


Хэллоуинский спецвыпуск Tproger Changelog: какие факапы мы словили за этот месяц


В предпраздничном выпуске ченжлога расскажем, с какими проблемами и неудачами нам пришлось столкнуться за этот месяц.
2К открытий2К показов
В этом выпуске ченжлога собрали для вас проблемы и факапы, с которыми столкнулись за последнее время.
Алексей рассказывает, из-за чего в начале месяца упал наш сайт и как пришлось его воскрешать, а Антон делится взломом нашего сервера reports и необходимостью оптимизации ClickHouse.

Алексей
генеральный директор Tproger
В ночь с четверга на пятницу, 2 октября, у нас падал сайт. Примерно с трёх ночи до десяти утра многие страницы не открывались вообще.
Причина оказалась простой: мы с Никитой тестировали новые рассылки в боте. Для этого нужно подключаться к продакшен базе и получать свежие посты. Бот не закрывал MySQL-соединение, и мы быстро достигли лимита в 255 открытых дескрипторов (ограничение managed MySQL от DO). Я закрыл подключение для бота, и минут через 15 база данных разрешила к себе подключаться.
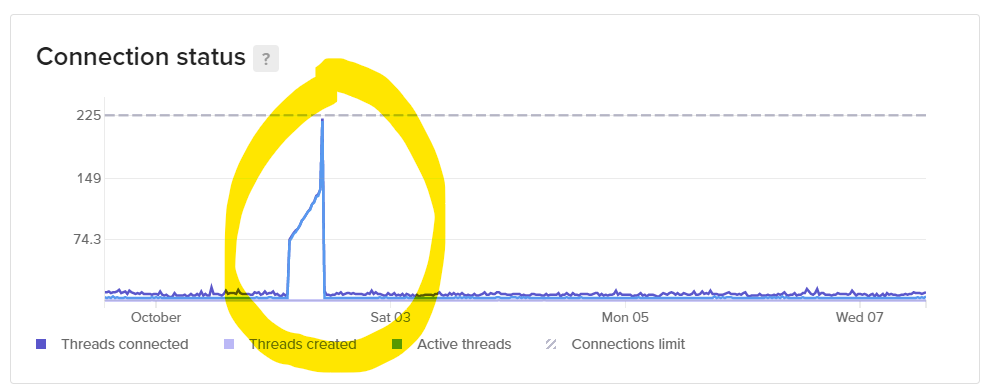
Выводы — настраивайте больше алертов на неочевидные метрики. Количество подключений не приводит к перегрузке по памяти или ЦП, и мы не смогли отловить состояние текущим мониторингом достаточно заранее для принятия превентивных действий.
Вот такая вот история восстания сайта из своей могилы.


Антон Брызгалов
разработчик аналитической инфраструктуры
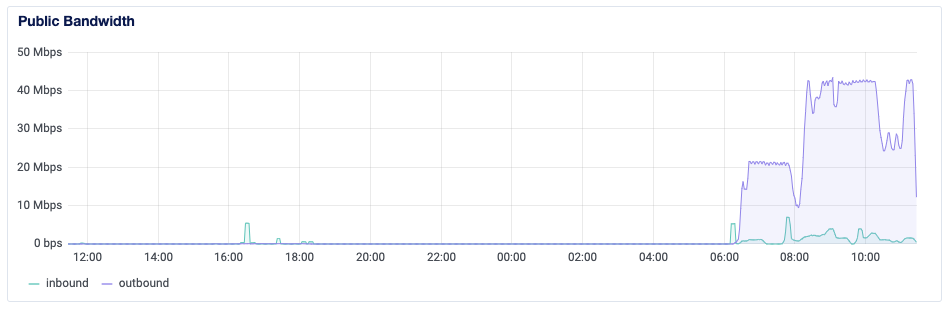
По рабочей необходимости мне потребовалось открыть порт для доступа к Docker API на одной из наших виртуальных машинок, развернутых в Digital Ocean. Открыл порт, воспользовался по назначению, а затем заметил, что ресурсы машины закончились. Нечто забило всю память, а потребление CPU выросло до 100%:

Я не очень опытный пользователь Docker, поэтому сначала решил, что это реально я создал такую нагрузку, и потому запросил дополнительный бюджет на эту машинку, чтобы поднять её ресурсы.
А ещё на сервере иногда запускался подозрительный контейнер с ubuntu. Я тоже подумал на себя и просто удалял его. А он опять появлялся. Ну а я опять удалял. А потом я пошёл спать.
На следующий день от Digital Ocean пришло письмо: мол, ребят, у вас на сервере запущено что-то, что сканирует порты других хостов. Если это не вы, сделайте что-нибудь.
И тут у меня сошлась картинка: открыл порт, на машинке появился незваный гость. А дело всё в том, что на машинках Digital Ocean по умолчанию нет никакого фаерволла: как только открываешь любой порт, он становится доступен всем в интернете. Это спорное решение, но упрощает задачу новичкам и злоумышленникам. Вот мне в открытый порт Docker и заслали какую-то ubuntu.
Я быстренько закрыл порты, удалил вредоносный контейнер в последний раз и всё стало хорошо.
Вот так мы не дали злоумышленнику погубить один из наших серверов.

Правда ненадолго: на следующий день вредоносная активность возобновилась, причем подозрительные процессы через ps aux не обнаруживались. Сервис пришлось перенести на другой сервер, а машинку загасить. Подскажите: как бы вы искали вредоносный процесс на своей виртуалке? Ресурсы были забиты под 100%, но в списке запущенных процессов ни один не вызвал подозрений. Сторонних контейнеров в Docker тоже запущено не было.
А вот еще история. Пишет мне наш шеф-редактор: зашла, мол, в DataLens (почитайте про наш трекер событий), собрала пару графиков, и всё сломалось. Смотрю, а ClickHouse, из которого графики читают данные, прилёг под нагрузкой. Кто виноват? Конечно же юзер! Поругался, урезал доступ к данным. Короче, молодец: если продуктом никто не пользуется — значит его никто не сломает.
Но как-то не по себе: от чего бы ClickHouse падать из-за такого простого запроса? Оказалось, почти вся оперативная память занята. Ну я и решил, всё верно: трекер работает уже несколько месяцев, мы накопили данных — значит, подросли. Значит, пора ресурсы увеличить. Согласовал небольшое увеличение бюджета. Уже знакомый способ решения проблемы, не правда ли? ?
И как-то обидно мне так стало за ClickHouse: что ж он всю оперативку занимает, даже когда запросы не выполняет? Причём потребление памяти постоянно росло:
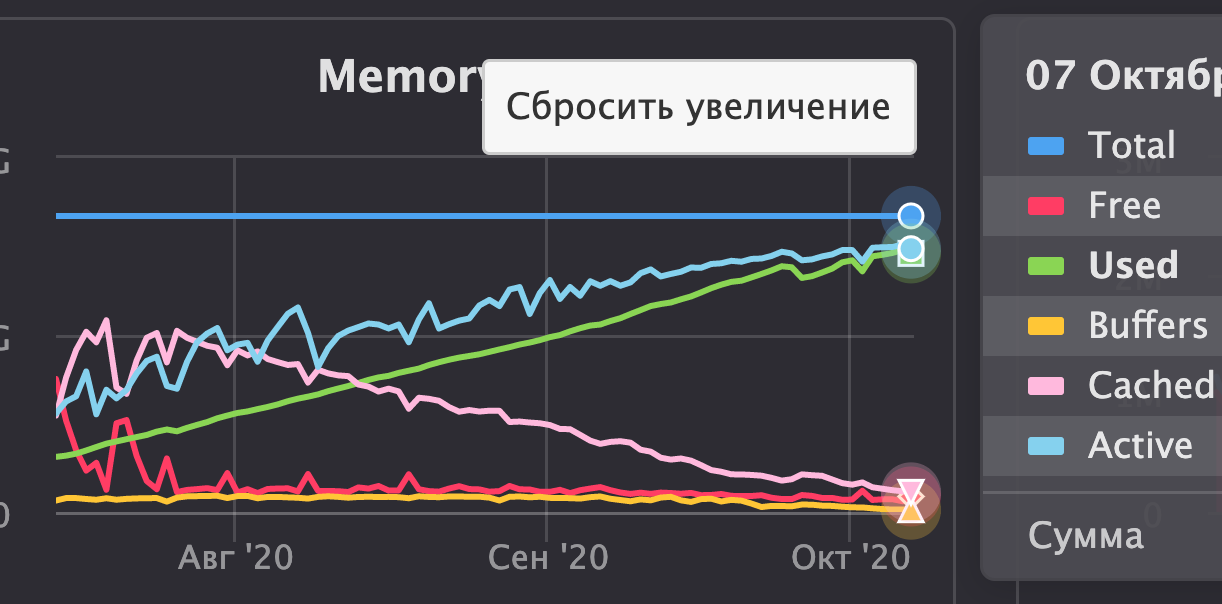
Были у меня под подозрением словари, которые реплицируют данные с продакшн базы Tproger. В них хранятся соответствия идентификаторов постов и их заголовков, рубрик, тегов и т.п. Такое решение было реализовано из-за невозможности создать базу данных с движком MySQL в managed версии ClickHouse.
И хранятся словари как раз в памяти. Причём статистика в системной таблице system.dictionaries по ним показывает, мол, занимают в памяти мегабайт 10 от силы (а по графикам занято уже больше 7 гигов). Короче, не поверил, поменял схему обращения к проду Tproger, и вот как изменилось потребление памяти:
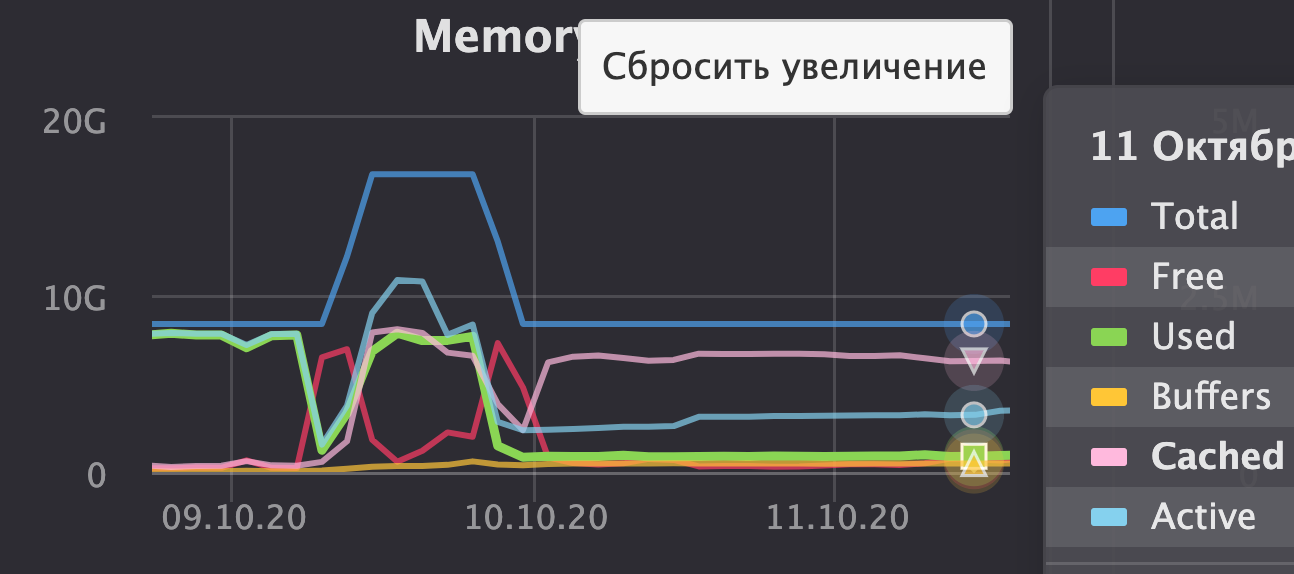
Оказалось, что словари действительно занимали почти всю свободную память. Теперь же данные с прода мы в ClickHouse не храним, а читаем налету. А получилось сделать так благодаря тому, что я случайно наткнулся на нужный раздел в документации ClickHouse ?
С точки зрения производительности и влияния на пользователя, негативного эффекта нет: наша продовая БД работает довольно шустро, а чтения со стороны ClickHouse из неё довольно редкие, ведь пользователей у DataLens пока немного.
В результате удалось вернуть ClickHouse в самую дешёвую конфигурацию и продолжить им комфортно пользоваться.
А как вы строите BI решения для небольших данных?

2К открытий2К показов

Анализируем отчеты Gartner, Stack Overflow и GitHub о будущем бэкенд-разработки. Обзор AI-ассистентов, cloud-native решений, Security as Code и других технологий, которые изменят подход к разработке.

В статье расскажем о невидимых метках, которые оставляет ChatGPT во время работы, а также о «мировом заговоре», который возник из-за этого, и как удалось его раскрыть.

JetBrains дарит год All Products Pack за $0, но требует доступ к приватному коду и данным проектов, что вызывает опасения утечек

Эра Swift 6. Показываем, что обновилось, и какие новые возможности появились. Рассматриваем сравнение с C++ ✔ Tproger