Рефакторинг запросов: как ускорить работу API без переписывания всего кода
Рефакторинг запросов. Показываем, как ускорить работу API без переписывания всего кода. Рассматриваем пошаговую инструкцию и основные нюансы ✔ Tproger
API тормозит, а переписывать код с нуля — не вариант? Рефакторинг запросов поможет ускорить работу без радикальных изменений. Разбираем, как оптимизировать API, сокращая задержки и снижая нагрузку на сервер, не разваливая всю систему.
Анализируем производительность API
Прежде чем ускорять API, нужно понять, что именно замедляет его работу. Для этого оцениваем ключевые метрики:
- Время отклика — сколько времени проходит от запроса до получения ответа.
- Нагрузка на сервер — сколько ресурсов потребляет API при обработке запросов.
- Частота ошибок — как часто сервер возвращает некорректные ответы.
Отслеживать эти показатели помогают инструменты вроде Postman, New Relic и APM-систем. Они визуализируют данные, автоматизируют тестирование и позволяют находить проблемы в режиме реального времени.
Postman
Используется для ручного тестирования запросов. Postman показывает время отклика и ошибки. Также через него удобно тестировать сценарии работы API.
Инструмент удобен тем, что поддерживает коллекции запросов. Это упрощает тестирование сложных цепочек операций во время рефакторинга. Можно интегрировать Newman для автоматизации тестов и анализа метрик на регулярной основе.
Большой гайд по работе с Postman API Platform
New Relic
Платформа для мониторинга производительности приложений. Можно отслеживать время обработки API-запросов, статистику по операциям, загрузку системы.
New Relic показывает распределение времени выполнения между сервером, БД и внешними сервисами, что помогает в рефакторинге разных частей системы.
APM-системы
Инструменты Datadog, AppDynamics или Dynatrace сохраняют данные о том, как работает API. Через них можно смотреть трассировку запросов, выявлять проблемы с медленными вызовами или зависимостями от внешних систем.
Ищем узкие места в запросах
Для выявления проблемных фрагментов кода необходимо посмотреть, как API реагирует на разные нагрузки, и как распределяется время обработки запроса.
Поиск состоит из 7 этапов:
- Анализ общей картины. С помощью APM-систем и логирования нужно выделить самые медленные запросы.
- Локализация длинных операций. В одном запросе может быть несколько узких мест (тяжелый SQL-запрос, внешний API-вызов).
- Поиск запросов с высокой частотой вызовов. Например, запросы к слою авторизации или ручки API, к которым обращаются массово при каждом действии пользователя.
- Проверка ошибок. Ошибки приводят к дополнительной нагрузке: например, если клиент совершает повторные запросы после тайм-аута.
- Анализ распределения нагрузки. Если одни эндпоинты перегружены трафиком, а другие используются редко, в рамках рефакторинга нужно сбалансировать нагрузку. Например, добавить серверы только под обработку горячих эндпоинтов.
- Тестирование в условиях пиковой нагрузки. Стресс-тест средствами JMeter поможет выявить проблемы, скрытые в условиях обычного трафика.
- Анализ зависимостей API. Замедленная работа внешнего сервиса увеличивает время отклика для каждого запроса. Через Jaeger или Zipkin можно посмотреть цепочку зависимостей.
- Локализация длинных операций. В одном запросе может быть несколько узких мест (тяжелый SQL-запрос, внешний API-вызов).
Оптимизация запросов к базе данных
Уменьшить время отклика API без переписывания кода можно за счёт оптимизации работы с БД. Один из ключевых инструментов — индексы. Они ускоряют поиск данных, снижая нагрузку на сервер.
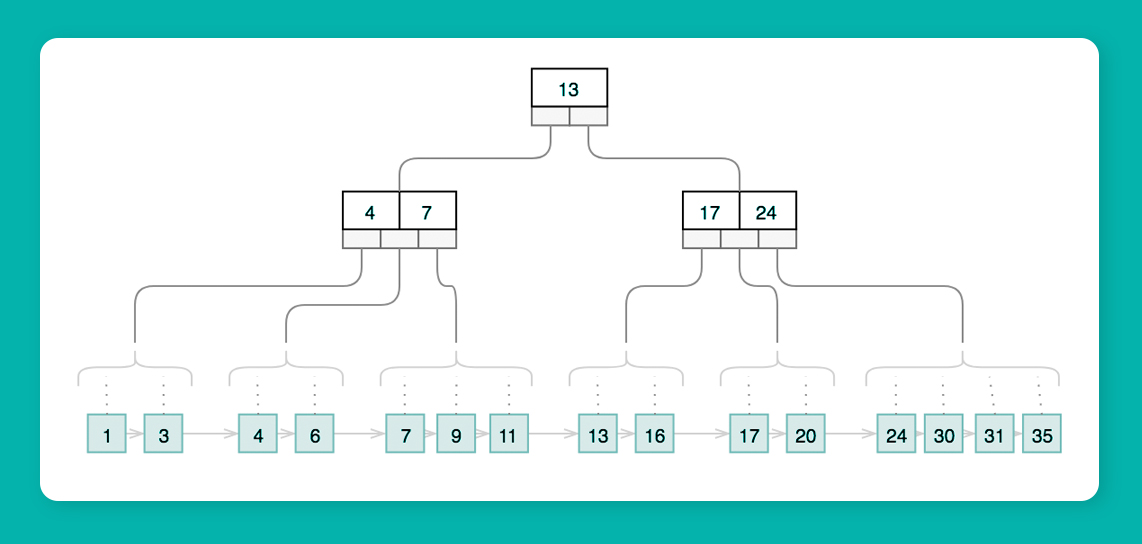
Что индексировать в первую очередь:
- Поля, используемые в WHERE, JOIN, ORDER BY, GROUP BY. Например, если запросы часто фильтруют по email, имеет смысл добавить индекс.
- Запросы с несколькими условиями фильтрации — их лучше оптимизировать составными индексами. Важно, чтобы порядок полей соответствовал порядку в SQL-запросах.
- Только те данные, где индексация действительно ускорит поиск. Например, индекс для gender (male/female) не даст прироста скорости.
Лишние индексы замедляют операции записи, их нужно удалять. В PostgreSQL они могут пересекаться, но при дублировании замедляют запросы. Вместо нескольких отдельных индексов эффективнее использовать составные.
Агрегация и выбор только необходимых полей
Обработка бесполезных данных увеличивает объем передаваемой информации, замедляет чтение и создает нагрузку на сеть.
Например, команда SELECT * выбирает все колонки таблицы, включая неиспользуемые. Вместо SELECT * FROM users следует указывать целевые поля: SELECT id, name, email FROM users.
Если к запросу добавлены ненужные JOIN-ы, группировки или сортировки, в рамках рефакторинга нужно постараться избавиться от них. Избыточные операции на стороне БД рекомендуется переносить в бизнес-логику приложения.
Снизить объем данных можно за счет COUNT, SUM, AVG, MAX, MIN — эти функции возвращают обобщенные записи вместо отдельных значений. Частичную обработку данных можно выполнять на стороне БД. Например, в PostgreSQL есть встроенные функции по типу JSON_AGG.
Пагинация и лимиты в запросах
API, работающие со списками пользователей и транзакциями, обязательно должны использовать пагинацию. Лимит на объем возвращаемых записей предотвращает перегрузку серверов и клиента.
Самое простое решение — во время рефакторинга ограничить количество строк с помощью LIMIT или FETCH FIRST. Например, вместо загрузки всех пользователей SELECT id, name FROM users LIMIT 30 вернет только первые 30 строк.
Еще можно использовать постраничную выборку (комбинацию LIMIT и OFFSET):
Если производительность упала, значит офсет слишком большой. В таких случаях лучше перейти на модель курсоров.
Пагинация с курсорами заменяет OFFSET значением последнего взятого элемента. Например, вместо LIMIT 20 OFFSET 100 можно использовать запрос:
Чтобы пагинация работала корректно, всегда нужно использовать явный ORDER BY.
Кэширование
Количество запросов к серверу можно сократить, если сохранять часто запрашиваемые данные. Это называется кэшированием. Рефакторинг кэширования уменьшает нагрузку на сервер, снижает время отклика API.
Рассмотрим инструменты для кэширования.
Redis
Подходит для серверного и распределенного кэширования. Поддерживает TTL, работу со списками, хэшами и включение репликации для отказоустойчивости. Для интеграции доступны библиотеки и клиенты — ioredis для Node.js или StackExchange.Redis для .NET.
Как использовать Redis для кэширования и очередей в веб-приложениях
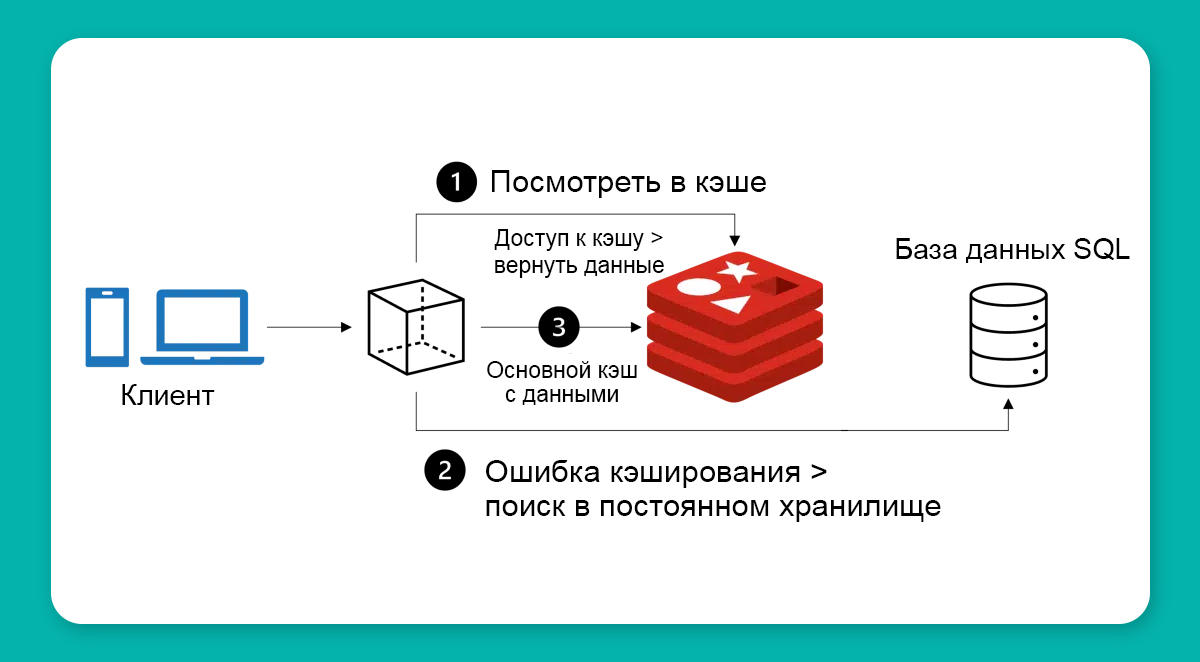
Рефакторинг кэширования повысит производительность сервиса:
- если API возвращает неизменяемые или редко изменяющиеся данные,
- если часть запросов к БД выполняется кратно дольше остальных.
Например, в Redis можно сохранять список активных пользователей:
Memcached
Применяется для уменьшения нагрузки на базу данных и работы с временными данными. Memcached менее функционален, чем Redis, но более эффективен для сценариев, где не требуется сложная логика или постоянное хранилище.
Как использовать серверы Redis и Memcached для кэширования
Виды кэша
Выбор типа кэширования зависит от архитектуры API и характера данных.
- Клиентский кэш — данные хранятся на стороне клиента. Например, браузеры загружают страницу дольше в первый раз, но затем мгновенно извлекают её из кэша.
- Серверный кэш — данные сохраняются на сервере или в промежуточном хранилище (Redis, Memcached). Это снижает нагрузку на базу данных: повторные запросы возвращаются из кэша, а не пересчитываются заново.
- Распределённый кэш — данные кэшируются в нескольких узлах для масштабирования и высокой доступности. Например, Redis в режиме кластера помогает организовать кэширование в микросервисной архитектуре.
Уменьшение объема передаваемых данных
Скорость API зависит от объема данных, передаваемых между клиентом и сервером.
Оптимизация формата ответа: JSON vs Protobuf

Формат JSON популярен из-за читаемости и универсальной поддержки большинством языков программирования. Он менее эффективен по сравнению с бинарными форматами. JSON занимает больше места из-за текстового представления структур и значений.
Protobuf (Protocol Buffers) — бинарный формат, разработанный Google. Он компактен, быстрее сериализуется и занимает меньше места по сравнению с JSON. В формате Protobuf каждый элемент закодирован с минимальным количеством байтов.
Переход на Protobuf может потребовать изменений в клиентах API, поэтому такая оптимизация выполняется на этапе, когда остальные методы снижения объема данных себя исчерпали.
Удаление избыточных данных и компрессия
Часто API отправляет больше данных, чем реально нужно клиенту. Это лишний сетевой трафик и задержки:
- Удаление ненужных полей — ограничение выборки данных на стороне сервера: используются выборочные запросы к БД, настройка сериализаторов или фильтрация на уровне представлений.
- Сжатие Gzip — уменьшение размера текстовых данных (JSON, XML) на 70–90%, не требуя изменений в API. Включается на уровне Nginx, Apache или через middleware. Клиенты автоматически распаковывают такие ответы, сохраняя прозрачность процесса.
Версионирование API
Клиенты обычно нуждаются в данных разного объема. Вместо универсального ответа для всех пользователей рекомендуется разработать несколько версий API.
Новые версии должны отправлять клиентам упрощенные данные или предлагать другую модель представления без модификации существующих запросов.
Упрощение достигается через фильтрацию полей на стороне сервера с использованием сериализаторов или форматов ответа. Например, через GraphQL можно сделать так, чтобы клиенты напрямую запрашивали только необходимые поля.
Чтобы не произошло одновременного отказа у клиентов на старых версиях API, можно временно поддерживать несколько версий. Со временем старую версию нужно объявить устаревшей и отключить.
Параллелизация и объединение запросов
Оптимизировать API можно за счет рефакторинга batch-запросов. Они объединяют несколько запросов в один — количество обращений между клиентом и сервером сокращается.
Клиенты отправляют массив запросов, сервер обрабатывает их и возвращает всего один ответ.
Batch-запросы дают прирост к производительности, когда клиент ожидает получение или обновление нескольких независимых ресурсов.
Например, мобильное приложение может запрашивать информацию о пользователе и связанных с ним объектах (сообщения, уведомления) за один вызов.
Если API поддерживает вложенные запросы, клиент может запрашивать связанные данные одним вызовом. Пример на GraphQL:
Асинхронные операции
API после рефакторинга будет работать быстрее, если выполнять запросы независимо друг от друга. Сервер может распределять выполнение независимых операций по асинхронным потокам.
Например, при обработке одного запроса API может обратиться к нескольким подсистемам, отправить синхронные запросы в базу данных и внешние API, параллельно собирая результаты.
Для асинхронных операций часто используются очереди сообщений RabbitMQ или Apache Kafka.
Оптимизация на уровне серверной логики
Обработку запросов можно откладывать до момента, когда данные действительно понадобятся. Это полезно при работе с запросами, где связанная информация не требуется или используется не полностью. Такое поведение называется lazy loading (ленивая загрузка).
Загружать связанные данные можно заранее в одном запросе, чтобы сократить количество запросов к БД. Такой принцип работы API называется eager loading (стремительная загрузка). Используется в случаях, когда известно, что все связанные данные понадобятся в ходе операции.
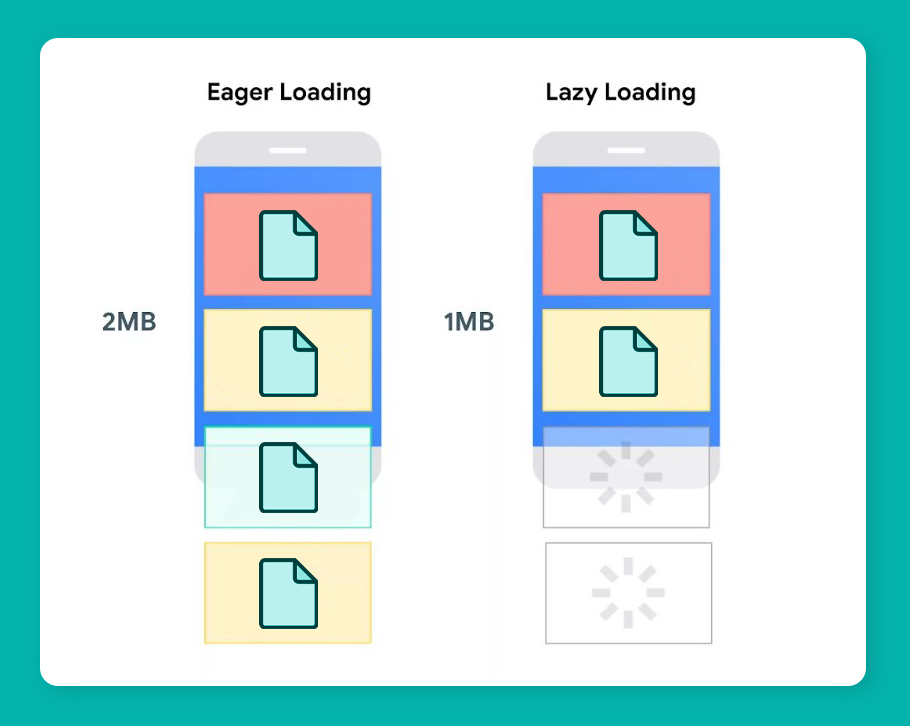
Lazy loading подходит, если только небольшая связка данных используется в каждом запросе.
Eager loading лучше применять, когда количество запросов к БД критично или весь объем данных необходим для выполнения операции.
Очереди для обработки задач в фоне
Вместо выполнения тяжелых задач в реальном времени, сервер может добавлять их в очередь, чтобы они обрабатывались фоновыми воркерами.
Очереди используются для задач, не влияющих на основной ответ клиенту:
- отправка писем,
- формирование отчетов,
- обновление статистики,
- построение индексов,
- обработка данных.
При поступлении запроса API выполняет только основные операции (валидацию данных или запись в базу), после чего создает задачу в очереди. Процессы выполняются в отдельной среде, не влияя на основной поток обработки запросов.
Разделение сложных операций на этапы
Комплексные операции, например, генерации отчетов, можно разделить на сбор данных из базы, их обработку и финальное преобразование. Каждый шаг выполняется независимо, а результаты промежуточных операций сохраняются для последующего использования.
Вместо последовательного выполнения всех шагов, задачу можно поручить системе планировщиков или pipeline в Jenkins. Каждый этап становится в очередь и выполняется отдельным процессом.
Мониторинг и тестирование
После рефакторинга хочется быть уверенным в стабильности API, выявить возможные проблемы и оценить эффективность оптимизаций. Процесс включает:
- нагрузочное тестирование,
- сравнение метрик до и после рефакторинга,
- автоматизацию наблюдения за состоянием API.
Нагрузочное тестирование определяет, как API справляется с возрастающей нагрузкой. Оно выявляет точки перегрузки. Инструменты для стресс-теста API: Apache JMeter, Gatling.
На основе результатов нагрузочного тестирования можно проанализировать, насколько рефакторинг улучшил производительность API. В сборе метрик помогут APM-инструменты.
Если показатели значительно улучшились, поздравляем, рефакторинг удался.
Автоматизация мониторинга повышает надежность API и предотвращает проблемы до их масштабного проявления. Инструменты для поддержания производительности в реальном времени: Prometheus + Grafana, Datadog.
Что запомнить
- Производительность API оценивается с помощью метрик: времени отклика, нагрузки на сервер и частоты ошибок.
- Для мониторинга API используются инструменты Postman, New Relic и APM-системы, которые выявляют узкие места системы.
- Оптимизация запросов к базе данных включает индексацию, удаление избыточных операций и выбор только необходимых полей. Для работы с большими объемами данных используется пагинация с применением LIMIT, OFFSET или курсоров.
- Кэширование снижает нагрузку на сервер, сохраняя востребованные данные локально.
- Уменьшение объема передаваемых данных достигается за счет перехода с JSON на Protobuf, компрессии Gzip и фильтрации полей.
- Для сокращения числа запросов к API применяются batch-запросы.
- Асинхронная обработка операций с помощью очередей RabbitMQ или Kafka ускоряет время отклика API для клиентов.
- Очереди для фоновой обработки задач снижают нагрузку на основной поток запросов.
- Нагрузочное тестирование помогает оценить улучшения после рефакторинга.
- Автоматизация мониторинга предотвращает проблемы API до их критического проявления.

