


Рекомендательные системы и реализация Content-based системы
Небольшое введение в рекомендательные системы: основные идеи, типы, метрики и как они работают. А также реализация content based системы для аниме и небольшой анализ данных.
2К открытий7К показов
Небольшое введение в рекомендательные системы: основные идеи, типы, метрики и как они работают.
Данную статью я условно разделю на 3 части: общая теория по рекомендательным системам, работа с данными, для которых будем строить систему и реализация системы.
Теория (самый страшный зверь)
Рекомендательная система — это система, которая пытается предсказать или отфильтровать предпочтения в соответствии с выбором пользователя. Рекомендательные системы используются в различных областях, включая фильмы, музыку, новости, книги, исследовательские статьи, поисковые запросы, социальные теги и продукты в целом.
Метрика
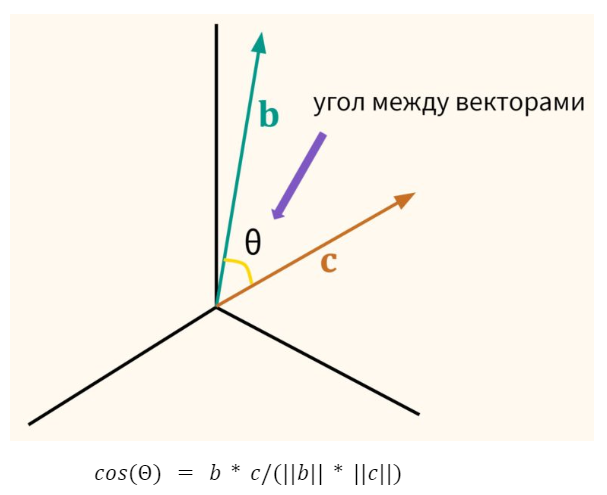
Чаще всего для оценки расстояния используют косинусное сходство (Cosine Similarity).
Представление данных в форме вектора имеет ещё одно полезное свойство. Мы можем измерить близость двух векторов или угол между ними. Чем угол меньше, тем они ближе.
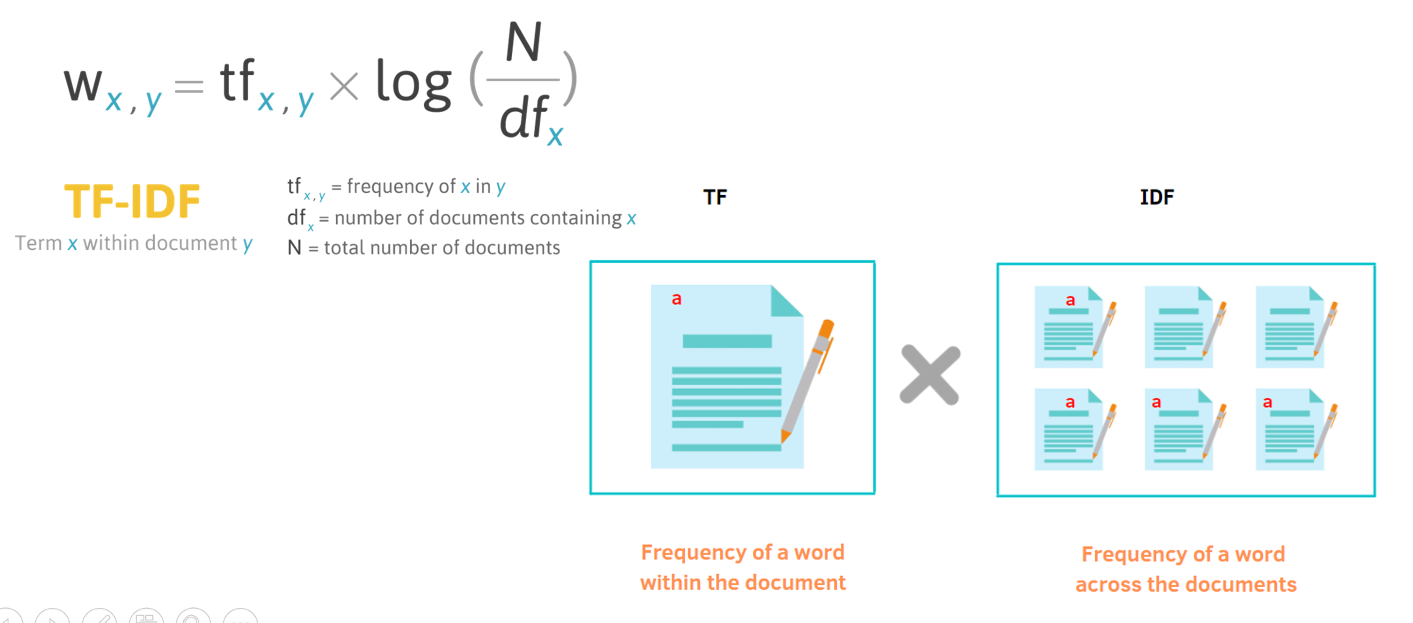
TF-IDF
– применяется для анализа значимости слова в документе, который является частью большой коллекции документов либо корпуса. С помощью этой статической меры можем составить вектор, с которыми работают рекомендательные системы.
TF — это частота слова в тексте – количество раз, когда слово появляется в документе, деленное на общее количество слов в документе (каждый документ имеет свою частоту терминов). Обратная частота данных IDF — это логарифм обратной частоты распространенности слова в корпусе. Распространенностью называется отношение числа текстов, в которых встретилось искомое слово, к общему числу текстов в корпусе.
Обратная частота данных определяет вес редких слов во всех документах корпуса.
Scikit-Learn предоставляет преобразователь под названием TfidfVectorizer в модуле feature_extraction.text для векторизации с оценками TF-IDF.
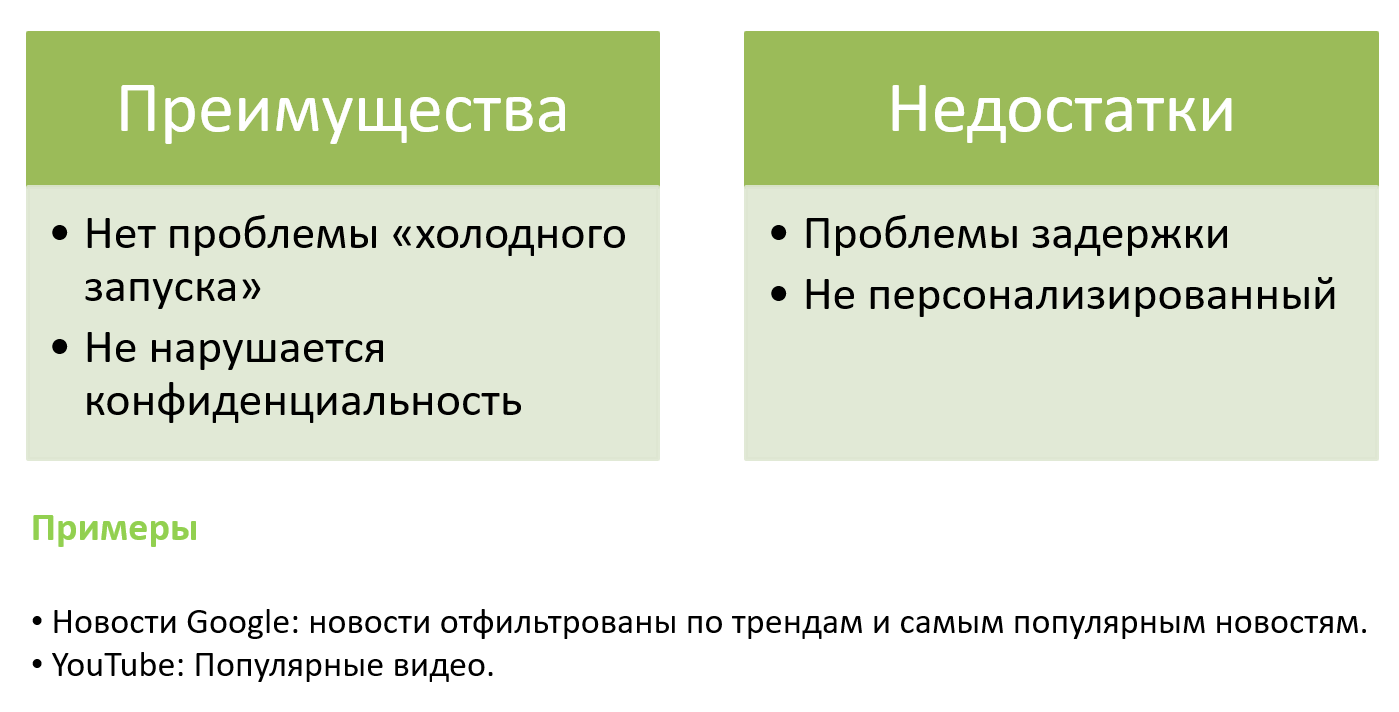
Проблемы
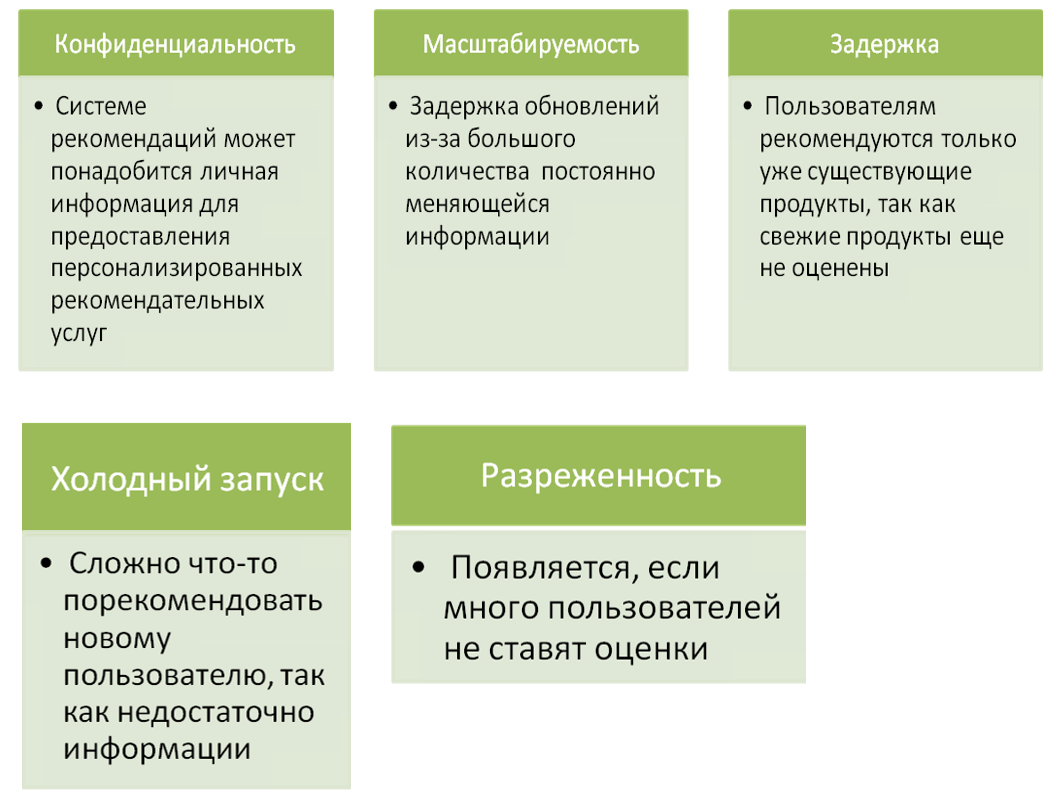
- Холодный запуск
Эта проблема возникает, когда в систему добавляются новые пользователи или новые элементы, новый элемент не может быть рекомендован пользователям изначально, когда он вводится в систему рекомендаций без какой-либо оценки или обзоров, и, следовательно, трудно предсказать выбор или интерес пользователя.
- Разреженность
Это происходит много раз, когда большинство пользователей не дают оценок или отзывов о товарах, которые они приобрели, и, следовательно, модель оценки становится очень разреженной, что может привести к проблемам разреженности данных, это уменьшает возможности найти набор пользователей с похожими оценками или интерес.
- Конфиденциальность
Как правило, человеку необходимо передать свою личную информацию в систему рекомендаций для получения более полезных услуг, но это вызывает проблемы с конфиденциальностью и безопасностью данных, многие пользователи не решаются передавать свои личные данные в системы рекомендаций. которые страдают от проблем с конфиденциальностью данных.
Типы рекомендательных систем
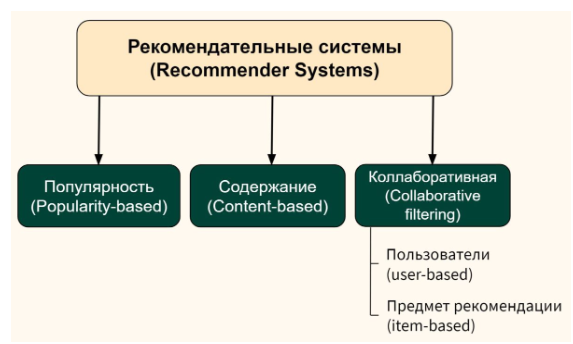
Popularity-based
Наиболее простая система выдает рекомендации на основе популярности (popularity-based recommender systems). Чем выше средний рейтинг фильма, купленного товара или статьи, тем вероятнее, что система будет рекомендовать именно их.
Сontent-based filtering
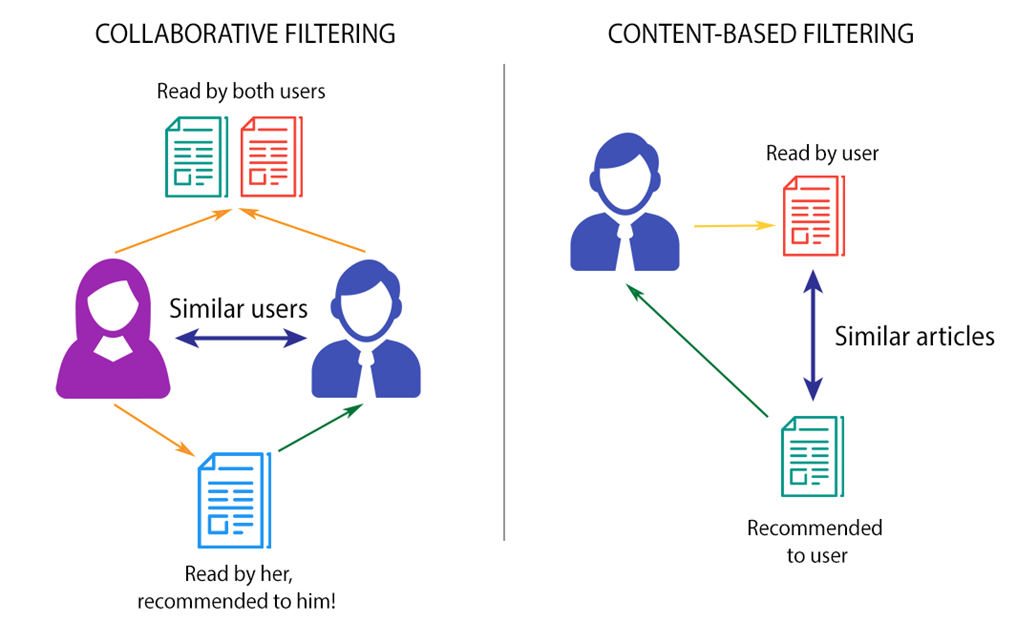
Вторым типом рекомендательных систем является, так называемая, фильтрация на основе содержания (content-based filtering). В данном случае алгоритм рекомендует товары или услуги, схожие с теми, которые пользователь приобретал ранее. Например, если вы посмотрели фильм «Матрица» с Киану Ривзом, то в дальнейшем система будет рекомендовать вам научную фантастику, а также другие фильмы с участием этого актера.

Collaborative filtering
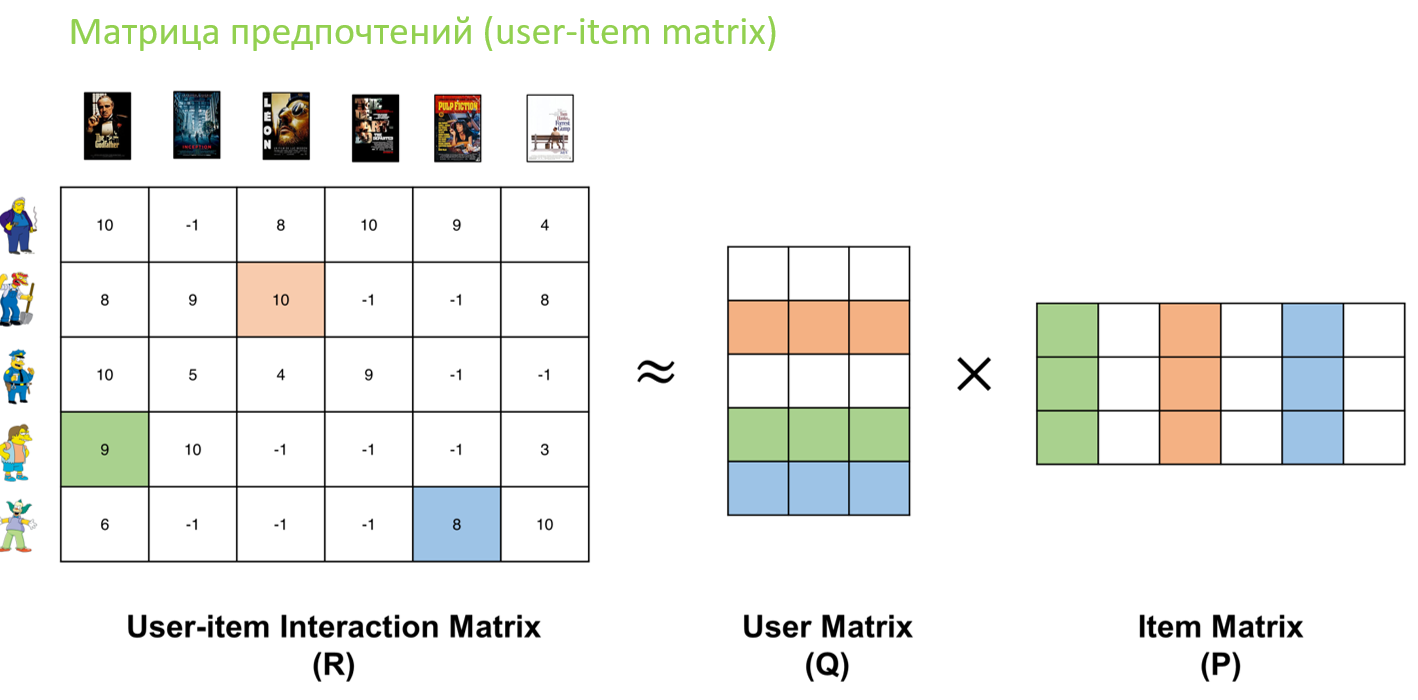
Третий тип — коллаборативная система (collaborative filtering). Она основывается на сопоставлении пользователей и товаров (или услуг, новостей и т.д.). Математически и графически в данном случае мы работаем с матрицами предпочтений (user-item matrix).

Основная предпосылка таких систем заключается в том, что предыдущих данных пользователей должно быть достаточно для создания прогноза. То есть нам не нужно ничего, кроме исторических данных, пользовательского ввода, текущих трендовых данных и так далее. Он считается одной из очень умных рекомендательных систем, которые работают на сходстве между разными пользователями, а также на товары, которые широко используются в качестве веб-сайтов электронной коммерции, а также веб-сайтов онлайн-фильмов. Он проверяет вкус похожих пользователей и дает рекомендации.
Сходство не ограничивается вкусом пользователя, более того, может учитываться сходство между различными предметами. Система будет давать более эффективные рекомендации, если у нас будет большой объем информации о пользователях и товарах.
Что такое User-item matrix?
Матрица полезности показывает предпочтения пользователя в отношении определенных элементов. В данных, полученных от пользователя, мы должны найти некоторую связь между элементами, которые нравятся пользователю, и теми, которые ему не нравятся, для этого мы используем матрицу полезности. В нем мы присваиваем определенное значение каждой паре пользователь-элемент, это значение известно как степень предпочтения. Затем мы рисуем матрицу пользователя с соответствующими элементами, чтобы определить его отношения предпочтений.
В совместной фильтрации используются два подхода:
а) Совместная фильтрация ближайших соседей на основе пользователей (user-based)
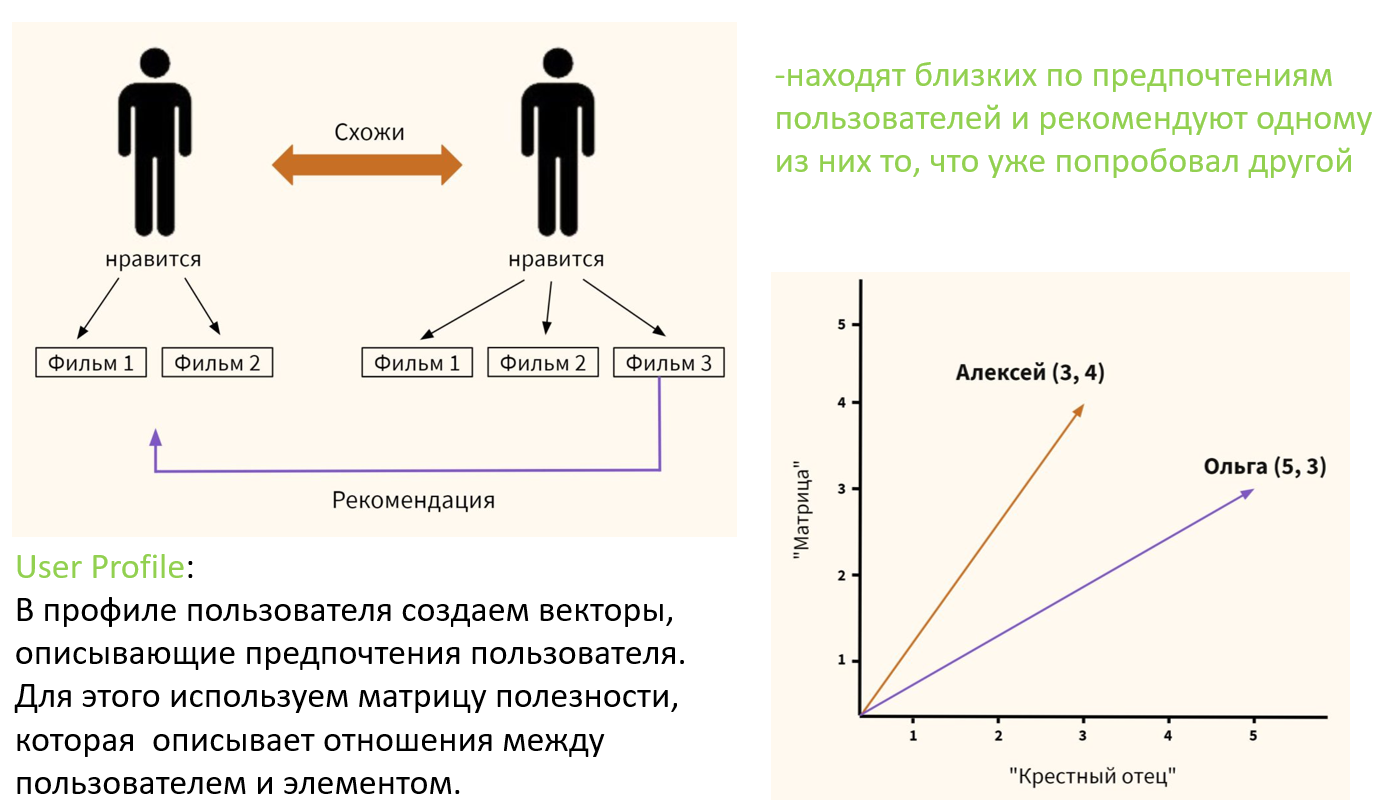
Коллаборативные системы, основанные на пользователях (user-based), находят близких по предпочтениям пользователей и рекомендуют одному из них то, что уже попробовал другой.
User Profile:
В профиле пользователя мы создаем векторы, описывающие предпочтения пользователя. При создании профиля пользователя мы используем матрицу полезности, которая описывает отношения между пользователем и элементом. С помощью этой информации лучшая оценка, которую мы можем сделать относительно того, какой элемент нравится пользователю, — это некоторая агрегация профилей этих элементов.
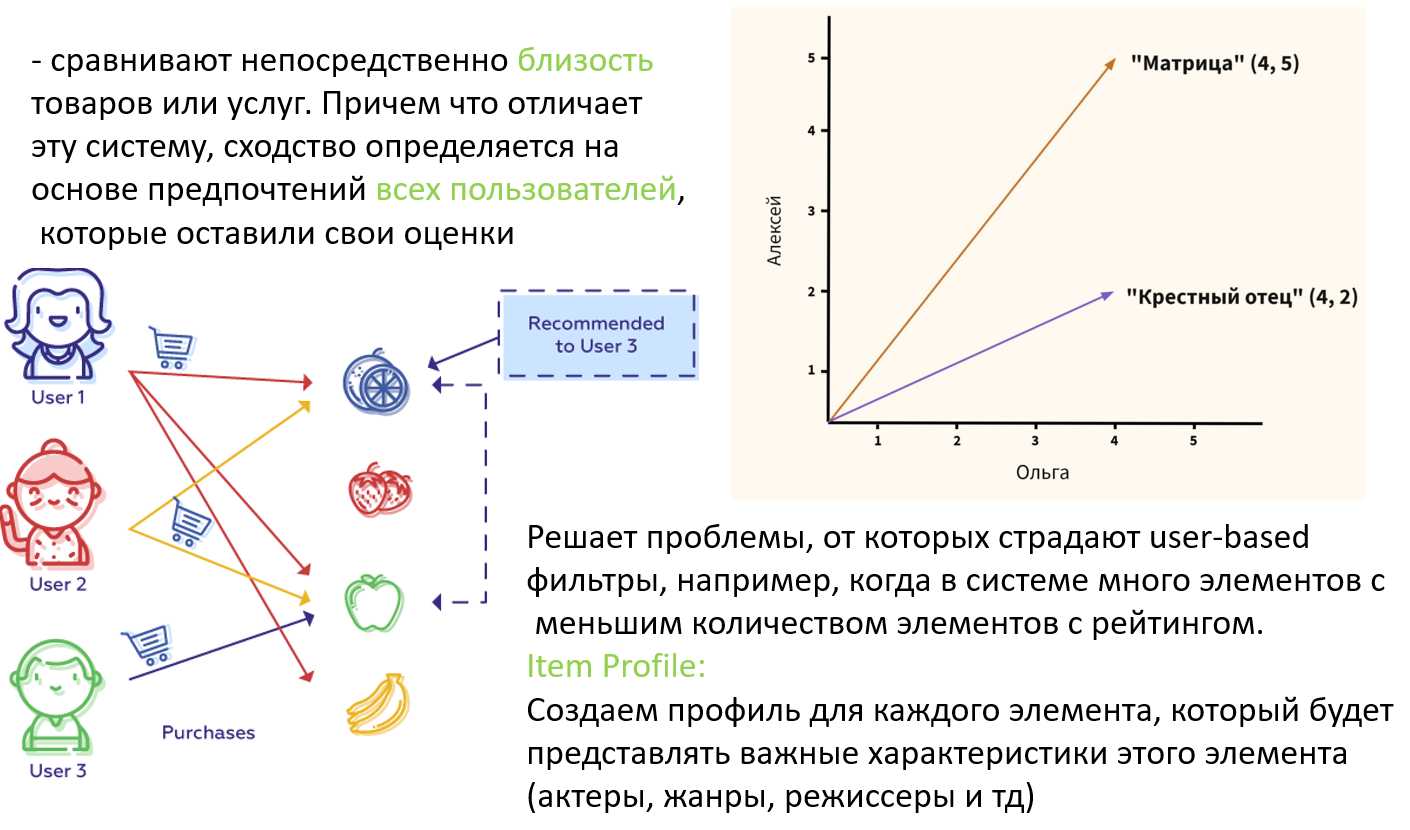
b) Совместная фильтрация ближайших соседей на основе элементов (item-based)
Системы, основанные на предмете рекомендации (item-based), сравнивают непосредственно близость товаров или услуг. Причем что отличает эту систему, сходство определяется на основе предпочтений всех пользователей, которые оставили свои оценки.
Item Profile:
В Content-Based Recommender мы должны создать профиль для каждого элемента, который будет представлять важные характеристики этого элемента.
Например, если мы делаем фильм как объект, то его актеры, режиссер, год выпуска и жанр являются наиболее значимыми характеристиками фильма. Мы также можем добавить его рейтинг из IMDB (база данных фильмов в Интернете) в профиле товара.
На этом мы закончим с ознакомлением с системами и перейдем к самому интересному — коду.
Немного о данных
Датасет я создала свой собственный, содержащий в себе данные об аниме (японской анимации) с сайта MyAnimeList(MAL). Очевидно, ниже приведенный код может быть использован для других наборов данных.
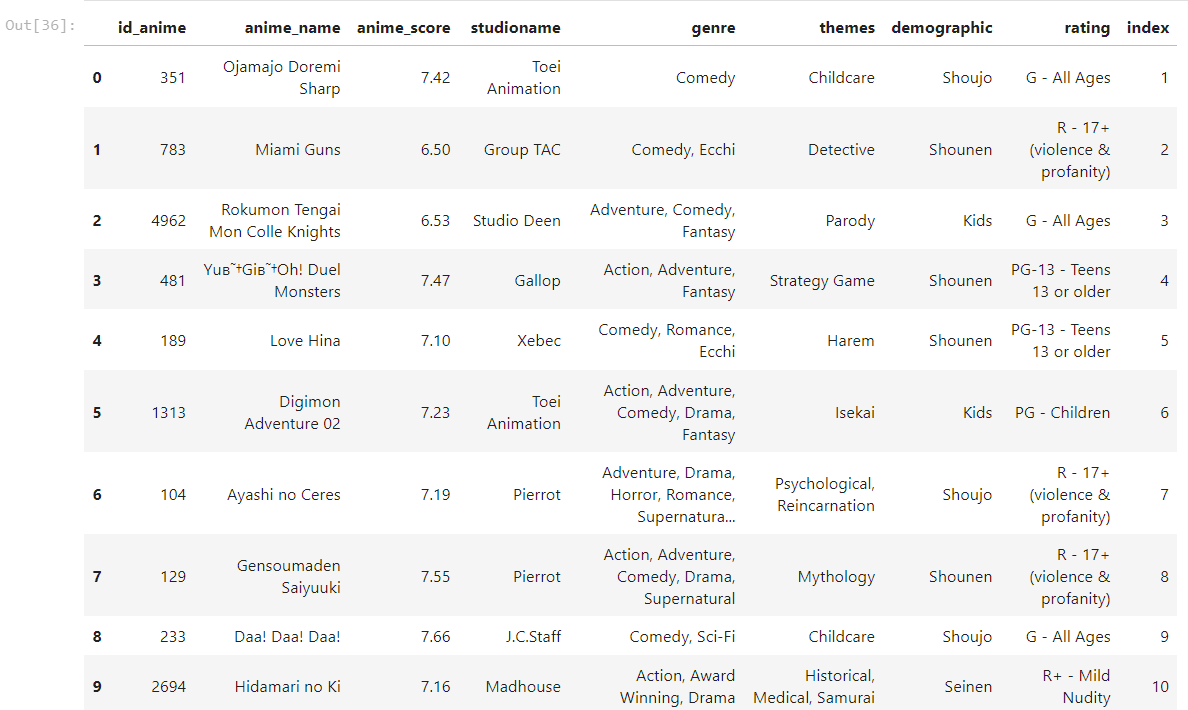
Проведем небольшой анализ данных, чтобы иметь общее представление с чем же все таки работаем.
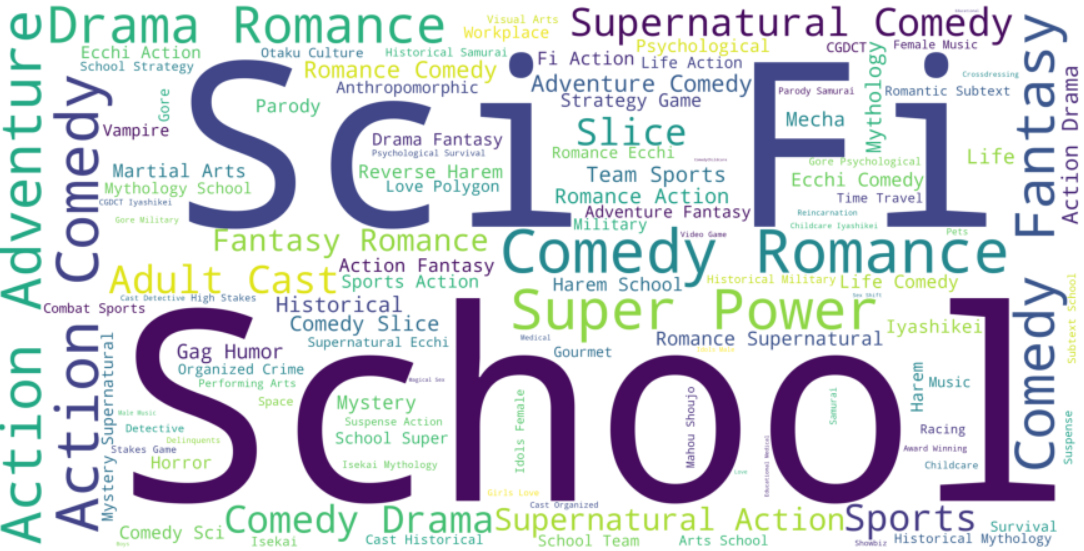
Посмотрим, какие жанры и теги чаще всего встречаются.
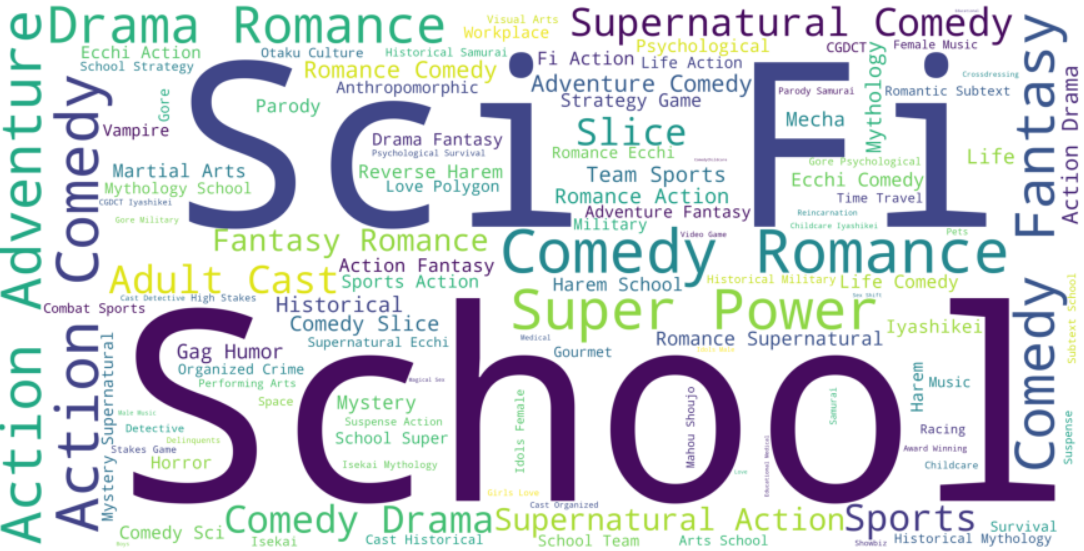
Самые популярные жанры – школа, научная фантастика, экшен, комедия и романтика. Самый популярный тег – суперсилы.
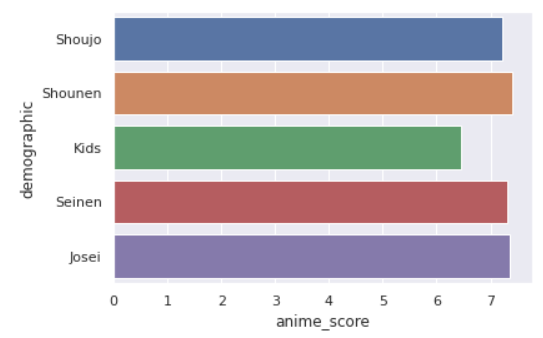
Чаще всего высокие оценки у сененов (аниме, рассчитанные на юношей до 18-ти лет), но в целом результаты почти одинаковые.
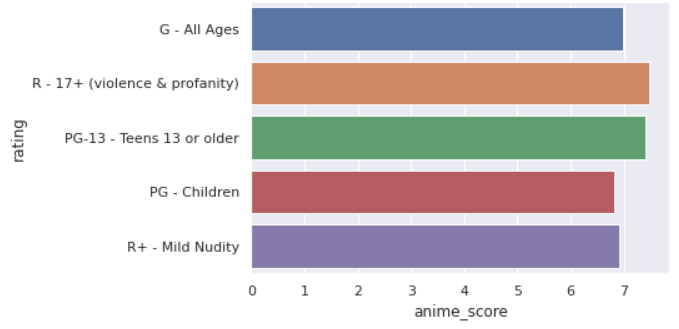
Высокие оценки имеют аниме с рейтингами R-17 и PG-13, то есть большинство аниме рассчитано на подростков от 13 до 17 лет.
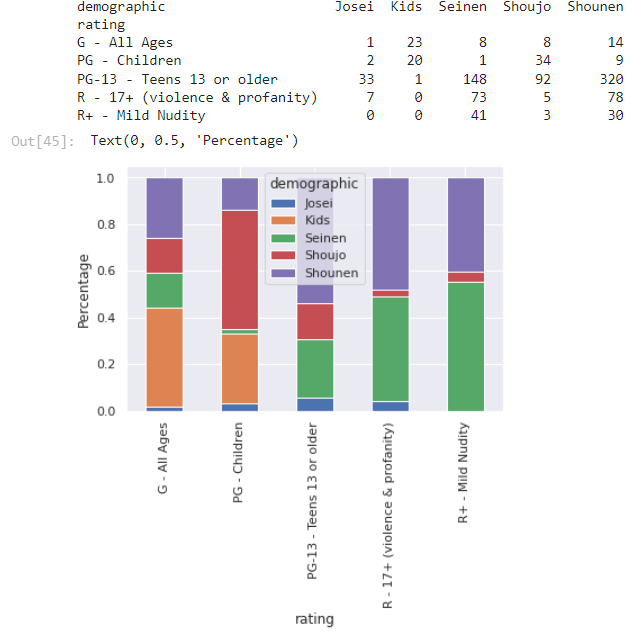
Аниме для детей имеют возрастной рейтинг для всех или для детей (до 13). Сёдзе (произведение для девушек до 18 лет) чаще всего имеет рейтинг для детей. Чем выше возрастное ограничение, тем увеличивается процент содержания сененов и сейненов (произведение для юношей до 18 и старше соответственно)
Выделим релевантные параметры для рекомендаций.

Рекомендательная система (Content Based)
Для меры сходства (Cosine similarity) выберем linear kernel (ядра являются мерами сходства, т.е. s(a, b) > s(a, c), если объекты a и b считаются “более похожими”, чем объекты a и c), так как это быстрее.
Теперь у нас есть матрица парного косинусного сходства (cosine similarity) для всех фильмов в нашем наборе данных. Следующим шагом будет написание функции, которая возвращает 30 наиболее похожих фильмов на основе оценки косинусного сходства.
Наконец, проверим, как работает наша модель
Теперь сравним полученный список рекомендаций с рекомендациями на популярных сайтах (на примере аниме “Vinland Saga”)

Самый популярный сайт на западе (MAL): Shingeki no Kyojin, Dororo, Kenpuu Denki Berserk, 91 Days, Golden Kamuy, Kingdom, Arslan Senki, Shingeki no Kyojin: The Final Season, Mushoku Tensei, Youjo Senki… – совпадает более чем на 70% с полученными результатами. Некоторые произведения не вошли, так как у них не были заполнены некоторые параметры или они вышли раньше 2000-х. Сайт, где рекомендации основываются полностью на отзывах пользователей (AnimePlanet): Shingeki no Kyojin, Berserk, Dororo, One Piece, Arslan Senki, Shoukoku no Altair, Akatsuki no Yona, Shingeki no Kyojin 3, Jormungand, Kingdom, Shigurui, Golden Kamuy 2, 91 Days, Kiseijuu… – похожие результаты как и выше. Можно сделать вывод, что система рекомендаций довольно хорошо работает – она показывает результаты, наиболее похожие на введенное аниме.
Одна из особенностей построенной системы рекомендаций заключается в том, что она рекомендует фильмы независимо от рейтингов и популярности.
Поэтому добавим механизм, где также учитывается рейтинг рекомендуемых произведений. То есть будем советовать не только наиболее похожие по тегам и жанрам, но и по популярности.

По сути объединили две системы, основанные на контенте: одна принимала на вход демографический параметр и возрастный рейтинг, а другая – метаданные, такие как студия, жанр и темы для составления прогнозов. А также разработали простой фильтр, чтобы отдать предпочтение фильмам с высоким рейтингом.
Источники


Посмотреть полную реализацию кода:

2К открытий7К показов

Что такое Security Operations Center. Показываем, как SOC защищает данные. Рассматриваем основные метрики и нюансы ✔ Tproger

Создайте свою собственную поисковую систему на PHP без внешних сервисов. Используйте токенизацию, веса и реляционные базы данных для точного и быстрого поиска по тексту. Полное руководство по реализации, индексированию и поиску.

Продвинутая версия Gemini от Google DeepMind завоевала золотую медаль на IMO 2025, решив 5 из 6 задач. Впервые модель на естественном языке прошла официальную проверку жюри олимпиады — и доказала, что способна рассуждать, как лучшие молодые математики планеты.

Иван Якунин, продуктовый аналитик команды Fintech Marketplace, рассказал про то, как в Авито работают с Vertica, и на примерах объяснил, что такое проекции, и когда их стоит использовать.