Платформа данных в Яндекс.Облаке: отслеживаем активность пользователей
В Tproger разработали аналитический веб-трекер, чтобы следить за активностью пользователей. Рассказываем о поставленных задачах и их решении.

Антон Брызгалов
разработчик аналитической инфраструктуры
В Tproger мы используем несколько инструментов веб-аналитики, чтобы отслеживать активность пользователей. В одном ряду с традиционными Яндекс.Метрикой и Google Analytics стоит наше собственное решение. В этой статье я расскажу о том, для чего мы разработали свой трекер событий, почему выбрали Яндекс.Облако и как в нем развернулись.
Статья получилась большой. Если у вас нет времени читать ее полностью, пройдитесь хотя бы по заголовкам: так вы поймете, какие задачи предстоит решать тем, кто захочет повторить наш опыт. И добавляйте в закладки, чтобы дочитать лонгрид на досуге ?
Зачем нам собственный трекер событий
Мы задумались о внедрении собственного трекера событий около полутора лет назад. Тогда мы хотели самостоятельно отслеживать активность пользователей, а именно их взаимодействие с рекламными баннерами: показы, клики, скрытия. И далее смотреть на данные в различных срезах, строить визуализации, получать оперативную статистику и развивать системы персонализации.
Эти задачи можно решить готовыми инструментами, например добавить JavaScript-события в Яндекс.Метрике. Кстати, из нее же можно выгружать детальные данные — например для рекомендательных систем. Мы не пошли по этому пути по следующим причинам:
- На момент принятия решения мы не знали о такой функциональности.
- У нас в команде был свободный дата инженер (я), которому интересно было бы реализовать свое решение.
- Свой трекер дает нам полный контроль над хранением данных. У нас была неприятная история с OneSignal: мы долгое время копили у них данные о том, как наши пользователи читают статьи по разным тегам, и сегментировали по ним пуш-уведомления. Внезапно сервис заявил о резком скачке стоимости своих услуг, и если бы мы отказались продолжать сотрудничество, все накопленные данные были бы для нас потеряны.
- В своем трекере мы можем хранить детальные данные. Google Analytics, например, через API отдает только агрегаты. Есть хитрости с кастомными измерениями, которые позволяют выгрузить почти сырые данные, но у нас не было в этом достаточной экспертизы. В случае Google Analytics детальные данные можно также выгружать через BigQuery. За $150,000 в год. Да-да, Analytics 360 стоит именно сто пятьдесят тысяч долларов в год. А сэкономил — значит заработал. Пойду запрошу повышение оклада.
Rockstat, Grafana, Redash — что было раньше и почему мы от них отказались
Итак, как же посмотреть активность пользователя на сайте? Для этого существует множество информационно-аналитических платформ. Начали мы с готового опенсорсного решения Rockstat. Это платформа для маркетинговой аналитики. Предоставляемая статистика в том числе определяет цифровую активность пользователей. Очень мощное решение для своей ниши, основанное на ClickHouse.
С Rockstat мы жили целый год, но отказались от него по следующим причинам:
- Очень слабое покрытие документацией. Около пары месяцев после развертывания мы вообще не понимали, как собирать нужные нам события. Чтобы разобраться в Rockstat, мне пришлось сходить лично на семинар Дмитрия Родина, создателя аналитической платформы анализа данных. Информацию взять больше попросту неоткуда. Тогда семинар был еще бесплатный, сейчас почерпнуть знания можно только на платных курсах Дмитрия.
- У Rockstat есть чат в Telegram, однако Дмитрий как лидер этого небольшого комьюнити, на мой взгляд, ведет себя крайне токсично. Более того, недавно из-за невыполнения его требований по участию в развитии инструмента он вовсе изъял Rockstat из публичного доступа. Впрочем, на GitHub проект все еще открыт.
- Мы не пользовались всей богатой функциональностью Rockstat. Это было решение не для наших задач. Буквально: из 124 столбцов таблицы с событиями мы понимали назначение лишь 5–10.
- Rockstat — Docker-контейнеризированное приложение, которое мы развернули на виртуальной машине в Digital Ocean. И хотя оно проработало без сбоев около года, отсутствие мониторинга и понимания поведения системы затрудняло как поддержку, так и развитие аналитической платформы под наши нужды. Ну и плюс я не девопёс, мне хочется чего-нибудь fully managed в облаке.
В качестве средства визуализации данных мы сначала использовали Grafana, которая поставляется в комплекте с Rockstat. Однако это решение для мониторинга, а мы хотели строить аналитику, и для этого нам не хватало интерактивности: данные хочется смотреть с разными фильтрами, в разных срезах и пр. Grafana такой интерактивности не дает, поэтому мы успешно переехали на Redash. Вот так выглядел наш дашборд в Redash, позволяющий отслеживать производительность сайта на устройствах пользователей:
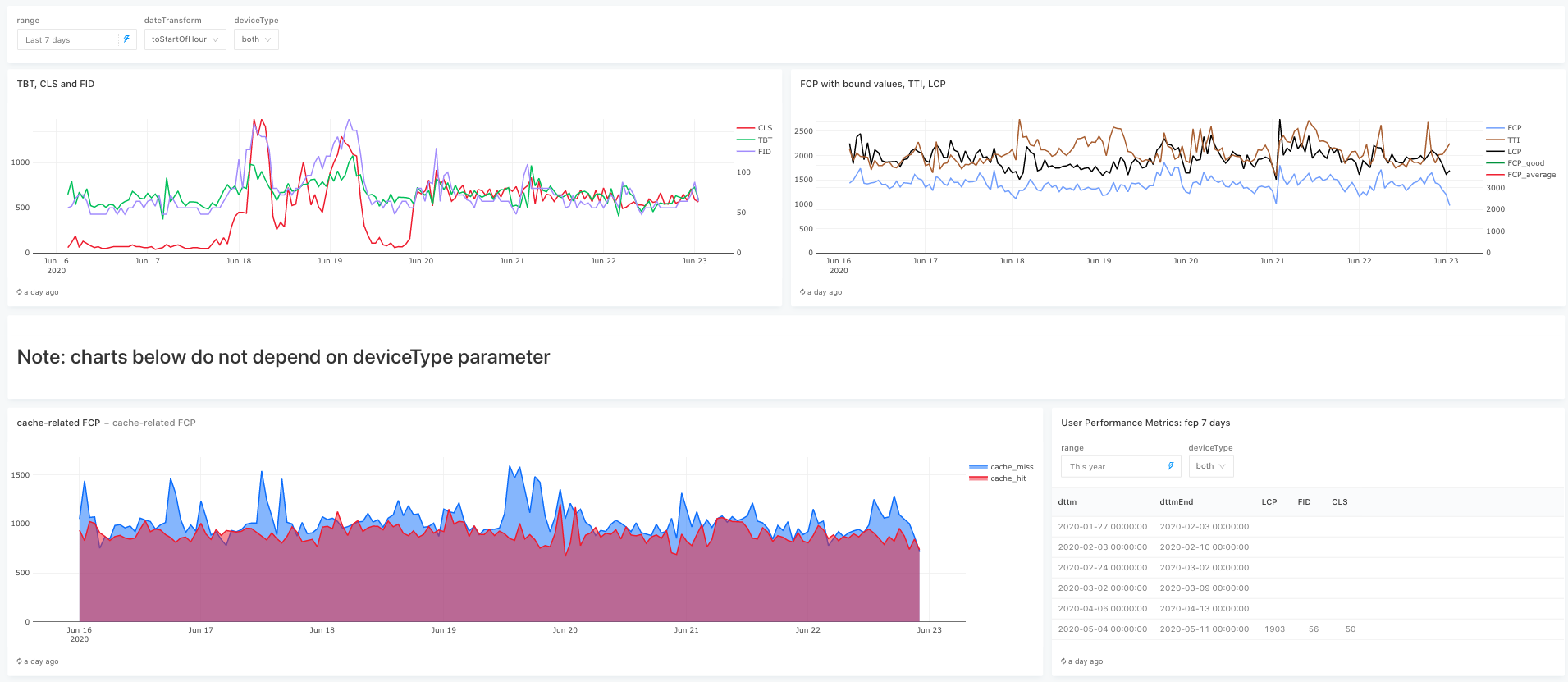
Redash — удобный инструмент, но только если вы владеете SQL. К сожалению, это верно не для всех членов нашей команды и почти все аналитические задачи требовали моего участия. Поэтому нам требовалось найти инструмент, в котором настроить визуализацию можно простым Drag’n’Drop’ом.
Требования к собственному аналитическому трекеру
Опыт использования связки Rockstat + Redash помог нам четче определиться с ожиданиями от собственного аналитического решения:
- Минимальные усилия по развертыванию и обслуживанию. Мы готовы переплатить за cloud-native и fully managed решения, но небольшая команда из одного дата инженера должна держать фокус на бизнес-задачах, а не эксплуатационной рутине.
- К пункту выше относится и удобство мониторинга. Это важно: Rockstat работал стабильно и фактически не требовал значительных затрат на обслуживание, но как долго он бы мог так проработать, было неясно из-за отсутствия контроля за его состоянием.
- Автономность no-SQL членов команды в решении аналитических задач. Дата инженер разово проектирует датасет, а затем не принимает участия в создании визуализаций.
- ClickHouse в качестве базы данных. Здесь особо нет альтернатив: он создан как раз для задач хранения и агрегации больших объемов сырых данных. Также свою роль сыграла моя личная симпатия к этому продукту ?
Почему мы выбрали Яндекс.Облако
Из всех облачных провайдеров сейчас только один предоставляет ClickHouse как услугу — это Яндекс Облако. На нем мы и остановили свой выбор. Набора облачных сервисов Яндекса нам хватило, чтобы реализовать полностью бессерверное управляемое решение.
Когда мы разобрались, как работать в облаке Яндекс, впечатления сложились самые приятные: удобная платформа, на которой поддерживаются популярные облачные технологии.
Что нравится в Яндекс.Облаке:
- Приветственный грант на 8 000 рублей на два месяца: можно опробовать минимальные конфигурации всех сервисов фактически бесплатно. Свое решение мы построили меньше, чем за месяц, и пока продолжаем жить в Яндекс.Облаке на грант.
- У службы поддержки есть несколько тарифов. И даже на бесплатном тарифе можно написать вопрос в свободной форме и в течение суток получить ответ от оператора. Это значительно упрощает освоение платформы. Тариф с возможностью задать вопрос в службу поддержки того же AWS стоит $29.
- Платформа активно собирает обратную связь и развивается. Со мной лично пообщался даже руководитель разработки Yandex Cloud Functions, с которым я поделился своим видением на желаемые фичи сервиса и опытом использования AWS Lambda. По результатам общения в течение месяца появились несколько запрошенных мной возможностей.
- Яндекс.Облако развивает свое сообщество. Например, есть раздел, где можно предложить свои идеи. Это здорово влияет на вовлечение: чувствуешь себя частью сообщества и понимаешь, что тебя услышат. Несколько моих (про MySQL, про фильтры по умолчанию) уже опубликовали, приятно ?
- Есть темная тема для интерфейса. Тут даже добавить нечего.
В то же время ощутимо, что сервис молод и поэтому лишен приятных мелочей, которые есть у зрелых конкурентов. Рассказываю об этом в разделе про архитектуру, где перечисляю, чем в Яндекс.Облаке пользуемся мы.
Более того, за короткую историю нашего трекера у Яндекс.Облака один раз «отказала автоматика», из-за чего мы потеряли несколько часов данных. О паре факапов — наших и провайдера — я рассказал в выпуске Tproger Changelog:
Этот инцидент выходил за рамки SLA, потому что мы использовали однонодовую конфигурацию ClickHouse-кластера, а гарантии начинаются от двух нод. Но с платным пакетом поддержки, который стоит 990 рублей в месяц, мы смогли совместными усилиями с командой Яндекс.Облака оперативно вернуть инфраструктуру трекера в рабочее состояние.
Удобно, что ресурсы Яндекс.Облака можно развертывать через Terraform, чем мы и пользуемся. Поддержка неполная, но постепенно догоняет веб-консоль, а где-то даже обгоняет ? В частности, для нашей несложной конфигурации возможностей Terraform вполне хватает.
Архитектура и компоненты трекера
В подразделах ниже перечислены архитектурные компоненты трекера. Сейчас мы выдерживаем нашу скромную нагрузку в несколько десятков запросов в секунду в пике, но решение обещает быть устойчивым и в будущем.
Web SDK
С клиентов события отправляет разработанный нами Web SDK. Это небольшая асинхронная JavaScript-библиотека, основанная на методе sendBeacon.
Этот метод позволяет отправить данные с веб-страницы, даже если пользователь уже закрыл вкладку или перешел по ссылке на другую страницу. То есть дает больше гарантий, чем AJAX. Однако имеет некоторые ограничения, например не дает управлять заголовками запроса и поддерживает только multipart/form-data или text/plain.
Фронтенд: CloudFlare Worker
Фронтендом для приема событий выступает бессерверный CloudFlare Worker. Напомню, что CloudFlare — это провайдер CDN. Воркеры аналогично медиа-ассетам развертываются по всему земному шару, что позволяет снизить задержку между клиентом и воркером.
Наш воркер сразу отвечает клиенту кодом 204 No Content, после чего в асинхронном режиме ждет ответа от бэкенда. Да-да, в отличие от других бессерверных решений CloudFlare Workers могут сначала ответить на запрос, а затем в фоне завершить какую-то задачу. Без дополнительной платы.
Бэкенд: Yandex Cloud Function
Бэкенд реализован на базе бессерверной Yandex Cloud Function, аналоге AWS Lambda.
Приятная особенность сервиса от Яндекса в том, что функция из коробки имеет URL для приема HTTP-запросов, который можно сделать публичным. В AWS публичный эндпоинт для функции можно было бы создать только в сервисе API Gateway, за который взимается дополнительная плата.
С недавнего времени появилась возможность делать HTTP-запросы к функциям приватно, используя долговременный авторизационный токен.
Yandex Cloud Function поддерживает несколько сред выполнения для популярных языков программирования: Python, PHP, Go, Node.js и даже Bash. Возможности создавать произвольные среды окружения, как в AWS Lambda, нет. Но разве может потребоваться что-то еще? Что-что, Perl?.. Те, кто пишут на Perl, в состоянии, пожалуй, развернуть собственное облако.
Я использую Python 3.7. Поддержки 3.8 пока нет. Впрочем, в 3.7 уже достаточно зрелая поддержка асинхронности, которую Cloud Functions поддерживают из коробки: основной обработчик можно определить как асинхронную функцию (async def) и окружение само разберется, как ее вызывать. Это значительное преимущество в сравнении с AWS Lambda, где обработчик может быть только синхронным.
Увы, поддержка асинхронности немного не докручена: запуск функции реализован через asyncio.run, который пересоздает EventLoop на каждый вызов. Из-за этого использование ресурсов, открытых вне обработчика, приводит к возникновению ошибки Future attached to a different loop. Чтобы этого избежать, открывайте ресурсы внутри обработчика или вручную выполняйте корутину через asyncio.get_event_loop().run_until_complete(handler_coro) внутри синхронного обработчика. Команда сервиса обещала это исправить.
Yandex Cloud Function уступает AWS Lambda в удобстве мониторинга активности пользователей: например, сейчас в сервисе от Яндекса нельзя даже грепать логи. После использования почти полноценного аналитического инструмента AWS CloudWatch Logs Insights, который позволяет агрегировать логи и строить по ним визуализацию, отсутствие даже простой фильтрации в логах Cloud Function удручает. Впрочем, и поиск по логам разработчики обещали добавить в ближайшее время.
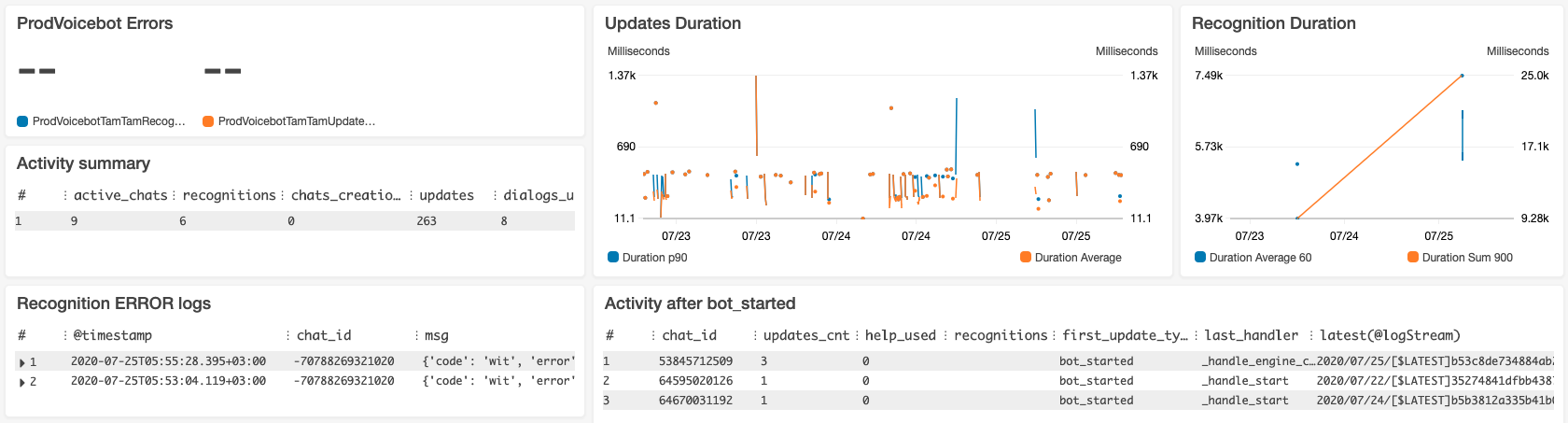
Очередь сообщений: Yandex Message Queue
Этот сервис — прямой аналог AWS SQS, в том числе реализует тот же API. Это позволяет использовать официальные AWS CLI и SDK: например, boto для Python. Нужно только указать правильные эндпоинт и регион, о чем подробно рассказывает документация Yandex Message Queue.
В первой версии нашего трекера функция-бэкенд писала напрямую в ClickHouse. Однако это анти-паттерн, потому что на каждую запись ClickHouse открывает новый файл. База нашего трекера состоит из одной таблицы, которая хранит все события, и нескольких таблиц-справочников, реализованных в виде материализованных представлений. Из-за этого на запись одного события наш ClickHouse открывал по несколько файловых дескрипторов, которые закончились под пиковой нагрузкой. Решилось буферизацией записи через очередь событий.
Другая проблема записи каждого отдельного события состоит в том, что при пиковой нагрузке может исчерпаться лимит на число соединений с базой данных. Я использую нативный TCP-протокол для связи с ClickHouse, и поэтому у сервера БД нет контроля за числом соединений, который был бы в случае использования HTTP-протокола с Keep-Alive. Cloud Function должна переиспользовать подключения, которые открыты в глобальной области видимости, но мои эксперименты показали неконтролируемый рост числа таких соединений. Попытки настроить через receive_timeout не увенчались успехом, а idle_connection_timeout и tcp_keep_alive_timeout в настройках кластера я не нашел. Поэтому буферизация событий тем более актуальна.
Из очереди события переносятся в базу данных второй Cloud Function в составе нашего проекта, которая запускается ежеминутно по триггеру-таймеру.
Состояние очереди сообщений удобно мониторить через стандартный дашборд:

База данных: Yandex Managed Service for ClickHouse
Fully managed ClickHouse. Кликаем несколько кнопок, и кластер нужной мощности развернут для использования. Ежесуточно создаются резервные копии. В несколько кликов можно изменить объем жесткого диска или мощность виртуальной машины. Минимальная стоимость составляет чуть больше 500 рублей в месяц: за эту сумму вы получите 2 ГБ оперативной памяти и 5% от 2 vCPU. Этих ресурсов вполне хватает для реализации Proof-of-Concept решений и тестовых нагрузок.
Под прод рекомендуется развертывать хосты со 100% vCPU. Минимальная стоимость таких начинается с 3 700 рублей в месяц. Также напомню, что Яндекс отвечает за жизнеспособность кластера с не менее чем двумя нодами. Чтобы ноды ClickHouse работали в кластере, потребуется добавить и хосты ZooKeeper, такие конфигурации начинаются от 15 000 рублей, согласно калькулятору (внизу страницы).
Мы пока живем с одной нодой ? Но не без казусов: однажды мы с коллегой одновременно открыли дашборды, которые строятся по данным из ClickHouse, и тот просто прилег, не вместив все данные в память. Случай пока единичный, но пренебрегать стабильностью базы данных не стоит.
Кластеру ClickHouse можно присвоить публичный адрес за небольшую дополнительную плату. Открывать базу наружу — это плохо, но в Яндекс.Облаке нет другой возможности писать в ClickHouse из Yandex Cloud Function. Команда сервиса сейчас работает над этой функциональностью.
В сервисе есть дашборд для мониторинга состояния как СУБД ClickHouse:
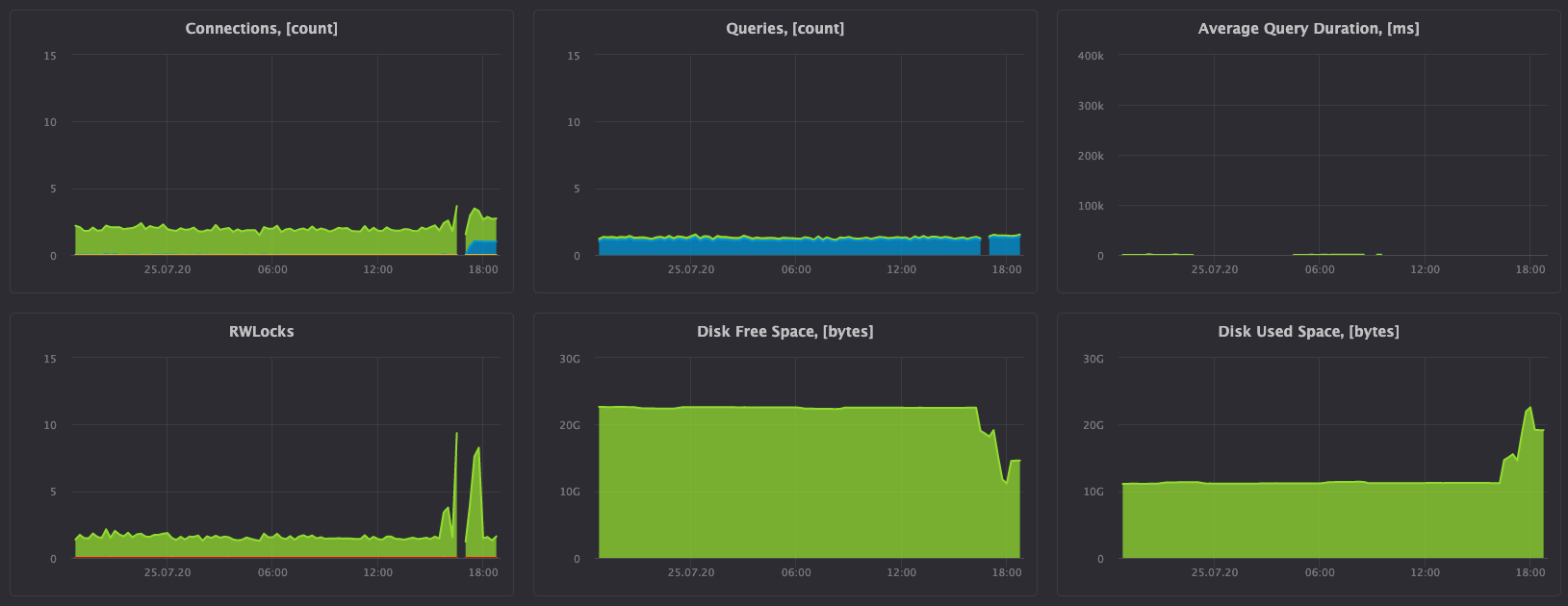
Так и состояния хостов в кластере:
Отдельное неудобство доставляет невозможность подключиться к ClickHouse в Яндекс.Облаке из PyCharm, моей любимой IDE. Я уже зарепортил баг, его даже пофиксили, но в релизе он пока не встретился. Отношения к Яндекс.Облаку не имеет, «но осадочек остался» ? Впрочем, у сервиса есть веб-клиент для написания SQL запросов, который вполне решает базовые задачи. Также без проблем можно подключиться из консольного clickhouse-client.
Визуализация: Yandex DataLens
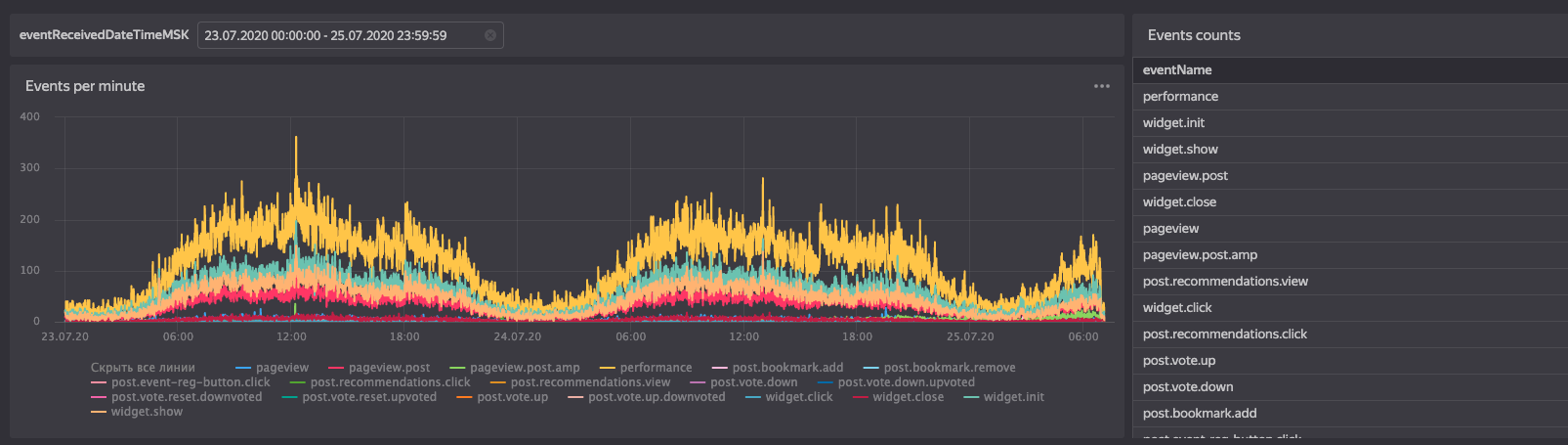
DataLens — BI-инструмент, поддерживающий Drag’n’Drop для настройки графиков, который реализован в формате SaaS, то есть это полноценное веб-приложение для построения визуализаций по данным. Вот так выглядит один из наших дашбордов:
Минусы DataLens
DataLens уступает таким коллегам по цеху, как Tableau, Google DataStudio или Microsoft PowerBI, в гибкости настройки и удобстве использования.
Вот неполный список неприятностей:
- Нельзя наложить графики разных типов друг на друга. Например, не получится построить линейный график CTR, а на его фоне столбчатую диаграмму просмотров.
- Не поддерживает поля типа
Array. В ClickHouse они активно используются для расширения схемы таблицы произвольным набором атрибутов. - Нельзя решить такую простую задачу, как выделение топ-N элементов. Можно отфильтровать по фиксированному порогу: например, 10 000 просмотров, но это снижает гибкость. Не хватает возможностей, вроде Set’ов и FIXED из Tableau.
- Запросы к БД делаются на каждое изменение визуализации, что на этапе проектирования графика может сильно нагрузить базу, не предназначенную для активных агрегаций (конкретно ClickHouse справляется с нагрузкой неплохо).
- Рядам на графиках нельзя задавать кастомные метки.
- На дашборде время отображается по UTC, даже если в поле-источнике указан часовой пояс. Настроить никак нельзя, только явным прибавлением сдвига по времени (+3 часа для Москвы).
Плюсы DataLens
При всем этом нельзя не отметить, что команда проделала большую качественную работу: будучи еще сотрудником Яндекса, я сам много работал с внутренним инструментом-предшественником DataLens, и то, насколько продукт приблизился к лучшим представителям индустрии, впечатляет. Сейчас сервис продолжает активно развиваться: за месяц, который мы его используем, команда DataLens уже переработала некоторые части интерфейса, а также добавила поддержку оконных функций.
Что еще приятного в DataLens:
- Он бесплатный.
- Никакого SQL. Визуализация строится в несколько кликов.
- Понятные абстракции для работы с данными: подключение, датасет, чарт и дашборд. И хотя это довольно стандартный набор сущностей, в этом инструменте они выглядят особенно целостно.
- Широкий спектр функций для вычислимых полей. Дает достаточную свободу, чтобы к полю-источнику применить все необходимые преобразования.
- Множество поддерживаемых источников данных: например, можно читать данные из Яндекс.Метрики.
- Есть географические функции: например, можно перевести топоним в координаты и наложить данные на карту.
- Очень точные настройки доступа: можно выдать права на чтение таблицы, но запретить чтение одного из полей. Очень удобно, чтобы открывать некоторые поля, например финансовые показатели, не всем пользователям.
- К графикам и дашбордам можно выдавать доступ по публичной ссылке.
- Интеграция с системой авторизации Яндекса. То есть все, у кого есть почта в доменах @yandex.*, могут получить доступ к DataLens, никаких дополнительных аккаунтов не требуется.
В целом DataLens — это достаточно удобный инструмент, чтобы отследить активность пользователей, но со своими ограничениями. Мы невольно сравниваем его с Redash, который использовали раньше. Не всегда в пользу DataLens, но привыкнуть можно.
Главный показатель успешности внедрения для меня — это то, что Redash пользовались 2–3 человека в команде, а к DataLens активный интерес проявляют уже около 10 членов редакции.
Например, DataLens активно использует команда, занимающаяся развитием сообщества читателей на нашем сайте. Среди прочих метрик, они отслеживают активность пользователей в комментариях:

Технические и организационные задачи при внедрении трекера
При реализации собственного трекера мы столкнулись с некоторыми техническими и организационными челленджами, которые успешно решили. Чтобы вам было понятнее, почему эти задачи возникли, я опишу модель данных нашего трекера.
Каждое событие — это связь нескольких сущностей: пользователь прочитал статью, пользователь оставил комментарий к статье. В терминологии хранилищ данных каждое событие — это факт. Сущности, которые связываются в одно событие, сами обладают некоторыми атрибутами: у статьи есть заголовок, у комментария — текст.
Факты — это ядро модели данных. По идентификаторам связанных сущностей из боевой базы мы подтягиваем атрибуты и можем затем строить аналитику в различных срезах по этим атрибутам: например, считать число комментариев к статьям в разбивке по дате публикации и/или тегам. Такая схема организации данных называется «звездой».
В нашей реализации таблица событий одна — в ней хранятся все события, которые мы трекаем. Каждое событие может иметь произвольный набор атрибутов. Для того, чтобы с атрибутами событий можно было работать, как с отдельными колонками, над таблицей создаются представления (VIEW). В случае ClickHouse такие представления — это просто сохраненные подзапросы.
В исходной таблице кастомные атрибуты события (например идентификатор статьи) хранятся в паре полей-массивов, первый из которых хранит имена атрибутов (например ['postId']), а второй — значения (например ['123']). В производных представлениях эти поля выделяются в отдельные атрибуты нужного типа (появляется столбец postId, содержащий значение 123). И затем по такому идентификатору мы можем из боевой базы подтянуть атрибуты сущности (например теги статьи).
ClickHouse очень эффективно работает с полями-массивами, поэтому неудобств от разбора атрибутов событий «на лету» мы не испытываем.
Хранение таблиц-измерений
Атрибуты сущностей (например дата публикации статьи) хранятся в так называемых таблицах-измерениях (это отсылка к многомерной модели данных). Боевая СУБД нашего сайта, где хранится вся информация о сущностях с сайта — это MySQL. И первый челлендж, который нам встретился — это организация доступа из ClickHouse в MySQL.
В пору использования Rockstat реализовать связь было просто: в ClickHouse есть специальный движок, позволяющий выполнять запросы над данными, которые хранятся в MySQL. То есть мы пишем запрос в SQL-диалекте ClickHouse, а СУБД сама ходит в MySQL-источник, читает оттуда данные и затем оперирует с ними как с данными внутри самого ClickHouse. Фантастическая возможность, которая в одну команду дает доступ ко всем данным боевой базы. Настраиваем фаервол, и готово.
В Яндекс.Облаке создать схему (database) в ClickHouse через SQL-запрос пока нельзя. Набор схем полностью контролируется провайдером. И потому движок у схемы может быть только стандартным, поддержки MySQL нет. Решением для нас явилась следующая схема:
- Создаем внешние словари с источником-MySQL. Словарь по ключу сопоставляет набор атрибутов. Например, идентификатор статьи можно через словарь зарезолвить в ее заголовок.
- Создаем материализованное представление, которое на примере таблицы с атрибутами статей содержит столбцы
postId,postTitle,postDateи т.д. - Материализованное представление работает следующим образом: на каждую вставку в таблицу событий выполняется вставка в материализованное представление. Таким образом, когда пользователь посмотрел статью, к нам в таблицу фактов прилетит событие с атрибутом
postId, по которому из словаря зарезолвятся атрибуты статьи. Идентификатор и атрибуты образуют новую строку в таблице-измерении, что позволяет отследить активность пользователей в статье. - Таблицу под материализованным измерением имеет смысл делать с движком
Joinи строгостьюANY. Таблицы с таким движком оптимизированы ровно под операциюJOIN, а при строгостиANY, во-первых, для каждого ключа хранится только одна строка, а во-вторых, при соединении таблиц ищется первое совпадение, что еще больше оптимизирует такие запросы. В силу того, что в нашей таблице-измерении хранится единственное значение для каждого идентификатора сущности (по сути это таблица-словарь), такая семантика полностью отвечает нашим нуждам.
Описанная схема дает следующие преимущества:
- Словари кэшируют свое содержимое, и чтение из них не создает высокую нагрузку на боевую базу сайта. Политик кеширования множество, почитайте.
- Материализованное представление хранит данные в таблице, что позволяет выполнять эффективные
JOIN‘ы сразу для множества строк, а не выполнять поиск в словаре для каждой строки. - Ручное создание таблицы под материализованным представлением позволяет контролировать ее движок и вставлять туда данные вручную. Это важно, потому что материализованное представление «слушает» только вставки в свежую таблицу событий, вставлять же в нее атрибуты исторических событий, которые хранятся в других таблицах, потребуется явным
INSERT‘ом.
Описанный подход доказал свою эффективность на нашем кейсе: чтение из базы данных при построении аналитики происходит достаточно быстро и несмотря на то, что на лету происходит довольно сложное преобразование из массива в число, задержка в построении визуализаций из-за этого значительнее не становится.
Недавно мне попался на глаза раздел документации про таблицы с движком Dictionary. Мы пока не успели опробовать движок на практике, но его использование выглядит как способ избежать сложностей с материализованными представлениями. Более того, словари при первом использовании загружаются из источника полностью, поэтому таблица с движком Dictionary будет копировать таблицу-источник. Далее словари обновляются в фоне, что также снижает эффективность постоянного обновления материализованного представления.
Альтернативным решением было бы чтение данных из боевой базы через DataLens: у сервиса есть поддержка подключения к MySQL. Однако в таком случае открыть доступ к базе потребовалось бы из нескольких подсетей Яндекс.Облака. Подключение напрямую из ClickHouse сужает доступ до единственного публичного IP-адреса.
Некоторые таблицы-измерения не хранятся в боевой базе в формате «ключ»-«набор атрибутов». Например, чтобы получить список тегов статьи по ее идентификатору, в WordPress требуется соединить три таблицы. Чтобы данные лежали в формате, который удобен для загрузки в словарь ClickHouse, мы строим в MySQL представление нужной структуры на базе этого соединения таблиц.
В ближайшем будущем нам потребуется подключить на чтение БД на PostgreSQL, для этого планируем использовать словари на ODBC.
Миграция исторических данных из Rockstat
До собственного трекера мы использовали Rockstat, и там накопился достаточный объем ценных для нас данных. Миграция исторических данных состоит из двух этапов: во-первых, данные надо перенести в новую базу данных, а во-вторых, объединить их со свежими данными.
В документации для миграции данных рекомендуется использовать clickhouse-copier. Но на наших небольших объемах себя отлично показал clickhouse-client, чем я был приятно удивлен. Порядок действий с его использованием следующий:
- Сдампить нужные поля из нужных таблиц в файл в формате ClickHouse Native:
clickhouse-client --query "SELECT … FORMAT Native" > dump.bin. Native — это ровно тот формат, в котором сам ClickHouse передает данные, без преобразований. То есть в файл они будут выгружены в колоночном бинарном формате и вы не потратите время даже на сериализацию. - Вставить данные в целевую таблицу целевой БД:
cat dump.bin | clickhouse-client --host … "INSERT INTO … FORMAT Native".
Таким способом удалось перенести 20 ГБ несжатых данных всего за несколько минут. clickhouse-client отлично жмет данные при передаче.
В Яндекс.Облаке исторические данные размещаются в отдельной схеме в таблицах со структурой, максимально приближенной к исходной БД. Отдельными представлениями данные преобразуются к формату нового трекера событий, а объединяем данные простым UNION ALL. Чтобы к историческим данным подтягивались атрибуты статей, баннеров и пр., атрибуты из словарей явным образом вставлены в таблицы материализованных представлений — об этом я писал в разделе выше.
При объединении с историей наблюдается небольшая просадка производительности, поэтому приучаем команду использовать историю событий только по необходимости.
Иерархия и версионирование событий
Отслеживаемые события в нашем трекере образуют иерархию. Иерархия отражена в именах событий. Например, имена событий, связанные со статьями, задаются паттерном post.%: post.bookmark.add, post.recommendations.click, post.vote.up.
Каждый тип события имеет свой набор атрибутов, причем атрибуты наследуются из старших узлов иерархии. Так, у всех событий семейства post.% присутствует postId, а у событий post.recommendations.% добавляется атрибут recommendationsType, обозначающий способ построения списка рекомендаций. Кстати, о нашей системе рекомендаций я рассказывал в выпуске Tproger Changelog:

Если у события атрибут может иметь пустое значение, не делайте этот атрибут необязательным. Лучше выделите такие события с пустым атрибутом в отдельную подгруппу.
Также события удобно версионировать. Мы увеличиваем версию события, если:
- Сменился его атрибутивный состав. Например, добавилось новое свойство.
- Сменилась его семантика. Например, как только вы открываете любую страницу нашего сайта, мы трекаем событие
pageview. Раньше мы отправляли это событие для всех страниц, но затем стали отправлять новое событиеpageview.postс параметромpostIdдля страниц со статьями, аpageviewбез атрибутов — для всех остальных страниц. Таким образом, имя событияpageviewосталось без изменений, однако его семантика изменилась — и отразить это можно только инкрементом версии события.
Чтобы команде было удобно пользоваться данными, я поддерживаю набор курируемых датасетов, на базе которых члены редакции строят свои визуализации. Обычно каждый такой датасет соответствует одному узлу в иерархии событий: отдельный датасет для событий, связанных со статьями, отдельный — с баннерами, и т.д.
В будущем иерархию и атрибутивный состав событий следует отразить в SDK трекера. Хотелось бы описывать события в чем-нибудь вроде YAML, чтобы по такому описанию автоматически генерировались документация и SDK для разных языков программирования. Например, так делают в Avito:
Мы собираем события из двух сред: со страниц сайта (JavaScript) и чат-ботов ВКонтакте и Telegram (Python). Поэтому для нас вполне актуальна задача кодогенерации.
Пользовательские «сессии»
Мы не трекаем сессии пользователей. Объединять активность в сессии правильнее уже в момент построения аналитики: например, в одной задаче сессией будут считаться действия с разницей не более 30 минут, а в другой — с разницей не более 12 часов.
Однако мы объединяем запросы пользователей, отправленные с одной страницы, общим идентификатором — идентификатором серии запросов. Это позволяет легко отследить всю активность, объединив в цепочку все взаимодействия пользователя со страницей нашего сайта.
Что дальше: интеграция трекера в бизнес-процессы
Итак, теперь у нас в арсенале есть собственный инструмент для отслеживания активности пользователей и построения аналитики на ее основе. Сейчас это хорошо протестированное и даже немного проверенное временем решение, поэтому технически первая итерация завершена. Отлажен механизм добавления новых событий для трекинга.
Следующая важная задача — это построение культуры использования данных. В этом направлении огромную работу делает топ-менеджмент Tproger: сейчас в команде активно внедряются методологии для ведения бизнеса на основе измеримых показателей. Мне как архитектору остается лишь прислушиваться к обратной связи от коллег и развивать продукт в сторону интуитивно понятной модели использования.
В общем, дальше остается сделать Tproger по-настоящему data driven ?
Также лично я лелею надежду выпустить проект в open source. Инструмент получился достаточно гибким и универсальным, чтобы решать задачи не только нашего бизнеса.
Спасибо всем дочитавшим мой рассказ до конца. Буду рад ответить на ваши вопросы в комментариях.
Опросы пока не работают










![Обложка: Как стать аналитиком данных за 6–12 месяцев [гайд]](https://media.tproger.ru/uploads/2025/12/1c7c4818-f579-4330-b4fe-56704d1972e0.jpg)

