


Обработка документов в PDF и JPG: распознавание, тегирование, извлечение текста

Как обрабатывать документы в PDF и в JPG, извлекать из них нужные данные автоматически, а текст включать в электронный документооборот.
3К открытий3К показов
Существует много RPA-платформ, которые позволяют автоматизировать практически любое взаимодействие с рабочими приложениями и избавить человека от рутинных задач.
Однако многие компании сталкиваются с проблемами в автоматизации обработки неструктурированных документов в формате PDF или JPG. Это могут быть договоры от контрагентов, выставленные счета от подрядчиков, заявления от клиентов.
Из каждого входящего документа нужно извлечь ценные данные: дату выставленного счета, финальную сумму договора, обратный адрес отправителя, название контрагента.
Далее необходимо внести эти данные в систему электронного документооборота, провести сверку данных из документа с данными из внутренних систем или подсчитать статьи расходов и сравнить их с финальной суммой.
Данные в подобных документах не структурированы. К тому же, у разных клиентов и контрагентов существует много форматов этих данных.
Подход с использованием строго описанных правил для обработки таких документов требует колоссальных затрат на разработку, поддержку и последующее расширение автоматизации.
В таких случаях не обойтись без применения технологий машинного обучения, что позволит сделать автоматизацию процессов «умной». Иными словами, необходима Intelligent Automation Platform (IA Platform).
Итак, для автоматизации обработки неструктурированных документов необходимы три компонента, каждый из которых требует своего уникального стека технологий и подходов. В статье мы расскажем, как используем их в ИТ-компании ИБА в работе нашей платформы «Канцлер RPA».
Компонент № 1: распознавание
На рынке есть большое количество различных движков Optical Characters Recognition (OCR): и платных, и open source. Мы решили изучить, какие технологии наиболее зрелые, и выбрать те, которые больше всего подходят под наши требования. Важна была возможность использования в коммерческих целях, а также хорошее качество распознавания отсканированных документов.
Мы выбрали для себя Tesseract OCR. Это разработка HP, перешедшая в open source благодаря Google. Также мы обратили внимание на амбициозный проект, который зачастую показывал лучшие результаты — PaddleOCR. Его мы внедрили в платформу как альтернативный движок.
Для повышения качества OCR мы делаем предобработку документов, используя ImageMagick. Большинству документов, с которыми мы встречаемся на практике, достаточно базовой предобработки, которая включает в себя изменение DPI картинки, обесцвечивание, выравнивание возможного наклона документа, удаление прозрачности.
Установка ImageMagick выполняется следующей командой:
● Для CentOS, Fedora:
yum -y install ImageMagick
● Для Debian, Ubuntu:
apt-get -y install imagemagick
Например, у нас есть картинка с именем «input.png». Для ее предобработки мы предлагаем команду со следующими параметрами ImageMagick:
Здесь видно, что обычно мы используем конвертацию DPI в 350 точек на дюйм. В официальной документации Tesseract есть упоминание о том, что движок лучше работает на картинках, у которых «хотя бы 300 DPI», но ничего не сказано про подходы к определению наилучшего значения. Однако они ссылаются на интересные эксперименты, которые показывают, что выбор правильного значения DPI лучше всего рассчитывать по высоте заглавных букв в тексте картинки, которую мы обрабатываем.
Мы повторили эти эксперименты. Из них следует неожиданный вывод об оптимальном размере заглавных букв в пикселях. Казалось бы, чем больше размер букв, тем количество OCR-ошибок должно быть меньше. На самом деле все оказалось не так, и минимальное количество ошибок Tesseract версии 4.0.0 допускает при вертикальном размере заглавных букв в пределах 20-35 пикселей.

Разумеется, все зависит от используемого в документе шрифта. Однако, в большинстве официальных документов используются одни и те же шрифты примерно одного и того же размера. Поэтому мы предлагаем именно 350 DPI как базовую настройку, что обычно изменяет размер заглавных букв как раз на 20-35 пикселей.
Вот пример предобработанного документа, где был исправлен наклон, увеличен контраст и использованы только черные и белые цвета:
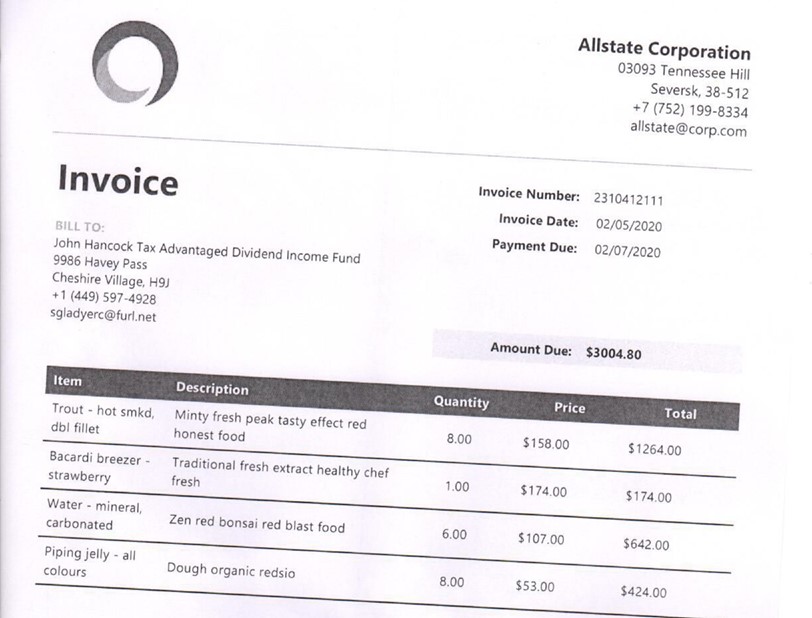
Компонент № 2: тегирование
Для подготовки обучающего набора документов мы разработали для нашей платформы специальный вид ручной задачи, где человек выделяет текст мышкой на оригинальном документе, таким образом указывая расположение нужных данных.
Для реализации UI мы выбрали ReactJS. Это самая популярная библиотека для создания пользовательских интерфейсов. Также ReactJS гибкий, с хорошей читаемостью кода благодаря разбивке приложения на компоненты, поэтому его легче поддерживать, находить и исправлять ошибки.
Чаще всего к нам приходит документ в формате PDF, который мы конвертируем в картинку, используя ImageMagick и Ghost Script. Предположим, мы получили вот такую картинку:

Далее документ отправляется на OCR. Результатом работы OCR будет следующая HTML-структура:
Мы видим иерархию следующего вида: каждый документ делится на страницы («ocr_page»), у каждой страницы могут быть колонки («ocr_carea»), у колонки есть параграф («ocr_par») и так далее до самой мелкой структуры — слова («ocrx_word»). В атрибутах каждого блока есть информация о его расположении относительно оригинального документа. Например, «bbox 2215 236 2443 288» означает, что верхний левый край слова начинается в координатах X=2215, Y=236, а правый нижний край — X=2443, Y=288.
Таким образом, на UI к нам приходит картинка оригинального документа и OCR-результат с извлеченным из него текстом с координатами.
Далее мы отображаем картинку документа в обычном теге, без каких-либо дополнительных слоев. Начинаем отслеживать JS-события перемещения мыши по картинке и событие выделения. Когда пользователь выделяет какую-либо область на картинке, в обработчике события мы получаем координаты выделенной области. Теперь перед нами стоит задача определить, какие области из OCR-результата затрагивает выделенная область. Это простая математическая задача о пересечении одной области с другой. Но эта операция должна выполняться максимально быстро, т. к. пока пользователь проводит мышкой, выделяя все большую область, мы каждый раз должны пересчитывать пересечение областей. Для оптимизации процесса мы решили конвертировать HTML формат в JSON с сохранением структуры вложенности. Таким образом HTML из примера выше примет следующий JSON-вид:
Теперь, получая координаты пользовательского выделения, мы начинаем идти по структуре OCR-JSON вглубь дерева вместо того, чтобы перебирать координаты каждого извлеченного слова. Например, на уровне параграфа мы сразу можем понять, стоит ли опускаться на уровень ниже к линиям или перейти к следующему параграфу для поиска вхождения.
Если мы определяем, что в выделенную пользователем область попадает регион какого-то слова, мы создаем элемент с полупрозрачным фоном с абсолютной позицией, чтобы имитировать выделение. У пользователя создается впечатление, что он выделил слово в самом документе, хотя технически это просто картинка, которая не содержит в себе текстового слоя.
В качестве выходных данных мы также используем JSON, который содержит в себе информацию об извлеченных сущностях и их относительные координаты. Такие данные несут в себе основную ценность и в дальнейшем используются для обучения Machine Learning (ML) модели:
Компонент № 3: извлечение
Для автоматического извлечения текста мы выбрали ML-библиотеку SpaCy, которая поддерживает 60+ языков, быстро тренируется, имеет множество преднатренированных моделей с использованием нейронных сетей.
Наша платформа предполагает обработку документов из различных сфер: это могут быть банковские выписки, страховые заявления, ритейл-счета, анкеты для HR-отделов и т. д. Поэтому под каждый вид документов конкретного клиента мы обучаем отдельную модель, что позволяет добиться лучших результатов. Благодаря разработанному компоненту тегирования документов процесс генерации обучающего набора не требует специализированных знаний в области ML. Обычно этот процесс выполняют Subject-Matter Experts (SME) — сотрудники клиента, которые до автоматизации занимались извлечением таких данных вручную, и именно они лучше всего знают, какой текст должен быть выделен в конкретном документе.
Один из главных вопросов при автоматизации обработки документов — какое количество исторических документов требуется для обучения ML-модели. Мы определили, что для быстрого старта первой версии модели, которая сразу же начнет приносить пользу, достаточно от 50 до 100 документов. Чтобы определить оптимальное количество документов, мы провели эксперименты по обучению моделей, в которых изменяли только размера тренировочного набора. Для каждой модели мы высчитывали такие показатели, как Accuracy, Precision, Recall и F1 Score. Оказалось, что оптимальным количеством является примерно 500 документов. При дальнейшем увеличении количества документов не происходит существенного улучшения точности.

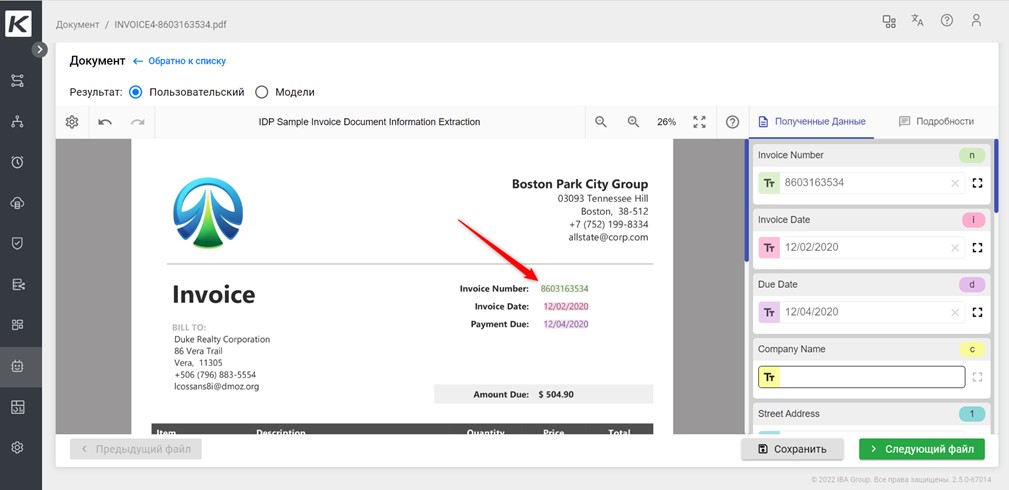
После того, как модель обучена, ее можно внедрять в бизнес-процесс. Она начнет выполнять тегирование документа автоматически вместо человека. Если по правилам валидации автоматически извлеченных данных требуется ручная проверка, мы отправляем результат работы ML-модели на наш компонент тегирования. Там производим обратную операцию по выделению извлеченных областей на документе. Так человек может увидеть, откуда были извлечены данные:

Таким образом, умная автоматизация сочетает в себе возможности роботизации процессов и машинного обучения. Тщательное исследование доступных open source решений и грамотная работа над обучением ML-моделей позволила нам создать RPA-платформу, которая отлично справляется с обработкой неструктурированных документов. Пользователю же при этом кажется, что он просто выделяет мышкой слова.

3К открытий3К показов

Как компьютерное зрение сокращает инспекции в сельском хозяйстве и строительстве: дроны, карты, edge-аналитика и снижение рисков.

ИИ-сервисы для генерации изображений быстро набирают популярность. В нашем обзоре — лучшие программы для создания картинок по фото и голосу, советы по выбору и полезные функции для профессионалов и творческих проектов.

Подборка из 8 сервисов, которые позволяют использовать ChatGPT, Midjourney, DALL·E и другие нейросети в России — без VPN, с русским интерфейсом и полным доступом.

Эпохи развития программирования в России и в мире. Какие стадии прошли разработчики и к чему пришли в настоящий момент. Прогнозы на будущее.