


Архитектура Stack Overflow версия 2016

9К открытий9К показов
Данная публикация является первой в серии, посвященной архитектуре Stack Overflow. Рады приветствовать.
Чтобы получить представление о том, как все работает, начну со среднестатистических данных Stack Overflow за день. Для того чтобы вы могли сравнить текущие данные с предыдущими, — по состоянию на ноябрь 2013 года, — привожу показатели за 9.02.2016 и их отличие от статистики на 12.11.2013.
- 209 420 973 (+61 336 090) HTTP-запросов к балансировщику нагрузки.
- 66 294 789 (+30 199 477) из них приходится на загрузку страниц.
- 1 240 266 346 053 (+406 273 363 426) байт (1.24 TB) исходящего HTTP-трафика
- 569 449 470 023 (+282 874 825 991) байт (569 GB) совокупный входящий трафик.
- 3 084 303 599 266 (+1 958 311 041 954) байт (3.08 TB) совокупный исходящий трафик.
- 504 816 843 (+170 244 740) SQL-запросов (только от HTTP-запросов).
- 5 831 683 114 (+5,418,818,063) хитов Redis.
- 17 158 874 (за 2013 г. данные отсутствуют) поисковых запросов Elasticsearch.
- 3 661 134 (+57,716) запросов по меткам.
- 607 073 066 (+48 848 481) мс (168 часов) потрачено на выполнение SQL-запросов.
- 10 396 073 (-88 950 843) мс (2.8 часов) потрачено на хиты Redis.
- 147 018 571 (+14,634,512) мс (40.8 часов) потрачено на запросы генератора меток.
- 1 609 944 301 (-1,118,232,744) мс (447 часов) потрачено на обработку ASP.NET.
- 22 71 (-5.29) мс — среднее значение обработки страницы (19.12 мс для ASP.NET) для 49 180 275 страниц, сгенерированных по запросам.
- 11 80 (-53.2) мс в среднем (8.81 мс в ASP.NET) для 6 370 076 сгенерированных домашних страниц.
Вас может удивить резкое падение времени обработки для ASP.NET по сравнению с 2013 годом (на тот момент оно составляло 757 часов) на фоне увеличения количества запросов на 61 млн. в день. Этому есть две причины: обновление аппаратного обеспечения в начале 2015 года, и серьезная работа по настройке производительности самих приложений. Не стоит забывать: производительность важна. Если вы хотите узнать об аппаратном обеспечении больше — не беспокойтесь, в следующей публикации мы предоставим детальную спецификацию аппаратного обеспечения для всех серверов, используемых сайтами (ссылку на материалы я предоставлю, как только они будут опубликованы).
Итак, что изменилось за последние два года? Кроме замены некоторых серверов и сетевого оборудования, не так уж и много. Вот список аппаратного обеспечения, на котором работают сайты в настоящий момент (с указанием отличий от 2013 г.):
- 4 Microsoft SQL сервера (2 из них — на новом железе).
- 11 IIS веб–сервера (новое железо).
- 2 сервера Redis (новое железо).
- 3 сервера меток (2 из 3 — на новом железе).
- 3 сервера Elasticsearch (аналогично)
- 4 балансировщика нагрузки HAProxy (два были добавлены для поддержки CloudFlare).
- 2 сети (каждая на Nexus 5596 Core + 2232TM Fabric Extenders, с увеличенной пропускной способностью до 10Gbps).
- 2 межсетевых экрана Fortinet 800C (замена Cisco 5525-X ASA).
- 2 маршрутизатора Cisco ASR-1001 (замена маршрутизаторам Cisco 3945).
- 2 маршрутизатора Cisco ASR-1001-x (новые!).
Что же нам нужно для работы Stack Overflow? По сравнению с 2013-м годом изменилось немногое, но в связи с оптимизацией и упомянутым обновлением аппаратного обеспечения, все, что нам нужно — один-единственный веб-сервер. Благодаря случаю, мы уже несколько раз успешно это проверили. Уточню: я лишь говорю, что это работает, я не утверждаю, что работа на одном сервере — удачное решение, но каждый раз этот факт меня поражает.
Теперь, когда у нас есть исходные данные, которые позволяют понять общие масштабы, посмотрим, как мы генерируем наши замечательные веб-страницы. Поскольку не многие системы могут существовать обособленно (и наша — не исключение), архитектурные решения часто теряют смысл без ясного понимания того, каким образом компоненты системы должны взаимодействовать в контексте единого целого. Цель публикации — дать полную картину, полное представление о системе. Частные вопросы её работы будут подробнейшим образом рассмотрены во многих последующих публикациях. Данная публикация представляет собой общий обзор аппаратного обеспечения, а уже в следующей, я остановлюсь на спецификациях устройств более детально.
Для тех из вас, кто хотел бы узнать, как выглядит современное «железо», я сделал несколько снимков стойки А (у которой есть сестра-близнец, стойка В) во время нашего февральского обновления 2015-го года:


… а для фанатов — полный альбом тех дней, состоящий из 256 фотографий (да, вы правы, такое количество фотоснимков отнюдь не случайно). Теперь углубимся в конфигурацию. Ниже логический обзор основных используемых систем:

Основополагающие правила
Несколько правил, которые действуют всегда, и мы не будем повторять их перед каждым разделом: — У всего есть копия. — Все сервера и сетевое оборудование соединены как минимум 2 x 10Gbps. — Все сервера имеют по 2 независимых входа питания от 2 источников бесперебойного питания с 2 резервными генераторами и 2 вспомогательными входами питания. — Все сервера имеют резервную связь между стойками A и B. — Все сервера и сервисы продублированы в дата-центре в Колорадо (все остальное оборудование находится преимущественно в Нью-Йорке). — У всего есть копия.
Сеть Интернет
Сначала нас надо найти — а это DNS. И найти нас надо быстро, поэтому мы делегируем эту задачу (в данный момент) CloudFlare, поскольку их DNS-сервера расположены максимально близко к любому компьютеру в любой точке земного шара. Мы обновляем наши DNS-записи через API, которые выполняют задачу хостинга DNS. Поскольку мы настоящие параноики в том, что касается надежности соединения, мы, в дополнение, позаботились и о собственных DNS-серверах. И если в случае Апокалипсиса (причиной которого, вероятно, станет GPL, Punyon или кэширование) люди, чтобы отвлечься, все еще захотят программировать, мы будем в состоянии предоставить им качественную связь.
После того, как вы обнаруживаете наше тайное убежище, HTTP-трафик поступает от одного из четырех наших ISP (Level 3, Zayo, Cogent, и Lightower в Нью-Йорке) и направляется одним из наших четырех граничных маршрутизаторов. Мы взаимодействуем с ISP при помощи протокола BGP (довольно стандартного), контролируя поток трафика и обеспечивая несколько путей наиболее эффективного его приема. Маршрутизаторы ASR-1001 и ASR-1001-X работают попарно, при этом каждая пара обслуживает по 2 ISP в режиме «активный-активный» — резервное копирование обеспечено. Несмотря на то, что все они находятся в одной и той же физической сети пропускной способностью 10Gbps, внешний трафик идет через выделенные изолированные VLAN, к которым также подключены балансировщики нагрузки. Итак, после маршрутизаторов, трафик попадает на балансировщик нагрузки.
Думаю, сейчас самое время упомянуть, что между двумя нашими дата-центрами запущен сервис 10Gbps MPLS, однако, не задействованный непосредственно в обслуживании сайтов. Этот сервис мы используем для репликации данных и быстрого восстановления при возрастании нагрузки. «Но, Ник, где же здесь резервирование?» Что ж, теоретически вы правы (в лучшем смысле этого слова), тут мы ошиблись — на первый взгляд. Но подождите! У нас есть еще два отказоустойчивых маршрутизатора OSPF (MPLS идет под номером 1, два сервера OCPF — под номерами 2 и 3, в порядке убывания себестоимости), работающие у наших ISP. Каждая из упомянутых групп подсоединяется к соответствующей группе в Колорадо, и они делят между собой нагрузку в случае отказа. Мы могли бы связать обе группы с одной стороны и обеими группами с другой стороны, получив, таким образом, 4 пути, но… Неважно. Идем дальше.
Балансировщики нагрузки (HAProxy)
Балансировщики нагрузки используют HAProxy 1.5.15 на CentOS 7, нашей любимой версии Linux. Трафик TLS (SSL) также распределяется на HAProxy. Тем временем мы присматриваемся к HAProxy 1.7, который поддерживает HTTP/2.
В отличие от остальных серверов с дублированием сетевого подключения 10Gbps LACP, каждый балансировщик нагрузки имеет по 2 пары, пропускной способностью 10Gbps: одна для внешней сети и одна для DMZ. Для повышения эффективности SSL-взаимодействия в этих боксах использовано 64GB и более памяти. Поскольку мы можем кэшировать для повторного использования больше сессий TLS, сокращаются работа по вычислениям при повторных подключениях к клиенту. Это означает, что мы сможем восстанавливать сессии и быстрее, и дешевле. Учитывая довольно низкую стоимость RAM в рублевом эквиваленте, выбор был прост.
Сами по себе балансировщики нагрузки устанавливаются достаточно легко. Мы прослушиваем различные сайты на разных IP (в основном, в целях ознакомления с сертификатами и управления DNS) и направляем трафик на различные терминалы в зависимости от названия сетевых узлов (в основном). Единственный примечательный факт в этом — ограничение скорости и сохранение данных о названиях узлов (отправляемых с нашего web-уровня) в syslog-сообщении HAProxy, что позволяет нам записывать метрики производительности для каждого запроса. Позже мы на этом также остановимся.
Веб-уровень (IIS 8.5, ASP.Net MVC 5.2.3 и .Net 4.6.1)
Балансировщики нагрузки передают трафик на 9 серверов, которые мы называем основными (01-09) и на два «dev/meta»-сервера (10-11, наша вспомогательная среда). Основные сервера обеспечивают работу Stack Overflow, Careers и всех сайтов Stack Exchange, кроме meta.stackoverflow.com и meta.stackexchange.com, которые работают на последних двух серверах. Основное приложение, сервис вопросов и ответов – распределенное. Это означает, что одно приложение отвечает на запросы всех сайтов вопросов и ответов. Иными словами, вся сеть сайтов вопросов и ответов может функционировать на одном пуле приложения, находящемся на одном сервере. Остальные приложения, такие как Careers, API v2, Mobile API и т.п. обособлены. Вот как выглядит первичный уровень и dev-уровень в IIS:

Так выглядит распределение Stack Overflow по веб-уровню в Opserver (наша внутренняя панель мониторинга):
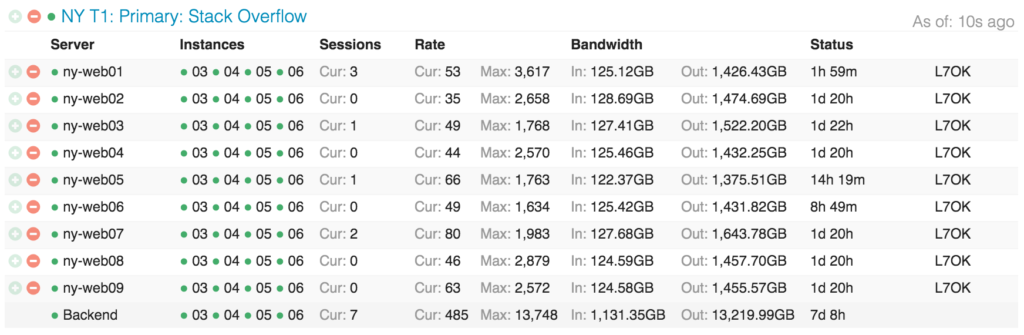
… а так выглядят сервера с точки зрения загрузки:
В следующих публикациях я подробнее остановлюсь на причинах подобной избыточности, а пока назову основное: загрузка программных версий, резерв мощности, резервное копирование.
Сервисный уровень (IIS, ASP.Net MVC 5.2.3, .Net 4.6.1 и HTTP.SYS)
За веб-серверами стоит очень похожий сервисный уровень. Он также использует IIS 8.5 на Windows 2012R2. Этот уровень задействует внутренние сервисы для обеспечения работы продуктового веб-уровня и других внутренних систем. Два основных игрока здесь — Stack Server, использующий сервер меток и http.sys (без привязки к IIS) и Providence API (на IIS). Забавный факт: я должен был установить соответствие, определяющее, что каждый из этих двух процессов должен обрабатываться отдельным процессором, потому что при обновлении списков вопросов Stack Server занимает всю кэш-память L2 и L3 примерно на 2 минуты.
Эти сервисные элементы проделывают немалую работу для сервера меток и серверных API, для которых необходимо лишь резервное копирование (но отнюдь не девятикратное). Например, загрузка всех сообщений и их меток, которые меняются каждые n минут в соответствии с обновлениями в базе данных (а теперь их две) — задача не такая уж и простая. Мы не хотим обрушивать на веб-уровень такой объем, да еще и увеличенный в 9 раз — троекратного запаса для безопасной работы достаточно. Также мы по-разному настраиваем эти сервисные элементы на стороне аппаратного обеспечения — для лучшей оптимизации к различным характеристикам вычислительной нагрузки по индексации для сервера меток и elastic–индексации (которая также осуществляется здесь). Вообще, сервер меток — тема довольно сложная сама по себе, и ей будет посвящена отдельная публикация. Вкратце: когда вы открываете /questions/tagged/java, вы используете сервер меток, чтобы найти соответствующий вопрос. Он осуществляет весь поиск по меткам вне /search, поэтому новая навигация и пр. используют именно этот сервис для получения данных.
Буферная память и Pub/Sub (Redis)
Мы используем Redis для выполнения нескольких функций: он надежен, как скала. Несмотря на внушительные 160 миллиардов операций в месяц, каждый экземпляр использует менее 2% CPU. Но обычно гораздо меньше:
В случае с Redis, мы имеем кэш-систему L1/L2. «L1» — это HTTP Cache на веб-серверах или на любом задействованном приложении. «L2» обращается к Redis и выбирает элемент данных. Наши данные хранятся в формате Protobuf — благодарим @Marc Gravell за его protobuf-dot-net. Для клиента мы используем StackExchange.Redis — написаного нами, общедоступного и бесплатного. Когда один веб–сервер получает непопадание сразу в кэш на L1 и на L2, он выбирает один элемент из источника данных (запрос базы данных, API-вызов и т.п.) и сохраняет результат — как в локальный кэш, так и в Redis. Следующий сервер, обращающийся к этому элементу, может получить непопадание на L1, но не на L2/Redis, что позволяет сохранить запрос к базе данных или API-вызов.
Мы обеспечиваем работу множества сайтов вопросов и ответов, и каждый сайт имеет собственное L1/L2-кэширование: по префиксу ключа на L1 и по идентификатору базы данных на L2/Redis. Более подробно об этом читайте в нашей будущей публикации.
Наряду с двумя основными серверами Redis (первичным/вторичным), на которых работают все копии сайтов, у нас также есть самообучающаяся платформа, расположенная еще на двух подчиненных серверах (в связи с требованиями к объемам памяти), которая используется для реализации механизма рекомендации вопросов, отображаемых на домашней странице, улучшения алгоритма поиска вакансий и т. п.. Платформа называется «Providence», описание которой вы можете найти у @Kevin Montrose.
Основные сервера Redis имеют 256GB оперативной памяти (используется около 90GB), а сервера Providence — 384GB оперативной памяти (используется около 125GB).
Выбор Redis объясняется не только кэшированием, но также механизмом публикации и подписки – когда один сервер публикует сообщение, а все остальные подписчики его получают — включая нисходящих клиентов на вторичных серверах Redis. Мы используем этот механизм для очистки буферной памяти L1 на других серверах в случаях, когда для согласованности данных очистка производится только одним веб–сервером, но есть еще одна великолепная причина, по которой мы выбрали Redis – протокол Websockets.
Websockets (NetGain)
Мы используем Websockets для осуществления принудительных обновлений в режиме реального времени, таких как показ уведомлений в верхнем горизонтальном меню, подсчет голосов, формирование статистики новой навигации, показ новых ответов и комментариев, и еще для нескольких задач.
Сами сервера сокетов используют сырые сокеты, работающие на веб–уровне. Это очень тонкое приложение, использующее нашу открытую библиотеку: StackExchange.NetGain. При пиковой нагрузке мы поддерживаем около 500,000 открытых соединений Websocketодновременно, а это, на самом деле, довольно большое число браузеров. Забавный факт: некоторые из этих браузеров остаются открытыми в течение полутора лет и более, почему — неизвестно. Надо, чтобы кто-то проверил, живы ли люди по ту сторону экрана… Так выглядит график работы Websocket за эту неделю:
Почему мы выбрали Websockets? Они в сотни раз эффективнее ждущего режима — если говорить о наших масштабах. Таким образом, мы можем предоставлять пользователю больше данных с большей скоростью, используя при этом меньше ресурсов. Однако не обошлось и без нюансов: динамический порт и недостаточность дескриптора файлов на балансировщике — курьезы, на которых мы остановимся более подробно чуть позже.
Поиск (Elasticsearch)
Спойлер: по этому поводу похвастаться нечем. Поиск на веб-уровне довольно прост и незамысловат — по сравнению с Elasticsearch 1.4, использующем очень тонкий высокопроизводительный клиент StackExchange.Elastic. Вразрез с нашей обычной политикой, планов открыть исходный код у нас нет — просто потому, что библиотека используемых нами API очень скромна. Я твердо уверен, что ее публикация вызвала бы непонимание разработчиков и принесла бы скорее вред, чем пользу. Мы используем Elasticsearch для /search, определения взаимосвязанных вопросов и генерации подсказок, которые выдаются в процессе создания вопросов.
Каждый кластер Elasticsearch (по одному в каждом из дата-центров) имеет 3 узла, и каждый сайт имеет свой собственный индекс (кроме Careers, который имеет несколько дополнительных индексов). Что делает нашу установку немного нетривиальной в терминах «эластичности»: наши 3 серверных кластера чуть мощнее среднего за счет SSD-хранилища, 192GB оперативной памяти и дублированной сети пропускной способностью 10Gbps для каждого из кластеров.
Домены приложений (да, с .NET CORE мы сплоховали…) на Stack Server, на которых находится механизм меток, также непрерывно индексируют элементы Elasticsearch. Здесь мы прибегли к простым уловкам: например, ROWVERSION в SQL Server (источник данных) сравнивается с документом «последней позиции» в Elastic. Поскольку он ведет себя как последовательность, мы можем просто проиндексировать любые элементы, изменившиеся с последнего прохода.
Главная причина, по которой мы выбрали Elasticsearch, а не что-то типа полнотекстового поиска SQL — его расширяемость и то, что он является более удачным выбором с точки зрения цена–производительность. Центральные процессоры SQL относительно дороги, а Elastic дешев, и, в данный момент, обладает большим набором функций. Почему не Solr? Нам нужен поиск по всей сети (одновременно по нескольким индексам), а на момент принятия решения эта возможность была недоступна. Почему мы еще не на 2.x — значительное изменение в «типах», которое для обновления требует полной переиндексации. И у меня пока просто нет времени внести необходимые изменения и составить план миграции.
Базы данных (SQL Server)
SQL-сервер является нашим единственным источником информации, все данные в Elastic и Redis поступают именно оттуда. У нас работают 2 кластера SQL-сервера с AlwaysOn Availability Groups. Каждый кластер имеет один первичный сервер (принимающий на себя почти всю нагрузку) и одну копию в Нью-Йорке. Дополнительно имеется еще одна копия в Колорадо (в нашем дата-центре аварийного восстановления). Все копии работают асинхронно.
Первый кластер представляет собой несколько серверов Dell R720xd, каждый на 384GB RAM, 4TB PCIe SSD и 2x 12 ядер. На нем работают Stack Overflow, Sites (плохое название; позже объясню), PRIZM и мобильные базы данных.
Второй кластер представляет собой несколько серверов Dell R730xd, каждый на 768GB RAM, 6TB PCIe SSD и 2x 8 ядер. На этом кластере работает все остальное. Список включает:Careers, Open ID, систему чатов, наш Журнал исключений и все остальные сайты вопросов и ответов (напр., Super User, Server Fault и т.п.).
Мы хотим сократить до минимума использования CPU на уровне баз данных, но пока это невозможно в связи с некоторыми нюансами планирования кэша, которые в данный момент мы пытаемся исправить.
На текущий момент, NY-SQL02 и 04 являются первичными, 01 и 03 — копиями, которые мы перезапустили как раз сегодня во время обновлений SSD. Так выглядит статистика за последние 24 часа:

Наш способ использования SQL довольно прост, а проще — значит быстрее. И хотя некоторые запросы могут быть довольно заумными, наше взаимодействие с самим SQL особой сложностью не отличается. У нас есть унаследованный Linq2Sql, но все новые разработки используют Dapper, нашу библиотеку Micro-ORM с открытым исходным кодом, использующую объекты POCO. Выражусь иначе: в базе данных Stack Overflow есть только одна сохраненная процедура и я твердо намерен перенести этот пережиток прошлого в код.
Библиотеки
Что ж, давайте сменим тему: теперь о том, что может быть полезно лично вам. Выше я уже упоминал о некоторых библиотеках, но завершении я бы хотел привести более обширный список библиотек .Net с открытым исходным кодом, поддерживаемых нами для всех, кто захочет ими воспользоваться. Мы сделали их таковыми, потому что особой бизнес-ценностью они не обладают, но могут помочь программистам всего мира. Надеюсь, вам они пригодятся:
- Dapper (.NET Core) — высокопроизводительная библиотека Micro-ORM для ADO.NET.
- StackExchange.Redis — высокопроизводительный клиент Redis.
- MiniProfiler — простое приложение протоколирования, используемое нами на каждой странице (с поддержкой Ruby, Go и Node).
- Exceptional — Регистратор ошибок для SQL, JSON, MySQL, и т.п.
- Jil — высокопроизводительный (де)сериализатор JSON.
- Sigil — средство генерации .NET CIL кода (когда C# оказывается недостаточно быстрым).
- NetGain — высокопроизводительный сервер Websocket.
- Opserver — панель мониторинга, непосредственно проверяющая работоспособность большинства систем, а также принимающая данные Orion, Bosun и WMI.
- Bosun — система мониторинга серверов, написанная на Go. В следующей публикации будет подробный перечень актуального аппаратного обеспечения, на котором работает наш код. После этого мы пройдемся по пунктам этого списка.
Следите за обновлениями!

9К открытий9К показов

История перехода из медтеха в Python-разработку: как менторство помогло преодолеть сотни отказов и найти первую работу в IT. Советы по резюме, собеседованиям и выбору оффера от опытного наставника.

Активность на Stack Overflow падает, сократившись на 75% с 2017 года. И причина не только в популярности ИИ, таких как ChatGPT, заменяющих запросы к сообществу

Опрос Stack Overflow 2025 года показал, что 80% разработчиков применяют ИИ в работе, но доверие к нему снизилось до 29%. Основная проблема — скрытые ошибки в коде, генерируемом ИИ, которые усложняют отладку.

Обновление Windows 11 KB5066835 сломало localhost: HTTP.sys перестал работать, и миллионы разработчиков не могут тестировать проекты