


Serverless и Cloud Native: разработка облачных приложений
В чем различие между Serverless и Cloud Native подходами, где и когда эти инструменты использовать, а также достоинства и недостатки каждого подхода.
IT-блогер Дмитрий Рожков в новом ролике рассказал об облачной архитектуре. Какие в современной практике существуют подходы, в чём их сильные и слабые стороны. А также на примере AWS показал, как выстроить Serverless-архитектуру.
Вот, о чём автор рассказал в ролике:
- Облачная архитектура приложений включает в себя ключевые концепции Serverless и Cloud Native, которые предлагают разные подходы к разработке.
- Cloud Native — это подход к разработке приложений с учетом масштабируемости, устойчивости и гибкости на облачных платформах, включая использование микросервисов, контейнеров и DevOps.
- Serverless (бессерверная архитектура) позволяет автоматически управлять вычислительными ресурсами, делая акцент на независимых функциях, выполняемых в ответ на конкретные события.
- Реализация Cloud Native подхода требует изменения инженерной культуры и может столкнуться с трудностями, такими как управление распределенными системами и контроль затрат на облако.
- Serverless идеально подходит для приложений с переменной нагрузкой, так как платформа автоматически адаптируется к изменениям требований.
- Преимущества Cloud Native достигаются за счет применения микросервисной архитектуры, контейнеризации и оркестрации, а не просто переноса существующих приложений в облако.
- Cloud Native не требует использования публичной облачной платформы и может работать на частных облаках или дата-центрах.
- Serverless может привести к существенной экономии для приложений с редкими вызовами функций, но может быть дорогим при резком увеличении нагрузки.
- Использование бессерверных компонентов позволяет собрать полноценную архитектуру приложения, включая вычисления, интеграцию систем, уведомления и хранение данных.
- Мультиоблачный подход демонстрирует, что основные компоненты и принципы Serverless доступны у разных облачных провайдеров, хотя и под разными названиями.
Ниже — транскрибация ролика.
Облачная архитектура
Serverless и Cloud Native являются двумя ключевыми концепциями в современной разработке облачных приложений, но они служат разным целям и предлагают разные подходы к архитектуре и развертыванию.
Чтобы говорить про облачную архитектуру, нужно сперва разобраться, что делает приложение Cloud Native. Если я просто использую облако для хостинга сайта, это уже Cloud Native или надо обязательно лямбды использовать? Может ли Cloud Native приложение работать не в облаке? Если коротко, то ответы на эти вопросы такие – нет, нет и да. Как и с DevOps, точное определение сложно дать.
Что такое Cloud Native?
Cloud Native, как его определяют сами облачные провайдеры и Cloud Native Computing Foundation (или CNCF), это подход к построению, развертыванию и управлению современных приложений на облачных платформах.
Cloud Native — подход, при котором вы на этапе проектирования закладываете возможность масштабировать приложение эластично на определенной платформе.
Что такое эластичная? Это значит, что инсталляцию можно быстро нарастить в ответ на возросшую нагрузку и также просто сжать обратно, когда нагрузка ушла. В идеале, чтобы это происходило автоматически. Распределенная платформа означает, что у вас точно больше одного сервера, которые еще и распределены географически, скорее всего.
Также выделяют несколько столпов Cloud Native:
- микросервисы;
- контейнеры;
- имутабельная инфраструктура;
- декларативный API;
- DevOps;
- CI/CD.
То есть буквально если у вас микросервисы на Kubernetes, то ваше приложение уже почти Cloud Native.
Эти приложения разрабатываются с учетом масштабируемости, устойчивости и гибкости, что позволяет им легко адаптироваться к изменяющимся требованиям и условиям. Понятное дело, бизнес меняется, условия постоянно меняются, нагрузка изменяется, то растет, то падает. И, соответственно, ваша архитектура должна быть достаточно гибкой и эластичной, чтобы отвечать на все эти изменения безболезненно.
Проблемы и сложности Cloud Native подхода
Несмотря на все преимущества, на практике реализовать такую систему не так уж и легко. Скорее всего, если вы раньше не работали с такими приложениями, то вашей команде придется изменить инженерную культуру, а не просто поменять какие-то фреймворки.
Вот только некоторые трудности, с которыми вы можете столкнуться.
Первое – это распределенные системы. Их сложно удерживать в голове, сложно проектировать, сложно вообще понимать, что там происходит. Если где-то что-то отвалилось, не всегда легко проследить почему это произошло. Поэтому обычно в таких инсталляциях используют продвинутое логирование, мониторинг и так называемая трассировка или трейсинг, когда у вас там весь запрос логируется через все сервисы, как он конкретно проходил, чтобы можно было вообще хоть что-то понять. Из-за количества переменных спастись можно только правильным подбором инструментов, как я уже сказал, и процессов разработки, тестирования и деплоя.
Тестировать тоже придется в распределенной структуре. Точно так же у вас, если есть кластер Kubernetes — обычно у вас есть три кластера Kubernetes как минимум. Это тестовый, это стейджинг и это продакшн кластер, собственно. А то еще и у каждой команды свой кластер может быть, в общем как только у вас появляется Kubernetes, вы сразу начинаете обрастать кластерами. Но это пример, можно и без Kubernetes делать Cloud Native.
Второе — не получится один раз настроить процессы, чтобы они работали. Это должно стать частью каждодневной работы. Инструменты также будут устаревать, требовать обновления, процессы будут давать сбой. Приготовьтесь постоянно мониторить эффективность, обсуждать с командой решения и привносить их в жизнь. Собственно, это и есть тот самый культурный сдвиг.
Третье — стоимость облака легко может выйти из-под контроля. В каждой компании, где я работал, всегда была инициатива сокращения расходов на инфраструктуру. Даже если она не была как бы изначально, то она в какой-то момент все равно появлялась.
Возникали всякие сервисы Janitor, типа мусорщик или дворник, которые там чистили какую-то инфраструктуру, которую забыли отключить. И постоянно приходили какие-то письма «вот столько мы тратим, столько надо сэкономить». В общем, достаточно просто посмотреть, сколько в этой нише создано стартапов. У меня даже есть друг, один хороший бывший коллега, который, собственно, тоже сделал стартап по оптимизации затрат на инфраструктуру. То есть, соответственно, эти стартапы, они зарабатывают на оптимизации ваших расходов. Такие бухгалтеры инфраструктуры, что ли.
Четвёртое — у вас просто может не быть нужного опыта и навыков. Как я сказал раньше, программирование распределенных систем существенно отличается от монолитов и как бы обычного какого-то программирования, которому мы все учимся. А тут не только программирование другое, но и как бы всё окружение другое, деплой другой, вся идеология. Поэтому я всегда стараюсь пробить для своей команды курсы или книги, когда нам нужно перейти в новую экосистему.
Например, сейчас для нас это Kubernetes, и, собственно, я рекомендовал нашим ребятам курсы по Kubernetes пройти.
Самая главная трудность, с которой вы можете столкнуться, если вот вы ее преодолеете, то дальше это уже все дело техники, я считаю, что это сопротивление. И тут я могу говорить часами, только, к сожалению, не имею права выносить такие вещи на публику, ну и это как бы было бы неэтично на самом деле.
Сопротивление изменениям – это основная причина, почему компании не могут перейти на Cloud Native, да и не только на Cloud Native, а вообще в принципе любые изменения сделать.
У людей как бы всё норм, зарплата платится, а тут надо что-то учить, какие-то процессы новые.
Тут надо работать на самом деле как с любым Change Management. Вы начинаете с какой-то инициативной группы, прототипа, который запускается и успешно работает, а потом просто вовлекаете все больше и больше людей.
Но несмотря на все сложности, для определенного масштаба Cloud Native это, считай, единственный подход, несмотря на исключения, где ребята потратили уйму усилий, но сохранили свои монолиты. И они для них работают, они счастливы.
Но как бы это странно не казалось, монолит он по двум сторонам того самого графика, где у вас интеллект отрицательный использует монолит, посередине вы рубитесь в Cloud Native, а на самом конце спектра вы снова приходите к монолиту.
Штука в том, что знания, которые у вас есть вот здесь, на самом конце спектра, и вы используете монолит, они существенно отличаются от тех знаний, которые у вас были в начале. Я считаю, что чтобы масштабировать монолит, нужно обладать гораздо большими знаниями и инженерной культурой, чем даже для того, чтобы использовать Cloud Native.
Поэтому простое использование услуг облачного провайдера не делает систему Cloud Native. Cloud Native подразумевает глубокую интеграцию с облачной инфраструктурой и использование специфических для облака возможностей и практик.
Преимущества Cloud Native, такие как масштабируемость, устойчивость и гибкость, достигаются за счет применения микросервисной архитектуры, контейнеризации, оркестрации, а не просто за счет переноса существующих приложений в облако.
Таким образом, преобразование традиционного приложения в Cloud Native требует переосмысления и перепроектирования архитектуры и процессов разработки, как я раньше сказал, чтобы полностью реализовать потенциал облачных технологий.
Теперь понятно, почему Cloud Native не требует, собственно, публичной облачной платформы, я надеюсь. И почему, если вы просто выгрузили монолит в AWS, это Cloud, но не Native. Или почему Serverless это Cloud Native, или, вернее, может быть, частью Cloud Native. Но Cloud Native не обязательно Serverless, да?
Если у вас есть частное облако, либо частные дата-центры в разных географических областях, в местах, соответственно, где у вас распределенный Kubernetes кластер, например, и, собственно, поверх него вы гоняете свои микросервисы, которые умеют расширяться и сжиматься, то по большому счету у вас Cloud Native, но вы вроде как не используете публичное облако. Необязательно использовать публичное облако, чтобы быть Cloud Native.
Интересный факт. Облакам уже почти 20 лет. Первые сервисы S3 и EC2 в AWS запустили в 2006 году. Даже AWS Lambda уже 10 лет. Поэтому это уже не что-то новое и непроверенное. Это вполне себе матёрая технология.
Что такое Serverless?
Serverless, или бессервисная архитектура, фокусируется на управлении вычислительными ресурсами автоматически, устраняя необходимость в ручном управлении сервисами.
В контексте Serverless приложения разбиваются на независимые функции, которые выполняются в ответ на конкретные события. Это позволяет разработчикам сосредоточиться на написании кода, в то время как облачная платформа автоматически заботится о выделении и масштабировании ресурсов.
Serverless идеально подходит для приложений с переменной нагрузкой. Поскольку платформа может мгновенно адаптироваться к изменениям в требованиях и к вычислительным ресурсам, оптимизируя затраты и эффективность. Я говорю про функции, но это относится и к другим бессерверным компонентам.
Например, для использования бессерверной базы данных вам не придется беспокоиться о достаточном количестве дисковой памяти. Вы просто заводите нужные таблицы, пишете или читаете данные, а все остальное за вас делает платформа.
Я сказал функции, но функция — это не значит функция программы, единичная функция. Конечно, можно такими минимальными блоками доставлять свой код, но в AWS Lambda можно сложить хоть маленький микросервисик и всё будет вполне нормально работать.
Также важно понимать, что Serverless это скорее про непредсказуемое использование ресурсов. С одной стороны, если функция вызывается редко, то вы существенно экономите в сравнении с другими вариантами инфраструктуры. С другой стороны, если ваша нагрузка вдруг резко возрастает, то вам не придется волноваться о масштабировании. Lambda сделает все за вас, но платить придётся очень много.
Я уверен, что вы читали уже в сети все эти истории, когда человеку внезапно прилетает счет на 100 тысяч долларов, потому что у него там лямбда, кто-то наслал трафик на его сайт и теперь он должен огромные деньги. Такое бывает, да. Если бы у него был просто один сервис, сервер бы просто упал, не справился с нагрузкой. А лямбда с нагрузкой справилась, но теперь надо платить.
Но опять-таки, если вы знаете, что нагрузка будет равномерной и постоянной, то лямбды лучше не рассматривать. Недавно писали много негатива о лямбда, насколько это дорого и медленно. И у всех как будто глаза открылись. Используют технологию не по назначению, а потом технология виновата. Впрочем, ничего нового. То есть даже сам AWS использовал лямбду для определения битого видео. Но штука в том, что у них там эти потоки видео, они постоянно шли. То есть эти лямбды молотили бесконечно.
Понятное дело, что в такой ситуации правильное архитектурное решение — микро-монолитики, которые локально держат эти данные, никуда их там не перегоняют, не сохраняют в облако S3, а локально быстренько всё обрабатывают, и у них расходы на эту инфраструктуру сократились бы на 90%. Как бы ничего нового, даже AWS инженеры делают ошибки, так что думаете перед тем, как использовать бессервисную архитектуру для ваших приложений.
Компоненты Serverless
Вообще, на основе бессерверных компонент можно собрать всю архитектуру. Давайте посмотрим, какие есть компоненты, в частности, на облаке AWS.
Понятное дело, что у любого уважающего себя облака так или иначе будет какой-то похожий набор бессерверных компонент. Но здесь можно понять, что компоненты разделяются на разные модули.
Compute — вычисления. Самый маленький модуль — это AWS Lambda. Это событийная pay-as-you-go модель. Лямбда отвечает не на HTTP request, не на запрос из HTTP, а просто на какое-то абстрактное событие. Этим событием может быть что угодно.
Вы загрузили файл в S3 ведерко, сработало событие, на это событие срабатывает Amazon Lambda, которая что-то с этим файлом делает. Либо, например, отправляет вам письмо. И по большому счету, вся инфраструктура AWS генерирует события. Ко всем этим событиям можно подключиться. Упал сервер, сработало событие, лямбда что-то сделала. Так как лямбда это очень маленький, самый маленький атом вычисления, то у него и ограничения там есть. У него ограничения на размер образа, который получается. У него есть ограничения на то, сколько событий оно может обрабатывать.
И если этого перестает хватать, можно перейти уже, собственно, на AWS Fargate. Это как бы вычислительный движок, который работает напрямую с амазоновским сервисом контейнеров и с сервисом Kubernetes. По большому счету, это уже такие контейнеры, которые поднимаются по запросу.
Как это всё происходит? Если к вашей инфраструктуре долго никто не обращается, то по большому счету Amazon это все положит. Ни одной лямбды не будет крутиться, ни одного контейнера Fargate не будет крутиться. И это может быть небольшой проблемой, потому что у этих сервисов есть так называемый холодный старт.
Холодный старт — это когда к сервису давно не обращались, теперь обратились первый раз и, соответственно, Amazon должен для нас либо поднять контейнер с Lambda, либо поднять контейнер на Fargate. И это время, обычно около 100 миллисекунд, закладывается во время ответа. Понятное дело, что если тут же придет второй запрос, то этот холодный старт уже нивелирован и ответ будет гораздо быстрее.
Так вот, на Fargate можно крутить контейнеры побольше, у них, по-моему, нет тайм-аута. У Lambda, по-моему, полчаса тайм-аут, то есть если Lambda за полчаса не отработала, она падает с 500 ошибкой, а Fargate — это просто контейнер, ну и, соответственно, он и стоит подороже.
Дальше у нас есть компоненты для интеграции систем — Event Bridge, по большому счету это маршрутизатор событий. Чтобы события из одних приложений, либо ноду внешних приложений, в том числе за пределами AWS, и внутренних приложений маршрутизировать между вашими обработчиками событий.
AWS Step Functions. Это сервис, который вам позволяет делать конечные автоматы. Если вы представите, что у вас лямбда функция — это просто функция в вашем коде, то step functions это if-else в вашем коде. И, как пишете ветвящуюся логику прямо в ваших программах, вы точно также можете делать ветвящуюся логику прямо в вашем AWS или в любом другом сервисе.
Приходит, допустим, письмо. Вы проверяете, если это письмо пришло с того-то адреса, то его должна обработать одна лямбда-функция, иначе должна обработать другая лямбда-функция. И, на самом деле, там можно очень сложные workflow, так называемые, делать. Подключать не только лямбда-функции, разные сервисы можно подключать. И дебажить это все, на самом деле, очень удобно. Компонент рисует граф-схему исполнения вашего вот этого workflow и где оно там свалилось. Рекомендую почитать, очень интересно, как это реализовано.
Дальше у нас, понятно, есть очередь — Amazon SQS. Notification service — Amazon SNS, то есть application-to-application или application-to-person. Вы отправляете какие-то уведомления, что что-то произошло. API Gateway — по большому счету, это входная точка для API в вашу систему. Вы там пишете какую-то таблицу ваших раутов, URL-ов и какие сервисы эти URL-ы должны вызывать. Ну и еще здесь есть AWS AppSync — GraphQL API-шки можно делать.

Объектное хранилище Amazon S3, у нас есть полностью эластичная файловая система Serverless — Amazon EFS. Вы, опять-таки, не заботитесь, где там у вас этот диск. Есть ли вообще в природе диски на 100 терабайт или нет? Вы просто подключаете эластичную систему и платите только за то, что вы используете.
Дальше у нас есть NoSQL, то есть key-value база данных DynamoDB, которая тоже масштабируется и вы буквально платите за каждую строчку в этой базе какую-то копеечку плюс за операцию чтения-записи. Есть SQL базы данных, если вам это надо. Ну и куча каких-то других, видите, движков.
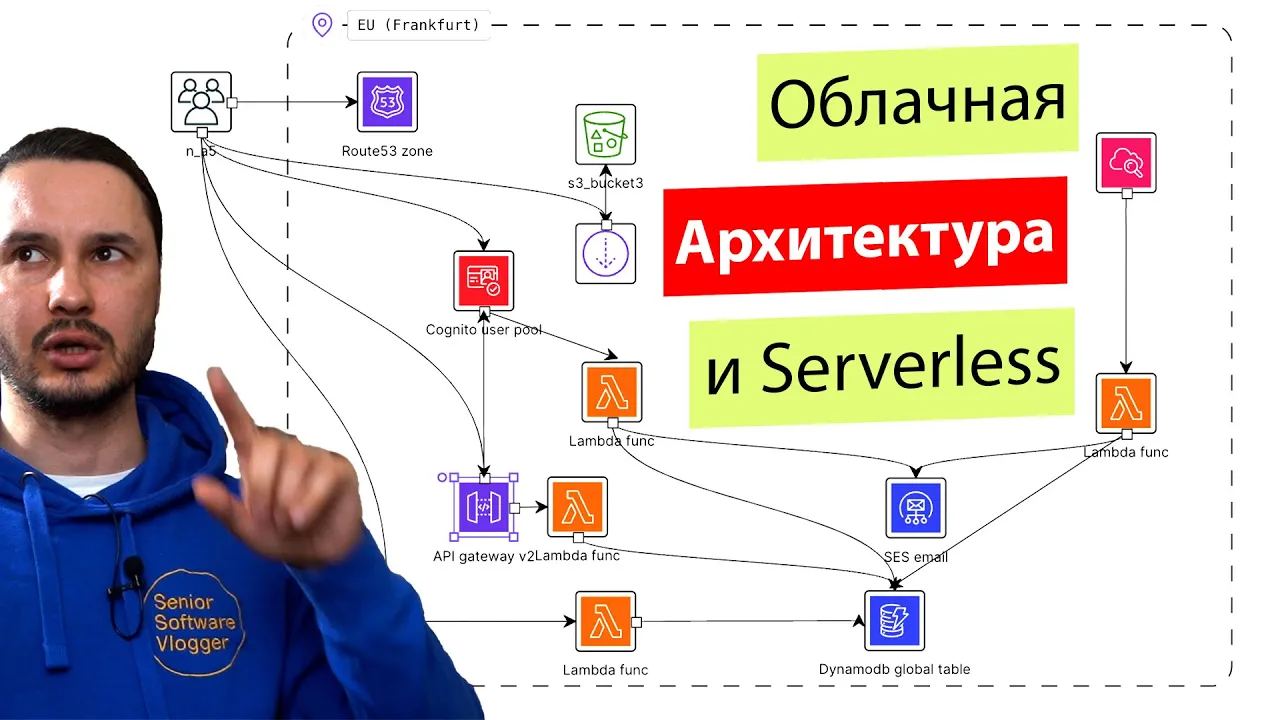
И из этого всего, как вы видите, у нас есть, у нас получается такая себе трехслойная архитектура. Представление можно сделать через S3, CloudFront и API Gateway. Логика на Lambda и Fargate. И, собственно, данные на всём остальном.
Демонстрация
Самое время что-нибудь набросать на этих ваших лямбдах. Переходим к демо.

Здесь они нам предлагают один регион. Ну, в принципе, как бы, наверное, не так страшно. Но это зависит все от вашего сервиса. Возможно, одним регионом вы не обойдетесь. Понятное дело, у нас здесь обозначены наши пользователи, которые каким-то образом стучатся в наше приложение. И наше приложение можно по большому счету посмотреть, что это архитектура, можно сказать, трехслойная. То есть у нас есть какой-то UI, у нас есть какая-то логика, у нас есть какие-то данные. То есть, в принципе, все то же самое, что я рассказывал в своем видео с Lego, можно проследить здесь.
Смотрим что здесь у нас есть понятное дело что нам нужно каким-то образом разрезолвить наши имена dns и для этого у нас есть раут 53 здесь сервис. Дальше Cloud Front Distribution — это CDN или content delivery network, и этот CDN, по большому счету, просто набор кэш-серверов, которые распределены гораздо больше. Получается, что по всему миру есть эти кэш-серверы, и они просто вот этот ваш статический контент делают ближе к пользователю, и, соответственно, время на загрузку, на отклик сайта сокращается. То есть, это очень популярное решение, когда вы, допустим, статику своего сайта выгружаете на CDN, понятное дело, что CDN статику всю берет из S3 ведерка.
То есть S3 это так называемое объектное хранилище. Что значит объектное хранилище? Есть объектное, есть блоковое хранилище. И под блоковым хранилищем можно представить тот самый жесткий диск, который находится у вас прямо в компьютере. И там напрямую вам дают адресовать блоки на диске. А в объектном хранилище эти блоки на диске от вас абстрагированы через абстракцию, ну, файла, можно сказать. То есть, наименьшая единица адресования в объектном хранилище — это файл. А наименьшая единица адресования в блочном хранилище — это, собственно, блок на диске.
Поэтому, если вы, например, хотите запустить какую-нибудь базу данных классическую, типа Postgres, то Postgres понадобится блочное хранилище.
Ну, вот, в общем, туда, в S3, скидывают всю статику вашего сайта. Например, у вас может быть сайт сгенерирован на Next.js. И, соответственно, во время компиляции он генерирует все странички. Все эти странички вы укладываете в ведерко S3. Оттуда их забирает и распространяет CloudFront. И люди могут видеть ваш сайт. Понятное дело, они попадают на ваш сайт через Route 53.
Дальше у нас может быть, возможно, какой-нибудь личный кабинет у нашего покупателя. Допустим, если это магазин на Next.js, для этого используется сервис Cognito. Часть контента нам доступна без логина, часть контента нам доступна с логином. И, соответственно, у нас есть какая-то API, которая позволяет нам, например, добавить наши продукты в корзину, либо что-то купить. Что такое API Gateway? По большому счету, API Gateway — это сервис, который представляет роутинг или перенаправление ваших запросов.
Грубо говоря, в API Gateway вы пишете, какие
URL-ы запроса чем будут обрабатываться.
Например, вы пишете, что ваш /shopping-cart должен обрабатываться, запросы на
эту API-точку должны обрабатываться вот
этой лямбда функцией.
Понятное дело, что он масштабируется, что он держит количество запросов какое-то потрясающее совершенно и позволяет вам прозрачно для пользователя переключать бэкэнды. То есть вы можете, допустим, потом понять, что лямбда-функция не справляется, либо вы решили поменять архитектуру. Здесь вы ничего не меняете, просто перенастраиваете трафик чтобы шёл уже не на лямбда функцию, а там на Kubernetes кластер или еще куда-нибудь. Ну и понятное дело, что некоторые большие файлы, например, документация, или если продаёте технику — прошивки, бинарные файлы. Их можно с ведёрка S3 раздавать напрямую прямо людям.
И понятное дело, что здесь мы смотрим, от ведерка S3 у нас есть обработчик в лямбда-функцию, то есть точно так же через лямбда-функцию, например, в S3 пользователь может что-нибудь загрузить. Если вы продаете футболки и говорите «присылайте нам свои фотографии», вы можете сделать такую связь, что у вас пользователь через лямбда-функцию грузит в S3. Либо эта лямбда-функция также может обрабатывать что-либо по событиям, которые происходят в S3.
Как я сказал, лямбда-функции вообще это обработчики событий. То есть, здесь в частном случае это событие является HTTP request. В то время как в Cognito user pool, например, событием является попытка логина, а в SES email событием может являться отправленный email. Email отправляется, мы это каким-то образом всё сваливаем в CloudWatch Dashboard.
Нужно понимать, что на месте каждого вот этого блока лямбды может быть просто, допустим, какой-нибудь сервис, либо какой-нибудь под в Kubernetes, то есть, это просто единица логики, и лямбду именно так следует понимать. Просто лямбда, она как бы вас подталкивает к тому, чтобы ваша единица логики стала минимально возможной. То есть, если, допустим, при монолитном подходе у вас вся логика в одном монолите находится, в микросервисном подходе у вас там какие-то маленькие микросервисы выделяются. Например, у вас будет микросервис для, собственно, корзины с товарами, который будет и рисовать эту корзину с товарами, и обрабатывать эту корзину с товарами.
Лямбда-функции вообще как бы идеологически должны разделить микросервисы еще дальше. То есть у вас будет одна функция, которая рендерит, собственно, список в корзине товаров. И другая функция, которая работает с этой корзиной товаров, то есть, например, делает заказ. Но это совершенно необязательно этому правилу следовать. Вы вольны разделять ваш код, как вам выгодно. Просто эти лямбда-функции позволяют именно даже вот на таком уровне отдельно масштабировать и тонко настраивать вашу архитектуру.
Забегая вперед, можно как бы использовать лямбда-функции без, собственно, облачных провайдеров. На Kubernetes можно на вашем собственном кластере поднять что-то похожее на лямбда-функции, и лямбда-функции, по большому счету, внутри, под собой, это, насколько я знаю, Firecracker, виртуальная машина.
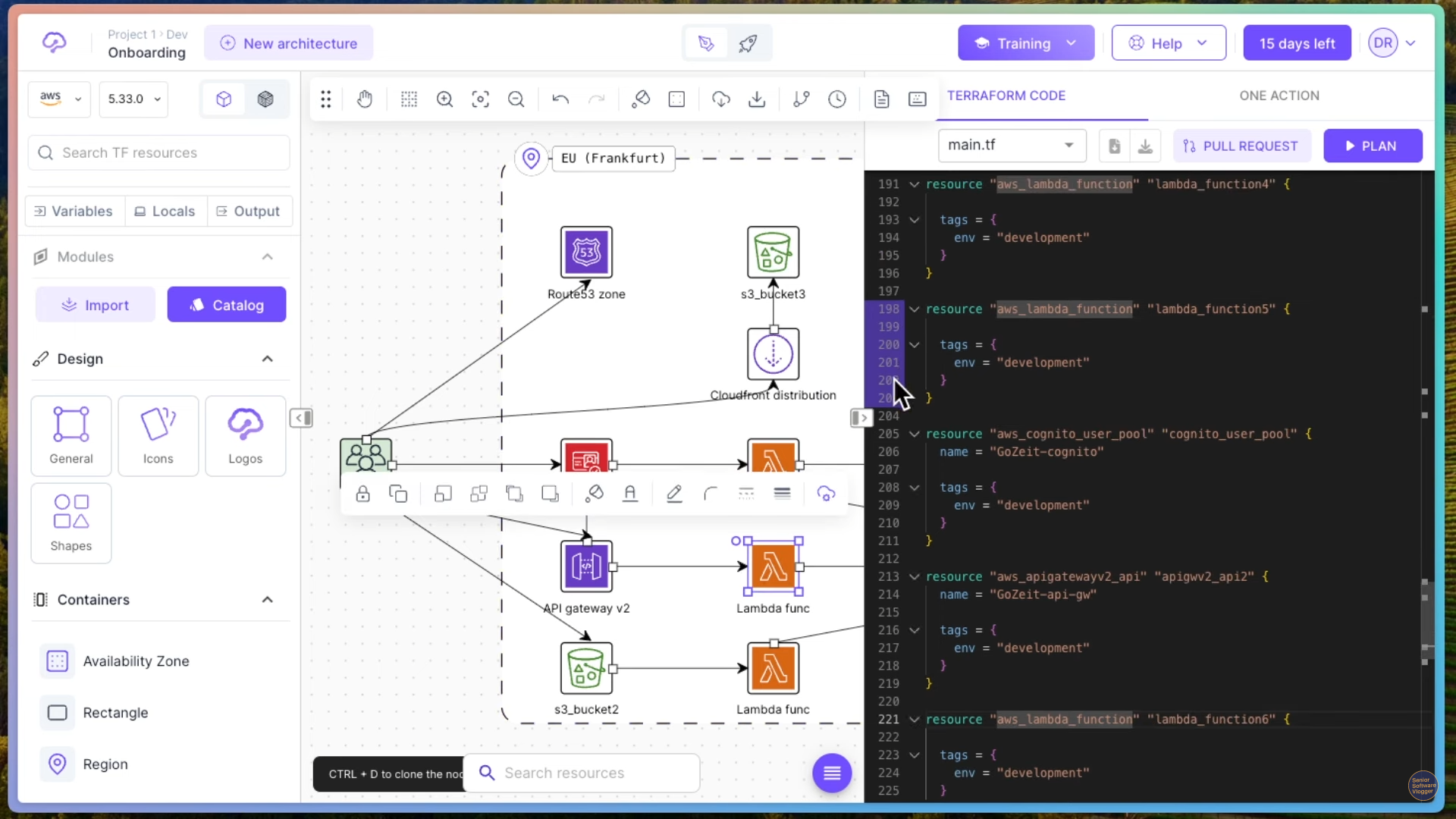
Здесь мы видим на каждый наш блочок, видите, у нас подсвечивается код в Terraform, то есть каждый этот блочок описан каким-то кодом, да, и этот код позволяет нам, собственно, эту инфраструктуру всю поднять. То есть мы уже эту инфраструктуру описываем не как что-то накликанное, руками наконфигурированное в облаке, а буквально пишем код, говорим, у нас есть ресурс. Этот ресурс — AWS Lambda-функция. Такой вот у нее идентификатор, такие у нее теги.
В чем прелесть такого подхода? В том, что вы получаете вместе со своим кодом, вы храните и инфраструктуру. Если человек захочет это все, допустим, скопировать и поднять в другом дата-центре, он может просто нажать Plan Deploy, и у вас, соответственно, это все полетит полетит в ваш продакшен. Или в продакшен того человека. И еще, в чем здесь интересный момент.
Если вы что-то поменяете в Terraform, это не означает, что конкретно вот этот ресурс будет уничтожен и создан заново. Он может быть изменен. То есть, Terraform умеет понимать разницу между изначальной инфраструктурой, то, что загружено, и то, что вы хотите изменить. Потом оно делает такой патч, и применяет только этот патч. То есть, не надо думать, что на каждый деплой ваша вся инфраструктура будет уничтожена и создана заново. Нет. Terraform очень умная штука и умеет делать такие патчи.
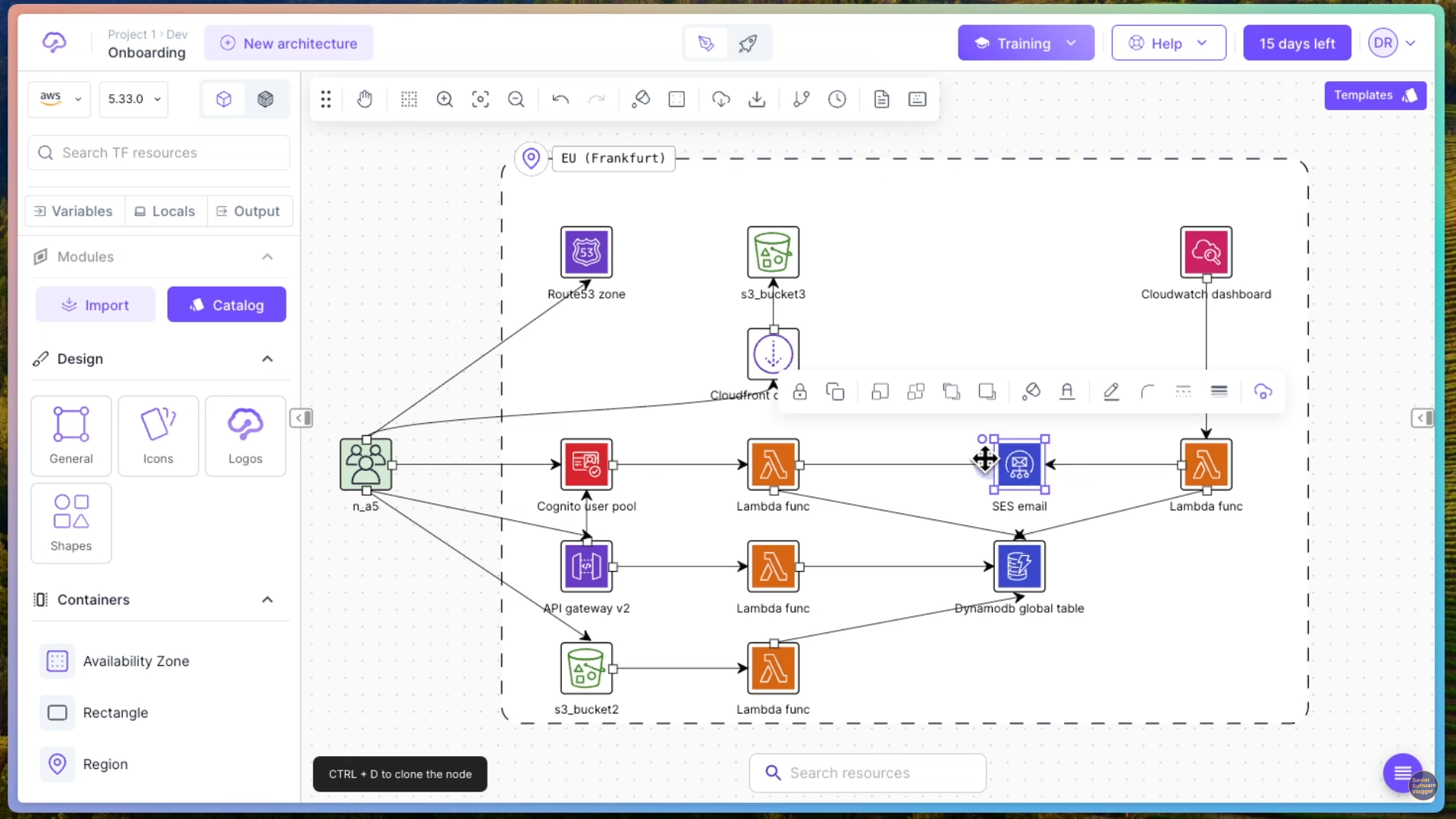
В общем, давайте дальше посмотрим. Здесь я не наблюдаю, допустим, ни очереди, ни системы нотификаций, то есть, SNS-сервиса. Но это на самом деле, можно их как бы добавить сюда, но не суть.
То есть у нас здесь получается есть сервис, который почту отправляет, а здесь у нас есть DynamoDB Global Table, то есть это бессерверная база данных и еще и более того, это база данных Global Table, то есть там все данные синхронизированы между регионами, насколько я знаю. Получается, по большому счету, все. Ну, последнее, что здесь можно посмотреть, это CloudWatch.
CloudWatch это та самая система мониторинга всего магазина, но я думаю, что здесь она привнесена как бизнесовая система мониторинга, а не система мониторинга именно самой инсталляции. То есть, саму инсталляцию вам тоже придется мониторить, понятное дело, здесь у нас очень простой пример, но обычно все так просто не заканчивается. Поэтому без мониторинга обойтись не удастся.

Давайте еще посмотрим. Это уже пример мультиоблачного подхода. Здесь есть наши клиенты. Вот, которые по большому счету приходят в какой-то HTTP-прокси, а прокси их уже раскидывает, видите, и он их раскидывает по облакам прям.
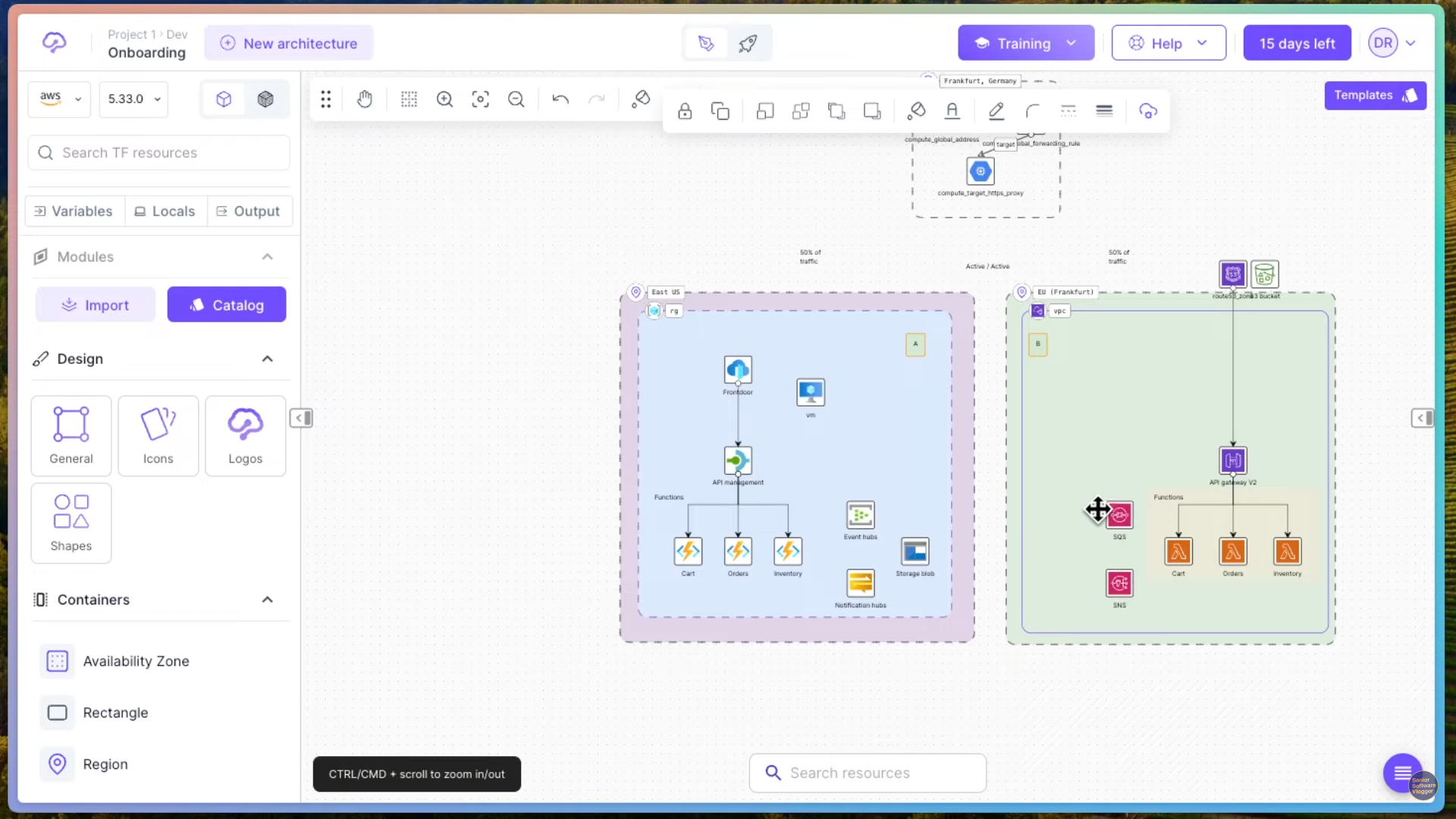
Облако AWS, тот же самый Route 53 Service, та же самая API Gateway, те же самые лямбда-функции, как я сказал, вот корзина, заказики, инвентарь. Тут же у нас есть какая-то очередь, тут же у нас есть какой-то сервис уведомлений. И если мы посмотрим в мир, получается, это у нас что, Azure, да, или что это у нас за облако, то здесь все то же самое есть.
У нас здесь есть API Management, у нас здесь есть какие-то Cloud Functions, у нас есть здесь какие-то Event Hubs, Notification Hubs, и, собственно, хранилище Storage. То есть Storage, это я думаю, что они здесь вот это вот S3 ведерко сэмулировали.
То есть все то же самое можно за набором некоторых исключений, понятное дело, что они не один в один реплицируют все фичи, воруют друг у друга, но все основные вещи есть у любого облачного провайдера, уважающего себя, так скажем.
Таким образом, я думаю, вы заметили, что компоненты все те же самые, просто немножко по-другому называются, и основное различие здесь в гранулярности подхода и в том, кто на самом деле этим всем управляет.
Если сами вашими серверами вы сами управляли, то лямбда функциями или serverless-архитектурой за вас управляет платформа, и сервер от вас абстрагирован. Вы вообще не знаете, сколько там серверов, сколько у них оперативной памяти, как они масштабируются, как они понимают, что нагрузка возросла. Вся эта проблема, вся эта работа от вас абстрагирована. И вы просто пишете код, разделяете ваш код на какие-то логические блоки.
В этом и есть преимущество Serverless. Понятное дело, что сервер там есть, просто вы о нем не беспокоитесь. Для вас сервера нет.