


Работа с JSON и XML в Python: парсинг, генерация и валидация
Работа с JSON и XML в Python. Показываем варианты использования. Рассматриваем пошаговую инструкцию и основные способы работы с JSON и XML в Python ✔ Tproger
Что такое JSON и XML
JSON и XML — это форматы для хранения информации. Их используют для обмена данными в веб-разработке между клиентом и сервером, поэтому они часто встречаются при работе с API.
Если вы хотите научиться работать с этими форматами и эффективно обрабатывать данные, рекомендуем пройти курс по Python.
JSON (JavaScript Object Notation)
JSON основан на JavaScript, но его понимают и другие языки программирования. Данный формат проще читать, он меньше весит, быстрее передается и совместим с разными платформами.
JSON состоит из объектов, ключей и значений. При этом файл сам является основным объектом, внутри которого могут быть другие объекты.
Перед объектом ставятся фигурные скобки {}. Далее идет имя ключа в кавычках “”, двоеточие и значение.
Значения могут содержать числа, строки, массивы. Также бывают пустые и булевые значения.
Пример синтаксиса JSON:
XML (eXtensible Markup Language)
Стандартный XML уступает JSON в читабельности, скорости передачи и кроссплатформенной совместимости. Но он поддерживает больше типов данных, поэтому хорошо подходит для сложных строгих структур.
Его код начинается с пролога. Это запись, в которой мы указываем версию и кодировку:
Далее идет структура из элементов, внутри которых хранится наша информация с разными типами данных. Этот принцип напоминает устройство HTM кода.
Элементы состоят из тегов — они бывают открывающими и закрывающими. Открывающий тег состоит из знака меньше “<”, имени и знака больше “>”.
Аналогично с закрывающим тегом. Но к нему добавляем слэш “/” после знака меньше “<”. Вот так:
Мы можем разместить между тегами другие элементы, либо такие типы данных как текст, числа, булевые значения, url-адреса, пути к аудио, фото, видео-файлам и документам.
Для открывающих тегов есть возможность прописывать атрибуты — они позволяют указывать дополнительную информацию для элементов. Делается это вот так:
Здесь мы написали атрибут gender со значением “female”
При написании кода мы должны заключить все элементы в один главный элемент. Его называют корневым:
В этом примере <person> корневой элемент.
Библиотеки python для работы с JSON и XML
Существует много библиотек для работы с JSON и XML. Ниже перечислены основные из них.
Библиотеки для работы с JSON
json
- Не нужно устанавливать, встроена по умолчанию.
- Может парсить из строк и файлов.
- Способна конвертировать объекты в JSON-строки.
SimpleJSON
- Может парсить из строк и файлов.
- Способна создавать JSON-строки из объектов.
- Предоставляет более гибкие опции кодирования и декодирования по сравнению с встроенной json.
ujson
- Может парсить из строк и файлов.
- Способна конвертировать объекты в JSON-строки.
- Отличается высокой скоростью работы благодаря реализации на C.
orjson
- Может парсить из строк и файлов.
- Способна создавать JSON-строки из объектов.
- Производительная благодаря реализации на Rust.
- Поддерживает только Python версии 3.6 и выше.
ijson
- Может парсить из строк и файлов.
- Экономит память за счет потоковой обработки данных.
jsonschema
- Специализируется на валидации.
- Поддерживает различные версии спецификации JSON Schema.
cerberus
- Специализируется на валидации.
- Поддерживает валидацию сложных вложенных структур и поддерживает пользовательские правила валидации.
Библиотеки для работы с XML
xml.etree.ElementTree
- Встроена по умолчанию.
- Может парсить из строки и файлов.
- Способна создавать и редактировать XML-строки и файлы.
lxml
- Может парсить из строки и файлов.
- Способна создавать и редактировать XML-строки и файлы.
- Поддерживает валидацию.
- Обеспечивает высокую производительность благодаря реализации на C.
xml.dom.minidom
- Встроена по умолчанию.
- Может парсить из строки и файлов.
- Способна создавать и редактировать XML-строки и файлы.
- Предоставляет DOM-интерфейс для работы с XML.
xml.sax
- Встроена по умолчанию.
- Может парсить из строки и файлов.
- Позволяет создавать собственные обработчики для XML-элементов.
- Эффективна для обработки больших XML-файлов, так как не загружает весь документ в память.
xmlschema
- Может парсить из строки и файлов.
- Выполняет валидацию XML-документов.
- Способна генерировать объекты из XML-данных.
- Позволяет создавать XML-схемы.
xmltodict
- Может парсить из строки и файлов.
- Преобразует XML в словари.
- Способна создавать XML-строки из словарей.
BeautifulSoup
- Может парсить XML и HTML из строки и файлов.
Парсинг данных из JSON и XML
Парсинг — это извлечение данных для последующей обработки и анализа. Давайте представим, что мы ищем новую работу. Для этого ходим по сайтам IT-агентств и сохраняем их контакты себе в таблицу. Это простейший пример парсинга.
Примеры извлечения JSON данных в разных библиотеках
Предположим, что нам надо спарсить вот этот код и вытащить из него значение "occupation".
json
Если данные уже находятся у нас в виде строки, то мы можем вызвать функцию json.loads() для извлечения:
Здесь мы принимаем JSON и записываем его в словарь Python. Далее выводим значение ключа "occupation".
simplejson
Представим, что у нас не строка, а файл json_string.json:
Мы открываем файл json_string.json и называем его f. Далее читаем JSON из файла f с помощью json.load(f) и превращаем в словарь data. В конце возвращаем значение, ключа "occupation".
ujson
Здесь происходит то же, что и в примере выше: ujson.load(f) читает JSON из файла f и преобразует его в словарь Python, который сохраняется в data.
orjson
Если мы хотим спарсить данные по url, то понадобиться библиотека requests:
Функция orjson.loads(response.content) парсит по url JSON, и преобразует их в словарь data, после чего мы можем обращаться к значениям этого словаря.
Примеры извлечения XML данных в разных библиотеках
Представим, что нам нужно спарсить значение из тега name в этом коде:
xml.etree.ElementTree
При помощи ET.fromstring(xml_string) мы извлекаем XML из строки и создаем объект root — он представляет корневой элемент. Далее при помощи индекса root[0] обращаемся к первому дочернему элементу <name> и выводим его значение.
lxml
etree.fromstring(xml_string) извлекает данные из xml_string в объект root. Как и в примере выше, мы можем обращаться к элементам и атрибутам через root и его дочерние элементы при помощи индекса, например, root[0].
xml.dom.minidom
Здесь minidom.parseString(xml_string) извлекает XML из строки и создает объект dom. Далее команда находит первый элемент с тегом <name>, записывает его в переменную name_element и выводит значение.
xmltodict
Библиотека анализирует XML структуру и создает словарь, где ключи — это теги XML, а значения — дочерние элементы. Мы обращаемся к элементу <name> и выводим его.
BeautifulSoup
При помощи BeautifulSoup(xml_string, 'xml') мы парсим из строки xml_string и указываем, что нам нужен формат xml. Далее сохраняем данные в объект soup, находим элемент с тегом <name> и выводим его значение.
Генерация данных JSON и XML в Python
Примеры генерации JSON в разных библиотеках
Библиотеки python используют схожий подход для генерации JSON. Делается это при помощи функции dumps(). Вот несколько примеров:
json
SimpleJSON
ujson
orjson
Мы создали словарь data с данными и преобразовали их в JSON.
dumps() конвертирует объект в JSON. Но если необходимо записать данные в файл, то стоит воспользоваться функцией dump().
Примеры генерации XML в разных библиотеках
Если мы хотим записать XML файл, то нам понадобятся следующие функции:
- ET.Element() — создает корневой элемент
- ET.SubElement() — создает дочерние элементы
- ET.ElementTree() — сохраняет дерево из элементов
- tree.write() — записывает xml данные в файл
xml.etree.ElementTree
В этом примере мы создаем корневой элемент person, добавляем дочерние элементы name и age, прописываем их значения, а затем сохраняем XML дерево в файл person.xml.
lxml
Здесь мы тоже создаем корневой элемент, добавляем дочерние элементы, формируем дерево и записываем в файл.
xmltodict
А это пример создания XML из словаря. Библиотека анализирует структуру словаря и создает XML документ. Ключи словаря становятся тегами, а значения — текстовым содержимым или вложенными элементами.
Примеры валидации данных в JSON и XML
Валидация — это проверка кода на соответствие определенным правилам. Например, мы создаем форму для регистрации, где будет пароль только из латинских знаков. Следовательно, нам нужно проверять символы, которые будут вводить пользователи при регистрации.
Примеры валидации JSON в jsonschema и Cerberus
jsonschema
Мы прописываем схему "schema", которая определяет наши правила. Данные должны быть объектом с ключами "name" и "age". Ключ "name" принимает только строки в качестве значений, а "age" только числа".
Далее мы определяем два набора данных. Один валидный, другой нет.
Проверяем, соответствуют ли valid_data и invalid_data заданной схеме. Выводим сообщение о валидности/невалидности данных.
Cerberus
Задаем схему с правилами. Указываем, что у нас обязательно должен быть ключ "name", который принимает строку. Его наличие обязательно благодаря команде "required": True. Ключ "age" принимает только числа.
Здесь мы передаем нашу схему в объект validator и определяем два набора данных. Первый — валидный, второй с ошибкой. В нем отсутствует "name".
Проверяем корректность кода и выводим сообщения.
Примеры валидации XML в lxml и xmlschema
lxml
Это XML-данные, которые мы будем проверять на ошибки.
А это наша схема с правилами. Давайте разберем ее более детально.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> — означает, что этот код является схемой и ссылается на определенный стандарт.
<xs:element name="person"> — здесь мы говорим, что элемент с тегом <person> должен быть корневым в проверяемом XML коде.
<xs:complexType> и <xs:sequence> означают, что у нас несколько элементов и они должны идти в определенном порядке. Далее мы указываем наши элементы и их тип.
xml_data и xsd_date являются строками. Чтобы выполнить валидацию, их необходимо преобразовать в объект python. Делаем это при помощи метода etree.fromstring(). Теперь у нас есть объекты xml_doc и xsd_doc. В них хранится информация о нашем xml коде и схеме.
При помощи xsd_doc создаем новый объект схемы.
Валидируем xml_doc и выводим сообщение о результате.
xmlschema
Рассмотрим вариант, при котором наша схема расположена в отдельном файле.
Импортируем библиотеку и указываем файл с правилами.
Определяем два набора данных для проверки. Один валидный, другой нет.
Проверяем валидность данных в функции validate() и выводим сообщения о результате валидации при помощи условной конструкции try: except.
Работа с API JSON и XML
Теперь рассмотрим несколько простых примеров передачи данных по API.
Получение данных из API с использованием JSON
Импортируем библиотеку для работы с API requests и записываем адрес в переменную url.
Отправляем запрос на наш API и проверяем ответ. Если он успешный, то записываем его в словарь data.
Выводим значения элементов name и email. Если их нет, то код покажет ошибку.
Отправка данных в API с использованием JSON
Импортируем requests, записываем адрес API в url и определяем данные, которые надо отправить.
Отправляем POST-запрос с данными на сервер.
Если всё работает, то получаем статус-код 201 и выводим сообщение об успехе. Если данные не отправились, то выводим сообщение с ошибкой.
Получение данных из API с использованием XML
Импортируем библиотеки, записываем API-адрес в переменную url и отправляем GET-запрос.
Если запрос отправлен успешно, обращаемся к элементу name и выводим его значение.
Отправка данных в API с использованием XML
Всё по классике. Импортируем requests и xmltodict. Записываем API в переменную url. Создаем словарь с данными для отправки.
Создаем словарь headers , в который записываем заголовок нашего запроса. Отправляем его.
Проверяем код ответа. Если все отправилось, то выводим соответствующее сообщение. Если нет — выводим ошибку.
Конвертация JSON и XML
Пример конвертации JSON в XML
Импортируем библиотеку и прописываем JSON, который будем конвертировать.
Конвертируем JSON в XML, сохраняем данные в xml_data и выводим результат.
Пример конвертации XML в JSON
Импортируем библиотеки и определяем XML-данные.
Преобразуем данные в словарь json_data.
Конвертируем словарь в JSON и выводим его.
Оптимизация работы с JSON и XML
Встроенные библиотеки Python, такие как json и xml.etree.ElementTree, обычно являются хорошим выбором для простых задач. Однако, для больших объемов или высокопроизводительных приложений они не подходят.
Производительность
С точки зрения производительности следует рассмотреть библиотеки: orjson и lxml.
Для JSON
orjson: Быстрая библиотека, написанная на Rust. Но поддерживает версию python от 3.6.
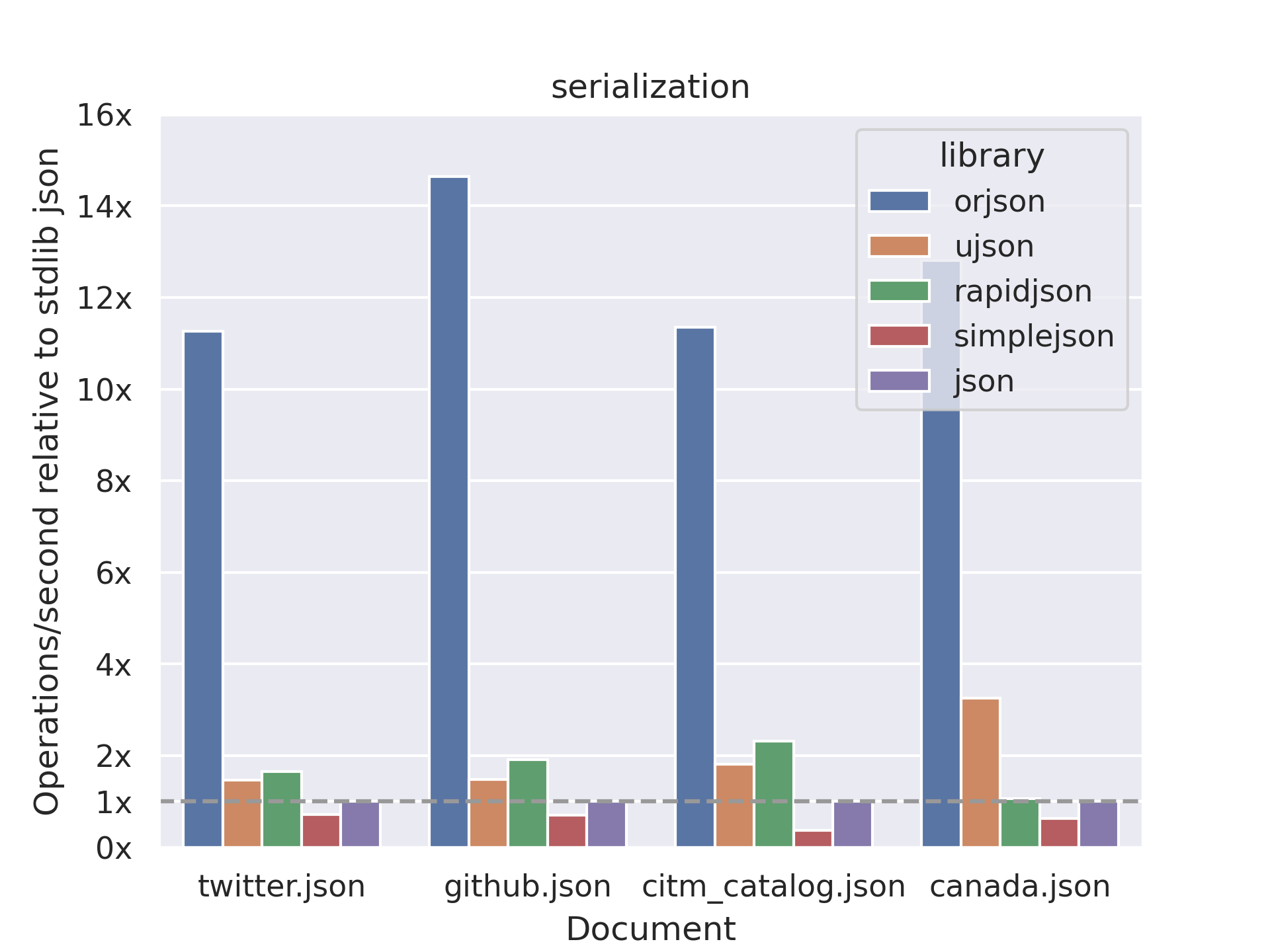
Эта диаграмма показывает скорость кодирования JSON данных в объект python на примере работы с API. Как видно, orjson справляется с задачей быстрее всех.
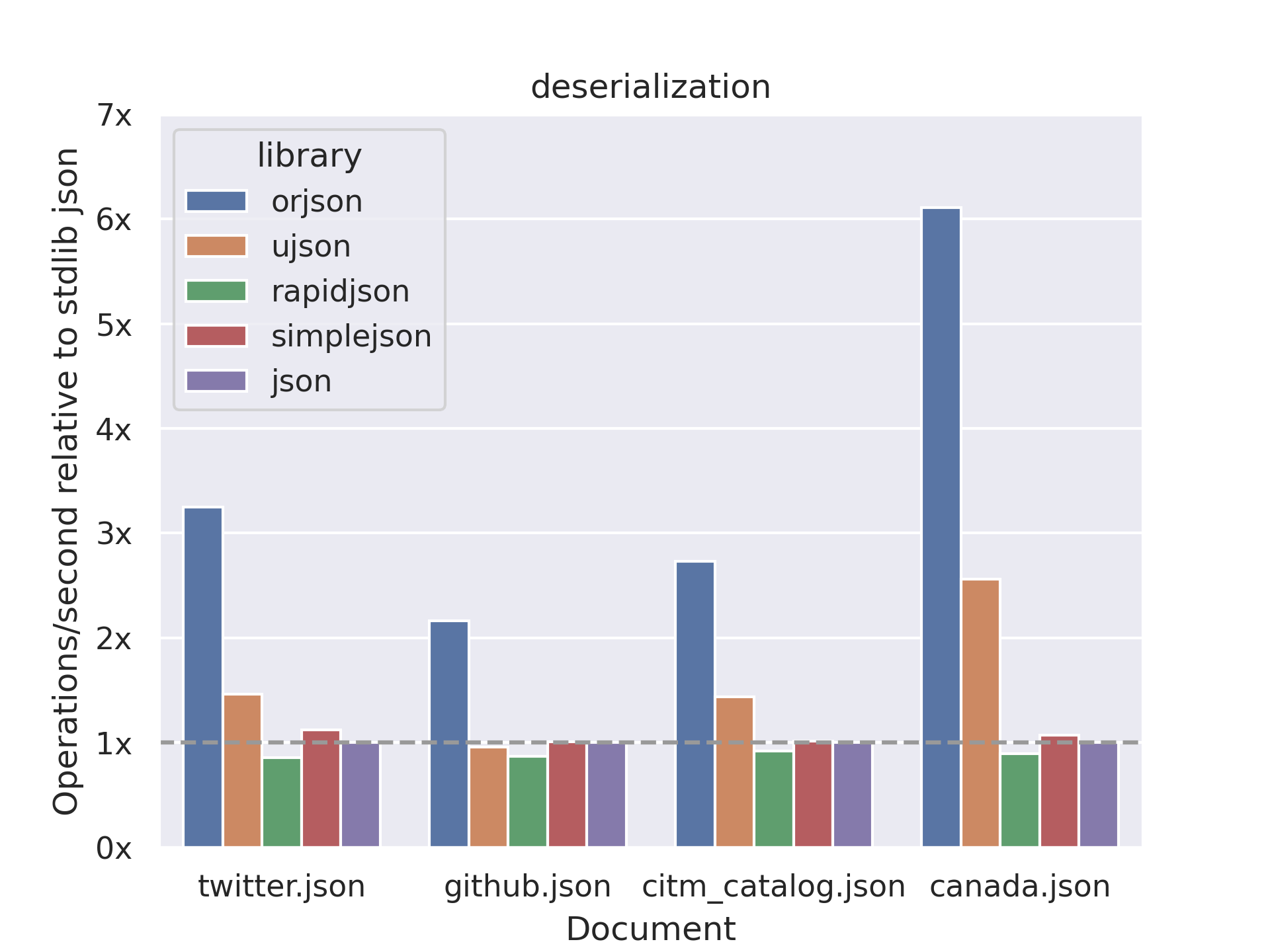
А здесь мы видим обратный процесс — преобразование Python в JSON-данные.
Эти тесты могут быть предвзятыми, поскольку проводились самими разработчиками orjson. Но другие эксперименты также подтверждают превосходство orjson.
Для XML
lxml: основана на C-библиотеках libxml2 и libxslt, обычно быстрее, чем xml.etree.ElementTree, особенно для больших XML-документов и сложных операций.

На этом скриншоте изображены итоги теста Python-библиотек. Они анализировали XML-файл весом в 95 мегабайт, и lxml показала себя здесь лучшим образом.
Работа с памятью
Для работы с памятью лучше использовать библиотеки, которые поддерживают потоковую загрузку и обработку данных.
Для JSON:
- ijson: Эта библиотека позволяет итеративно обрабатывать данные, не загружая весь документ.
Для XML:
- xml.sax: обрабатывает данные по частям, не загружая всё в память.
- lxml: также обрабатывает большие объемы информации по кусочкам.
Если вы пользуетесь другими библиотеками или фичами — рассказывайте о них в комментариях.









![Обложка: Как стать аналитиком данных за 6–12 месяцев [гайд]](https://media.tproger.ru/uploads/2025/12/1c7c4818-f579-4330-b4fe-56704d1972e0.jpg)


