


Мой pet-проект: исследование рынка ИТ-работодателей в Ростовской области

Рассказ о проекте, на котором можно ознакомиться с результатами опроса местного сообщества об IT-компаниях.
1К открытий1К показов

Вадим Мартынов
руководитель офиса разработки «Контура» в Ростове
Не звучит, как фан-проект, да? Вообще, в свободное время я делаю митапы, конференции и просто посиделки местной ИТ-тусовки. И как-то пытаюсь сравнить Ростов с другими регионами — слежу за мероприятиями и чатами, таскаю интересные идеи, смотрю, где какое образование и где есть интересные работодатели.

С последним в крупных городах всё достаточно понятно — в Новосибирске, например, есть офисы 2Гис, Яндекса, Джетбрейнса, Контура, Тензора, ABBYY, Касперского, Сбера, Тинькова.
А куда можно пойти работать в Ростове? Захотелось уметь отвечать на этот вопрос и делать это на основе данных и фактов. tl;dr: С 2019 года я провожу опрос местного сообщества о ИТ-компаниях и делюсь результатами публично на RND Tech.
Как создавал опрос
А можно всех посмотреть?
Сначала надо собрать все ИТ-компании, которые хоть кому-то известны в сообществе и которые могут быть желаемым местом работы. Готового списка нет, хотя сначала я надеялся, что из базы юрлиц может выйти что-то полезное. Поэтому я просто закинул опрос в локальные чаты сообществ и просил назвать вообще все компании по памяти. Параллельно с этим искал разработческие вакансии на работных сайтах и выписывал, кто их размещает.
Оказалось, что название одной и той же компании можно написать 4-5 разными способами, поэтому потом случился этап ручной нормализации и перепроверки данных, чтобы привести список компаний к единому виду. В итоге получилась дока на ~200 компаний.
С длинным списком есть проблема — хочется спросить пользователя про каждую компанию, а заполнять такую анкету из нескольких сотен элементов долго и скучно, скорее всего, её будут бросать на середине (на самом деле я проверил на маленькой выборке и её правда бросали). Ещё в таком списке легко пропустить какую-то компанию, потому что глаз начинает замыливаться.
У Хабра была подобная проблема — и ребята решили её тем, что спрашивали человека про его сферу работы, а потом показывали компании только из его отрасли.
Нам такая штука подходила плохо — про многие компании мы почти ничего не знали, а еще хотелось не потерять в репрезентативности, спрашивая только про часть компаний. Решение вышло компромиссным — если у компании было меньше 5 сотрудников или о ней вспомнил только 1 человек, то она с большой вероятностью мало кому известна и интересна. Таких я из списка исключал.
Кого и как спрашивать
Второй этап — спросить аудиторию, что она думает о компании. Я наверстал анкету на survey.js, добавил демографические данные (город, возраст, образование, стек, профессия). Нам было интересно фильтровать компании именно по этим признакам, потому что джависты и тестировщики знают разные компании и между ними популярность отличается довольно сильно. Хотелось уметь отвечать на вопрос «я qa в Таганроге, какие компании тут любят другие qa?»
В анкете спросил про каждую компанию:
- знаешь
- посоветуешь другу туда пойти
- если соберешься менять работу, то будешь рассматривать её в первую очередь.

Ссылку на опрос отправил в чаты и группы сообщества, попросил распространить знакомых. Среди участников опроса разыграли 50 футболок, это должно было мотивировать людей потратить время на анкету. За первые дни анкету заполнили 500 человек.
А вот дальше стало сложнее. Есть те, до которых сложно дотянуться с анкетой:
- Люди не в ИТ-сообществе: те, кому это неинтересно, не нравится быть в комьюнити или кто не знает о его существовании.
- Студенты, которые оторваны от общей ИТ-тусовки.
До первых я пытался дотянуться таргетированной рекламой, благо есть и уже готовые парсеры соцсетей, и какие-то общие базы резюме, где можно взять контакты. Можно было и рассылку сделать, но спамить как-то не хотелось, а клик на рекламу — дело добровольное. Рекламу запускал на свои деньги. Общий бюджет, вместе с изготовлением футболок для розыгрыша, вышел 40 тысяч рублей.
Со студентами было сложнее. Они не часть ИТ-сообщества, могут не знать работодателей или знать только тех, кто приходит к ним с рекламой вакансий. Кажется, ценность опроса для них сильно ниже, да и вовлеченности в дела ИТ-сообщества у них нет. Таргет почти не работает, попытки зайти в студенческие группы чаще всего заканчиваются ничем. Я просил знакомых студентов и преподавателей закидывать ссылки в их чаты и группы. Выходил на старост и через них публиковал опрос в чаты групп.
Итог этого года такой — анкет мы собрали в полтора раза больше, чем в прошлом (1100 против 700). Из них опрос заполнили всего 120 студентов. Это мало, но как это чинить я пока не придумал.
Техника
Ладно, мы же тут про ИТ, да? Хочу рассказать пару историй про код.
Дяденька, я ненастоящий фронтендер
Поэтому вся морда для меня была челленджем — сейчас там плохой код, да и отображение в mobile-версии не очень. Я надеюсь, что кто-то придёт в гитхаб и сделает так, чтобы 30% пользователей, которые смотрят сайт с мобилки, перестали страдать.
Поиск вбросов
У меня много спрашивали, как можно проверить данные, бороться с повторными заполнениями, искать аутлаеры. Я сделал защиту на бэкенде и не публиковал эту часть кода в репозиторий, чтобы потенциальным ботоводам было сложнее её обойти. Сам метод приёма результатов всегда возвращал 200 ОК, но по факту было сделано несколько правил:
- Если введен email, который уже есть в системе — не записывать новый ответ.
- Если заполнена всего одна компания и заполняющий не студент — не записывать ответ.
- Если предыдущий ответ с того же адреса приходил за последние несколько секунд — не записывать ответ.
- Email к ответам мы не привязывали, но вот дополнительную информацию из запроса я сохранял. С какого клиента пришел пользователь, с какого адреса. Это позволило посмотреть на массовые заполнения из одного физического расположения (с одного компьютера или из одного сети с общим внешним IP-адресом).
Я анализировал данные клиента, чтобы посмотреть похожи ли данные массовых заполнений, например, из одного офиса, можно ли их учитывать в общей выборке или это явная накрутка. Я смотрел на те места, где люди заполняли опрос из одного офиса, с одного ip-адреса или было много заполнений в короткий период (то есть, явно ссылку забросили в какой-то чат и попросили заполнить). Если данные при этом были однобокими, то есть продвигали только одну компанию, то я просто выкашивал этот кусок данных из общей выборки.
Ещё читал все заполнения, убирал те, в которых были явно невалидные данные (знает и хочет работать в 100% компаний, не знает ни одной и при этом не написал в комментарии, что вообще не шарит, etc.). А ещё искал паттерны, которые отличаются от общей выборки. Иногда даже глазами. Вот такой странный инструмент я себе сделал:

Случайная синяя или зеленая «свечка» на фоне сравнительно низкой узнаваемости компании в целом — это массовое заполнение за неё. На этом скриншоте таких свечек 2, в одном случае на поверку она оказалась случайной, а в другом IP оказался реально офисом разработки. На результат это сильно не влияло и сами заполнения были честными — заполнившие отметили и другие компании, внимательно указали свою информацию, поэтому это не было явной накруткой вброс и данные этих заполнений я не удалял.
Захостить бесплатно
Последнее испытание для меня — бэкенд. Я раньше не хостил пет-проекты, надо было это сделать максимально бесплатно. За основу взял Heroku, сделал версию с данными под ногами, но получил огромное потребление памяти на вычитку и удержание всех результатов в памяти. Оптимизировать получилось, но под нагрузкой память всё равно вылезала за хероковские 512 мегабайт, поэтому подумалось, что пора извлекать и фильтровать данные out of process. Попробовал решения с EF Core и SQLite (спойлер — всё очень медленно) и маленьким mariaDb хостингом. Было много занятных задач по оптимизации запросов, а ещё в последнем EF, оказывается, есть штатный метод получения SQL, который будет сгенерирован! В итоге мне в дополнение к внешней БД помогла побороть баланс производительности и потребления памяти бесплатная версия Memcached.
Пока вроде работает ? Из минусов — это всё ещё стоит 17$ в месяц за ssl и БД.
Call to action
Я стараюсь на основе данных опроса делать какие-то гипотезы разной степени очевидности о Ростовском ИТ-сообществе. В этом году получается скучно. Например:
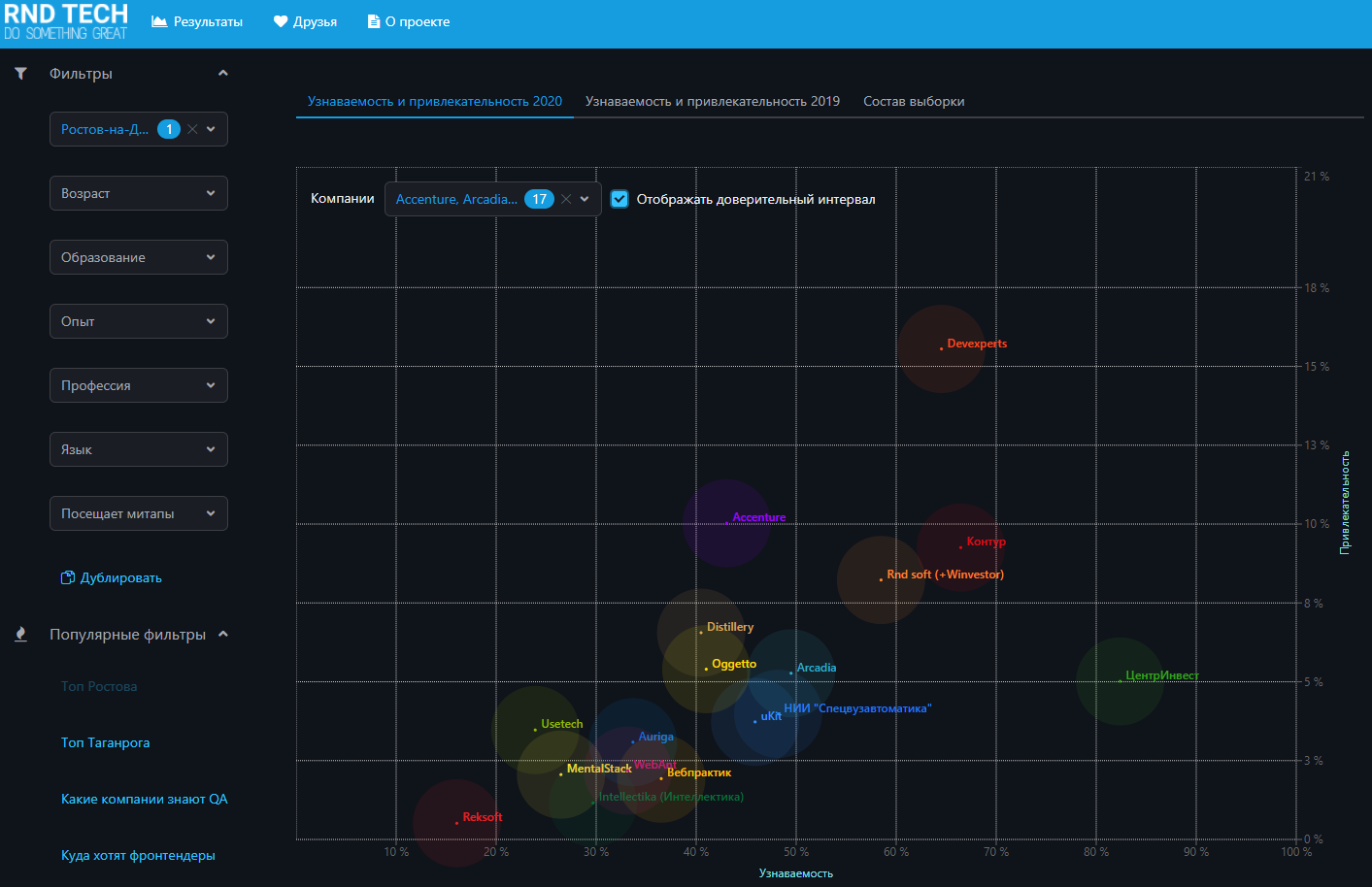
- В Ростове чаще всего хотят работать или в Тинькофф, или в местном офисе международного финтеха Devexperts. Ещё любят Теле2, Сбер, Контур, РнД Софт, TradingView — все они и узнаваемые и достаточно привлекательные )
- Джависты выбирают Тинькофф и Devexprts. JS/TS стек предпочитает Тинькофф, TradingView, Devexperts и Контур. Тимлиды — Тинькофф, Контур, Сбер, Devexperts. QA в Ростове (как и в прошлом году) больше всего хотят работать в Devexperts. Ещё хотят в Тинькофф, но там нет вакансий, поэтому, если не повезет с DX, то готовы сходить Юзтех, Контур, TradingView или Distillery.
- Средняя узнаваемость всех Ростовских ИТ-компаний среди людей, которые посещают митапы — 29.2%. То же самое среди тех, кто на митапы не ходит — 21.4%. Можно сказать, что люди, которые ходят на митапы в полтора раза лучше ориентируются в местном ИТ-рынке.
- В 2020-ом году люди стали больше ходить на митапы! Особенно тимлиды в Таганроге, спасибо за это новому сообществу «Тимлид на диване» ?
Если вы найдёте какие-то выводы, которые можно сделать на основе данных с RND Tech — пишите в комментарии, я с удовольствием выберу интересные наблюдения в ежегодную хабростатью о Ростовском ИТ ?

1К открытий1К показов
В книге раскрывают ценность API для бизнеса, рассказывают о составляющих успешного API и учит управлять его разработкой и развитием.
Поговорю об источниках для тестеров мидл и мидл+, которые читал и смотрел сам. Здесь нет «серебряных пуль», типа как стать мидл+ за 3 месяца.
Расскажем, что делать, если исследование нужно, а исследователя нет и поделимся опытом со стороны проектировщика и UX-исследователя.
Обзор любительского ответвления знаменитой игры Doom.