Selenium: пишем парсер для меняющегося сайта
Разобрали на примере, как работает Python selenium и настроили бота, который будет отсылать находки в Telegram.

Перед большинством Python-разработчиков рано или поздно встает вопрос сбора данных из сети. У дата-сайентистов, например, этот навык вообще считается само собой разумеющимся, и трудности освоения парсинговых библиотек принято проскакивать как нечто простое. На деле же легко упереться и в меняющиеся классы, и в необходимость проскочить защиту сайта.
В этой статье мы разберемся, как обходить защиту в виде меняющихся классов и изучим некоторые нюансы этой популярнейшей библиотеки,
Выбираем сайт
Для гайда я выбрала ресурс otzivisotrudnikov.ru, поскольку он позволяет не только провести парсинг, но и попробовать сопутствующие действия selenium вроде ожидания появления страницы и нажатия кнопки «Загрузить еще».
Если вы только осваиваете скрэйперы, к сложным порталам, сопротивляющимся парсингу, пока подступаться не стоит. Среди них — все продукты Яндекса, а также Авито. Некоторые популярные площадки вроде HeadHunter, «ощутив пауков на себе», поступили демократично и создали API для выгрузки данных.
Подготовка среды разработки
Для начала импортируем необходимые библиотеки:
Загоняем инструментарий в файл requirements.txt:
Создаем виртуальное окружение и устанавливаем инструменты:
Я хочу наладить коллекцию пауков таким образом, чтобы новые отзывы отправлялись мне в Telegram. Для этого предстоит создать бота. Чтобы получить ключ, перейдите по адресу my.telegram.org/apps, авторизуйтесь и создайте приложение (документация). API Key лежит в поле App api_hash:
Чтобы получить ID чата, добавим туда бота @RawDataBot и запустим командой /start. В ответ он отдаст массив, среди которых есть и идентификатор:
Это целочисленная переменная, знак минус тоже оставляем:
Чтобы получить токен, нужно пообщаться с @BotFather — утилитой для создания и настройки ботов. Если у вас пока нет ботов в TG, следуйте этой краткой инструкции.
Когда скрейперов становится слишком много, оптимальным решением будет .env-файл. О работе с этим инструментом можно узнать больше в статье “Using .env Files for Environment Variables in Python Applications”.
Вы могли заметить, что некоторые сайты защищаются от DDoS-атак с помощью спецсервисов. Selenium умеет обходить такие проверки. В случае сайта «Отзывы сотрудников» достаточно подождать несколько секунд, обычно хватает пяти:
Зададим полную ссылку на страницу:
Отзывов много, потому нам потребуется нажать кнопку «Больше». Чтобы это сделать, укажем число нажатий (число страниц пока проверяется вручную):
Инициируем бота для отправки новых отзывов:
Теперь настал через самого Selenium. Инициируем экземпляр веб-драйвера и передадим ему целевую ссылку:
Объявим временные списки, в которых будем хранить тексты отзывов, ссылки на них и дату публикации:
Отдадим команду selenium выполнять поиск элементов на каждой странице:
Как быстрее писать селекторы
Выбор элемента в HTML — одна из сложных вещей для новичков в парсинге. Потому попробую упростить вам дальнейшую работу с помощью концепции XPath. Это язык запросов для веб-страниц, и корректность селектора можно проверить в панели разработчика Chrome:
- нажимаем на любом свободном месте на веб-странице «Просмотреть код» (или комбинацией Ctrl + Shift + C / Cmd + Shift + C);
- выбираем наведением мыши один отзыв со всеми интересующими элементами и копируем название класса (col-xs-10);
- нажимаем комбинацию Ctrl + F / Cmd + F прямо в панели разработчика. Откроется поле поиска по селектору;
- набираем //* (отсылает к всей странице на языке XPath), затем [@class=’col-xs-10′];
Посмотреть, как проверяется селектор, можно на видео.
Записей несколько, потому я использую метод find_elements(). Укажем класс, который предстоит найти:
Теперь результат хранится в специальном объекте selenium-webdriver.WebElement, и чтобы извлечь из него текст, используется метод text().
Звездочка, кстати, помогает справляться с меняющимися названиями классов: вы можете подставлять ее аналогично сочетанию (.*) в регулярных выражениях, и в случае "//*[@class='col-*']" она будет цеплять все объекты классов, начинающихся с col-.
В сниппете ниже я удаляю фразу, которая не нужна в выгрузке заказчикам проекта:
Теперь выделим тем же образом ссылки, они зашиты в кнопки «Читать полностью отзыв и комментарии» (класс ‘read-more-serm‘):
Осталось вычленить время создания отзыва:
Теперь троицу выше превратим в словарь:
Преобразуем словарь в таблицу методом pd.DataFrame():
Добавим столбец с автоматическим индексом:
Сохраним результат в файл.csv:
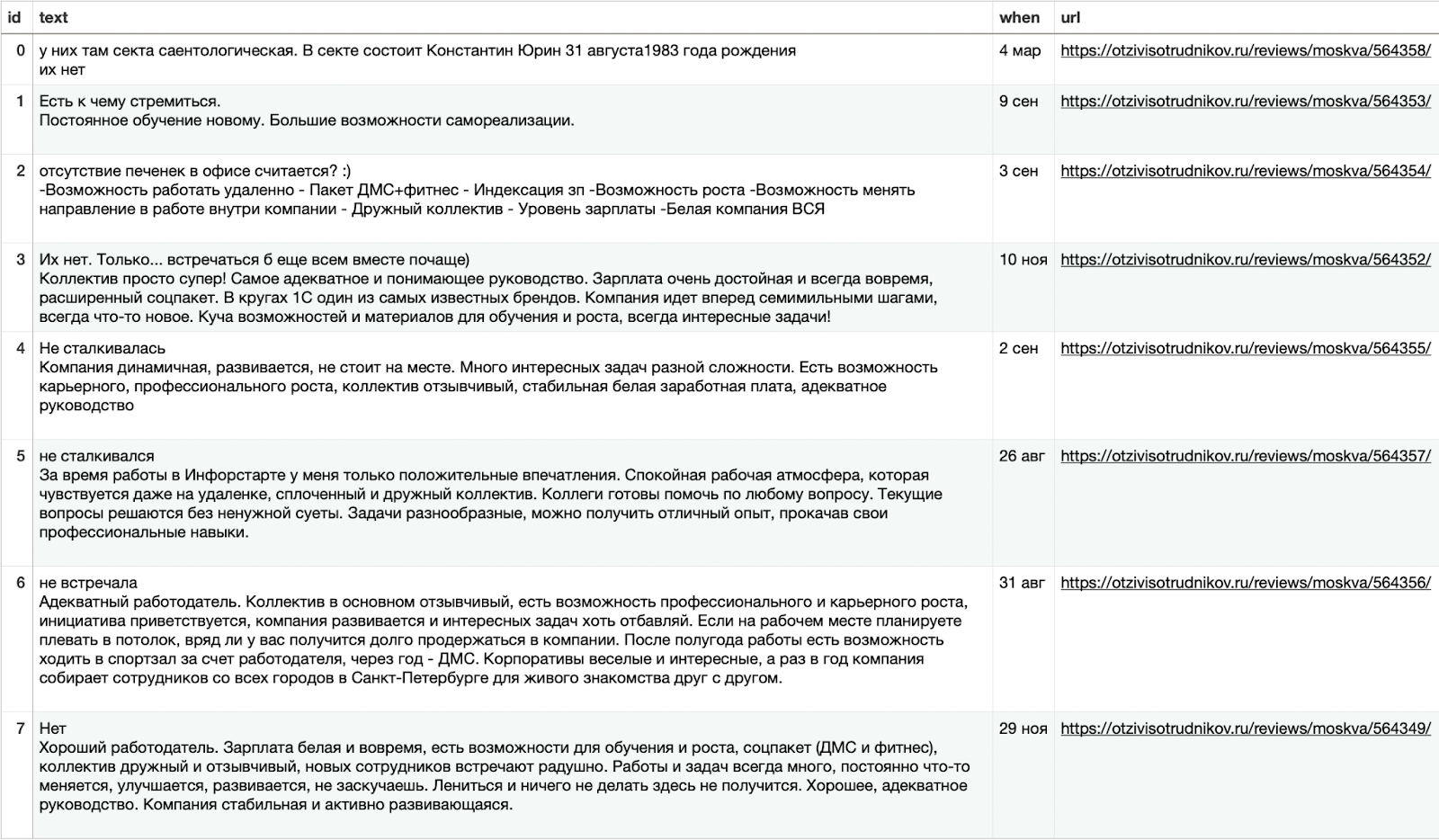
Отправим отзывы по одному в чат Telegram:
Кстати, параметр parse_mode позволяет подключить HTML-разметку и улучшить читаемость отзыва. Разделы «Список льгот», «Что мне нравится в работодателе» и «Что можно было бы улучшить» были «обернуты» полужирным шрифтом (…):

Заключение
Конечно, существуют и low-code решения для сбора данных с веба, однако полную управляемость по-прежнему обеспечивают лишь самописные инструменты вроде selenium и beautifulsoup4. Подспорьем новичкам в этой нелегкой задаче, где структура HTML-документа то и дело меняется, может стать подборка пауков на GitHub. Добросовестная часть авторов их даже обернула в Docker, а это значит, что процесс деплоя и дотяжки селекторов до актуального состояния займет у вас минимум времени.
Полный код можно посмотреть по ссылке.
Какую библиотеку для парсинга вы предпочитаете?
selenium
beautifulsoup4
Low=-code-инструменты















