


Миграции баз данных с помощью библиотеки Liquibase

46К открытий63К показов

Артем Зубченко
Java-разработчик IT-компании MediaSoft
Что такое миграции баз данных, когда и на каких проектах их настраивают, как они работают, — рассказываем в материале. А также по шагам разбираем, как настроить миграции с помощью открытой библиотеки Liquibase.
Миграции баз данных — что это такое и для чего нужно
Миграция баз данных — это что-то вроде системы контроля версий для вашей схемы базы данных. Она позволяет разработчикам изменять структуру БД, сообщать другим участникам команды об этих изменениям и самим быть в курсе апдейтов, а также отслеживать историю изменений.
Зачем нужны миграции БД и как они упрощают жизнь разработчикам
- По мере разработки приложения схема базы данных меняется. Добавляются новые таблицы и столбцы. Миграции позволяют упростить отслеживание этих изменений.
- У современных проектов зачастую есть несколько стендов — стенд разработки, тестирования, прод и другие. Возникает проблема синхронизации базы данных — нужно передавать изменения на стенды последовательно и без конфликтов. Миграции помогают решить эту проблему.
- Современные проекты работают по методологии Agile, а в ней сложно определить структуру БД на старте. Она развивается вместе с проектом от спринта к спринту. Поэтому автоматизированный рефакторинг БД должен быть таким же обязательным инструментом, как и рефакторинг любых других компонентов.
- Поскольку миграции являются частью исходного кода проекта, изменение структуры БД могут быть одобрены или отклонены во время код ревью до того, как они попадут в релизную ветку.
Чаще всего для настройки миграций БД в Java-приложениях используют инструменты Liquibase или Flyway. Они оба написаны на Java, легко интегрируются с maven, gradle и другими инструментами сборки, что способствует большей кастомизации. Предлагают Java API и могут быть расширены. Основное отличие между ними — это форматы, в которых инструмент записывает изменения. Flyway использует только SQL, а Liquibase работает также с XML, YAML или JSON.
Как работают миграции
- Изменения, которые разработчик вносит в схему базы данных, записываются в текстовых файлах конфигураций, понятных Liquibase или Flyway. Эти изменения преобразуются в SQL-запросы, с которыми инструмент обращается к БД и вносит необходимые изменения.
- Все изменения, которые мы вносим, хранятся в отдельных файлах. Часто их называют чейнджлогами.
- В файлах-чейнджлогах изменения представляются в виде чейнджсетов, так называемых точек сохранения. Чейнджсет может хранить одно или несколько изменений базы данных. Каждый чейнджсет уникально идентифицируется.
- При первом запуске миграции Liquibase или Flyway создает таблицу в схеме базы данных для отслеживания примененных чейнджсетов и дальше работает с ней автоматически. Если изменение уже применялось, повторного выполнения не будет.
Библиотека Liquibase: что это такое и для каких проектов подходит
Liquibase — это открытая независимая от БД библиотека для отслеживания, управления и применения изменений схемы базы данных. Поддерживает подавляющее большинство БД, включая PostgreSQL, MySQL, Oracle, Sybase, HSQL, Apache Derby. Работает с форматами XML, YAML, JSON, SQL.
Ее преимущества: библиотека Liquibase предоставляет больше возможностей из «коробки» в отличие от того же Flyway — отмена изменений, автогенерация миграций. Имеет dry-run, то есть можно посмотреть, какие SQL-запросы будут выполнены.
В отличие от Flyway, которая поддерживает скрипты миграции только в форматах SQL и Java, Liquibase — это универсальный инструмент. Он позволяет накатывать одни и те же миграции на любые базы данных и абстрагироваться от SQL. Эта библиотека больше подходит для проектов, где необходимо работать с разными окружениями и СУБД.
Liquibase не стоит использовать, если ваш проект имеет простую структуру базы данных. А также если вам нужна возможность изменять схему БД с помощью полностью кастомного SQL или с использованием Java-кода. В таком случае удобнее обратиться к Flyway.
Настраиваем миграцию с помощью Liquibase
Как настроить миграцию уже готовой базы данных
- Подключаем библиотеку Liquibase, то есть добавить зависимость в вашем проекте.
- Пишем нулевой вариант базы данных, то есть описываем скриптами ту БД, которая уже развернута.
- Все последующие изменения в структуре БД вносим только через скрипты.
Как создать миграцию для новой базы данных
Первый шаг. Для работы с библиотекой нам нужно добавить зависимость в файл pom.xml. Ссылка на зависимость тут. Ниже пример, как это сделать.
Шаг второй. Теперь нужно создать сам скрипт Liquibase. Как уже говорили, для работы можно использовать форматы XML, YAML, JSON или SQL. Мы будем использовать XML как наиболее наглядный. Его преимущества в том, что он позволяет автоматически подставлять названия тегов и атрибутов в файле.
В начале создаем главный запускаемый файл changelog.xml, в который мы будем добавлять пути к скриптам. В changelog.xml вставляем стандартный пустой шаблон по пути: src/main/resources/db/changelog/changelog.xml. Позже мы его дополним.
Шаг третий. Теперь напишем скрипты для создания таблиц. За основу возьмем схему базы данных ниже.
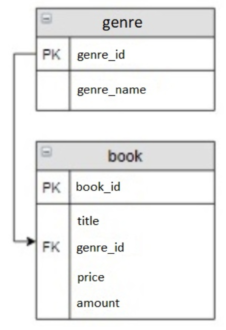
Описываем чейнджсет для создания таблицы genre. Для этого создаем файл по пути: src/main/resources/db/changelog/create-changeset-genre-table.xml. Пример ниже.
Напомним, что чейнджсет — это что-то вроде аналога коммита в системах контроля версий. Он может содержать одно или несколько изменений базы данных. Хорошей практикой считается одно изменение для одного чейнджсета — это может быть создание или изменение таблицы, удаление объекта, добавление индекса или данных в таблицу. Каждый чейнджсет обязательно должен иметь два идентификатора: уникальный id и author. Остальные теги можно посмотреть на официальном сайте.
Теперь занесем в таблицу genre данные с помощью тега insert. Для этого создадим новый файл по пути src/main/resources/db/changelog/insert-changeset-genre-table.xml и добавим новый чейнджсет:
Далее создаем чейнджсет для добавления таблицы book по пути: src/main/resources/db/changelog/create-changeset-book-table.xml.
Шаг четвертый. Теперь нам нужно связать наши таблицы. Для этого описываем создание внешнего ключа в changeset-genre-table.xml:
Шаг пятый. Теперь пропишем скрипт для заполнения таблицы book. Создаем новый файл по пути: src/main/resources/db/changelog/insert-changeset-book-table.xml
Воспользуемся возможностями Liquibase и проверим чейнджсет перед его выполнением на соблюдение условия, есть ли в таблице genre нужный нам жанр.
Для этого мы объявляем тег preConditions. В этом теге указываем результат проверки — он записывается в параметре expectedResult. При проверке мы будем использовать SQL, для этого объявляем тег sqlCheck.
Шаг шестой. Теперь в наш корневой файл changelog.xml импортируем наши миграции:
Важный момент: сначала создайте таблицу, к которой будете привязывать, а уже потом привязываемую. Иначе Liquibase не поймет, что с чем нужно связывать и выдаст ошибку. В нашем случае мы сначала создаем genre, а уже потом book с его внешним ключом.
Шаг седьмой. Теперь запускаем наш проект. Liquibase использует наши скрипты и создаст все таблицы. В итоге должно получиться так:

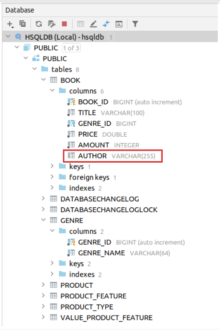
Шаг восьмой. Теперь добавим поле author в уже созданную таблицу book. Для этого нам нужно в changeset-book-table.xml добавить новый чейнжсет и использовать тег addcolumn.
Категорически нельзя менять и добавлять что-то в существующий чейнджсет, который попал в общую ветку в системе контроля версий. Скорее всего этот чейнджсет уже выполнился на одном из стендов, и его контрольная сумма попала в таблицу databaseChangelog. После изменения чейнджсета его контрольная сумма изменится. А Liquibase при ее проверке выдаст ошибку. Поэтому, если необходимо внести изменения в объекты, созданные в старых чейнджсетах, создавайте новый.
После запуска проекта мы увидим, что в нашу таблицу добавилось новое поле author.
Шаг девятый. Теперь, когда мы разобрались с запуском Liquibase, можем переходить к откату изменений.
Многие операции Liquibase может откатить самостоятельно, например, создание таблицы и добавление колонки. Для некоторых чейнджсетов необходимо написать скрипты отката. Мы будем использовать автоматический откат изменений. Остальные способы описаны на официальном сайте Liquibase. Важно понимать, что откат изменений приводит к потере данных.
Мы будем использовать откат по тегу, так как это самый удобный и простой способ. В данном случае, тег — это своего рода чекпоинт, по которому Liquibase определяет, что этот чейнджсет был последним в рамках наших изменений. К этой контрольной точке можно вернуться в любой момент, если мы что-то сделаем не так.
Чтобы установить тег, выполним команду в терминале:
Тег всегда устанавливается на последнем чейнджсете. Теперь если мы посмотрим в таблицу databaseChangelog, увидим, что к последнему чейнджсету привязался tag_1, к которому мы сможем откатиться при необходимости.

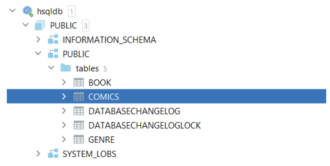
Проверим работу тега. Для этого создаем новый чейнджсет на создание таблицы comics по пути src/main/resources/db/changelog/create-changeset-comics-table.xml. Заполним этот файл:
Добавим наш новый файл в changelog.xml, запустим его и убедимся, что таблица добавилась в базу данных.

Теперь, если мы захотим удалить таблицу comics, нам необходимо выполнить эту команду в терминале, указав в конце команды наш тег:
После выполнения команды мы увидим, что таблица вернулась к первоначальному состоянию.

Ещё несколько советов по работе с Liquibase
Используйте XML, а не YAML или JSON
XML дает возможность автодополнения в IDE и автоматически проверяет формальную верность документа по схеме данных. Так что при написании лучше использовать XML, а к остальным форматам обращаться, если вы хотите быстро проверить миграцию.
Не используйте автоматическую генерацию Liquibase
Liquibase умеет сам генерировать чейнджсеты, на основе существующей базы данных, и показать изменения, произошедшие в БД по сравнению с имеющимися чейнджсетам. К этим удобствам надо относиться с осторожностью. Да, они позволяют избавить от рутины, но даже в этом случае все чейнджсеты надо просматривать и проверять. Вы ведь не хотите исправлять логическую ошибку, сгенерированную утилитой и уехавшую в прод, правда?
Лучше много маленьких чейнджсетов, чем один большой
Один чейнджсет — одна атомарная операция. Если происходит много изменений, лучше, чтобы операции были поменьше. Для каждой маленькой операции мы можем написать свою отдельную проверку. Такое изменение будет проще откатить и не затронуть остальные. А также оно будет проще для понимания другому разработчику в команде.
Работайте над операциями изолированно, не добавляйте без необходимости несколько изменений в один чейнджсет, думайте над содержимым тега rollback. Лучше много простых и даже однотипных чейнджсетов, чем один сложный и невнятный.
Скрипты
Хорошей практикой является хранение скриптов для каждой таблицы отдельно с последующим включением в корневой файл, который будет их запускать. Как и в SQL здесь важен порядок написания запросов, так как они запускаются друг за другом.
По ссылке оставили официальный гайд с лучшими практиками использования Liquibase.

46К открытий63К показов

В статье разбираемся, почему Django — далеко не финиш в карьере, и в каких направлениях можно двигаться Python-разработчику.

Когда прочитаете эту статью, сможете настроить типобезопасную навигацию в своем проекте, забудете про сломанные ссылки после рефакторинга и перестанете нервничать на релизах.

Иван Некулицы, основатель PQ.Hosting, рассказывает, как организовать переезд на другой хостинг без рисков и простоев.

Подходы для раскрашивания: от наиболее примитивных до самых передовых. Рассмотрим их ближе, а также имплементируем одну готовую раскраску в телеграмм бот.