Эта статья посвящается всем начинающим в области нейронных сетей. В особенности тем, кто не создал еще ни одной «нейронки».
31К открытий35К показов
Григорий Бузмарев
Вackend-разработчик TAGES
Далее будут описаны основные шаги создания нейронный сетей при работе с Tensorflow. Прежде чем начать, необходимо выбрать среду разработки. Я рекомендую использовать для несложных сетей https://colab.research.google.com. Это бесплатная среда разработки написаная командой Google специально для решений в области машинного обучения и нейронных сетей.
Основные шаги:
Предобработка данных.
Построение модели.
Компиляция модели.
Обучение модели.
Оценка модели.
Предобаботка данных
Результат вашей работы наполовину зависит от того, как хорошо вы подготовите данные для модели. Пропущенные данные или неправильная размерность может свести на нет все усилия. Поэтому важно уделить этому этапу и время, и внимание.
По сути для обработки данных можно использовать то, что удобнее. Можно писать свои функции на Python или использовать библиотеку sklearn.preprocessing. В самом tensorflow тоже есть средства для предобработки в модуле tf.keras.preprocessing. В частности большой выбор инструментов для изображений и текста.
На что обратить внимание в первую очередь:
Пропуски в данных. Ситуацию можно исправить несколькими способами. Если таких записей немного, и ими можно пренебречь, то их можно удалить. Также их можно заменить: это может быть среднее значение или наиболее часто используемое для данной фичи.
Нормализация данных. Приведение значение к определенному диапазону. Например [-1; 1] или z-масштабирование (в sklearn это StandardScaler).
Обработка категориальных данных. Как правило, это создание под каждую категорию своей фичи. Можно использовать OneHotEncoder из sklearn или get_dummies в pandas.
Также необходимо разбить данные на 3 выборки:
обучающую,
валидационную,
тестовую.
Обучающий набор данных — это то, на чём непосредственно обучается модель. Валидация нужна для проверки вашей модели. В процессе обучения сеть может слишком сильно подстроиться под данные, на которых обучается. В результате такая модель не сможет работать с данными отличными от обучающего набора. Это явление называется переобучением. Чтобы избежать этого нужен валидационный набор на котором контролируется, как модель предсказывает. Тестовый набор используется только один раз, когда сеть полностью обучена, для финальной оценки. После этого сеть не доучивается и не изменяется. Обычно на валидационный набор выделяется 20-30% данных и на тестовый 5-10%.
Построение модели
Проще всего создать модель с помощью класса Sequential, который принимает список слоев. Чтобы посмотреть содержимое модели нужно вызвать метод summary(). Важно назначить размер входных данных. Это можно сделать с помощью атрибута input_shape в первом слое.
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(32, activation='relu', input_shape=(10,), name='hidden_layer_1'),
tf.keras.layers.Dropout(0.2, name='dropout'),
tf.keras.layers.Dense(10, name='hidden_layer_2')
])
model.summary()
Заметьте, к модели добавилось ещё два слоя. Внизу указывается количество параметров, которые нужно обучить. Соответственно, чем больше параметров, тем дольше будет обучаться ваша сеть.
Sequential удобен если у вас небольшая сеть с последовательной структурой, где слои следуют друг за другом, есть только один вход и один выход. Но что делать если модель должна быть немного хитрее? Для этого в tensorflow есть функциональный API. Перепишем модель выше.
Теперь каждый слой представляет собой функцию, которая принимает на вход результат работы предыдущего слоя. Структуру такой модели можно вывести наглядно со всеми зависимостями слоев друг от друга.
С помощью функционального API можно создать структуру с несколькими входами и выходами.
# Назначим два отдельных входа
input_1 = tf.keras.Input(shape=(10,), name='input_1')
input_2 = tf.keras.Input(shape=(20,), name='input_2')
# Определим структуру для обработки первого входа
layer_1 = tf.keras.layers.Dense(32, name='layer_1')(input_1)
# Для второго входа
layer_2 = tf.keras.layers.Dense(32, name='layer_2')(input_2)
layer_3 = tf.keras.layers.Dense(16, name='layer_3')(layer_2)
# Объединим
concatenate = tf.keras.layers.concatenate([layer_1, layer_3])
# Определим два выхода
output_1 = tf.keras.layers.Dense(1, name='output_1')(concatenate)
output_2 = tf.keras.layers.Dense(1, name='output_2')(concatenate)
model_3 = tf.keras.Model(
inputs=[input_1, input_2],
outputs=[output_1, output_2],
)
tf.keras.utils.plot_model(model_3, show_shapes=True)
Компиляция модели
После того как структура модели готова, её нужно скомпилировать. Для этого у модели есть метод compile(). Главное, что можно определить при компиляции — это функция потерь. По сути, от неё зависит результат обучения. Например, среднеквадратичная ошибка сильнее «наказывает» модель за выбросы чем средняя абсолютная ошибка. Что именно использовать, зависит от задачи. Если вам нужно предсказать цену жилья, то, скорее всего, выбросы плохо повлияют на результат. В этом случае больше подойдёт средняя абсолютная ошибка. Если вы предсказываете движение цен на фондовом рынке, то слишком большое отклонение от цены будет во вред, и здесь лучше среднеквадратичная ошибка.
Ещё один важный параметр — это алгоритм оптимизации. Хорошо подобранный оптимизатор позволит вам быстрее обучить модель и по возможности избежать локальных минимумов.
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(5, input_shape=(10,), name='hidden_layer_1'),
tf.keras.layers.Dense(2, name='output')
])
model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # Функция потерь
optimizer='Adam', # Оптимизатор
metrics=[ # Метрики
'accuracy', # Если у объекта назначено имя, то можно вызвать объект с его помощью
tf.keras.metrics.Precision()
]
)
Обучение модели
После того как модель скомпилирована её нужно обучить. Для этого применяется метод fit(). Он принимает входные данные и ожидаемые ответы сети. Можно указать массив с валидационными данными, максимальное количество эпизодов и многое другое. Простой пример:
import numpy as np
# Инициализируем набор данных случайными цифрами.
X = np.array(np.random.random((100, 5))) # Матрица 100 на 10 с диапазоном значений [0;1]
Y = np.array(np.random.random((100))) # Вектор длины 100 с диапазоном значений [0;1]
# Создадим модель
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(3, input_shape=(5,)),
tf.keras.layers.Dense(1)
])
# Скомпилируем
model.compile(
optimizer='Adam',
loss='mse',
metrics=['mean_absolute_error']
)
# Обучим
model.fit(
X, # Набор входных данных
Y, # Набор правильных ответов
validation_split=0.2, # Этот параметр автоматически выделит часть обучающего набора на валидационные данные. В данном случа 20%
epochs=10, # Процесс обучения завершится после 10 эпох
batch_size = 8 # Набор данных будет разбит на пакеты (батчи) по 8 элементов набора в каждом.
)
В выводе показывается результат выполнения каждой эпохи. Выводится номер эпохи, количество пакетов, затраченное на эпоху время и ошибки. Loss — это расчитанная функция потерь, mean_absolute_error — это метрика указанная при компиляции. Если указать дополнительные метрики, то они тоже будут присутствовать в выводе. Все ошибки с префиксом «val_» — это то же самое только для валидационного набора данных.
В данном виде модель можно обучить, но гораздо эффективнее это можно сделать, если использовать функционал обратных выходов. С их помощью можно осуществить раннюю остановку обучения для борьбы с переобучением, визуализировать данные и многое другое. Вот пример некоторых из них:
# Если ошибка не уменьшается на протяжении указанного количества эпох, то процесс обучения прерывается и модель инициализируется весами с самым низким показателем параметра "monitor"
early_stopping = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', # указывается параметр, по которому осуществляется ранняя остановка. Обычно это функция потреть на валидационном наборе (val_loss)
patience=2, # количество эпох по истечении которых закончится обучение, если показатели не улучшатся
mode='min', # указывает, в какую сторону должна быть улучшена ошибка
restore_best_weights=True # если параметр установлен в true, то по окончании обучения модель будет инициализирована весами с самым низким показателем параметра "monitor"
)
# Сохраняет модель для дальнейшей загрузки
model_checkpoint = tf.keras.callbacks.ModelCheckpoint(
filepath='my_model', # путь к папке, где будет сохранена модель
monitor='val_loss',
save_best_only=True, # если параметр установлен в true, то сохраняется только лучшая модель
mode='min'
)
# Сохраняет логи выполнения обучения, которые можно будет посмотреть в специальной среде TensorBoard
tensorboard = tf.keras.callbacks.TensorBoard(
log_dir='log', # путь к папке где будут сохранены логи
)
Обучим эту же модель, но уже используя обратные вызовы.
Как мы видим, процесс обучения остановился раньше, поскольку модель не улучшалась. В результате есть и сохраненная модель, её можно восстановить методом tf.saved_model.load(). Если не использовать ModelCheckpoint, то модель можно сохранить методом save().
INFO:tensorflow:Assets written to: my_model/assets
Можно посмотреть и как модель обучалась. Для этого нужно вызвать TensorBoard.
%load_ext tensorboard
%tensorboard --logdir "log"
The tensorboard extension is already loaded. To reload it, use:
%reload_ext tensorboard
Reusing TensorBoard on port 6006 (pid 287), started 0:01:15 ago. (Use '!kill 287' to kill it.)
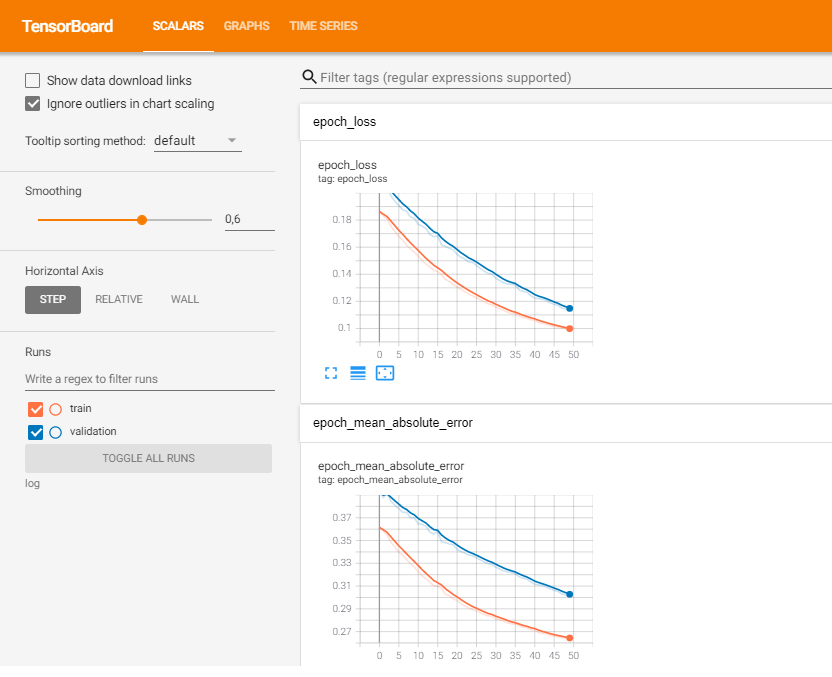
На графике оранжевая линия показывает, как изменялась функция потерь на обучающем наборе данных, а синяя — на валидационном. TensorBoard это мощный инструмент для исследования модели. Его обязательно надо изучить и использовать.
Оценка модели
Последнее, что нам осталось — оценить обученную модель. Для этого есть метод evaluate(). Для примера создадим тестовые данные:
X_test = np.array(np.random.random((10, 5)))
Y_test = np.array(np.random.random((10)))
res = model.evaluate(X_test, Y_test)
print("loss and mean_absolute_error", res)
1/1 [==============================] - 0s 21ms/step - loss: 0.1259 - mean_absolute_error: 0.3187
loss and mean_absolute_error [0.1258658617734909, 0.3187190890312195]
Чтобы получить предсказанные значения, используйте predict().
С помощью нейронных сетей можно создавать удивительные вещи. Иногда это что-то обыденное, но весьма полезное, иногда даже похоже на магию. Машинное обучение и нейронные сети, в частности, это огромный пласт знаний, который вам предстоит изучить. Надеюсь, моя статья поможет вам сделать следующий шаг на этом пути.