


Путешествие в golang regexp

В этой статье мы рассмотрим инструмент, с помощью которого можно прорываться через мусор в тексте — регулярные выражения в Golang.
50К открытий64К показов

Маргарита Гавриленко
Разработчик NGR Softlab
Приветствую всех, принадлежащих к клубу «Тыжпрограммист, почини утюг», а также просто интересующихся IT-миром!
В этой статье мы рассмотрим инструмент, с помощью которого можно прорываться через мусор в тексте. А также фильтровать контент и названия файлов, отлавливать запрещённые/разрешенные команды, парсить SQL-запросы и выпендриваться перед коллегами. Это регулярные выражения ?
Все примеры описаны для языка Golang, однако общие принципы, синтаксис самих регулярных выражений применимы и к других языкам программирования.
В начале было слово…
И слово это – паника. Давайте сперва запомним, как надёжней начинать работу с регулярными выражениями. Рассмотрим простейший пример:
Запустив сей код легким мановением руки… получим то, что всей душой ненавидят пишущие на golang люди — панику. Дело в том, что MustCompile паникует вместо возврата ошибки, как это сделано, например, в методе Compile из того же пакета.
Поэтому MustCompile рекомендуется использовать только в тех случаях, когда:
- вы на 100% уверены, что регулярное выражение валидно;
- вы очень хотите упростить код с инициализацией каких-нибудь глобальных переменных.
В остальных случаях лучше подойдёт вариант с возвратом ошибки.
Простой пример проверки соответствия (который можно скопировать и поломать):
Общая информация
- Немного общих сведений о регулярных выражениях в Golang (regexp пакет):
- синтаксис RE2 (библиотека регулярок от Google);
- кодировка UTF-8 и классы символов Unicode;
- время выполнения линейно зависимо от размера ввода;
- обратные ссылки не поддерживаются (не думайте об этом, просто положите на полочку в своих «чертогах разума», чуть позже будет объяснение);
- для регулярных выражений лучше использовать (аккуратно, ведь там своя специфика) необработанные строки (raw strings, строки без интерпретации экранированных литералов).
А теперь приступим к более подробному разбору темы.
Простые совпадения

Простые совпадения не несут в себе никакого тайного смысла. Что написано – то и ищем.
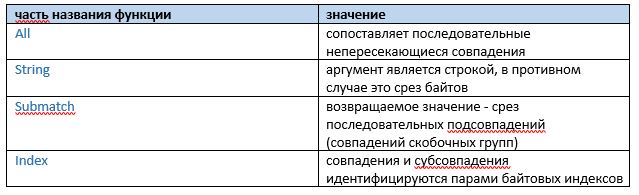
В дальнейшем в простых примерах будем использовать функции:
- MatchString (проверяет, есть ли в строке вхождения регулярного выражения);
- FindAllString (ищет все последовательные непересекающиеся повторения в
строке).
Регулярные выражения будут выделяться синим цветом, а комментарии — серым для создания качественных нейронных связей в голове читателя.
Совпадение не полное, в последнем слове лишняя «t».
«Banana» полностью совпадает со строкой.
«сat» встречается в строке.
Находятся два вхождения.
Якори границ
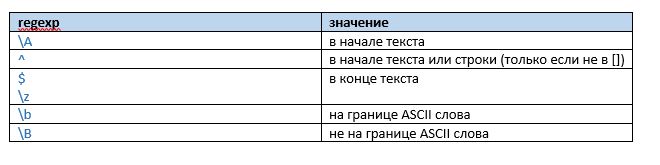
Якори границ позволяют нам делить текст на отдельные слова, явно задавать привязку к началу или концу строки/текста.
Ищем текст, начинающийся с «I am here», но есть пробел перед «I» – не подходит.
Ищем строку, состоящую только из кота — но он в середине.
Ищем кота отдельным словом — находим.
Ищем что-то, заканчивающееся котом — находим.
Классы символов (воин, маг, лучник)
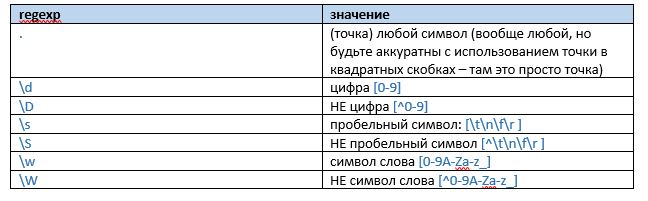
Классы — это краткая запись перечисления символов, объединённых по какому-либо признаку. Также можно использовать posix классы ([:digit:], [:space:], etc.), если так удобней.
Ищем вхождение пяти любых символов.
Ищем вхождения сочетаний: «ow<цифра><конец слова>» через два символа слова с начала строки, любой символ, затем две НЕ цифры, затем снова «ow», цифра, конец.
Ищем начало текста, три любых символа, «@_», два символа слова, «D», конец.
Ищем начало текста, «GO», один пробельный символ, одну цифру, любой символ, две цифры, конец.
Специальные символы и escape

Что нужно знать про специальные символы:
- список спецсимволов: ^ $ * + ? { } [ ] \ | ( )
- их нужно экранировать с помощью `\`, т.е. `\+` = просто +
Ищем «I» в начале текста, перенос, «am», перенос, «here», конец текста.
Ищем «I» (в виде 16-ричного кода символа), в начале текста, перенос, «am», перенос, «here», конец текста.
Ищем… не «a+b=c», а одно и более повторение «a», «b=c», ибо «+» не экранирован.
Ищем «a|b=c», символ «|» экранирован, всё в порядке.
Повторение (жабное, не жабное)
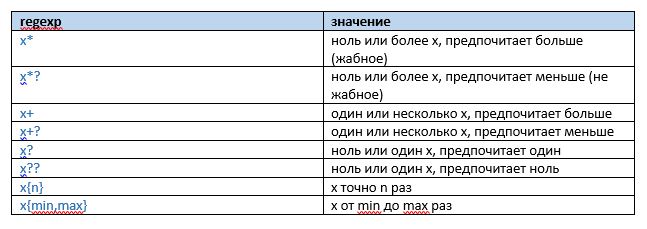
Повторения являются, пожалуй, одной из важнейших фич при работе с регулярными выражениями. Как минимум, из-за того, что дают возможность исключать некоторые подвыражения из обязательных (при использовании?). ЖаБным оно стало в связи со случайной опечаткой и осознанием, что так запоминается лучше.
Ищем все вхождения чисел из одной и более цифр.
Ищем начало текста, одно повторение «А», от одного до 3 повторений «G», одно и более повторение «А», от 0 до 2 повторений «!».
Пытаемся найти все вхождения тегов — из-за жадного повторения получаем весь текст как первое вхождение, ибо весь текст также соответствует выражению <.*> — начинается скобкой, дальше имеет 0 и более любых символов, заканчивается скобкой.
Пытаемся найти все вхождения тегов, используя не жадное повторение — происходит магия, все срабатывает.
Квадратные скобки, ИЛИ и НЕ
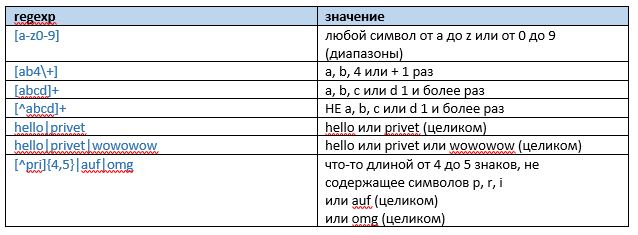
Квадратные скобки эквивалентны перечислению (перечислению с отрицанием при использовании ^). Прямая черта | равнозначна набору альтернативных вариантов из слов. Крышечкой ^ обозначается отрицание при использовании внутри квадратных скобок.
Ищем либо «good», либо «bad», либо один символ в конце текста, не являющийся пробельным, «i», «c» или «e».
Ищем начало текста, ноль или более (лучше меньше, не жадное повторение) символов из перечня [a, A , u , U , f ,F], «go» или «python», пробел, от одной до трех цифр, точку, одну цифру и конец текста).
Ищем начало текста, один и более символов из перечня [h, a, H, A], конец текста.
Ищем начало текста, один и более символов из перечня [h, a, H, A] либо ноль и более символов из перечня [g, o, G, O], конец текста – пустая строка соответствует второму варианту после прямой черты.
Группы
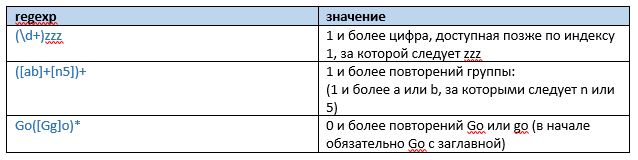
Важное о группах:
- позволяют поместить часть совпадения в отдельный массив;
- квантификатор после скобок группы применяется ко всей группе (под квантификаторами подразумеваются такие товарищи, как: +, *, {min, max}, etc.);
- группа 0 всегда относится ко всему выражению;
- группа 1 — к подвыражению, начинающемуся с “(“ и заканчивающемуся “)” (и так далее);
- при повторении группы в качестве «группы 1» берется последнее совпадение.
В примерах некоторые элементы подчеркнуты. Это не баг, это фича, помогающая увидеть, какой элемент в какой список групп попал. Также используется новая функция — FindAllStringSubmatch — возвращающая срез последовательных непересекающихся подсовпадений (совпадений скобочных групп). Вторым параметром в данной функции является ограничение количества найденных подсовпадений (найдется всё, если использовать -1).
Тема групп совсем не проста, поэтому пробуйте разное, ломайте, дебажьте.
Ищем все подсовпадения с выражением «любой символ, одна и более цифра», находим три вхождения, в каждом из которых есть группа 0 – всё вхождение целиком – и группа 1 – часть с «одна и более цифра».
Выделяем год, месяц и день в отдельные группы, ищем (4 цифры), тире, (2 цифры), тире, (2 цифры). Получаем одно подсовпадение, где группа 0 — вся дата, группа 1 — год, группа 2 — месяц, группа 3 — день.
Парсинг дат в разных форматах может быть использован в кейсах, когда нам необходимо, например, сделать предположение о возможном содержимом столбцов с данными из стороннего датафрейма и выделить колонки с. временными метками. Реализация без регулярных выражений будет достаточно неудобна.
Как ни странно, в группе может быть внутренняя подгруппа (а в ней ещё одна…и ещё…). Здесь мы ищем ноль и более (лучше меньше) любых символов, одно и более повторение символа из перечня [a-zA-Z\-0-9], слэш, любой символ, 2 и более повторения символов из перечня [a-zA-Z]. В итоге находим одно вхождение, где группа 0 – все выражение, группа 1, как внешняя, целиком соответствует части «одно и более повторение символа из перечня [a-zA-Z\-0-9], слэш, любой символ, 2 и более повторения символов из перечня [a-zA-Z]», а группа 2 – части «одно и более повторение символа из перечня [a-zA-Z\-0-9]».
Вспоминается мем (в нём, кстати, есть мааленькая опечатка :), кто отыщет?):

С группами, как и с математическим анализом, нужно сесть, поплакать, хорошо разобраться один раз и работать на автомате в дальнейшем…
Именованные и необязательные группы

Еще один факт о регулярных выражениях в Golang:
- обратных ссылок тут нет (!) (запоминание встретившейся группы для повторного использования в том же выражении).
Иногда этот факт вызывает головную боль.
В примерах используется новая вспомогательная функция — SubexpNames — позволяющая получить доступ к списку разделённых по названию групп подсовпадений.
Пытаемся выловить из мусорного текста дату, разделив её на год, месяц, день. В группу Year попадают первые 4 цифры до тире, группу Month — 2 цифры до следующего тире, Day — последние 2 цифры. Доступ к разделенным по названиям групп подсовпадениям получаем при помощи прохождения по re.SubexpNames()
Ищем go либо Go (группа, которая не попадает в список подсовпадений благодаря ?: после открывающей скобки группы), py либо Py — находим два подсовпадения, где группа 0 — вхождение целиком, группа 1 – вторая группа
(которая «py либо Py»).
Другие функции для работы с регулярными выражениями
Формула функций работы с регулярными выражениями:
Также рассмотрим несколько иных функций на примерах.
Дальше будет сложно. Слабонервным рекомендуется закрыть статью, отойти от экранов и уехать жить в Лондон (почему бы и нет).
Большие примеры с кейсами применения регулярных выражений
Валидация логина:
Фильтрация трафика syslog (привет работающим с logstash и его фильтрами):
Парсинг имен таблиц и баз данных, к которым идет обращение, из SELECT SQL-запроса:
Маленькое заключение
Регулярные выражения — достаточно полезная штука при анализе текста, парсинге потокаданных, когда необходимо вытащить оттуда нечто действительно важное…ну и вообще для всякого рода магии ?
Разбирайтесь, не бойтесь экспериментировать и развлекайтесь!

50К открытий64К показов