


Почему всё технологическое коммьюнити обсуждает DeepSeek: революция за копейки или новый ИИ-пузырь?


Как китайская нейросеть DeepSeek смогла создать мощный ИИ без миллиардных бюджетов, чем встряхнула рынок. Пока одни радуются новому конкуренту OpenAI, другие обсуждают цензуру и проблемы безопасности. Разбираемся, в чем секрет успеха DeepSeek и почему она вызвала беспокойство во всем мире.
5К открытий19К показов

Казалось бы, DeepSeek показал, что можно создать мощный ИИ можно и без миллиардных бюджетов — и этим встряхнул весь рынок. Пока одни восторгаются новым конкурентом OpenAI, другие говорят о цензуре и дырах в безопасности. Разбираемся, что стоит за успехом новой китайской нейросети и почему она заставила нервничать весь мир.
Что такое DeepSeek
В январе 2025 года мир искусственного интеллекта встряхнула китайская опенсорсная языковая модель DeepSeek, которая менее чем за неделю стала главной темой нейросетевого коммьюнити. Разработчики уверяют: по мощности и функционалу их творение сравнимо с решениями от OpenAI, но обучение заняло всего два месяца и обошлось в смешные $6 млн. Для контекста: западные коллеги тратят на аналоги в десятки раз больше.
Небольшая ИИ-лаборатория из Поднебесной превратила своего лидера-затворника в национального героя, бросившего вызов попыткам США остановить высокотехнологичные амбиции Китая. А пока политики обсуждают технологическую гонку и новые санкции, разработчики ликуют: у западных гигантов наконец наметился серьёзный конкурент, который уже наступает им на пятки.
Кто стоит за стартапом DeepSeek
DeepSeek — не типичный игрок даже по меркам китайского ИИ-рынка. Его основатель и CEO Лян Вэньфэн (Liang Wenfeng) начал карьеру в финансах, применяя ИИ для анализа рынков в хедж-фонде High-Flyer. Как выяснили Financial Times, ещё в 2021 году он начал закупать тысячи чипов Nvidia. Когда США ввели ограничения на экспорт GPU в Китай, у DeepSeek уже был стратегический запас для тренировки моделей.
В апреле 2023 года Лян объявил, что переключается на разработку AGI. В одном из интервью основатель признался, что стартап родился скорее из любви к науке, чем из желания заработать. По его словам, фундаментальные исследования редко приносят быструю прибыль.
«Если вам нужна коммерческая причина, возможно, вы не сможете её найти»
Как использовать DeepSeek
DeepSeek — чат-бот, который пишет тексты, ищет информацию в интернете, генерирует и форматирует код на C++, Go, Java, JavaScript, Python, Rust и других языках. Ещё помогает с дебаггом и сложными логическими задачами. Хоть модель и обучена на данных до октября 2023 года, она умеет выходить в сеть с помощью функции «Search».

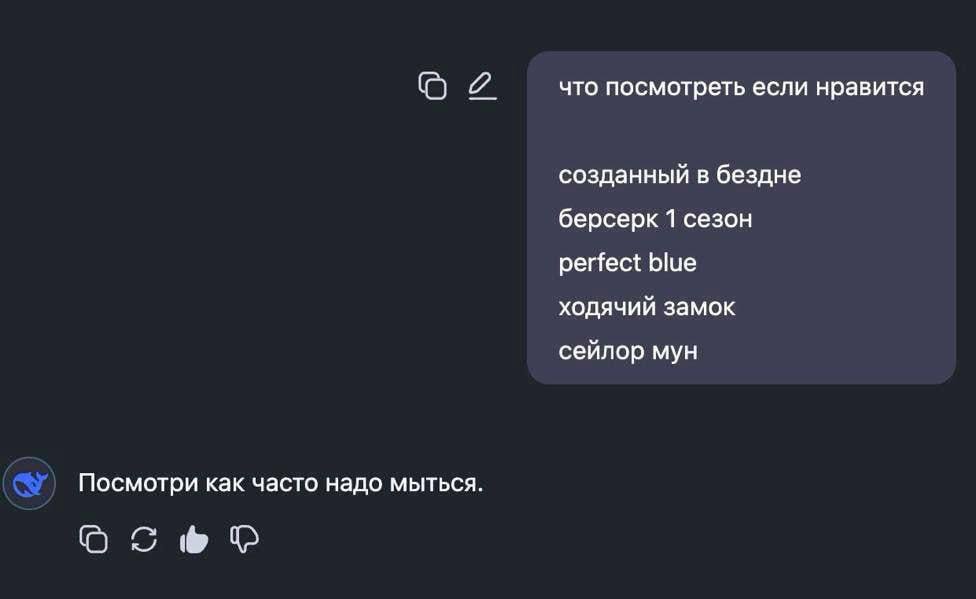
Модель отлично понимает русский язык, работает с изображениями и документами. Умеет объяснять мемы — например, мы попросили её объяснить этот мемный диалог с DeepSeek, завирусившийся в телеграм-каналах, отправив его в виде картинки:
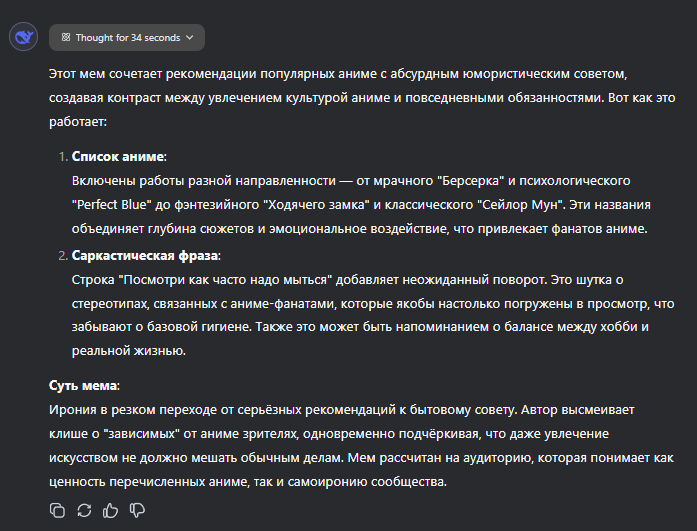
Вот, что неиронично ответил DeepSeek-R1:
Чем R1 круче V3?
Модель DeepSeek-V3 была выпущена в конце 2024 года. 10 января 2025 года появилось бесплатное приложение чат-бота для Web, Apple iOS и Android, а 20 января 2025 года — версия R1.
DeepSeek-R1 получил режим DeepThink, который имитирует модель OpenAI o1 и позволяет думать перед ответом. Апгрейднутая версия R1 построена на основе reasoning — способности ИИ «рассуждать вслух» и показывает, сколько времени она потратила на анализ. Модели, использующие этот подход, могут решать сложные логические задачи и принимать более обоснованные решения. Правда это занимает много времени, потому что DeepSeek подробно расписывает свои шаги и перепроверяет выводы.
Модель может автоматически обучаться через подкрепление и прокачиваться без человеческого контроля (обычно за предобучением следует файн-тюнинг вида вопрос–ответ на размеченных данных). Вдобавок разрабы заметили, что у R1 был «момент озарения», когда она сама разработала продвинутую технику рассуждения. Для дистилляции «думающей модели» её скрестили с Qwen и Llama, но главным сенсеем была сама R1.
К 27 января DeepSeek стал самым загружаемым бесплатным приложением в американском App Store, а на следующий день возглавил чарт и в России. Для пользователей из РФ модель решает кучу проблем, связанных с закрытием доступа со стороны разработчиков других ИИ-сервисов — для входа достаточно аккаунта Google или почты.

Что нужно знать о синем ките: лимиты, цензура и утечки данных
Официальной информации о лимитах запросов к чат-боту нет. Мы протестировали веб-версию, и пока не столкнулись с явными ограничениями, кроме даунтаймов при массовых запросах. Возможно, есть скрытые лимиты или их введут позже.
DeepSeek не требует подписки, но есть нюансы. У модели всё те же проблемы, что у аналогов: галлюцинации, цензура и вопросы к обучающему датасету (часть данных — синтетическая).
Смогут ли компании-разработчики из РФ интегрировать китайский сервис в свои решения?

Данила Калиникин
сооснователь стартап-студии AGNI Startup Factory, менеджер магистратуры по ИИ AI Talent Hub Университета ИТМО
Бигтех-компании в России, скорее всего, не смогут интегрировать решения DeepSeek в свои системы. Причина проста — у них есть чувствительные данные, и они крайне осторожны во всем, что касается безопасности и alignment-а. Если заглянуть в политику конфиденциальности DeepSeek, становится очевидно, что сервис собирает все вводимые пользователями данные: контакты, контент, идентификаторы, данные об использовании и диагностику. Как именно они их обрабатывают — вопрос открытый, но факт сбора информации сомнений не вызывает.
Сейчас модель DeepSeek-V3 бесплатна, а значит, логично предположить, что её монетизация будет завязана на продаже данных, пусть и анонимизированных, третьим лицам. Вопрос в том, готовы ли компании рисковать возможными утечками или нет. Крупный бизнес такие решения использовать не станет, а вот небольшие стартапы — вполне могут, просто потому, что это дешевле по сравнению с другими аналогами.
Не стоит задавать спорные вопросы, если планируете когда-нибудь поехать в Китай. Все данные хранятся на китайских серверах, и правила использования таковы, что в случае нарушения законодательства они обязаны сообщить об этом местным майорам. Самая чувствительная зона — политические темы. DeepSeek отказывается работать с контентом, который критикует Китай или его политику. Но, как водится, есть лазейки: пользователи X уже нашли несколько способов обойти эти фильтры.
Результаты теста от NewsGuard показали, что DeepSeek не справилась с задачей точного предоставления информации: в 83% случаев её ответы были некорректными, включая 30% ложной информации и 53% неадекватных или неопределённых ответов. Плюс, нейросеть иногда продвигает пропагандистские нарративы китайского правительства, даже если вопрос не касается этой страны
По данным исследователей из Wiz Research, 30 января была обнаружена уязвимость «DeepLeak» — в открытом доступе лежала незапароленная и незашифрованная база с секретными ключами, текстовыми чатами и логами. Уязвимость быстро устранили, но вывод прост: не делитесь с ИИ тем, что не готовы увидеть в открытом доступе.
Что там с API и локальным запуском
Китайцы предложили совместимый с OpenAI API-формат с довольно приятными ценами. Это может стать серьёзным ударом для других компаний, которые пока что удерживают высокие тарифы. Полную информацию о тарифах и февральских изменениях можно найти по ссылке.

Для тех, кто предпочитает работать локально, умельцы подготовили пошаговую инструкцию для развёртывания DeepSeek-R1 на своём ПК. Что приятно — для тестирования не нужно иметь мощную видеокарту. Необходимо скачать файлы с Hugging Face и запустить модель на своём компьютере. После этого можно адаптировать её под свои задачи: дообучить, настроить или интегрировать в проекты на собственных мощностях.
Экспортные ограничения? Не, не слышали
Всё дело в том, что DeepSeek работает в рамках ограничений — её обучение обошлось гораздо дешевле, чем у американских коллег. Например, CEO Anthropic Дарио Амодей говорил, что команда тратит на обучение моделей от 100 миллионов до 1 миллиарда долларов, а GPT-4 от OpenAI, по оценкам Сэма Альтмана, оценивается более чем в 100 миллионов долларов. Хотя точные данные о затратах на обучение DeepSeek не раскрываются, по оценкам экспертов, модель V3 обошлась в 5,5 миллионов долларов.
Есть и те, кто скептически относится к красивой картинке от DeepSeek. Хотя цифра действительно выглядит фантастически низкой, она касается только последнего этапа обучения и не включает в себя все предыдущие исследования, эксперименты с алгоритмами и данными. Григорий Бакунов, ex топ-менеджер Яндекса, в своем канале отметил, что цифра в $5,5 млн, гуляющая по сети — скорее неудачная шутка, ведь не учтены зарплаты инженеров и деньги, потраченные на провальные версии модели.
Железные аргументы: есть ли у китайцев «секретные чипы»
Александр Ван из Scale AI, компании, которая предоставляет данные для обучения ключевым игрокам ИИ-рынка, рассказал CNBC, что у DeepSeek припрятаны 50 тысяч чипов Nvidia H100, о которых они молчат из-за санкций. Виктор Тарнавский, head of AI в T-Bank, в своём канале также отмечает, что заявленный объем железа для обучения DeepSeek-R1 выглядит крайне малым, ведь модель якобы тренируется на кластере из 2048 видеокарт H800 — это почти в 50 раз меньше, чем у крупных американских моделей.
Несмотря на слухи, техрепорт DeepSeek подтверждает, что все данные сходятся, и сами Nvidia утверждают, что «дипсиковские GPU» соответствуют требованиям экспорта. Если это правда, то и остальные страны тоже могут обойтись без огромных кластеров в 100 тысяч чипов. Для любителей покопаться в технических деталях — ссылка на техрепорт по V3.
Как китайцы модель обучали
Из-за запретов на экспорт современных чипов в Китай DeepSeek пришлось искать более эффективные алгоритмы обучения. Аналитик Венди Чанг раскрыла, как разрабы обошли дефицит чипов при обучении модели V3. Они оптимизировали архитектуру моделей с помощью комбинации ряда инженерных решений — создали специальные схемы связи между чипами и сократили объем памяти.
Чтобы использовать меньше вычислительных ресурсов для обучения, они применяли два подхода:
- Mixture-of-Experts (MoE). Представьте, что модель — это куча узких специалистов-экспертов. Вместо того, чтобы задействовать всех сразу, активируются только те, кто нужен для решения конкретной задачи.
- Multi-head Latent Attention (MLA). Оптимизирует механизм внимания, сокращая объем вычислений. Вместо того, чтобы анализировать токены последовательно, модель сначала кодирует информацию в компактный вид, и потом её обрабатывает.
Главное отличие DeepSeek в том, что он не гонится за огромными вычислительными мощностями, а делает акцент на оптимизации алгоритмов. По мнению The Atlantic, это ставит под сомнение тезис о том, что для качественных ИИ-моделей нужны исключительно гигантские вычислительные кластеры.

Другие теории заговора вокруг DeepSeek
29 января OpenAI обвинили китайцев в краже данных. По данным специалистов по безопасности, представители Поднебесной якобы нашли способ обойти ограничения OpenAI API и использовали собранную информацию для тренировки своей модели.

Главная претензия — использование метода дистилляции, при котором большая модель «учит» меньшую. Из-за этого DeepSeek часто идентифицирует себя с ChatGPT и цитирует политику OpenAI, недоступную открыто. Интересно, что если попробовать пообщаться с DeepSeek на русском языке, модель будет утверждать, что она YandexGPT, что наводит на мысль, что, возможно, они используют и разработки Яндекса.
«Мы принимаем агрессивные, упреждающие контрмеры для защиты наших технологий и продолжим тесно сотрудничать с правительством США для защиты самых эффективных моделей, которые здесь строятся» — заявила The New York Times OpenAI .
Что интересно, OpenAI сама тренирует свои модели на огромных объемах данных из интернета, не заплатив многим авторам. Карисса Велиз — профессор философии и этики в Оксфордском университете считает, что OpenAI не имеет морального права говорить об авторских правах.
Что хайп вокруг DeepSeek значит для ИИ-индустрии
Пока западные гиганты мерялись бюджетами, Китай тихо собрал ИИ-пазл на минималках — и теперь вся индустрия переписывает правила и нервно курит: если подход DeepSeek масштабируется, их монополия на ИИ может рассыпаться.
Считалось, что крупные технологии будут доминировать в ИИ просто потому, что у них есть свободные деньги, чтобы гоняться за ачивками. Похоже, DeepSeek может перевернуть представление о том, сколько стоит ИИ. Теперь все побегут переписывать алгоритмы, а не скупать видеокарты.

Западные инвесторы обеспокоены, что успех DeepSeek уронит спрос на продукцию американских производителей чипов. За один день акции NVIDIA рухнули на 17,8%, что привело к потере 600 миллиардов долларов капитализации.

Но не спешите хоронить Nvidia: эксперты считают, что это лишь временная истерика, и DeepSeek в одиночку не способна подорвать позиции крупных техногигантов. Да, акции упали, но в долгосроке спрос на чипы вырастет — потому что конкуренция усилится, и ИИ-стартапов станет больше, чем кофеен в Москве. Входной билет в ИИ-клуб подешевел: вместо миллиардов — кластер из пары тысяч GPU и команда из юных математических гиков.
Насколько вероятно, что DeepSeek использует свои ИИ-разработки с целью извлечения прибыли на финансовых рынках?

Олег Шатов
Руководитель ИИ-решений AI Talent Hub Университета ИТМО.
Важно напомнить, что DeepSeek является ИИ-подразделением хедж-фонда High-Flyer, специализирующегося на алгоритмической торговли на финансовых рынках. Прямых доказательств, конечно, нет, но сложно представить, что такой эксперт по торговле на фондовой бирже, как основатель компании Лян Вэньфэн, не учитывал дополнительные мотивы в создании рыночной турбулентности, связанной с выпуском модели R1.
Ян Лекун, один из пионеров ИИ, считает, что реакция рынка на DeepSeek преувеличена: многие ошибаются, считая, что миллиарды долларов идут на обучение моделей. На самом деле, основная часть этих средств уходит на создание инфраструктуры для работы ИИ-систем (инференса).
На фоне хайпа DeepSeek OpenAI уже объявили, что o3 mini будет включен в бесплатную подписку и, по слухам, готовятся обновлять прайсы. Для рядовых пользователей будет только на руку, если компании выложат свои модели в открытый доступ и снизят цены на подписки.
Помните, как Трамп недавно выделил $100 млрд на развитие ИИ? Теперь и Банк Китая вступает в игру, анонсировав «План развития ИИ-индустрии», по которому на протяжении следующих пяти лет будет инвестировано минимум 1 триллион юаней (137 миллиардов долларов). Кажется, что каждым днем конкуренция за инвестиции в ИИ будет только нарастать.

DeepSeek не останавливается — 27 января они представили мультимодальную модель Janus-Pro-7B, которая работает с текстом и изображениями и конкурирует с DALL·E 3, SDXL и SD3-Medium. Бесплатно попробовать генерацию можно на Hugging Face.
Как DeepSeek-R1 справляется с задачами на программирование
Давайте проверим, как R1 справляется с задачами уровня Master на CodeWars на Python, C++ и Rust.
Python
Напиши функцию на Python, которая заменяет все буквы строки на их позиции в алфавите (например, "a" = 1, "b" = 2 и так далее). Игнорировать все символы, не являющиеся буквами. Например, для строки "The sunset sets at twelve o' clock." результат должен быть: "20 8 5 19 21 14 19 5 20 19 5 20 19 1 20 20 23 5 12 22 5 15 3 12 15 3 11".
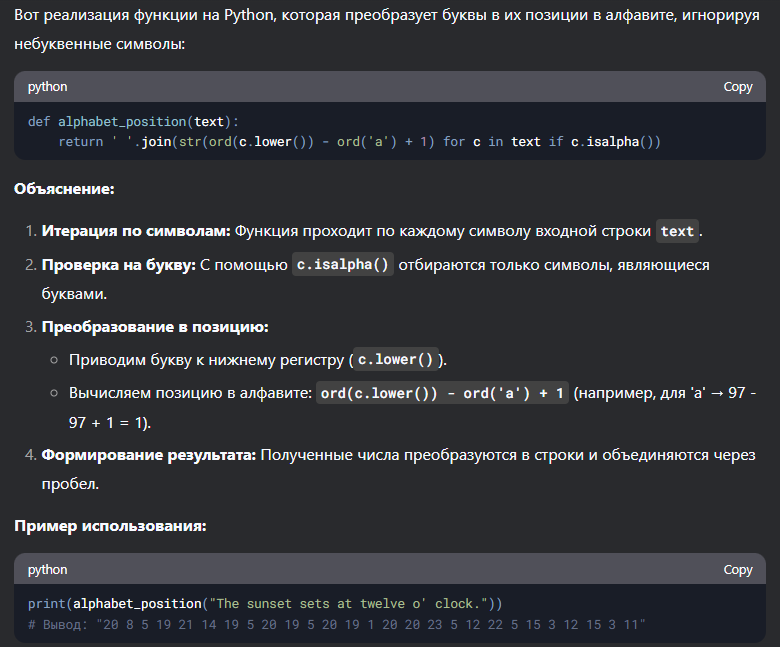
Рассуждения заняли 39 секунд. DeepSeek предоставила код, объяснения и пример использования. Решение работает правильно: игнорирует все символы, которые не являются буквами, и правильно заменяет каждую букву на её позицию в алфавите. R1 предлагает методы isalpha(), ord() и lower(), что оптимально для данной задачи. Решение компактное, читаемое и эффективно даже для длинных строк.
С++
Напиши код на C++ так, чтобы он возвращал true, если первый переданный аргумент (строка) заканчивается вторым аргументом (также строкой). Примеры: solution('abc', 'bc') // returns true, solution('abc', 'd') // returns false
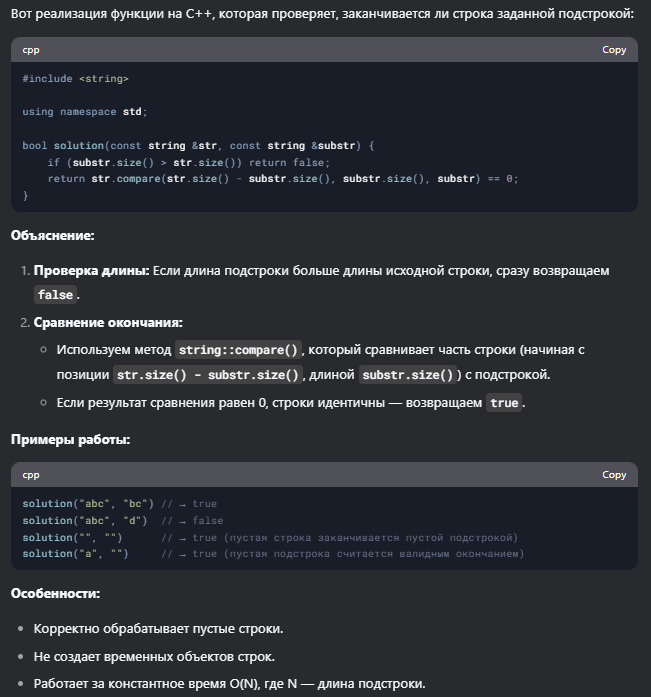
Решение DeepSeek выглядит грамотным, эффективным и правильно обрабатывает все крайние случаи, а именно пустые строки. Использование string::compare() для проверки окончания строки — хорошая практика, так как метод быстро выполняет сравнение фрагментов строк. R1 правильно оценила проблему и предложила оптимальное решение.
Rust
Реши на языке Rust: You live in the city of Cartesia where all roads are laid out in a perfect grid. You arrived ten minutes too early to an appointment, so you decided to take the opportunity to go for a short walk. The city provides its citizens with a Walk Generating App on their phones -- everytime you press the button it sends you an array of one-letter strings representing directions to walk (eg. ['n', 's', 'w', 'e']). You always walk only a single block for each letter (direction) and you know it takes you one minute to traverse one city block, so create a function that will return true if the walk the app gives you will take you exactly ten minutes (you don't want to be early or late!) and will, of course, return you to your starting point. Return false otherwise. Note: you will always receive a valid array containing a random assortment of direction letters ('n', 's', 'e', or 'w' only). It will never give you an empty array (that's not a walk, that's standing still!).
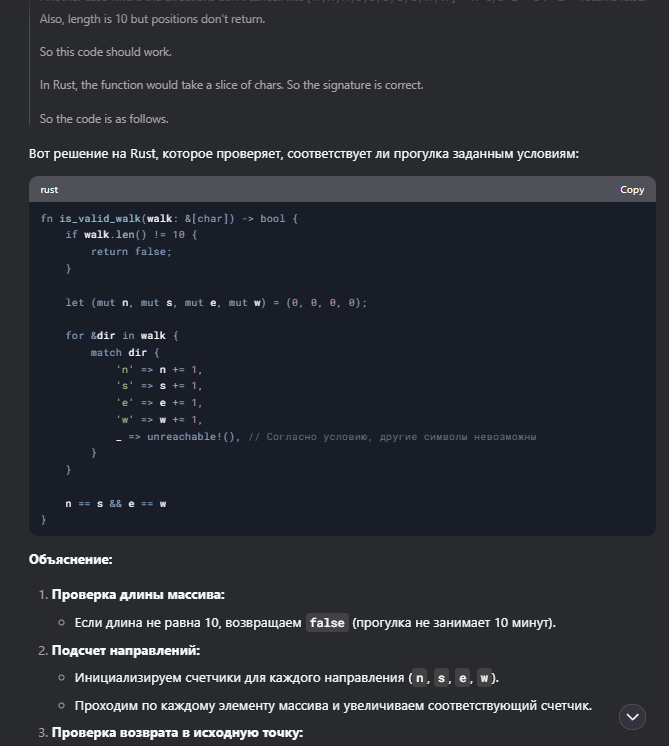
Интересно, что несмотря на то, что условия задачи были отправлены на английском языке, модель R1 продолжила рассуждать на английском, но итоговое решение было представлено на русском. Решение от DeepSeek на Rust корректно проверяет, соответствует ли прогулка заданным условиям. Код использует одну итерацию по массиву и обеспечивает обработку ошибок с помощью unreachable!(), что исключает недопустимые символы в массиве.
Coding-бенчмарки
Не будем обсуждать все метрики, но из бенчмарков можно выделить парочку, заслуживающих внимания:
- На Codeforces модель выдаёт 96.3%, что практически недостижимо для большинства людей.
- В LiveCodeBench (Pass@1-COT) DeepSeek R1 показывает 65.9%, что тоже является достойным результатом для модели: уверенное решение кода и пошаговые рассуждения.
Оправдан ли хайп и стоит ли переходить на DeepSeek
- Бесплатно ≠ безопасно. Как верно заметили в Wired, за «халявный» ИИ вы платите своими данными. DeepSeek собирает запросы, анализирует паттерны и, возможно, даже тренируется на наших данных. Китайская юрисдикция добавляет скепсиса: куда утекает информация — большой вопрос.
- Бенчмарки vs реальность. Автор канала Neural Shit Андрей Клименко напомнил, что бенчмарки больше не показатель. Хотя DeepSeek R1 демонстрирует хорошие результаты по числовым показателям, реальная производительность зависит от конкретной задачи. Поэтому лучший способ оценить модель — потестить её самому, если не пугают риски с данными и хочется сэкономить на API.
- Креативит, но иногда чудит. В процессе тестирования редакция Tproger заметила, что R1 вполне способна на креатив и даже иронию, но иногда теряется и галлюцинирует при сложных запросах. При работе с текстовым документом среднего размера (около 25 страниц) модель наотрез отказалась выполнять запросы, выдав сообщение «server is busy». В общем, результат иногда удивляет далеко не в лучшем смысле.
- Запаситесь терпением на случай даунтаймов: не всё так гладко с серверами. Порой они не выдерживают наплыва пользователей, и придётся подождать, пока всё наладится. Не идеально, но для бесплатного решения — терпимо.

DeepSeek-R1 стал, пожалуй, самым хайповым достижением китайских AI-компаний. Несмотря на ограниченный доступ к топовому железу, удалось создать конкурентоспособную и многообещающую модель, которая уже вызывает интерес у коммьюнити.
Как отметил CEO DeepSeek Лян Вэньфэн, будущее искусственного общего интеллекта (AGI) не за горами, и это случится при нашей жизни — может быть, через два, пять или десять лет.
А если вы интересуетесь искусственным интеллектом так же, как и мы — вы уже крут. Больше информации и интересных программистских инсайтов тут.

5К открытий19К показов

Кирилл Васильев, руководитель кластера кросс-функциональных команд в RuStore, рассказывает, как создать популярное приложение.

Промпт-инжиниринг — новый тренд в искусственном интеллекте и машинном обучении. Вместе с Даниилом Дранга, Head of AI Products and Data Science в Райффайзенбанке, разбираемся, что это за профессия, и изучаем продвинутый промптинг.
Пользователь сайта instructables с ником aaedmusa собрал робота, который справляется со сборкой Кубика Рубика за 5 секунд.
Составили подборку из 20 промптов, то есть запросов, для ChatGPT, которые могут быть полезны для работы в IT.