


Что такое ELK-стек и как он помогает в логировании и мониторинге приложений


Разбираемся, что такое ELK, зачем он нужен для логирования и мониторинга и какие у него есть особенности и преимущества.
7К открытий16К показов

Стек ELK — набор компонентов, который обеспечивает эффективное и удобное централизованное логирование с нескольких серверов. Логирование здесь — ведение журналов.
ELK — аббревиатура от Elasticsearch, Logstash, Kibana. Это названия опенсорс-проектов, которые разрабатываются и поддерживаются компанией Elastic.
Стек ELK позволяет быстро и безопасно извлекать данные в нужном формате из любых источников и работать с этой информацией в режиме поиска, анализа или визуализации в режиме реального времени. Специалисты часто называют стек «эластичным» — небольшая пасхалочка.
Зачастую журналы программных сервисов и приложений оказываются единственным средством, с помощью которого можно найти источник проблем, однако после монтажа и настройки о журналах просто забывают. Такой подход в современной разработке недопустим: развертывание и сопровождение продуктов требуют более ответственного отношения — нужны опции для мгновенного поиска нужных данных. С этой задачей системы сбора и анализа журналов справляются максимально эффективно.
Узнаем, что собой представляет ELK-стек, как он работает, каковы его преимущества и как правильно настроить настроить и оптимизировать этот программный инструмент.
Из чего состоит ELK-стека
Существуют разные способы формирования структуры данных в памяти устройства, стек — один из основных вариантов. В таких системах используется последовательный способ хранения с линейной связью. Данные хранятся в строгом порядке, и эту последовательность нельзя нарушить.
Извлечение данных происходит по принципу «пришел последним, вышел первым» по аналогии с пассажирами в вагонах метро — кто заходит позже других, вынужден выходить на остановке первым. По такому принципу работают все стеки.
Программный продукт ELK-стек — это связка из приложений Elasticsearch, Logstash, Kibana, а также Filebeat (доставщик лог-сообщений, отвечающий за мониторинг и сбор данных и их пересылку).
С помощью стека разработчики без труда собирают журналы всех систем и приложений, анализируют их и создают визуализацию. Это необходимо, чтобы мониторить продукты и инфраструктуру, быстро устранять неполадки, тестировать систему безопасности и проделывать другие операции с данными. ELK-стек предоставляет все необходимые сведения об обслуживаемой системе, выполняет свою работу оперативно и наглядно.
Рассмотрим в подробностях каждый из компонентов ELK.
Elasticsearch
Основа стека ELK. В техническом плане это распределенная RESTful-система (инструмент для взаимодействия веб-приложений и серверов) на базе JSON — текстового формата для обмена данными, созданного на JavaScript. Компонент Elasticsearch сочетает в себе функции базы данных NoSQL, поисковика и системы аналитики.
Изначально инструмент разрабатывался как поисковая утилита библиотеки Apache Lucene с дополнительными возможностями в виде репликации, масштабирования и некоторых других опций. Эта многофункциональность плюс простота применения и повышенная производительность сделали Elasticsearch крайне удобным инструментом для проектов с высокой нагрузкой, массивами данных и усложненными поисковыми системами.
Постепенно инструмент стал использоваться не только для реализации внутреннего поиска на сайтах, но и для разработки систем централизованного хранения логов и оперативной аналитики. Благодаря разнообразной функциональности решение стало востребованным во многих направлениях, что привлекло внимание разработчиков из самых разных сфер ИТ. Вокруг ES сформировалось компетентное сообщество — специалисты всегда помогут настроить кластер для решения любых задач.
Статус Elasticsearch в настоящий момент — обширное, быстродействующее, масштабируемое хранилище с функциями поисковика и анализатора журналов. Мощность, простота, документация JSON, поддержка всех актуальных языков программирования и геолокации — все эти достоинства позволяют системе в скоростном режиме работать с большими массивами данных, индексировать логи по мере их поступления и реализовывать запросы в онлайн-формате.
В коммерческих проектах разработчиков Elasticsearch решает следующие задачи:
- агрегирует данные любого формата и объема с различных площадок (например, информацию о товарах из множества онлайн-магазинов), выполняет фильтрацию и поиск по заданным свойствам продуктов;
- шардирует (разделяет) данные и распределяет их на автономные хосты для экономии места, при этом группы автоматически выравниваются для соблюдения баланса;
- обрабатывает данные из множества онлайн-опросников и анкет;
- оперативно вычисляет заданные параметры в массивах данных, собранных из разных систем — такие задачи важны в комплексной аналитике бизнес-процессов;
- анализирует обширные объемы неструктурированных статистических данных;
- хранит информацию и управляет записью с помощью API.
Можно назвать Elasticsearch распределенным поисковым движком, который используется для широкого круга задач в рамках аналитики, поиска, распределения и хранения данных. Установить его проще всего через Docker.
Logstash
В стеке ELK Logstash выступает в роли конвейера для парсинга — автоматизированного сбора и структурирования данных (в нашем случае логов событий), которые приходят из многих источников, с целью их обработки и последующего применения в Elasticsearch.
Эта утилита с открытым кодом позволяет выделять отдельные поля с их значениями в сообщениях о системных событиях, распределять данные с помощью фильтров и редактировать их. Настройка выполняется через конфигурационные файлы.
В системе Logstash очередность событий разделяется на три фазы:
- Input. Журналы передаются для обработки в машинно-понятный формат. Можно установить последовательность чтения файлов из папок, путь и протокол для извлечения логов.
- Filter. Поле управления сообщениями, приходящими на Logstash. Здесь задан набор условий для выполнения конкретных действий или событий. Настраивается также парсер логов — можно редактировать значения, добавлять и удалять новые параметры.
- Output. Фаза настройки места, куда будет отправлен обработанный лог. Если непосредственно в Elasticsearch, потребуется документальный запрос. Если это дебаг (код для исправления ошибки), он просто записывается в файл.
Задача Logstash — централизованная и оперативная обработка обширного объема событий, различных данных со структурой и без нее. Чтобы подключаться к разным способам ввода, утилита использует более 200 плагинов для упрощения доступа.
Через Logstash данные из источников поступают в Elasticsearch. По пути они могут быть преобразованы в нужный формат. Встроенные фильтры и модули обеспечивают юзерам простой и быстрый доступ к данным независимо от их типа.
На GitHub в свободном доступе находится более 20 моделей — высока вероятность, что там уже есть именно тот инструмент, который подойдет для настройки нужного вам конвейера данных. Если такого модуля нет, вы без особого труда сможете создать его самостоятельно. Как и ES, Logstash можно установить и запустить в Docker.
Kibana
Этот компонент представляет собой веб-панель (пользовательский интерфейс) для взаимодействия с логами. Он отвечает за визуализацию проиндексированных данных в Elasticsearch в формате графиков и разного рода диаграмм. Благодаря гибким настройкам мониторинга с помощью Kibana можно путешествовать по ELK-стеку, отслеживая маршруты, по которым запросы проходят через конкретное приложение.
Инструмент подходит для сложного анализа данных и визуализации этого процесса, а также для администрирования баз данных. Есть возможность контролировать несколько панелей мониторинга с сохранением настроек для каждой из них.
Есть несколько методов поиска по данным Кибана в режиме реал-тайм:
- текстовый поиск определенной строки;
- поиск в формате поля;
- логические матрицы для объединения нескольких поисков;
- поиск близких по смыслу терминов.
В Kibana интуитивно понятные схемы и аналитические отчеты, которые можно применять для интерактивной навигации. Можно динамически перемещать созданные окна, играть с масштабом подмножеств и максимально детализировать отчеты.
Как работает ELK-стек
Elasticsearch занимается хранением и поиском данных, Logstash обрабатывает, фильтрует и структурирует логи, в Kibana визуализирует поисковые операции и занимается администрированием.
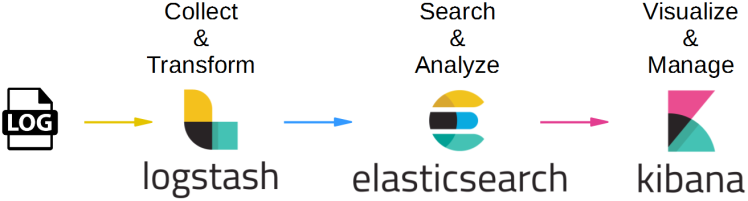
Все три компонента расположены на сервере пользователя, который выполняет функцию клиента. За логами следит доставщик Filebeat, он же пушит логи в Logstash. Последний компонент выполняет с логами определенные манипуляции и помещает их в нужный столбец таблицы Elasticsearch. Далее с помощью визуализации Kibana пользователь с легкостью ищет нужные события.
Функционал стека ELK довольно широк — это аналитика журналов, поиск нужных файлов, контроль информации и безопасности, наблюдение за работой приложения. Это эффективный поисково-аналитический инструмент, который удовлетворяет все потребности разработчиков, инженеров и аналитиков в сфере работы с журналами.
Поскольку значительная часть инфраструктуры в ИТ сегодня перемещена в публичные облачные структуры, разработчикам нужны действенные решения для управления журналами, с помощью которых можно мониторить структуру приложений, обрабатывать журналы и данные навигации.
Стеком пользуются не только разрабы, но и инженеры DevOps (актуальная концепция непрерывной разработки). Специалисты получают полезную информацию, выполняя диагностику сбоев, аналитику производительности софта и мониторинг инфраструктуры.
Настройка и применение ELK-стека на практике
Есть несколько способов установки стека ELK в разных ОС и средах. Это делается локально, в облачных сервисах, через Docker и системы управления конфигурацией. Рассмотрим универсальные этапы установки на примере ОС Linux.
Для развертывания понадобятся определенные системные ресурсы: около 10 Гб памяти и примерно столько места на жестком диске. Для Elasticsearch и Logstash потребуется Java 8. А еще нужно заранее установить агент Filebeat — сейчас он стал неотъемлемой частью экосистемы ELK.
Основные этапы развертывания:
- Установка Filebeat из отдельных пакетов, репозитория или через Docker Compose.
- Установка Elasticsearch. Этот этап довольно простой и быстрый благодаря готовым пакетам — есть версии для всех востребованных операционных систем. Потребуется скачать публичный ключ репозитория и подключить Elasticsearch.
- Настройка ES. Все необходимые настройки находятся в специальном файле. Промежуточные результаты можно наблюдать на локальном интерфейсе.
- Очистка индексов в ES. Это автоматический процесс, за который отвечает встроенный инструмент Index Lifecycle Policies. Его тоже можно настроить под конкретные задачи.
- Установка Kibana. Есть пакеты и репозиторий для всех популярных платформ.
- Настройка Kibana. Все нужные параметры находятся в специальном файле. Не забудьте настроить безопасность и авторизацию.
- Установка Logstash. Компонент устанавливается из того же репозитория, что и Elasticsearch и Kibana.
- Настройка Logstash. Конфигурационные файлы для настройки находятся в соответствующих файлах. Фильтры можно расположить на свое усмотрение.
В качестве наглядного примера использования стека ELK можно привести банковские сервисы, которые делают по требованию клиентов выписки по счету в личных онлайн-кабинетах. Пользователи могут выполнить полнотекстовый гибкий поиск по транзакциям. Такая опция реализована, в частности в веб-приложении Альфа-Банке.
ELK используют и многие другие компании, среди которых Mozilla, GitHub и Netflix. Везде, где нужно работать с Big Data, разработчики отдают предпочтение Elastic, поскольку он закрывает большинство потребностей по поиску, обработке и аналитике.
В чем преимущества использования ELK для мониторинга
В цифровом мире данные отвечают за всё, и их становится все больше. Это значит, что решения для обработки данных должны постоянно эволюционировать. В такой ситуации стек ELK делает работу с данными проще и улучшает качество аналитики.
Перечислим все плюсы ELK:
- способен быстро и без последствий для системы извлекать, обрабатывать, анализировать данные и визуализировать их независимо от формата;
- позволяет вести журнал из одного центра, отслеживать все проблемы в приложении и на серверах, сравнивать журналы на разных серверах и делать выводы;
- прост и удобен в настройке и использовании, доступен для освоения начинающим ИТ-специалистам;
- в набор компонентов входят программные продукты с открытым исходным кодом;
- предоставляет гибкие поисковые фильтры, в том числе для работы с азиатскими языками;
- встроенные преобразователи текста выполняют токенизацию, леммматизацию и другие преобразования контента в соответствии с задачами пользователя;
- стек можно развернуть в любых масштабах независимо от технической структуры компании;
- для решения характерна стабильность, отказоустойчивость и надежность — данные при сборе не теряются и не исчезают;
- большой выбор настроек под конкретные задачи проекта;
- есть официальные клиенты с профессиональной поддержкой, предоставленные разработчиками на востребованных языках программирования;
- стек универсален и подходит для работы с СУБД, файлами любого типа, приложениями и другими данными;
- контейнер для загрузки компонентов стека есть на Docker.
Но эксперты отмечают и недостатки:
- В ELK нет встроенной опции авторизации с управлением правами доступа. Это потенциальная проблема с информационной безопасностью. Базу данных нужно в обязательном порядке защищать паролем, поскольку движок по умолчанию можно открыть через любые интерфейсы.
- Масштабирование в некоторых проектах требует значительных ресурсов и может оказаться нерентабельным.
- Размеры индексов могут превысить лимиты хранилища узла, индексация начинает сбоить — есть риск потери данных.
При этом установка и грамотный запуск стека — довольно ответственный и непростой процесс. Организациям, у которых нет собственных специалистов, придется нанять сотрудника со стороны, который будет управлять развертыванием.
Итоги
Годы практики и активное комьюнити создали из ELK перспективный многофункциональный инструмент, у которого нет достойной альтернативы. Стек ELK широко используется для мониторинга производительности приложений, поиска аномалий и ошибок в системе, выяснения причин багов и дефектов с целью их устранения на программном уровне.
Это современное решение позволяет инженерам и разработчикам настраивать мониторинг динамических сред с распределением и выполнять профессиональную аналитику. ELK — мощная платформа, которая умеет собирать данные из разных источников, помещать в централизованное хранилище и обрабатывать. По мере роста базы систему легко масштабировать, а многие трудности при настройке решаются через привлечение активного и доброжелательного сообщества.

7К открытий16К показов

Расскажем о том, как можно начать работать в сфере ИИ. Если вы уже работаете в IT, но хотите расширить карьерные и финансовые возможности, читайте материал.

Intel выяснила, что половина современного кода — open-source зависимости. Компания предупреждает: индустрия утопает в уязвимостях

Рассказываем, как push-уведомления помогают бизнесу доставлять пользователям сообщения с 99.9% вероятностью и как работают изнутри.

Госзаказ больше не про папки и беготню: цифровизация и ИИ изменили работу закупщика, автоматизировали рутину и открыли рынок для малого бизнеса. Что происходит с профессией — в материале с кейсами.