


MLup: как создавать веб-приложение с машинными обучением за один взмах волшебной палочки - конкурс пет-проектов
Написал библиотеку на Python , которая позволяет создавать и запускать приложения с любой моделью машинного обучения.
2К открытий10К показов

Я с самого начала своего пути в IT полюбил machine learning (машинное обучение). И мой пет-проект связан с этим. Я сделал небольшой фреймворк, который позволяет создавать и запускать веб-приложение с любой моделью машинного обучения без необходимости привлекать программиста.
Тут написано совсем чуть-чуть про машинное обучение
Сегодня уже многие слышали, что такое нейросеть. Если вы знаете, что такое модель машинного обучения и как ее можно запустить, тогда смело пропускайте этот раздел.
Модель машинного обучения — это алгоритм, у которого есть параметры и состояние. Если провести аналогию с программированием, то модель можно назвать экземпляром класса.
Обучить модель — значит настроить ее параметры, показать ей данные для обучения и изменить ее внутреннее состояние. Если в терминах программирования это – создать экземпляр класса с аргументами и через метод «обучить» сунуть в него данные для обучения.
Использовать обученную модель — значит показать ей данные и попросить по ним какой-то ответ.
Для переноса модели на сервера недостаточно перенести код модели, нужно еще перенести параметры и ее внутреннее состояние. Для этого разработчики уже придумали кучу способов и форматов сохранения обученной модели машинного обучения: pickle, joblib, onnx, etc. Все они сводятся к сохранению параметров и состояния модели в файл и загрузку из этого файла на сервере.
Про проблему веб-приложений с машинным обучением
Модель – это какой-то исполняемый код, которому можно отдать данные в определенном формате (подать на вход) и получить ответ (получить выход). Как правило, это массивы чисел: массивы numpy, тензоры, спарс-массивы и другие.
Пользователям вашей модели недостаточно знания о том, какой массив им нужно отдать вашей модели машинного обучения. Им нужен интерфейс взаимодействия с ней: сайт, телеграм-бот, мобильное приложение.
В больших компаниях есть ресурсы для создания таких интерфейсов, их оптимизации и поддержки. Но также есть много небольших компаний и просто исследователей, которым нужно создавать этот интерфейс самостоятельно. Мой пет-проект должен, если не избавить, то сильно упростить этот процесс.
Библиотека, про которую я пишу, создает веб-приложение с API для модели машинного обучения. Я назвал ее mlup. Чтобы запустить ваше веб-приложение, нужна только модель.
В связи с тем, что основные ЯП в машинном обучении — Python и C++, я написал библиотеку на Python. Хочу в будущем сделать реализацию на С++. Название mlup было уже занято в pypi, поэтому я загрузил библиотеку под названием pymlup.
Установить библиотеку на Python можно через pip: pip install pymlup.
Про решение
Как пользоваться
Самый простой вариант — запустить веб-приложение со всеми стандартными настройками:
Эта команда создаст и запустит сервис c API, в котором можно вызывать предсказание вашей модели. Сам сервис запустится на 8009 порту. Вы можете открыть документацию API и потестировать ваш сервис в ней по адресу http://localhost:8009/docs.
Вы можете написать свой конфигурационный файл в yaml/json формате и запускать из него:
Или сгенерировать код веб-приложения в Python-файл. Созданное приложение можно дорабатывать собственным кодом и запускать любым удобным способом:
Также можно использовать все возможности из кода, импортируя библиотеку mlup и создавая объект mlup.UP.
EmptyModel ничего не возвращает, когда ее просишь что-то предсказать. Это просто заглушка, которая используется для внутренних целей и для пустой инициализации.
Каждая модель машинного обучения занимает какой-то объем памяти, поэтому ее загрузка в память должна быть явной. А без загрузки модели в память невозможен ее анализ и создание веб-приложения. Когда вы создаете объект mlup.UP, ничего в память не грузится. Для загрузки модели и ее анализа нужно вызывать метод up.ml.load().
Код up.run_web_app(daemon=True) запускает веб-приложение. Под капотом используется FastAPI.
Архитектуры веб-приложения
На момент написания статьи, в mlup есть три архитектуры веб-приложения:
- Прямое использование модели (directly_to_predict)
- Очередь и воркер (worker_and_queue)
- Батчинг данных из запросов (batching)
Архитектура веб-приложения: прямое использование модели
Самая простая и очевидная на первый взгляд архитектура. Для каждого запроса пользователя вызывается предсказание модели.
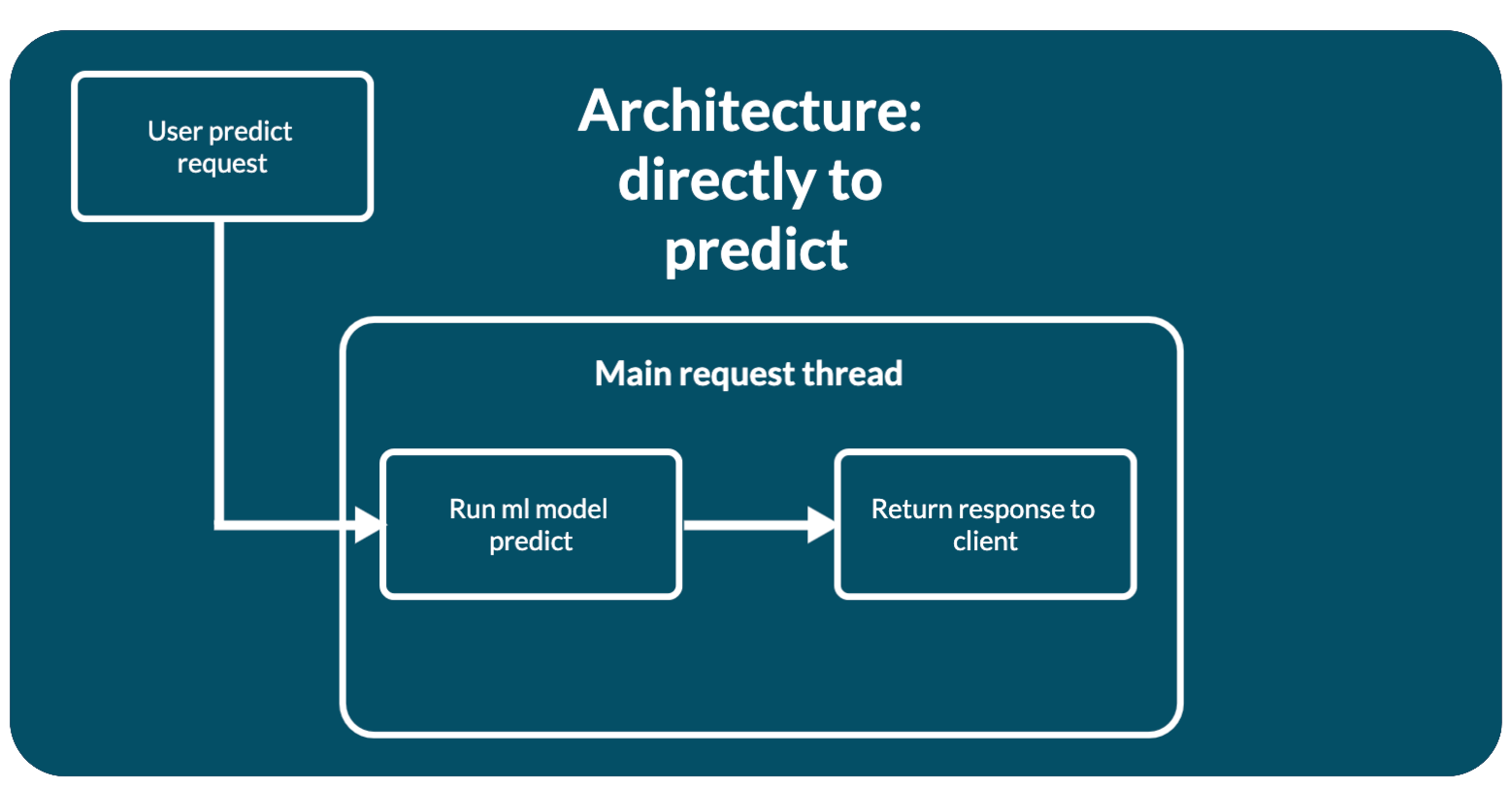
Модели машинного обучения, во время предсказания, выполняют CPU bound операции. Каждый запрос пользователя будет запускать предсказание модели независимо от других. Получается параллельные предсказания. В таком случае ресурсы потребляемые моделью будут множится для каждого запроса и могут закончится. Приложение зависнет.
Но эта архитектура самая быстрая для предсказания. Она подходит для случаев: когда у вас маленькая модель, быстрая модель, мало запросов к ней.
Архитектура: очередь и воркер
Когда у вас недостаточно ресурсов для запуска несколько параллельных предсказаний модели, вы можете обеспечить доступ к модели через очередь. Тогда ваша модель машинного обучения будет выполнять только 1 предсказание (CPU bound операцию) в момент времени. И все запросы пользователей будут обработаны в том порядке, в котором пришли.
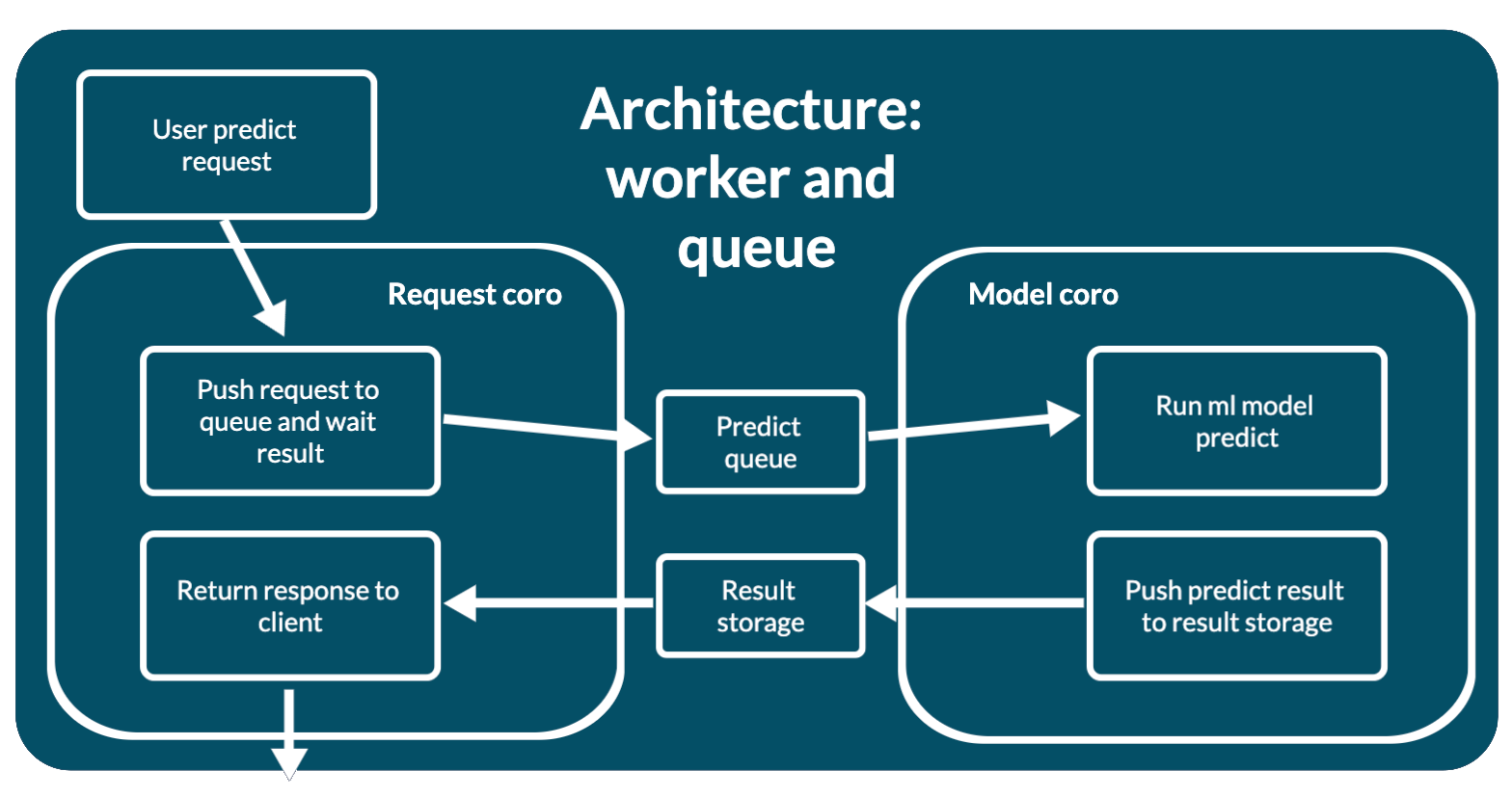
Эта архитектура поддерживает долгие предсказания (long predict) – когда ваша модель машинного обучения вычисляет ответ дольше, чем клиент может ждать. Клиент может отправить запрос на предсказание, получить в ответе predict_id (uuid) и вернутся за ответом позже.
Архитектура веб-приложения: батчинг данных из запросов
Доступ к модели через очередь не всегда бывает эффективным. Архитектура батчинга данных из запросов обеспечивает такой же доступ к модели через очередь, как архитектура очередь и воркер. Но в модель попадают на предсказание уже не один запрос в момент времени, а несколько.
Воркер с моделью читает очередь запросов, пока не наберет определенное число данных для предсказания (батч). Собранную пачку данных из нескольких запросов отправляет в модель, а результаты раскладывает в хранилище результатов по ключу predict_id. В случае mlup, все это происходит в памяти, без привлечения сторонних хранилищ.
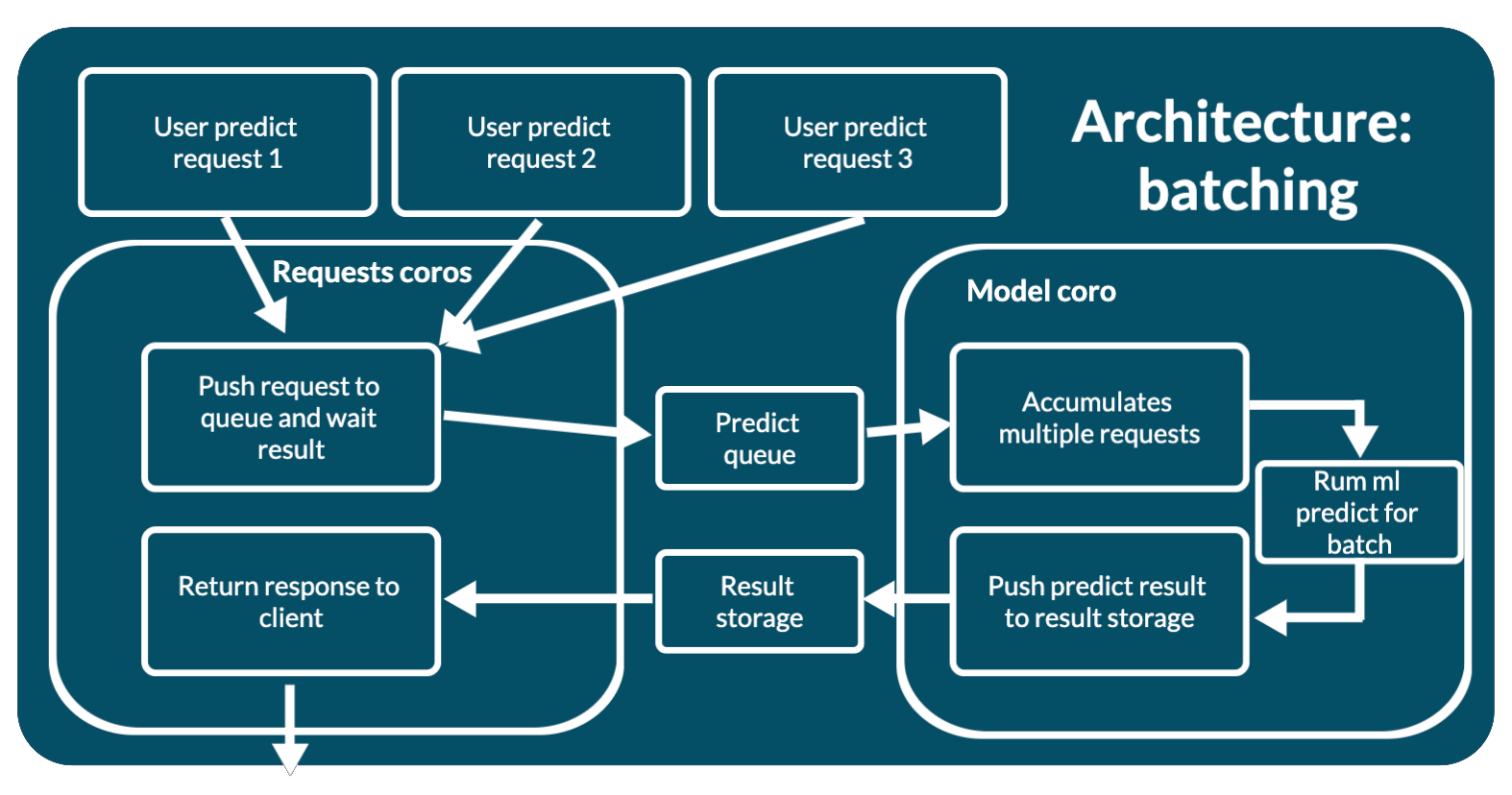
Эту архитектуру можно использовать, когда пропускная способность вашей модели машинного обучения предсказуема. Нет никакого смысла использовать архитектуру батчинга данных из запросов, если ваша модель может предсказывать одновременно только для маленького количества объектов.
Какую архитектуру выбирать, зависит от многих факторов: модели, ожидаемой нагрузки, количества ресурсов. Но эта тема заслуживает отдельной статьи.
Более подробно про весь процесс запуска и работы доступных архитектур веб-приложения написано в документации:
Кастомизация
Если стандартных алгоритмов mlup вам недостаточно, вы можете создавать свои. Все возможные кастомизации процесса загрузки и работы можно написать самостоятельно и подключать как модули. Например, вы можете реализовать собственную архитектуру веб-приложения с моделью и подключить ее в файле конфигурации, указав путь для импорта вашего кода.
Если API веб-интерфейс, созданный mlup, вам не подходит, вы можете создать любой другой интерфейс. Вам нужно просто загрузить вашу модель с помощью mlup и использовать ее. Обращаться к модели, как к черному ящику, через метод mlup.UP.predict, используя привычные Python-типы и не думая о внутренних преобразованиях данных в формат модели машинного обучения и ее работе.
Чтобы не дублировать документацию, не стану останавливаться на всех возможных вариантах использования фреймворка и всех конфигурациях. Про это подробно я написал в документации.
Про производство
Я написал десятки сервисов, в которых использовались модели машинного обучения. Это были как простые приложения с одной моделью, так и более сложные приложения, в которых модели были лишь кусочком бэкенда. И все они загружались и работали по одному сценарию:
- Загрузка модели в память.
- Инициализация модели и ресурсов под нее (GPU).
- Запуск интерфейса взаимодействия с моделью.
- Принятие запроса к модели от клиента.
- Преобразование данных от пользователя в формат модели.
- Вызов модели с преобразованными данными и ожидание ответа от нее.
- Преобразование ответа модели в формат понятный пользователю.
- Ответ пользователю.
В большинстве случаев мне приходилось создавать приложение для каждого сценария заново. Даже если они были однотипные и создавались через Ctrl+C, Ctrl+V. Однажды я захотел консолидировать создаваемые мной приложения в одно, работу которого можно настраивать.
Я планировал сделать MVP за месяц. Это было наивно! Впрочем, я же программист: проваливать дедлайны — часть моей профессии. По часику в день я за месяц собрал приложение с разными архитектурами. Начал создавать разные модели машинного обучения, чтобы протестировать мой код. И тут меня осенило! Data Science специалисты не любят использовать библиотеки для разных задач, которые можно импортировать в свои исследования. А также в 1–2 строчки кода решать свои проблемы: сделать красивый график из массивов данных, красивый прогресс бар для обучения, обучить модель машинного обучения и другие.
Я понял, что созданное мной приложение неудобное для использования. Для его использования нужно клонировать Github-репозиторий, что-то прописывать в конфигурационный файл, собирать докер. Это все сложно и не подходит для главной цели — упростить создание веб-приложения с моделью. Было решено: обернуть написанный сервис в библиотеку. И на это ушло еще пару месяцев. Еще месяц я писал документацию, все оформлял и заливал в интернет.
В итоге я получил фреймворк для создания любого интерфейса взаимодействия с моделью с собственной реализацией веб-приложения. Мне нравится, что получилось сделать взаимодействие с фреймворком удобным и привычным для всех ролей, участвующих в создании приложения с моделью машинного обучения:
- Для Data Science специалиста можно использовать как библиотеку. В том числе запускать веб-приложение, тестировать его и сохранять в файл проверенный конфиг для будущего приложения.
- Для программиста можно использовать из bash или прямо из кода. Можно брать созданное Data Science специалистом приложение с настройками для его модели и навешивать свою инфраструктуру.
- Для DevOps-специалиста — это привычная работа с конфигами приложений и bash-командами для запусков процессов и приложений.
Я очень надеюсь, что предлагаемый фреймворком mlup формат создания приложений будет удобным для всех участников этого процесса.
Какие планы
Я хочу добавить несколько модулей в коробку, поддерживающих популярные площадки по хранению моделей. Также улучшить валидацию входящих данных и доработать саму документацию.
Но самая желанная идея — добавить реализацию на C++, которая будет использовать тот же конфиг. Но не все модули из Python реализации можно реализовать в C++. Например, работу с Pickle моделями. Но если вам нужно C++ приложение с моделью машинного обучения, значит вы, скорее всего, знаете, что делаете, и можете сохранить вашу модель в нужном формате.
Спасибо, что дочитали эту статью до конца. Буду рад любой обратной связи, особенно на GitHub.
Ссылки
- Github — https://github.com/nxexox/pymlup
- Документация — https://mlup.org

2К открытий10К показов

22 апреля пройдет конференция Газпромбанк.Тех для разработчиков и инженеров.
Приложение для подсчета калорий Cal AI, разработанное тинейджерами из США, скачали более 5 млн раз — оно принесло ребятам более миллиона долларов.

OpenAI выпустила модели o3 и o4-mini с улучшенным reasoning — точнее решают задачи, пишут код и используют внешние инструменты через API

Самые лучшие курсы по чат-ботами. В предложенной подборке актуальные варианты обучения от проверенных школ, а так же рейтинги и цены на курсы по разработке чат-ботов