Получение данных c веб-сайта без API в 3 строки кода на Python


Рассказываем о том, как можно сэкономить время и нервы при автоматизации процесса получения данных с веб-сайтов без соответствующего API-интерфейса.
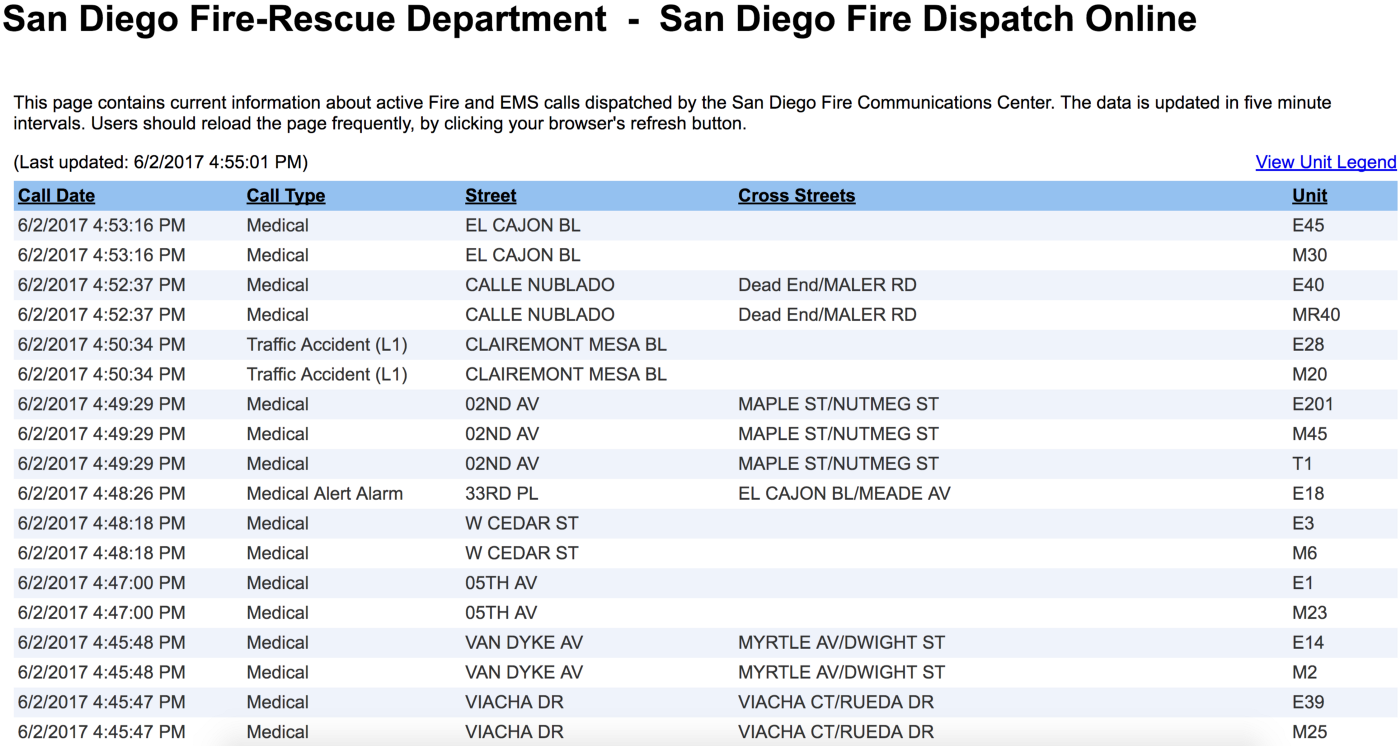
Предположим, что в поисках данных, необходимых для вашего проекта, вы натыкаетесь на такую веб-страницу:
{kind=link}
Вот они — все необходимые данные для вашего проекта.
Но что же делать, если нужные вам данные находятся на сайте, который не предоставляет API для их получения? Конечно же, можно потратить несколько часов и написать обработчик, который получит эти данные и преобразует их в нужный для вашего приложения формат.
Но есть и более простое решение — это библиотека Pandas и ее встроенная функция read_html(), которая предназначена для получения данных с html-страниц.
Прим. перев. В данной статье используется версия Pandas 0.20.3
Да, все настолько просто. Pandas находит html-таблицы на странице и возвращает их как новый объект DataFrame.
Теперь попробуем указать Pandas, что первая (а точнее нулевая) строка таблицы содержит заголовки столбцов, а также попросим ее сформировать datetime-объект из строки, находящейся в столбце с датой и временем.
На выходе мы получим следующий результат:
Теперь все эти данные находятся в DataFrame-объекте. Если же нам нужны данные в формате json, добавим еще одну строчку кода:
В результате вы получите данные в формате json с правильным форматированием даты по стандарту ISO 8601:
При желании данные можно сохранить в CSV или XLS:
Выполните код и откройте файл calls.csv. Он откроется в приложении для работы с таблицами:

И, конечно же, Pandas упрощает анализ:
Статистика запроса:
Группировку:
Результат группировки:
И обработку данных:
Результат метода unique:
Теперь вы знаете, как с помощью Python и Pandas можно быстро получить данные с практически любого сайта, не прилагая особых усилий. Освободившееся время предлагаем посвятить чтению других интересных материалов по Python на нашем сайте.

72К открытий72К показов

Поговорили с руководителями инженерных групп направления телекоммуникации КРОК: чем занимаются, о стажёрах и работе в команде.
Как поднять стенд микросервисов в Kunernetes из монорепозитория, чтобы быстрее зарелизить микросервисы на стенд для экспериментов.
Рассуждаем, почему и язык Ruby, и фреймворк Ruby on Rails до сих пор актуальны, почему они до сих пор живы и будут жить.

Сегодня мы поговорим про механизм диспетчеризации методов. Он существует в разных языках, но мы сделаем акцент именно на Swift.