


SQL для начинающих: 10 правил построения «точных» запросов
Научимся писать SQL-запросы, которые будут предоставлять данные в нужном объёме и за минимальное время.
14К открытий22К показов

Денис Карпов
Отдел автоматизации процессов информационных технологий
«Точный» SQL-запрос возвращает «чистые» данные в необходимом и достаточном количестве, при этом потребляет как можно меньше памяти и справляется за минимальное время. Скорость работы с базой влияет на производительность. Потребление памяти может негативно сказаться даже на безопасности. Всё это прямо и косвенно влияет на прибыль компании. В статье разберёмся, как не допускать ошибок.
Для наших целей понадобятся тестовые данные. Будем работать с базой данных Oracle Database. Примеры в статье будут приводиться на языке SQL, PL/SQL. Нам важен подход, который можно адаптировать под другую реляционную систему управления базами данных — РСУБД.
Тестовые данные
⚒ Создадим тестовую таблицу 1:
⚒ Заполним тестовую таблицу 1 данными:
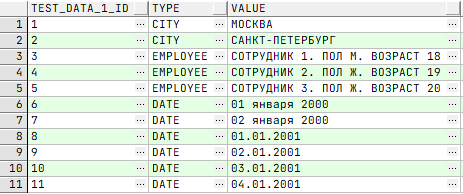
⚒ Создадим тестовую таблицу 2:
⚒ Заполним тестовую таблицу 2 данными:
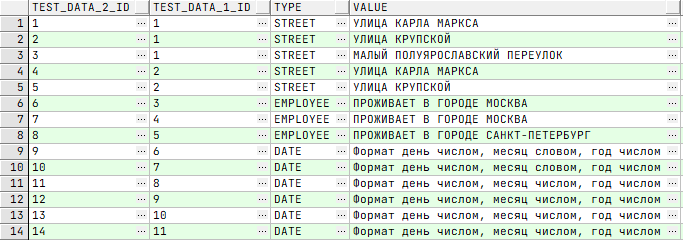
1. Объявляя имена таблиц, обращайся к записям через псевдонимы таблиц
Допустим, есть таблица с некоторым количество колонок. К ней можно обратиться двумя разными способами:
⚠️ Опасный подход:
✅ Безопасный подход заключается в обращении через псевдоним:
Псевдоним (анг. Alias) — это имя, назначенное источнику данных в SQL-запросе при использовании выражения в качестве источника данных или для упрощения ввода и прочтения инструкции SQL. Это полезно, если имя источника слишком длинное или его трудно вводить.
Псевдонимы можно использовать для переименования таблиц и колонок. В отличие от настоящих имён, они могут не соответствовать ограничениям базы данных и содержать до 255 знаков (включая пробелы, цифры и специальные символы).
В случае извлечения данных из одной таблицы без псевдонимов можно обойтись. Рисков нет. Синтаксический анализатор базы данных однозначно знает, данные из какой колонки таблицы запрашиваются. Но рекомендуется всё же использовать их — чтобы выработать привычку.
В случае извлечения данных из нескольких таблиц отказ от использования псевдонимов увеличивает риск получения некорректного результата. Допустим, что у таблиц есть колонки с одинаковым именем. Когда данные извлекаются и SQL-запрос звучит как: «Получаю записи из таблиц колонку А», то о какой колонке «А» идёт речь: из первой или второй таблицы? Если для таблицы назначен псевдоним, то SQL-запрос может звучать уже так: «Получаю записи из таблицы Т1 колонку А».
К SQL-запросу, возможно, придётся вернуться через какое-то время, чтобы внести в него изменения. В таких случаях подсказки в виде псевдонима (alias) помогут определить нужную колонку. Практически со стопроцентной уверенностью будет понятно, из какой таблицы что извлекали.
⚠️ Опасный подход:

✅ Безопасный подход заключается в обращении через псевдоним:
2. Извлекай только те данные, которые планируешь использовать
База данных зачастую является неотъемлемой частью приложения. По мере усложнения функционала в отдельной взятой таблице может увеличиваться количество колонок.
Рассмотрим пример «Карточка сотрудника». У нас есть таблица «Сотрудник» с колонками ФИО, пол, возраст. Данные из них извлекаются и выводятся на форму «Карточка сотрудника». SQL-запрос можно написать следующим образом: «Извлекаю все колонки из таблицы по указанному сотруднику». В таком случае извлекаются все колонки.
⚠️ Опасный подход заключается в извлечении всех данных:
В будущем могут появиться дополнительные колонки в базе данных — например, описание должностных обязанностей или адрес проживания — в рамках нового информационного потока использования базы данных. То есть вне «Карточки сотрудника».
В результате данные по новым полям заполняются уже не только формой «Карточки сотрудника». И SQL-запрос получения информации для формы начинает работать медленнее. Причина в том, что приходится извлекать данные из большего количества колонок.
Деградация скорости получения данных может происходить постепенно или резко — но в самый неподходящий момент. Зачастую это связано с тем, что поля свободного ввода данных могут быть большими. То есть база данных должна больше информации подгрузить в память и потом отдать клиенту, приложение которого не готово к такому потоку данных.
Рассмотрим пример «Телефон». На телефоне пользователя установлено приложение. Сам телефон старый. Пользователь не выполнял обновления программного обеспечения (ПО), но замечает, что с какого-то момента времени приложение начало работать медленнее. У другого пользователя на новом телефоне то же приложение работает быстро. Ошибка «плавающая», но для разработчика неприятная.
Как правило, дело в том, как написано приложение. Данных извлекается больше, чем надо, и более современный телефон, у которого памяти больше, этого не заметит. Но старый не может себе этого позволить.
Чтобы таких неожиданностей не возникало, нужно извлекать строго те данные, которые требуется использовать и показывать на форме. В данном случае нужно было написать: «Извлекаю колонки ФИО, возраст, пол из таблички сотрудника, с фильтрацией по сотруднику».
✅ Безопасный подход заключается в получении нужных данных:
3. По максимуму используй данные, которые извлёк из таблицы
Каждый SQL-запрос к базе данных чего-то стоит. В тот момент, когда данные извлечены и находятся в памяти, надо по максимуму использовать то, что получено, чтобы оптимизировать время и ресурсы.
После обращения к таблице Table1, нужно постараться написать SQL-запрос так, чтобы не пришлось извлекать данные из неё несколько раз. Это не всегда возможно, но попытаться стоит.
⚠️ Опасный подход:

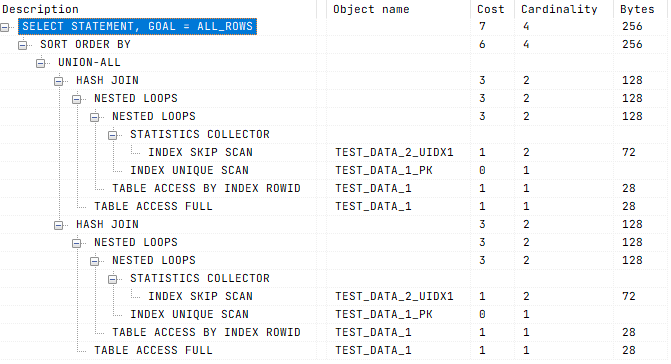
✅ Безопасный подход заключается в использовании полученных данных максимально продуктивно:

Неоптимальный SQL-запрос может выполняться дольше, уронить инфраструктуру и даже повлиять на безопасность системы.
⚒ Рассмотрим тестовый пример:
Рассмотрим пример «Работа ЦОД». Есть Центр Обработки Данных (ЦОД). В нём, на одном из ресурсов внутри приложения, выполняется некий SQL-запрос, который постепенно использует всю доступную память без ограничений. И приложениям, которые стоят на том же ресурсе, со временем перестаёт хватать памяти на стабильную работу. Это может привести к их падению.
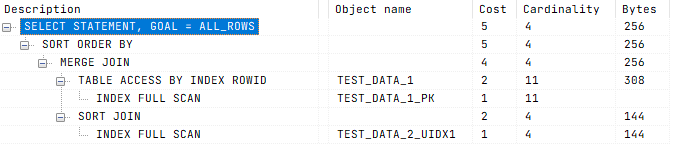
4. Проверяй запросы SQL на индексы
SQL-запросы бывают простые и сложные. Иногда извлекается мало данных, иногда — много. Если таблица большая, и в ней очень разнообразные данные, то в зависимости от того, как обращаться к этим данным, использовать индекс или нет, можно потерять время.
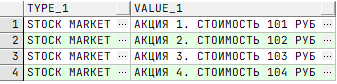
Рассмотрим пример «Брокерская биржа». В рамках отдельного процесса извлекаются данные для покупки-продажи акций. Используя оптимизированный SQL-запрос, можно быстро получать информацию, по какой цене торгуется каждая акция. И делать прогноз — покупать или продавать.
Если SQL-запрос не оптимизирован, извлечение данных занимает больше времени. И пользователь вынужден ждать, хотя мог за это время сделать что-то, что принесло бы ему деньги.
Индексы — это инструмент оптимизации извлечения данных. Конечно, это не панацея, и если таблица маленькая, по ней проще пройти прямым перебором и получить данные.
Добавим в тестовую таблицу 1 новые данные:
⚠️ Опасный подход заключается в игнорировании использования индексов:

Добавим в тестовую таблицу 1 новый индекс
✅ Безопасный подход заключается в использовании индексов:

Рассмотрим пример «Доставка почты». Показательный пример работы индексов — доставка почты из точки А в одном городе, в точку Б в другом. Зная, куда конкретно нужно доставить посылку, мы можем идти по индексам и определить, где и когда повернуть, чтобы довезти посылку за максимально короткое время. Если везти посылку на машине, то это сокращает расход топлива — а значит, и материальные издержки на доставку.
В противном случае можно сворачивать не там, спрашивать дорогу у прохожих, которые знают её плохо. И, вместо того чтобы доставить посылку за Время Т1, опоздать на Время Т2. В итоге покупатель ждёт, а продавец теряет деньги.
5. Начинай запрос SQL с таблицы с меньшим набором записей
Допустим, нам нужно соединить две таблицы: с маленьким количеством записей и с большим. Стоит сделать следующее:
- начинать извлечение данных из таблицы с меньшим набором данных;
- продолжать извлечение данных из таблицы с большим набором данных.
⚒ Добавим в тестовую таблицу 2 новые данные:
Если поступить наоборот, то мы потеряем время, потому что перебирать данные из большей таблицы дольше.
⚒ Рассмотрим тестовый пример:

Рассмотрим пример «Очередь клиентов». Есть поток клиентов, каждого из которых нужно обслужить. Операторы, заполняя форму «Анкета» задают серию вопросов. Один из них, влияет на дальнейший ход общения: «Вам исполнилось 18 лет?». Если клиент отвечает нет, то оператор прекращает общение, иначе продолжает задавать вопросы.
Если оператор задаст вопрос про возраст в конце общения, то любой потенциальный клиент должен будет заполнить всю анкету, даже если в этом нет смысла. Рациональный подход в общении с клиентами помогает операторам за одно и то же время обслужить большее число клиентов. С базами данных всё так же.
6. Не допускай декартового произведения между таблицами
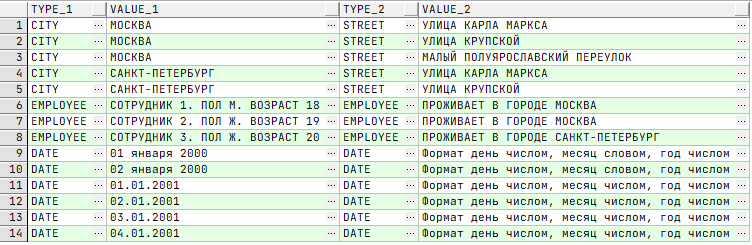
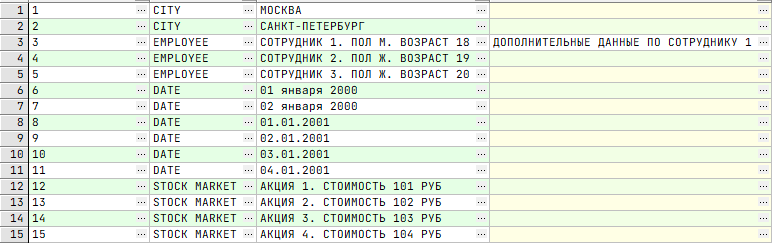
Результатом декартового — или перекрёстного — произведения множеств будет такое множество, элементами которого являются все возможные упорядоченные пары элементов исходных множеств. Рассмотрим пример «Адрес». Возьмём две таблицы «Город», «Улица». В первой таблице «Город» есть две записи: Москва и Санкт-Петербург. Во второй таблице «Улица» сохранены следующие записи:
- улица Карла Маркса, которая одновременно есть и в Москве, и в Санкт-Петербурге;
- улица Крупской аналогично и в Москве, и в Санкт-Петербурге;
- Малый Полуярославский переулок только в Москве.
Пишем запрос: «Получаю из таблицы «Улица», которые принадлежат городу Москва».
⚠️ Опасный подход:

SQL-запрос написан без условия, то есть: «Извлекаю улицы, относящиеся к городам, без соединения таблиц». База данных, не понимая, по какому городу делается SQL-запрос, соединит со всеми улицами и Москву, и Санкт-Петербург. Всего вернётся 2* 5 = 10 записей.
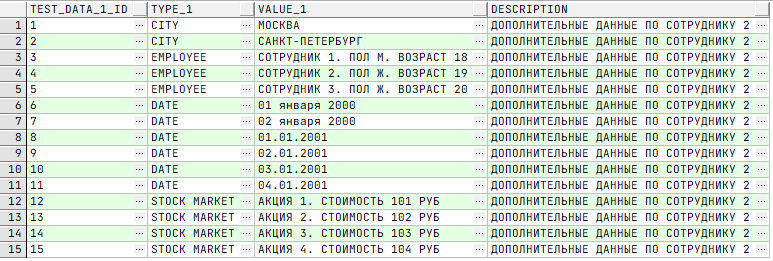
✅ Безопасный подход заключается в наличии связей:

Этот SQL-запрос написан с условием, то есть: «Извлекаю улицы, относящиеся к городу Москве, соединяя две таблицы условием». В нём указывается, по какому городу нужно выполнить фильтрацию. Поэтому возвращено 3 записи.
Когда данные извлекаются больше чем из одной таблицы, важно, как они соединяются между собой. Неправильное соединение будет возвращать неверные данные и не в ожидаемом количестве.
7. Проверяй, что имена параметров процедур не совпадают с именами колонок
Процедуры, функции могут использоваться для разных целей. Одно из возможных предназначений — обновление записей в таблице.
Допустим, есть строковый параметр А, который передаётся на вход процедуры с целью фильтрации. Можно сказать, что написано так: «Обновляю таблицу, задав новое значение для колонки, где выполняется фильтрация по колонке А равной параметру А». В этом случае наблюдается полное совпадение А = А. База данных обновит все записи в этой таблице.
Чтобы этого не было, параметру добавляют префикс или постфикс. Например, параметр будет называться не А, а РА. В изменённом виде можно сказать, что написано так: «Обновляю таблицу, задав новое значение для колонки, где выполняется фильтрация по колонке А равной параметру PА».
⚠️ Опасный подход:
⚠️ Опасный подход:
✅ Безопасный подход заключается в передаче параметра, имя которого не совпадает с именем колонки в таблице:

8. Следи за временем выполнения SQL-запроса
Время, пожалуй, один из самых бесценных ресурсов. Пренебрежение за контролем времени выполнения SQL-запроса приведёт к трате усилий и денег.
Рассмотрим пример «Мониторинг времени выполнения». Допустим, на уровне базы данных продуктовой среды настроен специальный триггер. Его предназначение сводится к следующему:
- прерывать сессию, которая выполняется дольше N-минут;
- сохранить информацию об SQL-запросе в журнал для последующего анализа или постановки на мониторинг.
Вариант триггера на таблицу с искусственно генерируемой ошибкой в момент обновления данных:
Специалисту рассказывали про этот триггер. Он проигнорировал это или забыл — и реализовал, поставленную задачу на непродуктовой среде таким образом, что одно из действий выполняется больше N-минут. Передал всё на установку в продуктовую среду. Получилось, что реализованный функционал не работает полностью или частично.
Вариант процедуры с искусственно завышенным временем выполнения
Задача специалиста смотреть на поставленную задачу шире, учитывая разные аспекты, применяя разные подходы. Можно попробовать оптимизировать SQL-запрос, например, добавляя индексы. Можно менять алгоритмы выполнения действий, добиваясь требуемого результата.
9. Используй копию данных для построения отчётности
Отчётность — это извлечение массива данных из базы для последующей обработки, аналитики, построения прогноза, прочее. Для неё может извлекаться значительный объём данных.
Рассмотрим пример «Отчёт о расходах за период». У нас есть промышленная среда, на которой развёрнуто приложение с подключением к базе данных. С приложением работают сотрудники. Задачей одних является внесение информации о приходе и расходе денежных средств. Задачей других — подготовка отчёта о расходе денежных средств за период. Информация вносится периодически и в небольшом объёме. Извлекается реже, но вся, что была внесена за конкретный период.
При ограниченных ресурсах базы данных извлечение может приводить к замедлению работы приложения. Потому что на стороне БД подключаются сотрудники из обеих групп, ресурсы делятся между ними, и отклик происходит медленнее. Избежать подобного эффекта можно при помощи копии базы данных с применением механизма репликации. Так, клон клон с определённой периодичностью синхронизируется с основной базой данных (их может быть несколько).
Создание копии базы данных — задача администраторов базы данных (Database administrator, DBA). Для большего погружения в механизм репликации можно обратиться к официальной справочной информации соответствующей базы данных. Например:
- Oracle — Setting Up Replication (oracle.com);
- MSSQL — Учебник. Подготовка к репликации – SQL Server | Microsoft Learn;
- PostgreSQL — PostgreSQL : Документация: 15: Глава 27. Отказоустойчивость, балансировка нагрузки и репликация : Компания Postgres Professional.
- MySQL — MySQL :: MySQL 8.0 Reference Manual :: 17.1.2.6 Setting Up Replicas.
Взаимодействие с базой данных можно трансформировать следующим образом. Сотрудники, которые вводят информацию, так и продолжают работать с основной базой данных. Сотрудники, которые заняты отчётностью, работают с её копией. Информационные потоки разведены. Влияние устранено.
10. Проверяй формат данных
Бывает, что отчёт, который обычно работает хорошо, возвращает ошибку, если ввести другие входные данные. Это связано с тем, что у новых входных данных другой формат.
Рассмотрим пример «Отчёт». У нас есть отчёт, строящийся на данных, которые заполняются внешним приложением. Одна из его колонок — дата. Поле ввода на форме, в которой происходит её заполнение — строковое. В подавляющем большинстве случаев формат: день числом, месяц числом, год числом, например, 01.01.2001. Изредка — день числом, месяц словом, год числом, например, «1 января 2001».
Приложение позволяет вводить в любом виде. Конечные пользователи ошибку не видят, но для отчёта это — потенциальная проблема. Она может заключаться в неверном предположении, что дата всегда заносится в базу данных в одном виде.
⚠️ Опасный подход заключается в игнорировании формата используемых данных:
✅ Безопасный подход заключается в понимании формата используемых данных:

Наличие разных данных можно узнать заранее. Для этого, когда делается отчёт, можно выполнить проверку на всех данных, а не только на части. Это — залог стабильной работать и уверенность, что созданный отчёт будет работать.
Вспомним, что написано выше, и закрепим правила:
- Объявляя имена таблиц, обращайся к записям через имена таблиц.
- Извлекай только те данные, которые планируешь использовать.
- По максимуму используй данные, которые извлёк из таблицы.
- Проверяй запросы SQL на индексы.
- Начинай запрос SQL с таблицы с меньшим набором записей.
- Не допускай декартового произведения между таблицами.
- Проверяй, что имена параметров процедур не совпадают с именами колонок.
- Следи за временем выполнения SQL-запроса.
- Используй копию данных для построения отчётности.
- Проверяй формат данных.
От автора
Подходов к оптимизации великое множество. Цель статьи — пробудить интерес искать и находить места роста производительности и снижения издержек. И помните Зако́н Ме́рфи: «Если что-нибудь может пойти не так, оно пойдёт не так».

14К открытий22К показов
Рассказали, как устроена система омниканальной рассылки без сложной персонализации и как реализовать что-то похожее с отправкой в Telegram
Рассказываем про обязанности и инструменты интеграционного системного аналитика в банке и объясняем, что ждут в компании от соискателей.
Разобрали несколько популярных методологий управления проектами и обсудили их плюсы и минусы.
Рассказали о том, как мы настраиваем CI/CD и автоматически обновляем не только отдельные системы, но всю тестовую среду из многих систем.