


Почему Python хорош для Data Science и разработки приложений

Рассказываем, в чём преимущества Python перед низкоуровневыми языками и чем он полезен в Data Science.
17К открытий17К показов
Дизайн любого языка программирования предполагает компромисс. Низкоуровневые языки трудны в освоении, требуют от программиста многое делать вручную, зато позволяют проводить гибкую оптимизацию кода и обеспечивать быстродействие. Высокоуровневые языки позволяют решать те же задачи более удобным и простым способом, но имеют меньше способов и инструментов для оптимизации. Одним из таких языков является Python. В Дирекции больших данных X5 Retail Group рассказали, в чём его преимущества перед низкоуровневыми языками и для каких задач его используют в компании.

Петр Пушкарёв
ведущий разработчик Дирекции больших данных X5 Retail Group
Дирекция больших данных X5 Retail Group существует уже больше двух лет. В ней работают специалисты по Data Science, которые обрабатывают массивы данных о покупателях и товарах, а также разработчики, которые создают программные продукты для работы с большими данными.
Когда мы только запускались, перед нами встал вопрос об инструментах, прежде всего о языках программирования. Первым желанием было взять самые совершенные средства, например Java — универсальный, производительный, постоянно развивающийся и крайне популярный язык. Однако значительная часть наших задач просто не требовала настолько навороченного инструмента. К тому же Java достаточно сложен в освоении, и для наших DS-специалистов, которые больше аналитики и математики, чем программисты, он мог стать проблемой. Нам нужен был язык, который был бы одинаково удобен для всей дирекции, поэтому мы обратили внимание на Python.
Сильные стороны
Чем Python хорош для команды, в которой есть как разработчики, так и специалисты по Data Science? Перечислю свойства этого языка, за которые мы выбрали его для наших задач.
Высокая продуктивность разработки
Язык интерпретируемый, поэтому на нём можно писать быстрее, чем, например, на C. Неявная, но строгая типизация обеспечивает меньший объём кода для решения задач, чем в Java. А лаконичный и ясный синтаксис позволяет быстро писать читабельный код. Для человека, знающего C или Java, Python вообще понятен интуитивно.
Сравните, как выглядит одна и та же функция, написанная на Java и на Python:
расчёт факториала на Java:
расчёт факториала на Python:
Низкий порог входа для изучения
То, что Python широко используется в области Big Data, частично связано со скоростью его освоения. Потребность в анализе данных чаще всего возникает у тех, кто управляет бизнесом — аналитиков, экономистов. Осваивать тяжеловесные языки типа Java или C им нецелесообразно — в отличие от Python, который можно изучить довольно быстро.

«Интерактивность» языка (расчёты без компиляции)
Аналитики также ценят Python за то, что благодаря встроенному интерпретатору он позволяет кодировать на ходу. В Data Science это актуально для проверки гипотез в интерактивном режиме.
Интегрированные возможности для оптимизации исходного кода
Для разработчиков встроенный интерпретатор тоже может быть полезен: так как Python предлагает неявную и динамическую типизацию данных, оценить степень оптимизаций можно только в процессе исполнения кода, для чего и пригодится интерпретатор. Он переводит исходный код в машинные инструкции, которые могут подсказать идею для оптимизации. Например, сравнив две инструкции, можно понять, почему одна работает быстрее, чем другая. Это важное преимущество для работы с Big Data, потому что помимо анализа данных здесь много работы по улучшению алгоритмов их обработки.

Динамичное развитие языка
Ещё одним аргументом в пользу Python для нас стало то, что этот язык быстро и интенсивно развивается. С каждой версией производительность языка повышается, а синтаксис совершенствуется. Например, в версии 3.8 появился новый walrus оператор — :=, что для любого языка достаточно серьёзное событие. В низкоуровневых языках типа C++ или Java темп изменений заметно ниже — их утверждает специальная комиссия, которая собирается раз в несколько лет. В Python процесс стандартизации более открыт для комьюнити, каждый может предложить свои идеи, и их количество быстро растёт.
Необходимость командной проработки решений
Особенности Python делают его интересным инструментом для командной разработки. Из-за того, что интерпретатор языка скрывает детали низкоуровневых машинных вычислений, разработчикам требуется подробнее обсуждать и вникать в детали проекта.
Например, когда на Java разработчик определяет тип возвращаемого значения функции, и происходит какая-то проблема с типом значения, программа просто не запускается. Программа на Python может запуститься, но будет работать некорректно, если тип значения принципиально важен. Подобные проблемы может быть сложно найти на этапе разработки, так что это приходится обсуждать. Кому-то это обстоятельство покажется скорее минусом, но коллективное обсуждение часто помогает находить наиболее удачные решения. А ещё это позволяет разработчикам чувствовать себя причастными к общему делу, что позитивно влияет на мотивацию.
Возможность быстро расширять приложения новыми функциями
Как я уже сказал, кроме дата-инженерных у нас также есть задачи по разработке веб-приложений и микросервисов. Для них Python, возможно, не самый лучший выбор: в перспективе больших нагрузок и скорости сетевого взаимодействия он может быть менее продуктивен, чем компилируемый язык со статической типизацией. Но для web-приложений средней нагруженности и на этапе MVP Python более чем удобен ввиду того, что разработка новых фич занимает меньше времени.

Python в цепочке наших задач на примере
Приведу конкретный пример, где мы используем Python.
Бизнес-задача
Обеспечить регулярный сбор и анализ информации о покупателях наших торговых сетей. На основе этих данных мы можем сегментировать аудиторию, выделив у каждого покупателя особые характеристики (атрибуты) — например, его склонность совершать премиальные покупки. Таких атрибутов много, реализовать методологию их вычисления — это работа специалиста по Data Science, но с течением времени данные обновляются, и атрибуты необходимо рассчитывать регулярно, а значит — это следует автоматизировать.
Для этого мы разработали на Python систему, которая позволяет рассчитывать эти атрибуты с заданной периодичностью. Вычисление одного атрибута занимает 4–5 часов, при этом используются десятки терабайт данных. Основная сложность заключается в том, что нам необходимо дать регулярный доступ к этим данным другим департаментам компании, которые будут их использовать для построения всевозможных маркетинговых моделей и создания отчетов. Организовать доступ к результатам этих вычислениям само по себе — интересная техническая задача.
Решение
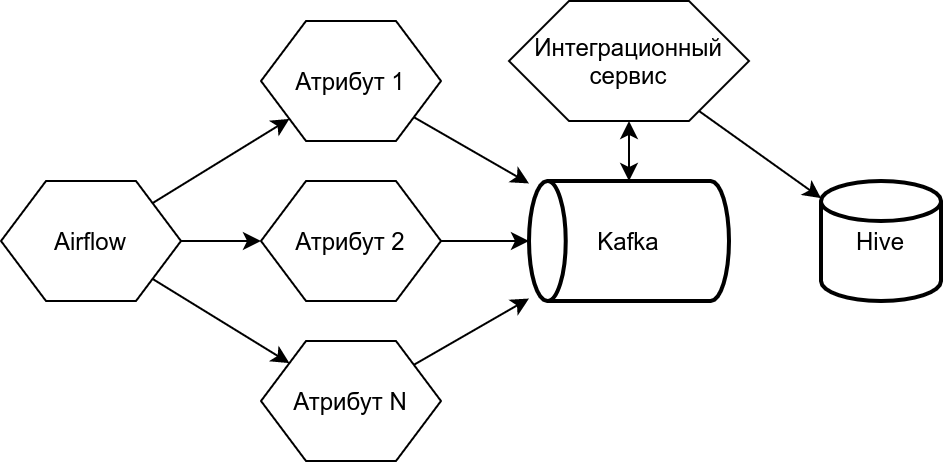
Сами вычисления у нас реализованы на основе PySpark фреймворка в экосистеме Hadoop. В качестве планировщика вычислений используется Apache Airflow. В основе разработанного сервиса лежит микросервисная архитектура, микросервисы оркестрируются через Kubernetes.
В этом ряду примечателен Apache Airflow — открытый инструмент планирования и мониторинга процессов обработки данных. Он написан на Python, что позволяет подключить к процессу работы с проектами не только разработчиков, но и дата-аналитиков. Они заняты ETL-задачами (Extract, Transform, Load), и Airflow для этого исключительно удобен, потому что позволяет просто описывать сложные пайплайны данных.

Были определённые трудности в том, чтобы подружить Airflow с Kubernetes. Airflow активно развивается, так что документация часто отстает от актуальной версии кода. Поддержка Kubernetes — относительно новая функция, так что многие нюансы удалось понять по коду и комментариям. А то, что Airflow написан на Python, оказалось очень кстати. Когда мало документации, крайне важно иметь возможность разобраться в коде, тем более реализация тех или иных функций может быть не всегда очевидна.
В целом, наш сервис состоит из двух частей: одна планирует расчёты посредством Airflow, а вторая отвечает за наполнение конечных витрин данными. Там с помощью брокера сообщений Kafka организован последовательный процесс наполнения витрин результатами расчётов, которые могут происходить параллельно. Обе части сервиса используют Python: в первой части это Airflow с пайплайнами, во второй — система интеграционных микросервисов.
Результат
Разработанная система позволяет автоматизировать и планировать регулярные расчёты 45 атрибутов покупательского поведения (часть рассчитывается раз в неделю, часть — раз в месяц). Объём данных, накопленных в результате этих расчётов за три года, составляет 4,5 терабайт, и другие департаменты компании имеют возможность легко обращаться к ним и использовать их для своей работы. При этом система ориентирована на расширение своих функций и реализацию новых.
Таким образом, Python позволяет решать самые разноплановые задачи. Он объединяет в проекте разработчиков и специалистов, для которых программирование не является профильным навыком — бизнес-аналитиков, дата-аналитиков, дата-сайентистов. Отлично подходит для Agile-разработки, для гибкой оптимизации. Для компании, у которой много разноуровневых задач и ведётся работа с большими данными, Python является отличным дополнением к компетенциям в низкоуровневых языках.

17К открытий17К показов

История перехода из медтеха в Python-разработку: как менторство помогло преодолеть сотни отказов и найти первую работу в IT. Советы по резюме, собеседованиям и выбору оффера от опытного наставника.

Комплименты — боль многих айтишников. Но не переживайте, мы в редакции решили эту проблему: теперь у вас есть готовый бот, который будет отправлять красивые вашей второй половинке. Показываем, как он выглядит.

Обзор лучших инструментов для оценки качества программного кода! Эксперты подготовили подробную статью о том, для чего необходимо проводить валидацию кода, и подобрали лучшие сервисы

Хакеры маскируют вирус под тестовое задание на LinkedIn: проект DLMind заражает ПК через GitHub-репозиторий и крадет данные разработчиков