


Работа с большими данными: введение в Apache Hadoop и Spark

Apache Hadoop и Apache Spark — две популярные платформы в сегменте обработки и анализа больших данных. В статье рассмотрим основы фреймворков, сравним преимущества, а также разберем сценарии оптимального применения на проекте.
5К открытий11К показов

Что такое Apache Hadoop?
Apache Hadoop — это платформа для хранения и работы с большими объемами данных. Ее преимущество заключается в распределении вычислений между множеством узлов. Hadoop разбивает большую задачу на много маленьких и решает их одновременно на разных компьютерах.
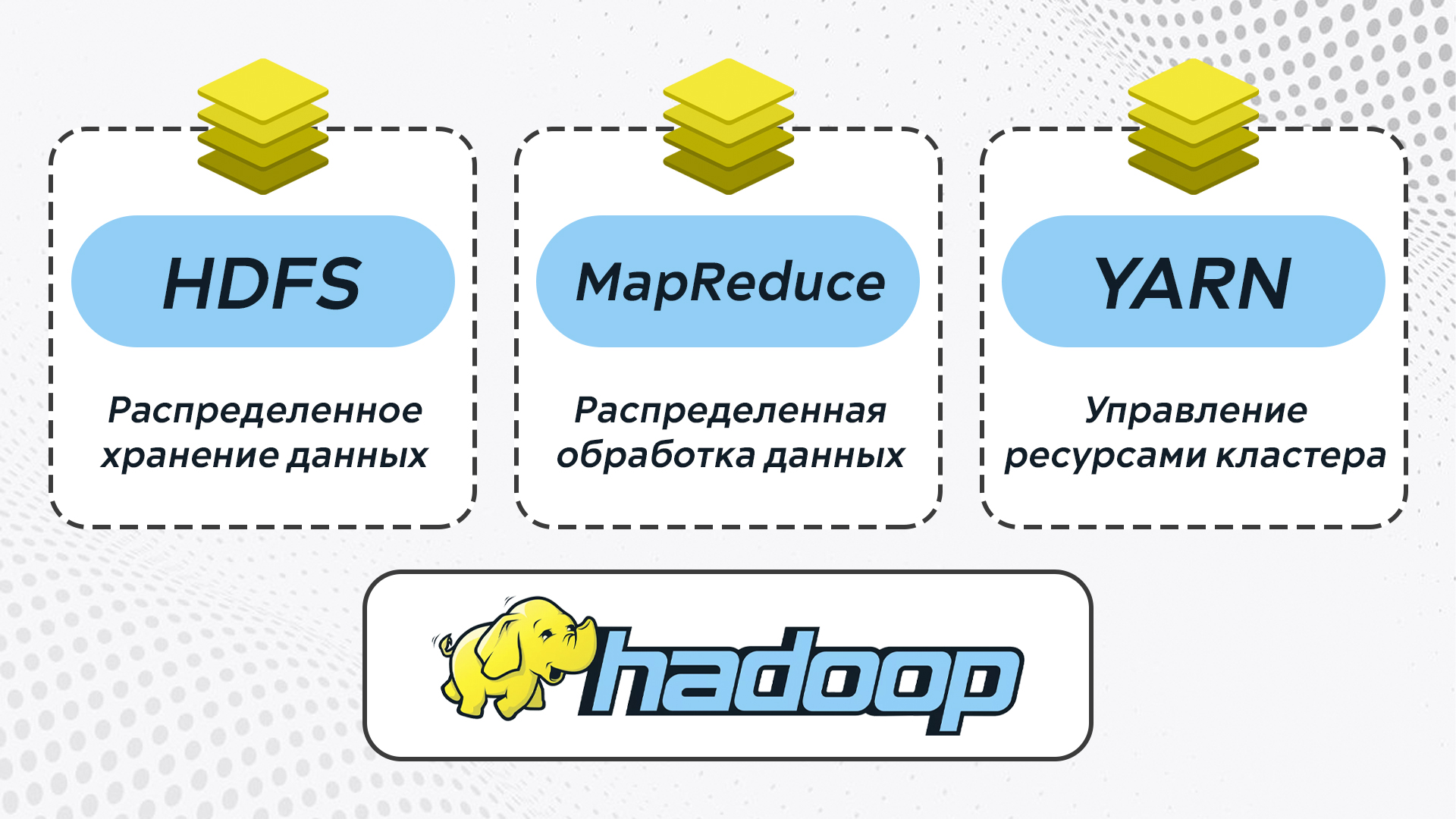
Основные компоненты фреймворка:
- Hadoop Distributed File System (HDFS) — файловая система для хранения больших данных с потоковым доступом. HDFS оптимизирована под работу с файлами до десятков терабайт, а кластеры могут хранить петабайты информации.
- MapReduce — модель для обработки записей из HDFS. MapReduce разбивает задачу на две фазы. На этапе «Map» данные обрабатываются параллельно на разных узлах кластера, а на этапе «Reduce» результаты объединяются.
- Yet Another Resource Negotiator (YARN) — система управления ресурсами кластера и планирования задач. YARN расширяет возможности Hadoop и поддерживает другие модели обработки помимо MapReduce — Spark, Flink.
HDFS, MapReduce и YARN образуют основу Hadoop, обеспечивая хранение, обработку и управление ресурсами соответственно.
Hadoop используют для анализа логов пользователей, чтобы, например, улучшить таргетирование рекламы. Онлайн-ритейлеры применяют Hadoop для рекомендаций товаров на основе истории покупок и просмотров. Распределенная система также применяется в банковской сфере для обработки транзакций.
Преимущества Hadoop
Масштабируемость. Систему Hadoop можно расширять до тысяч узлов. Компании наращивают вычислительные мощности по мере роста объемов данных.
Экономия. Дешевые сервера на базе Hadoop объединяются в мощный вычислительный кластер. Компании используют Hadoop, чтобы не инвестировать в дорогостоящее оборудование.
Отказоустойчивость. Благодаря распределенной архитектуре и автоматической репликации Hadoop работает даже при отказе отдельных узлов кластера.
Гибкость. Hadoop применяется в проектах со структурированными и неструктурированными данными.
Что такое Apache Spark?
Apache Spark — это система распределенных вычислений. Она используется для преодоления ограничений Hadoop MapReduce и интегрируется поверх HDFS.
Spark до 100 раз быстрее Hadoop MapReduce благодаря обработке данных в памяти. Также Spark предоставляет API на Java, Scala, Python. Еще поддерживаются пакетная обработка, интерактивные запросы, потоковая обработка и машинное обучение.
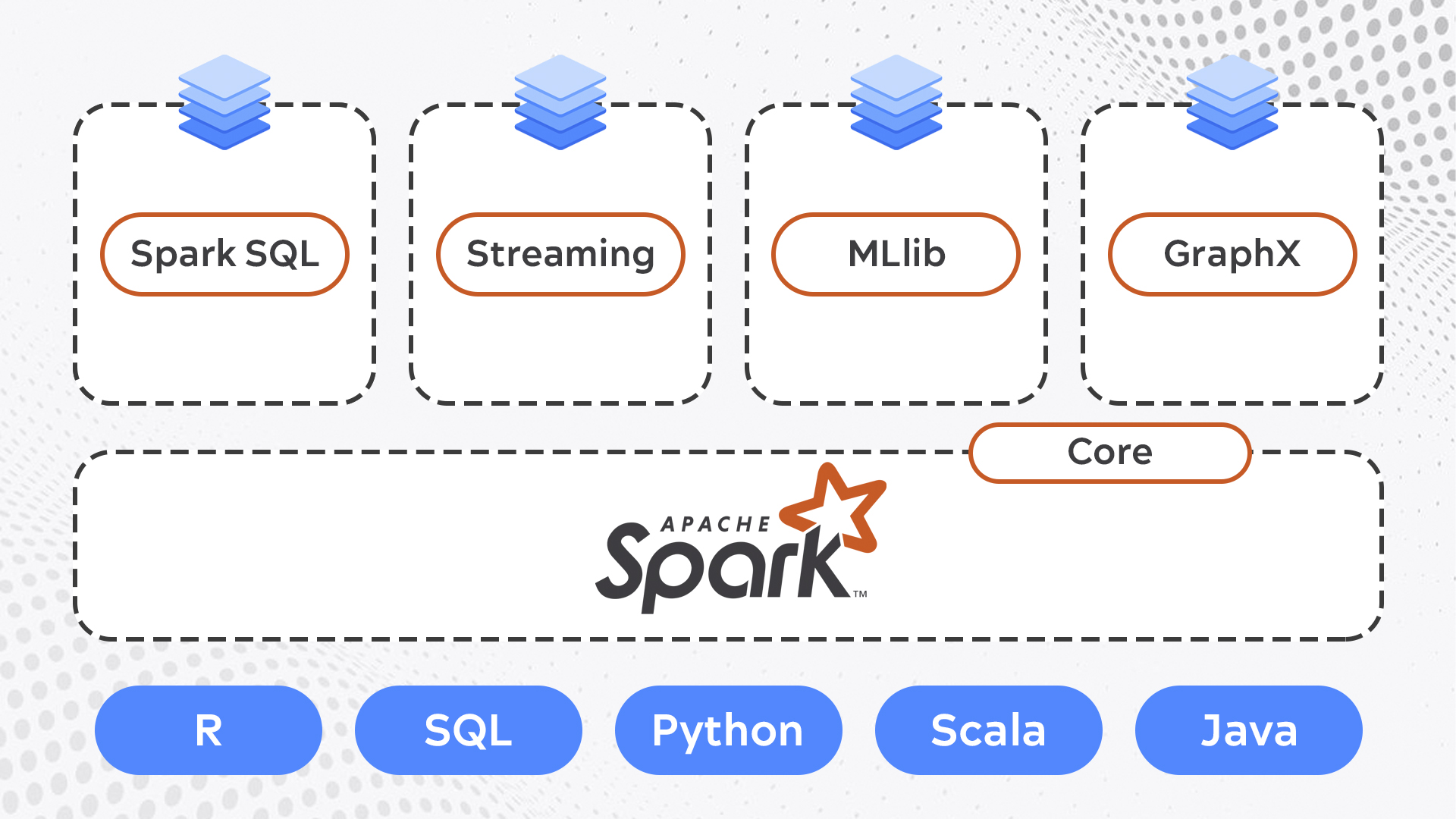
Компоненты Apache Spark:
- Spark Core — движок для распределенной обработки больших данных. Включает в себя API для работы с Resilient Distributed Datasets (RDD) — основной абстракцией данных в Spark.
- Spark SQL — модуль для работы со структурированными данными, поддерживающий SQL-запросы.
- Spark Streaming — компонент для обработки потоковых данных в реальном времени.
- MLlib — библиотека машинного обучения с алгоритмами для классификации, регрессии, кластеризации и фильтрации данных.
- GraphX — движок для визуализации данных на графиках.
Преимущества Spark
Скорость. Spark быстрее Hadoop. Производительность заметна при интерактивной обработке информации и задачах с низкой задержкой.
Отказоустойчивость. Как и Hadoop, Spark устойчив к сбоям за счет распределенного хранения и обработки информации.
Универсальность. Spark подходит для разных видов обработки информации: пакетной, потоковой, SQL-запросов, машинного обучения и графовых алгоритмов.
Интерактивность. Благодаря производительности, с помощью Спарка можно анализировать информацию в реальном времени.
Hadoop vs Spark: сравнение и различия
Оба инструмента предназначены для работы с массивами информации, но их подходы и возможности существенно различаются.
Производительность
Hadoop был создан как решение для распределенной обработки информации, позволяющее разделить нагрузку между множеством серверов. Spark же появился позже как ответ на ограничения Hadoop, предлагая более быструю и гибкую альтернативу пакетной обработке.
Hadoop эффективен для пакетной обработки больших данных, но не отличается высокой скоростью из-за постоянного обращения к внешнему хранилищу. Это делает его подходящим для задач, не требующих мгновенного отклика, например, для анализа ежемесячных отчетов.
Спарк ориентирован на обработку в реальном времени. Он копирует информацию в оперативную память, что значительно ускоряет процесс. Такой подход позволяет Spark превосходить Hadoop как в простых, так и в сложных операциях.
Hadoop:
- Записывает промежуточные результаты на диск, что замедляет выполнение задачи.
- Эффективен для пакетной обработки, когда время выполнения не критично.
- Предпочтительнее для обработки данных, которые не помещаются в память кластера.
Spark:
- Хранит промежуточные результаты в памяти, минимизируя операции ввода-вывода.
- Использует направленный ациклический граф (DAG) для оптимизации задач.
- До 100 раз быстрее Hadoop MapReduce, когда данные помещаются в память.
Программные модели
Основа Hadoop — собственная распределенная файловая система HDFS, которая разбивает массивы данных на мелкие блоки и распределяет их по кластеру. Спарк не имеет встроенной файловой системы, поэтому использует HDFS Hadoop для хранения и управления базой.
Hadoop:
- Двухэтапная модель map и reduce.
- Сложно реализовывать алгоритмы с несколькими этапами обработки данных.
Spark:
- Более гибкая модель с использованием Resilient Distributed Datasets (RDD) и DataFrame API.
- Поддерживает функциональное программирование, что упрощает написание итеративных алгоритмов.
Hadoop изначально разрабатывался с учетом высоких требований к безопасности и включает функции шифрования и контроля доступа. Spark имеет ограниченные встроенные механизмы защиты и требует дополнительных мер безопасности при развертывании.
Поддержка различных типов данных и возможностей машинного обучения
Функционал Spark в обработке данных гораздо шире, чем у Hadoop.
Hadoop:
- Поддержка структурированных данных через Hive.
- Обработка неструктурированных данных через MapReduce.
- Ограниченная поддержка потоковых данных.
- Ограниченная поддержка графовых данных.
- Работа с CSV, JSON через Hive.
- Нет встроенной библиотеки машинного обучения.
- Ограниченный набор алгоритмов ML через внешние инструменты.
- Ограниченные возможности интерактивного анализа данных.
- Обработка текста через MapReduce.
- Ограниченные возможности анализа графов.
- Проблемы с реализацией алгоритмов машинного обучения.
Spark:
- Поддержка структурированных данных через Spark SQL.
- Обработка неструктурированных данных через RDD API.
- Полная поддержка потоковых данных через Spark Streaming.
- Полная поддержка графовых данных через GraphX.
- Работа с CSV, JSON, Parquet и другими форматами через Spark SQL.
- Встроенная библиотека машинного обучения MLlib.
- Широкий набор алгоритмов ML в MLlib.
- Широкие возможности интерактивного анализа через Spark Shell.
- Обработка текста через RDD API и MLlib.
- Реализованы алгоритмы PageRank, Connected Components, Shortest Paths.
- Относительно простая реализация сложных алгоритмов ML.
Интеграция Hadoop и Spark
Платформы интегрируются вместе на проектах, где необходимо хранить данные долговременно и быстро их обрабатывать:
- HDFS используется как основное файловое хранилище, предоставляя масштабируемую инфраструктуру для хранения информации.
- Spark обрабатывает и трансформирует данные в реальном времени.
- YARN распределяет вычислительные мощности между платформами.
Расширить функционал системы можно при помощи следующих инструментов:
- Apache Hive — позволяет выполнять SQL-подобные запросы к данным, хранящимся в HDFS, используя Спарк в качестве движка.
- Apache Kafka — система обмена сообщениями, часто используемая вместе со Spark Streaming для обработки в реальном времени.
- Apache HBase — NoSQL на основе HDFS, которая может быть использована совместно со Спарком для быстрого доступа к данным.
Чтобы выбрать оптимальную архитектуру системы и компоненты, нужно определить требования и цели проекта. Например, если требуется обрабатывать потоковые данные, то помимо Hadoop и Spark понадобиться Apache Kafka.
Следующий этап — планирование инфраструктуры. Необходимо рассчитать объемы данных, которые будут храниться в HDFS, и спроектировать кластер. Нужно выделить достаточно ресурсов для процессов Спарка, учитывая пиковые нагрузки.
Шаг 1. Определите источники данных и их характеристики
Составьте список всех источников данных, которые будут загружаться в HDFS. Для каждого источника выясните:
- формат (CSV, JSON, Avro, текстовые логи),
- частоту поступления (раз в час/день/неделю, непрерывный поток),
- объем, поступающий за один период,
- ожидаемый рост в будущем.
Пример:
Есть 3 источника данных об активности пользователей на сайте, о покупках и логи сервера приложений. Данные поступают каждый день в формате JSON, со средним объемом 5 ГБ, 10 ГБ и 20 ГБ соответственно. Ожидаемый ежегодный прирост — 20%.
Шаг 2. Определите время хранения данных
Решите, как долго хранить каждый тип данных, исходя из требований бизнеса. Иногда достаточно хранить только свежие данные за последний месяц.
Пример:
Решили хранить данные об активности и покупках за последние 2 года, а логи сервера — за 6 месяцев.
Шаг 3. Рассчитайте общий объем сырых данных
Для каждого источника рассчитайте ожидаемый объем данных за требуемый период хранения. Учитывайте ожидаемый рост.
Пример:
- Активность: 5 ГБ × 365 дней × 2 года × 1.2 (прирост 20% в год) = 4.38 ТБ
- Покупки: 10 ГБ × 365 дней × 2 года × 1.2 = 8.76 ТБ
- Логи: 20 ГБ × 182 дня × 1.1 (за полгода прирост около 10%) = 4 ТБ
- Итого сырых данных: 4.38 + 8.76 + 4 = 17.14 ТБ
Шаг 4. Учтите репликацию
По умолчанию HDFS хранит 3 копии каждого блока данных для обеспечения отказоустойчивости. Поэтому оценку объёма данных нужно умножить на коэффициент репликации.
Пример:
С учетом репликации потребуется 17.14 ТБ × 3 = 51.42 ТБ
Шаг 5. Добавьте пространство для промежуточных данных
В процессе обработки данных в Hadoop создаются временные файлы, результаты ETL-процессов, агрегаты. Нужно зарезервировать под них дополнительное пространство — обычно 20-30% от объема сырых данных.
Пример:
Добавляем 30% к оценке: 51.42 ТБ × 1.3 = 66.85 ТБ
Шаг 6. Спланируйте разделение по папкам
Для удобства управления данными в HDFS их нужно разделить по папкам — например, по типам, по бизнес-доменам. Примерная структура:
- /data/raw/,
- /data/processed/,
- /data/tmp/,
- /user/,
- /apps/.
Это позволит выставлять разные политики хранения для разных типов данных, ограничивать права доступа.
В HDFS планируется разместить около 66.85 ТБ данных с учетом двухлетнего срока хранения, ожидаемого роста, репликации и промежуточных сведений. На основе этой оценки можно принимать решения о конфигурации кластера. В реальных проектах могут быть и другие факторы, влияющие на расчеты — например, сжатие больших данных, нагрузка на кластер.
Пример проекта с большими данными на Hadoop и Spark
Предположим, что есть большой набор данных о продажах в сети розничных магазинов. Наша задача — проанализировать собранные сведения, чтобы получить бизнес-инсайты. Будем использовать HDFS для хранения информации, а Spark — для их обработки.
Сначала загрузим датасет в HDFS. Информация о продажах содержится в CSV-файле sales_data.csv. Загрузим его в HDFS с помощью bash-команды:
Пример кода на PySpark для анализа данных из sales_data.csv:
Скрипт создает сессию Spark с конфигурацией для работы с HDFS, читает данные из CSV-файла. Далее запускается 3 вида анализа:
- Расчет общих продаж по категориям товаров.
- Определение средней цены продукта по брендам.
- Выявление ТОП-5 продуктов по количеству продаж.
В конце скрипт выводит результаты анализа на экран и сохраняет их в HDFS в формате CSV.
Заключение
Hadoop и Spark открывают огромные возможности для работы с большими данными, но их внедрение — это непросто. Каждый проект уникален, и опыт использования этих технологий может сильно различаться.
А вы уже использовали Hadoop и Spark на своих проектах?
А вы уже использовали Hadoop и Spark на своих проектах?
Да, конечно!
Еще нет, но звучит круто!
Поделитесь опытом в комментариях:
- Какие задачи вы решали с помощью этих инструментов?
- С какими трудностями столкнулись при внедрении?
- Какие недостатки обнаружили?
Ваши истории будут очень полезны для тех, кто только начинает изучать Hadoop и Spark.

5К открытий11К показов

Трясите коробку и забирайте свой подарок ко Дню программиста!

Мессенджер MAX от VK стал официальным национальным мессенджером России. Поддерживает звонки, чаты, переводы, ИИ-ассистента и интеграцию с Госуслугами

Подборка топовых мобильных IDE и редакторов, которые помогают фронтенд и бэкенд разработчикам писать код прямо со своего телефона.

Запускаем новую рубрику на Tproger. В первом выпуске — Сергей Сова, разработчик, фронтендер и подкастер, делится своими мыслями о Serverless SSR, новостях CSS и мастхев книге.