


Сравниваем модели семантического поиска: от классики до трансформеров
Сравниваем различные мультиязычные методы для создания эмбеддингов с помощью поиска по документам наиболее релевантного к запросу.
2К открытий6К показов

Для создания векторных представлений текстовых документов на разных языках, стоит рассмотреть использование моделей на основе трансформеров, таких как BERT, RoBERTa или их мультиязычные версии, например, mBERT или XLM-R. Они хорошо подходят для обработки текстов на разных языках и способны захватывать семантические связи между словами и предложениями.
Мультиязычные модели — mBERT и XLM-R — обучены на текстах на нескольких языках, что делает их идеальными для работы с документами на английском, русском и других языках. Это позволяет избежать необходимости обучать отдельные модели для каждого языка. Сегодня сравним модели по ключевым запросам на разных языках и определим, что же подходит лучше.
Преимущество трансформеров
Современные NLP-модели, основанные на архитектуре трансформеров, значительно улучшили качество обработки текстов. Сегодня они позволяют учитывать контекст слов, работать с несколькими языками одновременно и легко интегрируются в различные проекты.
В сравнении с традиционными методами векторизации текста (TF-IDF или word2vec), трансформеры обеспечивают более точное понимание смысла, что критично при поиске похожих документов, машинном переводе и анализе текста.
Рассмотрим ключевые преимущества трансформеров и их влияние на обработку естественного языка.
1. Качество представления: Модели на основе трансформеров обеспечивают высокое качество векторных представлений благодаря своей способности учитывать контекст слов в предложении. Это позволяет лучше понимать смысл текста, что особенно важно для поиска похожих документов.
2. Мультиязычность: Мультиязычные модели, такие как mBERT и XLM-R, обучены на текстах на нескольких языках, что делает их идеальными для работы с документами на английском, русском и других. Это позволяет избежать необходимости обучать отдельные модели для каждого языка.
3. Гибкость и доступность: Эти модели доступны через популярные библиотеки, например, Hugging Face Transformers, что упрощает их интеграцию в проекты. Можно легко загрузить предобученные модели и использовать их для генерации векторов.
Какие бывают модели
Рассмотрим различные доступные модели для создания эмбеддингов на разных языках.
LaBSE — модель, которую можно использовать для отображения 109 языков в общее векторное пространство. Она заимствована из предобученной BERT, поэтому её также можно использовать для любых задач, к которым можно применить BERT. Производительность зависит от конкретной задачи. Полученные векторные представления также могут быть использованы для классификации текста, семантического сходства, кластеризации и других задач обработки естественного языка.
Multilingual E5 Large — модель инициализируется из xlm-roberta-large и непрерывно обучается на смеси многоязычных наборов данных. Она поддерживает 100 языков из xlm-roberta, но языки с недостаточными ресурсами могут испытывать снижение производительности.
paraphrase-multilingual-MiniLM-L12-v2 — разновидность SBERT. Она отображает предложения и абзацы в 384-мерное векторное пространство и может быть использована для таких задач, как кластеризация или семантический поиск. Сам SBERT представляет собой модификацию BERT (LaBSE), оптимизированную для создания векторных представлений предложений и документов.
Sentence-BERT (SBERT) модификация предварительно обученной сети BERT, которая использует сиамские и триплетные сетевые структуры для получения семантически значимых вкраплений предложений, которые можно сравнивать с помощью косинуса подобия. Это позволяет сократить время поиска наиболее похожей пары с 65 часов при использовании BERT / RoBERTa до примерно 5 секунд при использовании SBERT, сохраняя при этом точность BERT.
USE — это модель от Google, предназначенная для создания векторных представлений предложений и документов. Поддерживает мультиязычность и предоставляет готовые решения для векторизации.
mBERT — это версия BERT, обученная на многомиллионных текстах на 104 языках, предназначена для решения задач обработки естественного языка (NLP). Обратите внимание, что эта модель в первую очередь — для тонкой настройки на задачах, в которых для принятия решений используется все предложение (потенциально замаскированное): классификация последовательностей, классификация лексем или ответы на вопросы.
XLM-R — модель, основанная на RoBERTa и предназначенная для кросс-языкового понимания. Она обучена на большом количестве данных на различных языках. XLM-R значительно превосходит многоязычный BERT (mBERT) в ряде межъязыковых тестов.
Сравним модели
У нас есть набор из четырех документов на разных языках и поисковый запрос на испанском. Наша задача — определить, какой из документов наиболее релевантен запросу, измеряя косинусное сходство между векторными представлениями запроса и документов:
`documents = [
“Cats and dogs are the most popular pets in many households, bringing joy and companionship to families.”,
“Le nouveau zoo ouvrira ses portes le week-end prochain, offrant une expérience unique aux visiteurs.”, # Новый зоопарк откроется в следующие выходные, предлагая посетителям уникальные впечатления.
“鶏肉の料理方法は、まず鶏肉を洗い、調味料を加えてマリネした後、オーブンで焼きます。”, # Чтобы приготовить курицу, сначала ее промойте, добавьте приправы и замаринуйте, затем запеките в духовке.
“Слоны – это крупные животные с длинными хоботами, известные своей умной и дружелюбной природой.”
]
Документы:
- 🐶 Английский — о домашних животных (кошки и собаки).
- 🦁 Французский — об открытии зоопарка.
- 🍗 Китайский — рецепт приготовления курицы.
- 🐘 Русский — о слонах.
Запрос:
✅ "¿Cuánto pesan los elefantes?" (Сколько весят слоны?)
Анализ результатов
Мы сравнили модели по двум основным критериям:
- Точность — насколько уверенно модель ставит правильный документ на первое место.
- Разница между 1-м и 2-м местом — если разница слишком мала, модель может легко ошибиться при другом наборе данных.
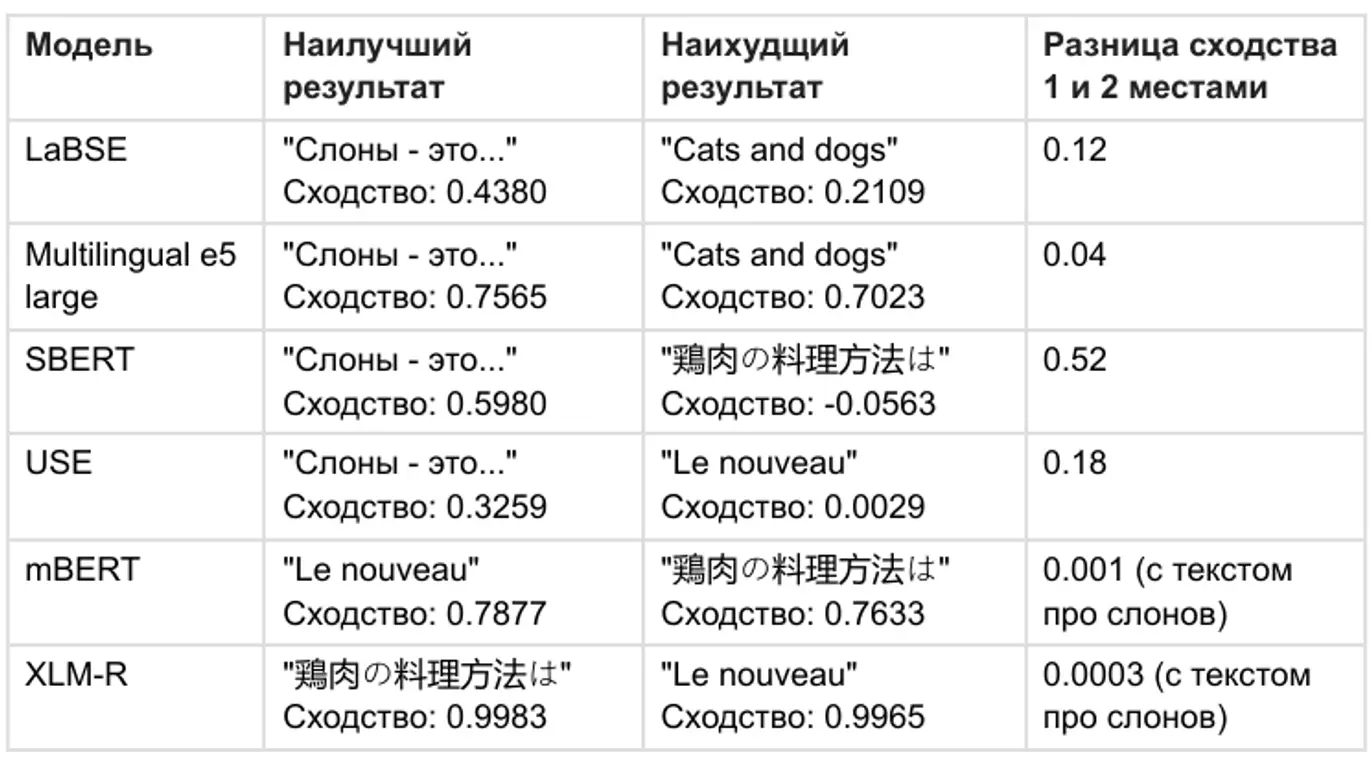
Лучше всего себя показали SBERT (paraphrase-multilingual-MiniLM-L12-v2) и USE. Обе модели хорошо справляются с многозадачным мультиязычным сравнением и точно определяют, что документ на русском о слонах наиболее релевантен запросу.
Современные методы обработки текста показывают, что SBERT-модели остаются наиболее надежными для поиска схожих текстов в многозадачных и многоязычных сценариях. USE также показал хорошие результаты, но SBERT оказался чуть точнее за счет более продвинутой архитектуры.
Если важна интуитивная интерпретируемость и высокая точность в мультиязычных задачах, стоит обратить внимание на SBERT и его производные модели.

2К открытий6К показов

Узнайте, стоит ли использовать антивирус в 2025 году и как выбрать защиту для Windows и Linux. Анализ 7 главных мифов: от нагрузки на систему до эффективности против новых угроз. Обзор EDR-решений и встроенных защитников..

Microsoft сделала ИИ-ассистентов обязательными: теперь использование Copilot влияет на аттестацию и входит в систему оценки сотрудников

95% россиян принимают соглашения без чтения — узнайте, какие риски скрывают длинные тексты: от скрытого сбора данных до потери прав на контент. 🔒 Анализ UX-ловушек, опасных пунктов в документах VK, Яндекса и Ozon, и новые законы РФ. Практические советы: как защитить данные и читать договоры осознанно в 2025 году.

Почему work-life balance — миф: инженер из Кремниевой долины объяснил, зачем жертвовать личным временем ради карьерного роста