-10 способов заработать на искусственном интеллекте. Как ИИ может приносить прибыль бизнесу и специалистам.